大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
同样是copy,二者有什么不同呢今天我们就一探究竟!!!
关于copy()和deepcopy()的第一篇博客
初学编程的小伙伴都会对于深浅拷贝的用法有些疑问,今天我们就结合python变量存储的特性从内存的角度来谈一谈赋值和深浅拷贝~~~
预备知识一——python的变量及其存储
在详细的了解python中赋值、copy和deepcopy之前,我们还是要花一点时间来了解一下python内存中变量的存储情况。
在高级语言中,变量是对内存及其地址的抽象。对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身。
引用语义:在python中,变量保存的是对象(值)的引用,我们称为引用语义。采用这种方式,变量所需的存储空间大小一致,因为变量只是保存了一个引用。也被称为对象语义和指针语义。
值语义:有些语言采用的不是这种方式,它们把变量的值直接保存在变量的存储区里,这种方式被我们称为值语义,例如C语言,采用这种存储方式,每一个变量在内存中所占的空间就要根据变量实际的大小而定,无法固定下来。
值语义和引用语义的区别:
值语义: 死的、 傻的、 简单的、 具体的、 可复制的
引用语义: 活的、 聪明的、 复杂的、 抽象的、 不可复制的
引用语义与值语义详解
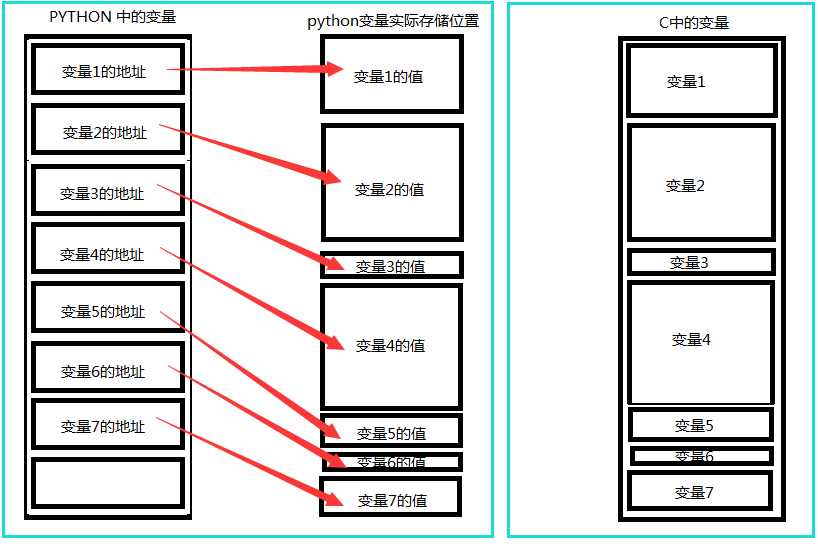
我们来看一张简单易懂的图理解一下python的引用语义和C语言值语义在内存中的存储情况,左右两个图,分别表示了python中变量存储与C语言中变量存储区别:

预备知识二——各基本数据类型的地址存储及改变情况
