大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
时间轮很早前就很流行了,在很多优秀开源框架中都有用到,像kafka、netty。也算是现在工程师基本都了解的一个知识储备了。有幸在工作中造过两次轮子,所以今天聊聊时间轮。
时间轮是一种高性能定时器。
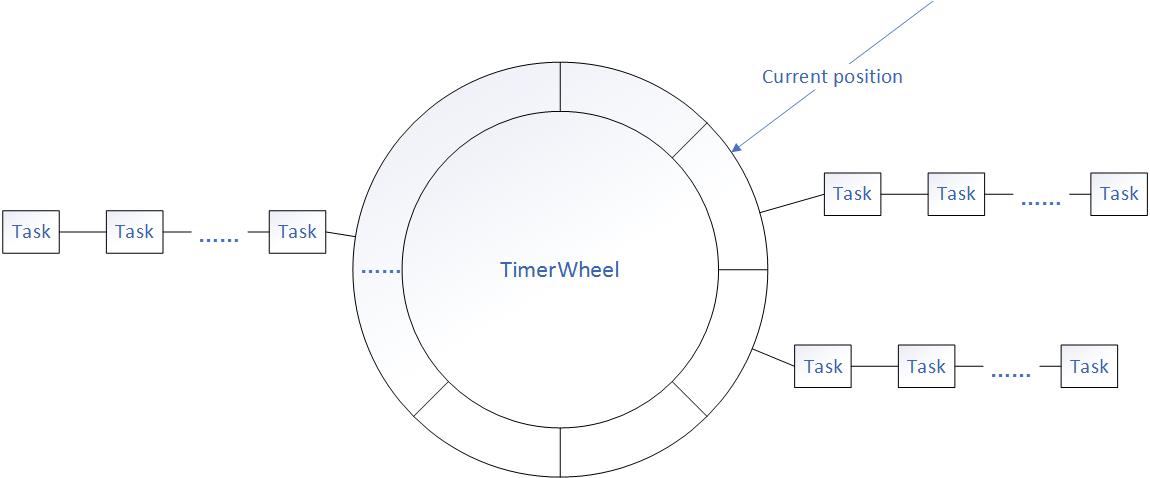

时间轮,顾名思义,就是一个基于时间的轮子,轮子划分为多个槽,每个槽代表一个时间跨度,槽的数量*时间跨度等于时间轮可以支持的最大延迟时间。在每个槽上挂载若干同一时间跨度内需要执行的任务。随着时间的流动,每过一个时间跨度,当前位置向前推进一格,触发当前槽挂载的所有定时任务。
定时任务如何找到需要挂载的槽呢,我们可以利用公式来计算:
delay:延迟时间
slotDuration:槽时间跨度
currentSlot:当前推进的槽
例如,我们时间轮精度为1s,当前推进到了第10个槽,新来的延迟10s的任务放在第20个槽上。
在实际应用中,一般单时间轮无法满足需求。例如我们需要秒级的精度,最大延迟可能是10天,那我们时间轮就要至少864000个格子,这就产生了如下几个问题:
- 占用存储过大
- 利用率太低,比如我们只有1秒一个任务,而7天若干任务,那大部分时间,整个轮子都是在空转。
所以一般又会有对基本的时间轮做一些改造。一般有两种改造方式,我们依次介绍一下。
第一种改造,对每个任务增加一个round属性,即轮次的属性,只有当前任务的round=0时才会触发执行,如果发现round>0,则只需要对round减一即可。
比如我们一个轮子还是秒级精度,总共3600个槽,即单圈支持1小时的延迟。当我们有一个需要延迟3小时的任务时,我们只需要把任务放到指定槽,并且设置round=3即可。
计算公式如下:
slot=(delay/slotDuration)%slotSize+tick
round=math.floor((delay/slotDuration)/slotSize)这样又会产生另外一个问题,即每个槽上的任务数量过多,并且大部分是不需要执行的,只需要进行round-1的任务,又会产生性能问题。
第二种改造,多级时间轮。
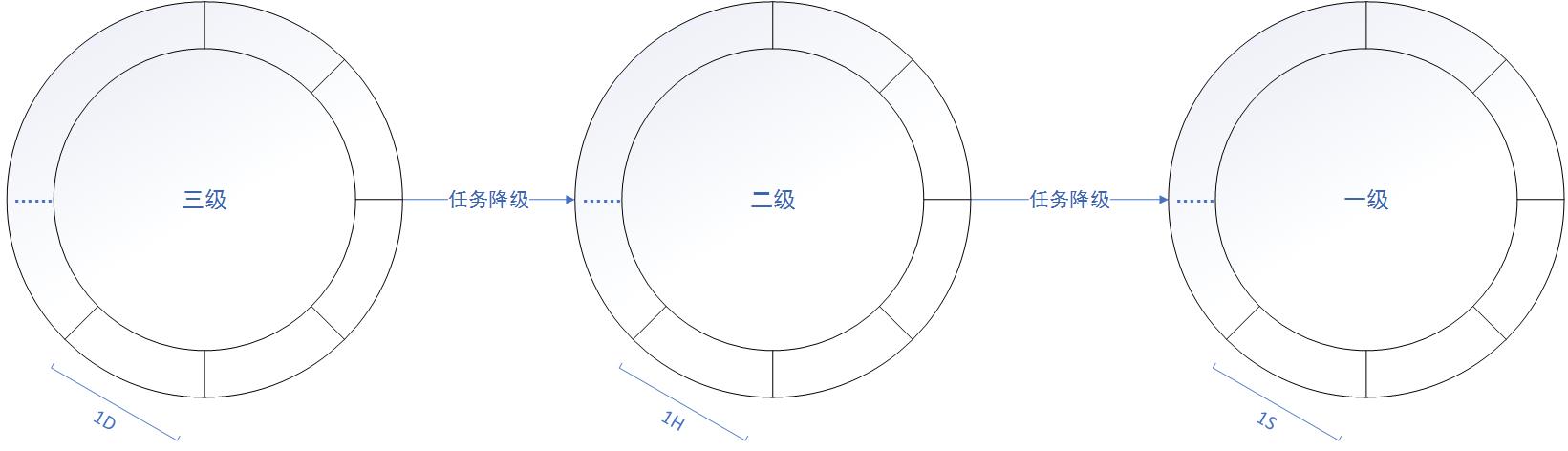
我们可以把时间轮分级,n+1层时间轮的槽时间跨度为n层时间轮的一圈的总时间跨度,所以当n层时间轮推进一圈时,n+1层时间轮推进一个槽,并且只有第一层时间轮实际处理定时任务,其余n+1层时间轮转动后,都是把当前槽的任务降级挂载到第n层时间轮上。
