大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
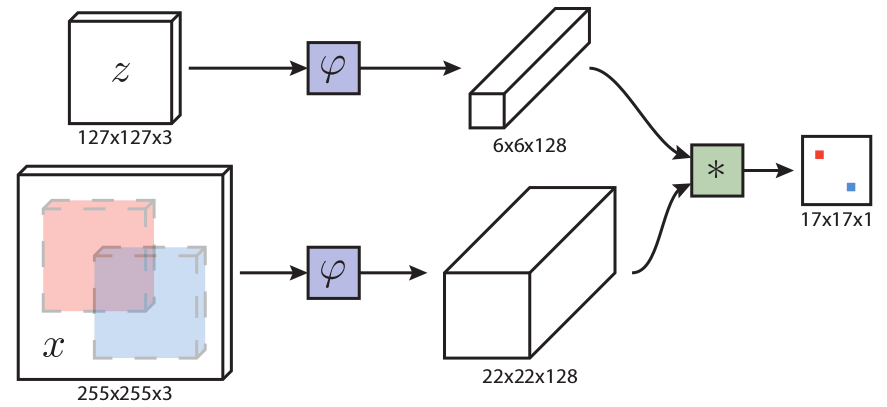

训练过程
训练过程,网络的最终输出是 17×17 的response map.
网络的输入
需要保证两条支路上目标物体在输入图片的中心位置,且目标物体在整幅图像中有一定的占比。
对于模板图片
模板图片大小: 127×127×3。以目标中心为裁剪中心,确定一个稍大的正方形(记边长为 C )裁剪区域(可能会超出原图片,以图片颜色均值填充),然后再将裁剪区域resize到127×127大小。根据paper,C 的计算公式如下(设目标框的大小为w×h):
$$
\begin{array}{ll}
w’ =w+(w+h)·0.5 \\
h’ =h+(w+h)·0.5 \\
C = \sqrt{w’*h’}
\end{array}
$$
对于搜索图片
搜索图片大小:255×255×3。以目标中心为裁剪中心,需要先确定上面的 C ,然后在按比例(127:255)确定搜索图片的正方形裁剪区域边长 C‘。
训练的细节
维度问题
具体实现上,卷积后的通道数和paper描述的不同。
卷积操作
训练batch中每个输入样本对的卷积操作可以用groups参数实现。
batch norm
添加 batch norm 层,否则loss会出现nan的情况。要对其进行初始化。
label
训练网络的输出是一个 17×17 的 2D response. 由于SiamFC是全卷积网络,所以不用关心物体在图片中的位置,将以物体为中心的图像输入两条支路。这样可以直接将 ground truth 设为中心响应最大的 17×17 2D response:根据输入和网络缩放情况,将 response 中心点及其 Manhattan Distance 距离为2的点设为1,其余点设为0(与paper中稍不同,因为采用的是binary_cross_entropy_with_logits损失函数)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18labels:
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
Manhattan Distance = 16 / 8, 8是网络stride的总步长, 16是超参数。
normalize response1responses_maps = 0.001 * responses_maps
Score adjustment is simply normalizing response to the range (e.g. [-10, 10]) where sigmoid is not saturated. Without it, the scale of the response will be on the order of 1e3 and the gradients vanish.
For most of the time, set the scale to 1e-3 and the train_bias to True should be fine.
lr_decay_factor这是根据作者的 learning rate schedule 得到的。作者在 50 个 epoch 内,learning rate 从 1e-2 下降到 1e-5,设 x = lr_decay_factor, 则有 1e-2 * x ^ (50 -1) = 1e-5, 求解得到 x = 0.8685113737513527.