在python中的数据类型包括:bool、int、long、float、str、set、list、tuple、dict等等。我们可以大致将这些数据类型归类为简单数据类型和复杂的数据结构。
我的划分标准是,如果一个数据类型,可以将其他的数据类型作为自己的元素,我就认为这是一种数据结构。
数据结构的分类有很多种,但是在Python中常用的只有集合、序列和映射三种结构。
对应python中的set、list(tuple、str)、dict;常用的数据类型有int、long、float、bool、str等类型。
(其中,str类型比较特别,因为从C语言的角度来说,str其实是一个char的集合,但是这与本文的关联不大,所以我们暂时不谈这个问题)
数据结构及其划分依据

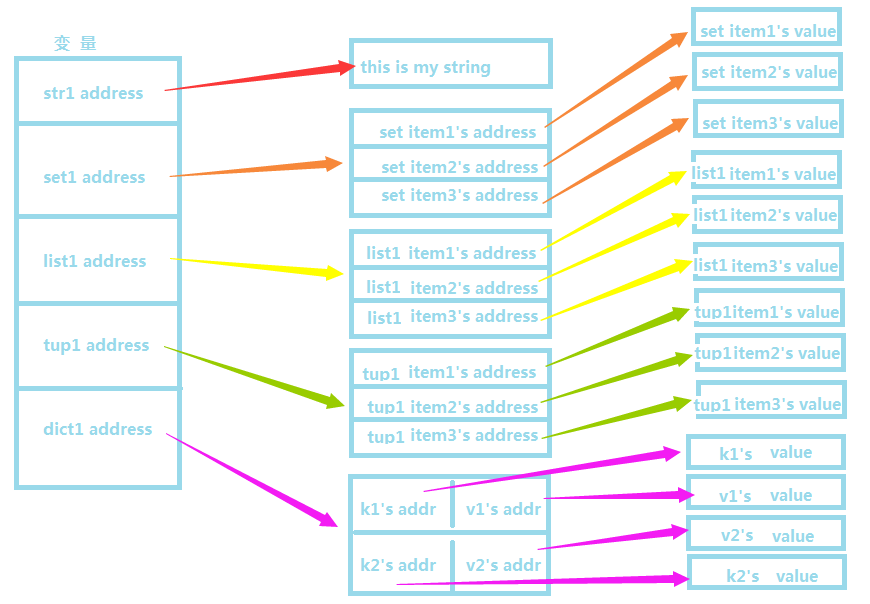
由于python中的变量都是采用的引用语义,数据结构可以包含基础数据类型,导致了在python中数据的存储是下图这种情况,每个变量中都存储了这个变量的地址,而不是值本身;对于复杂的数据结构来说,里面的存储的也只只是每个元素的地址而已。:
1.数据类型重新初始化对python语义引用的影响
变量的每一次初始化,都开辟了一个新的空间,将新内容的地址赋值给变量。对于下图来说,我们重复的给str1赋值,其实在内存中的变化如下右图:
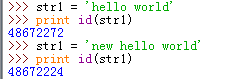
从上图我们可以看出,str1在重复的初始化过程中,是因为str1中存储的元素地址由’hello world’的地址变成了’new hello world’的。
2.数据结构内部元素变化重对python语义引用的影响
对于复杂的数据类型来说,改变其内部的值对于变量的影响:
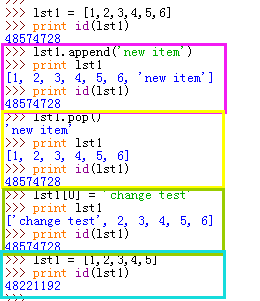