例如,我们如图有三级时间轮,一级时间轮每个槽1秒时间跨度,3600槽,即一圈总时间跨度1小时。二级时间轮每个槽1小时时间跨度,24个槽,即一圈总时间跨度1天。三级时间轮每个槽1天时间跨度,10个槽,即总时间跨度10天。
我们只需要3600+24+10=3634个槽,就可以支持1秒级精度,最大10天的时间延迟,相比于单级时间轮的864000个槽,是很大的优化。
当我们有一个5小时10分钟的定时任务,我们可以很容易看出他应该属于第二个时间轮,按照前面的公式挂载到相应的位置。当一级时间轮推进5圈后,即二级时间轮推进5次后,处理到该定时任务所在的槽,该定时任务只剩下10分钟延迟,再通过公式把该定时任务降级到一级时间轮的指定槽中。
但是也产生了另外一个问题,即n级时间轮推进一圈后,需要等待n+1级时间轮降级后才可以继续推进,如果n+1级时间轮的降级操作很耗时,则会影响n级时间轮的正常推进。
所以一般会采用预热的方式,提前触发n+1级时间轮的降级,解耦多级时间轮之间推进的强关联,保证一级时间轮推进的连续性。预加载方式很多,比如n级时间轮增加round信息,n+1级时间轮推进时处理下一槽,而不处理当前槽;比如不等n级时间轮转一圈后再推进n+1级时间轮,可以在推进一半或某些位置时,提前触发n+1级时间轮的降级;等等。
这样我们就解决了占用内存过大的问题,一般两种模型会结合使用。
对于时间轮空转的问题依旧存在,一般我们还会结合延迟队列来配合时间轮的推进。
一般会把每个使用到的槽都会放到DelayQueue中,然后根据DelayQueue来协助时间轮的推进,防止空推进的情况。
例如,当有延迟500s的任务时,除了挂载到时间轮外,我们还会把其放到DelayQueue中,这样DelayQueue的头结点为延迟500s,如果期间没有小于500s的延迟任务再加进来时,我们只需要等待500s,时间轮推进一次即可。如果有小于500s的定时任务新加进来,我们只需要唤醒DelayQueue,重新计算等待时间即可。
即当有定时任务新增时,如果对应槽为新槽(即新增任务为该槽的第一个任务),在DelayQueue中增加延迟任务,并判断是否为头结点,是的话唤醒DelayQueue重新计算等待时间。
这样我们对于时间轮的改造就完成了。
那么接下来看一下在实际工作中,我们是如何使用的,并且使用到了什么场景。
第一个造轮子场景就是我们最常见的延迟任务。场景是,一大批的数据库执行的任务,每行记录都可以自行设置更新、删除操作,并且可以设置任意的延迟时间。
这个场景就非常适合使用时间轮,首先因为数据量非常大,而一般我们用的DelayQueue的插入、删除时间复杂度都为nlongn,我们的时间精度要求非常高,所以不太适合。如果对每条记录都创建一个定时任务,那更不现实。并且我们是一个微服务架构,产生定时任务的服务与处理定时任务的模块是分开的。