关于augmentation
为了增强鲁棒性,对输入图片加入干扰。由于response map 上相邻的两点在输入的搜索图片上对应区域中心的间隔为2×2×2=8. 所以,可以让模板图片和搜索图片的中心(也就是目标物体)在8×8的区域内随机取点(保证二者的最大间隔不超过8)。
测试过程
网络的输入
模板图片是第一帧上crop和resize的区域,搜索图片则根据上一帧的预测bbox确定,具体方法和训练过程一样。
确定物体中心和大小
要注意如何确定输入的 search 区域上目标框的中心和大小:
找到 一号最大响应点 ,确定尺度:三个17*17的 2D response 分别经过16倍双三次插值上采样变成三个272*272大小的2D response。
对于第一个和第三个非正常尺度的 2D response 乘以一个惩罚值(这里是 0.9745 )。第二个是正常尺度(与原图1:1),可以将惩罚值看做 1.0 。
选取惩罚后的三个 2D response 中最大值所在的那一个 response 对应的尺度作为目标的最佳尺度 best scale ,将这个 response 称为 best response (272×272)。
找到 二号最大响应点 ,将此最大相应点对应到输入的 search 区域,确定目标框的中心:对 best response (272×272) 进行归一化处理,然后用一个对应大小的余弦窗(hanning window)进行惩罚(余弦窗中心位置的值最大,往四周方向的值逐渐减小。因为目标物体靠近区域中心,这样做可以看做是对预测时出现较大位移的惩罚)。
找到处理后的 best response (272×272) 中最大值的坐标,将这个坐标对应到输入的 search 区域上的一个点(通过和中心的距离来对应),作为 search 区域中预测的目标物体中心位置。
确定目标框的大小:由 best scale 和初始帧中的目标框大小确定当前预测框的大小,宽高比保持不变 。
测试的细节
关于加窗
具体计算过程:
1response = (1 – 0.176) * response + 0.176 * hanning_window
0.176 (22/125) 这个超参数的由来并没有特别说明。
关于尺度的选择

3尺度情况下
输入crop:
将原crop边长(记为 C ) 乘以下面的尺度,得到三个新的crop边长,按新边长进行区域裁剪:
$$
scales = [1.0375^{-1}, 1.0375^{0}, 1.0375^{1}]
$$
1.0375 (83/80) 这个超参数的由来并没有特别说明。
惩罚:
对于三个尺度上的最大值,分别乘上 [0.9745, 1, 0.9745] 作为惩罚,然后再比较三者中的最大值,作为最终尺度。
0.9745 这个超参数的由来并没有特别说明。
bbox更新:
确定最终bbox的尺度:
1
2update_scale = (1 – 0.59) * 1.0 + 0.59 * new_scale
bbox_w_h *= update_scale
0.59 这个超参数的由来并没有特别说明。
中心点到输入图片的映射
backbone采用的是AlexNet,共有3次stride操作,所以 response map 上相邻的两点在输入的搜索图片上对应区域中心的间隔为2×2×2=8. 从距离中心的位置可以推断 scaled crop 上的位置,进一步推断出原图上的位置。
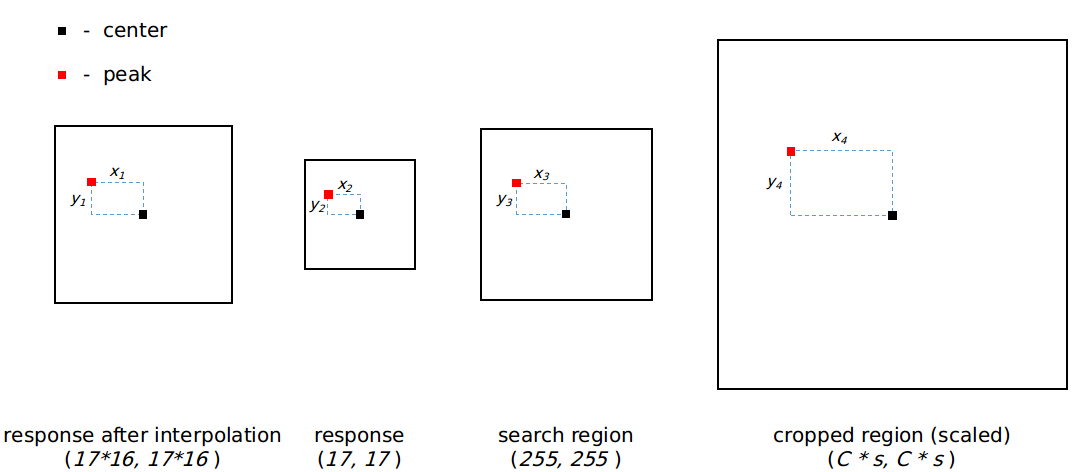
s 是选择出来的 best scale.
$(x_4, y_4)$ 是预测的目标中心$(x_p, y_p)$相对于上一帧的目标中心$(x_l, y_l)$的偏移量,有:
$$
\begin{array}{ll}
x_p = x_l + x_4 \\
y_p = y_l + y_4
\end{array}
$$
改进模板图像始终是第一帧,未涉及更新。
bbox纵横比不能改变。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186993.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