当对列表中的元素进行一些增删改的操作的时候,是不会影响到lst1列表本身对于整个列表地址的,只会改变其内部元素的地址引用。可是当我们对于一个列表重新初始化(赋值)的时候,就给lst1这个变量重新赋予了一个地址,覆盖了原本列表的地址,这个时候,lst1列表的内存id就发生了改变。上面这个道理用在所有复杂的数据类型中都是一样的。
变量的赋值
搞明白了上面的内容,再来探讨变量的赋值,就变得非常简单了。
1.str的赋值
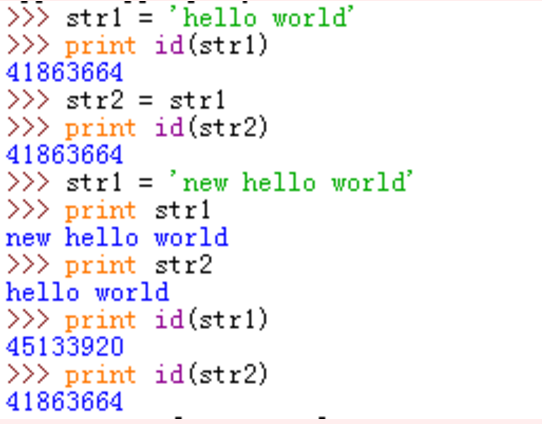
我们刚刚已经知道,str1的再次初始化(赋值)会导致内存地址的改变,从上图的结果我们可以看出修改了str1之后,被赋值的str2从内存地址到值都没有受到影响。
看内存中的变化,起始的赋值操作让str1和str2变量都存储了‘hello world’所在的地址,重新对str1初始化,使str1中存储的地址发生了改变,指向了新建的值,此时str2变量存储的内存地址并未改变,所以不受影响。
2.复杂的数据结构中的赋值
刚刚我们看了简单数据类型的赋值,现在来看复杂数据结构变化对应内存的影响。
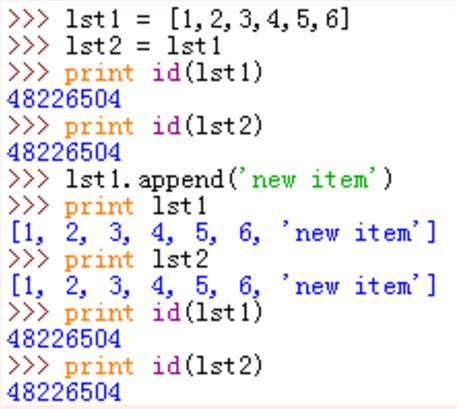
上图对列表的增加修改操作,没有改变列表的内存地址,lst1和lst2都发生了变化。
对照内存图我们不难看出,在列表中添加新值时,列表中又多存储了一个新元素的地址,而列表本身的地址没有变化,所以lst1和lst2的id均没有改变并且都被添加了一个新的元素。
简单的比喻一下,我们出去吃饭,lst1和lst2就像是同桌吃饭的两个人,两个人公用一张桌子,只要桌子不变,桌子上的菜发生了变化两个人是共同感受的。
初识拷贝
我们已经详细了解了变量赋值的过程。对于复杂的数据结构来说,赋值就等于完全共享了资源,一个值的改变会完全被另一个值共享。