因为当时业务场景,单级时间轮完全可以满足,所以就利用了redis来实现了单级时间轮的功能。
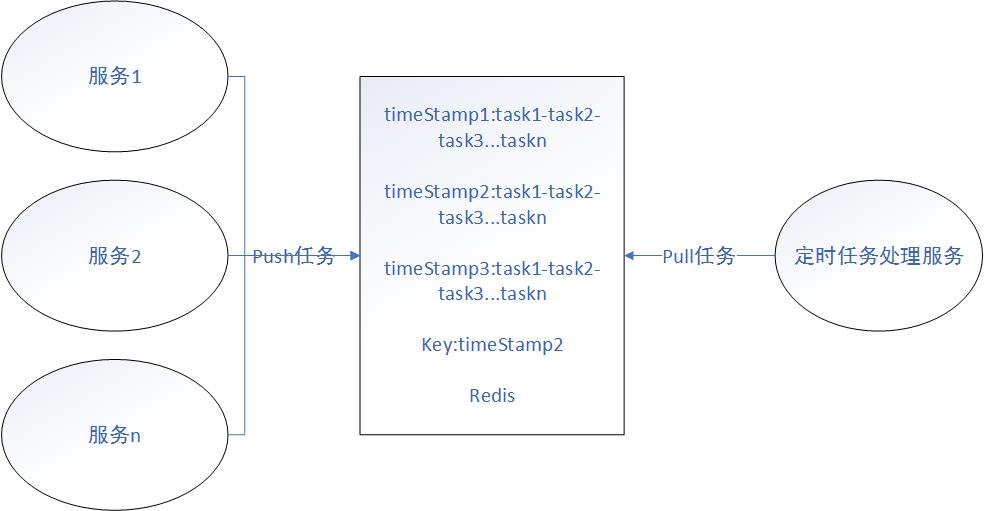
首先,我们在redis中按照时间精度存了若干个key-list结构,key为槽所对应的延迟时间,这里与上面介绍的时间轮不同,这里的时间不是相对延迟时间,而是绝对的时间戳。list就保存了该槽挂载的所有任务,这里为数据库主键与操作类型。
当有新任务产生时,首先计算出实际执行的时间戳,并转换为我们需要的精度,然后利用lpush放到对应key的list里。在我们的定时任务处理服务中,会通过sleep的方式来推进时间轮,每推进一次,根据当前时间l前时间lrange对应key的定时任务,然后执行,最后把key删除。
这会存在可靠性的问题,如果定时任务服务挂了,宕机期间未执行的定时任务都无法再执行了。因此我们还会在redis中保存一个key-value,用来记录已经推进完的key。这样当服务重启时,首先从k/v结构中获取已经推进的位置,然后从该位置连续推进到当前时间戳。正常服务运行时,每推进一次,都会更新一次k/v结构中的值,更新已经推进的位置。
以上是第一个造轮子的场景,利用redis实现了一个简单的一级时间轮。
第二个造轮子的场景是消息队列对于任意延迟消息的支持。
这里我们采用了两级时间轮+多round组合的方式来实现。一级时间轮为1s精度,3600个槽的时间轮,二级时间轮为1h精度,240个槽的时间轮。这样我们就可以支持1s精度,最大10天的任意延迟消息。
时间轮实际保存为一个数组结构,数组每个位置为一个链表,保存所有的任务,通过本地sleep的方式进行推进。
我们以RocketMQ为例,说明如何支持任意延迟消息的。我们知道RocketMQ中接收到一条消息后,通过DispatchServer会将其保存到commitLog与consumeQueue中。我们在其中又加入一个流程,即如果是任意延迟消息类型,会将其保存到DelayLog与DelayLogIndex中。DelayLog按小时存储,每小时内的消息存储到一组文件中,保存实际的消息。DelayLogIndex则保存了消息的索引,即发送的timeStamp、所处DelayLog的offset、与消息的大小size。
一级时间轮上挂载了当前小时所有DelayLogIndex。二级时间轮上,挂载了所有的DelayLog,当然这里只是一个文件引用,不会保存文件内容,否则内存压力会很大。
当有新消息进来时,首先计算出其实际发送的时间戳,判断是否可以直接挂载到一级时间轮上,并且如果该消息为当前消息的第一条消息,则需要将DelayLog挂载到二级时间轮的指定槽上。
每秒一级时间轮推进时,通过DelayLogIndex从DelayLog中获取实际消息内容,重新保存到commitLog与consumeQueue中,这样消费者就可以消费到了数据。
每一个小时二级时间轮推进时,要获取当前槽处的DelayLog,将其对应的DelayLogIndex全部挂载到一级时间轮上。
因为有多级时间轮推进的问题,所以一般也都会采用预加载的方式。哪种方案都可以采用。
这里我们同样面临第一个场景的问题,可靠性。如果服务端宕机,如何恢复数据。这个就不像第一个任务那么简单,只需要记录已经推进完哪个slot即可,因为数据库操作我们可以做到幂等,而这里我们需要保证消息的不丢不重。
所以,我们不仅需要记录当前已经推进slot,还需要记录推进到当前slot挂载的任务链表的哪个位置。这就需要恢复数据的稳定性,即数据恢复后,链表与最原始链表一致。所以我们在挂载数据时,需要按照消息到达服务端先后顺序进行排序,并且每处理一条消息,要记录一下该消息的位置。在启动恢复时,就可以根据该位置只处理其后的消息,这样,我们就可以保证消息在时间轮上不重不丢。
这样结束了吗?我们继续看一个问题,我们算一条索引30B,一级时间轮有3600个槽,两个round,一共是7200个槽。10GB内存平均每个槽可以存储多少条索引?(10*1024*1024*1024)/(30*7200)=49710。也就是说我们最大能支持的QPS只有不到5W,这也太低了。怎么解决这个问题?
我们提出一种文件倒排链表的组织结构,每个DelayLogIndex增加一个前置索引preIndex,把每秒钟的延迟消息按照时间上的倒叙串成链表,即链表头为当前秒的最后一条消息的DelayLogIndex,其preIndex指向前一条消息。这样我们只需要一级时间轮上保存链表头即可。当推进到某个槽时,我们通过链表头可以倒叙遍历找到该秒的所有DelayLogIndex。如此解决了内存问题。
但是又会引入另一个问题,如果遍历链表耗时很长,那么每次推进就会产生延迟。所以我们依旧需要预加载,即对当前推进槽后的n个槽提前触发遍历,把所有数据加载到一级时间轮上,保证了推进的连续性。
以上是第二个造轮子的场景。
对于时间轮的一些实现细节,在kafka和netty中都有最佳实践,不过kafka中是结合DelayQueue来做推进,避免了空推进的场景。而netty中采用了修正时间的sleep的方式进行推进,有兴趣可以阅读源码。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186969.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