然而有的时候,我们偏偏需要将一份数据的原始内容保留一份,再去处理数据,这个时候使用赋值就不够明智了。python为这种需求提供了copy模块。提供了两种主要的copy方法,一种是普通的copy,另一种是deepcopy。我们称前者是浅拷贝,后者为深拷贝。
深浅拷贝一直是所有编程语言的重要知识点,下面我们就从内存的角度来分析一下两者的区别。
浅拷贝
首先,我们来了解一下浅拷贝。浅拷贝:不管多么复杂的数据结构,浅拷贝都只会copy一层。下面就让我们看一张图,来了解一下浅浅拷贝的概念。
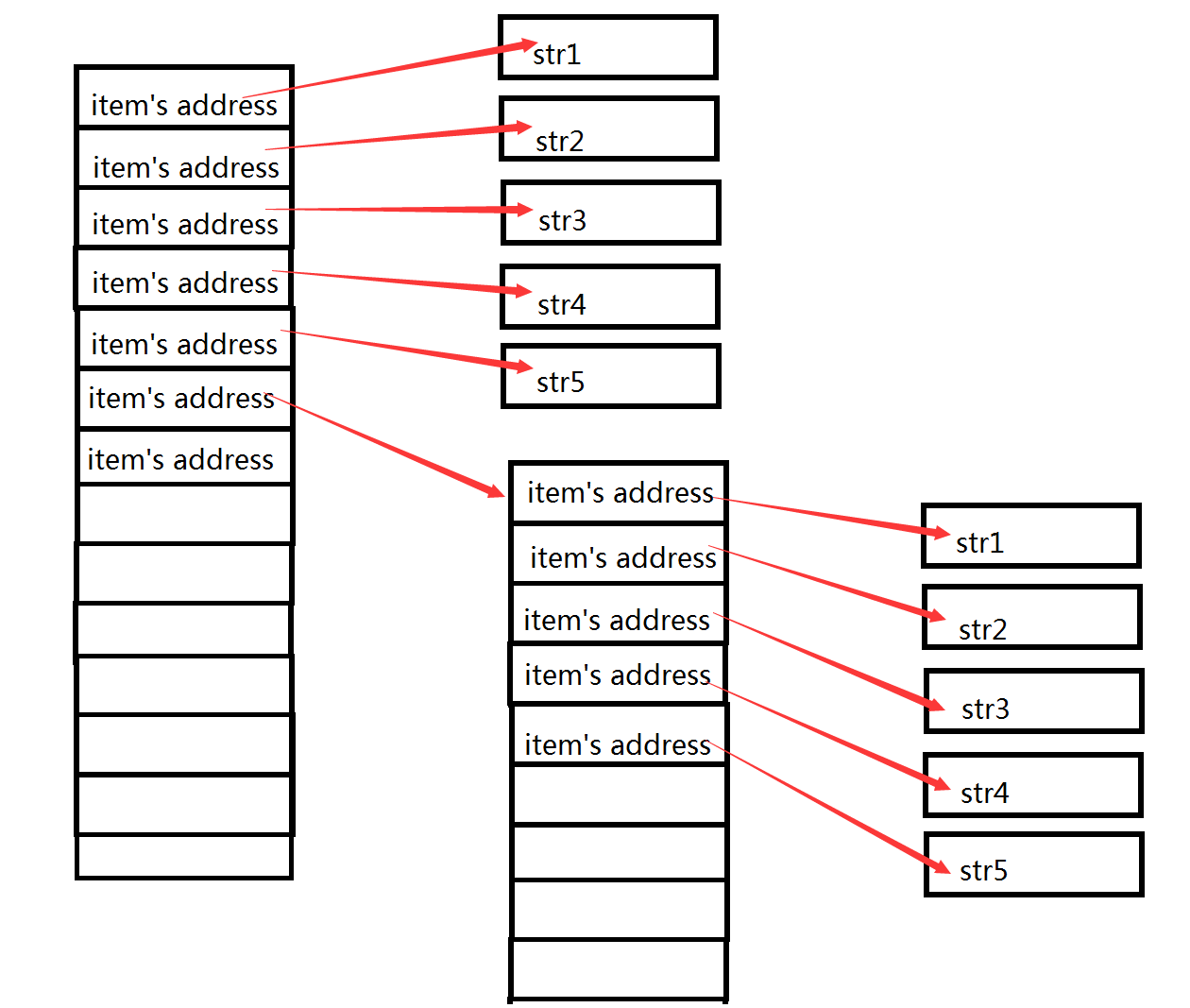
看上面两张图,我们加入左图表示的是一个列表sourcelist,sourcelist = [‘str1’,’str2’,’str3’,’str4’,’str5’,[‘str1’,’str2’,’str3’,’str4’,’str5’]];
右图在原有的基础上多出了一个浅拷贝的copylist,copylist = [‘str1’,’str2’,’str3’,’str4’,’str5’,[‘str1’,’str2’,’str3’,’str4’,’str5’]];
sourcelist和copylist表面上看起来一模一样,但是实际上在内存中已经生成了一个新列表,copy了sourceLst,获得了一个新列表,存储了5个字符串和一个列表所在内存的地址。
我们看下面分别对两个列表进行的操作,红色的框框里面是变量初始化,初始化了上面的两个列表;我们可以分别对这两个列表进行操作,例如插入一个值,我们会发现什么呢?如下所示:

从上面的代码我们可以看出,对于sourceLst和copyLst列表添加一个元素,这两个列表好像是独立的一样都分别发生了变化,但是当我修改lst的时候,这两个列表都发生了变化,这是为什么呢?我们就来看一张内存中的变化图:
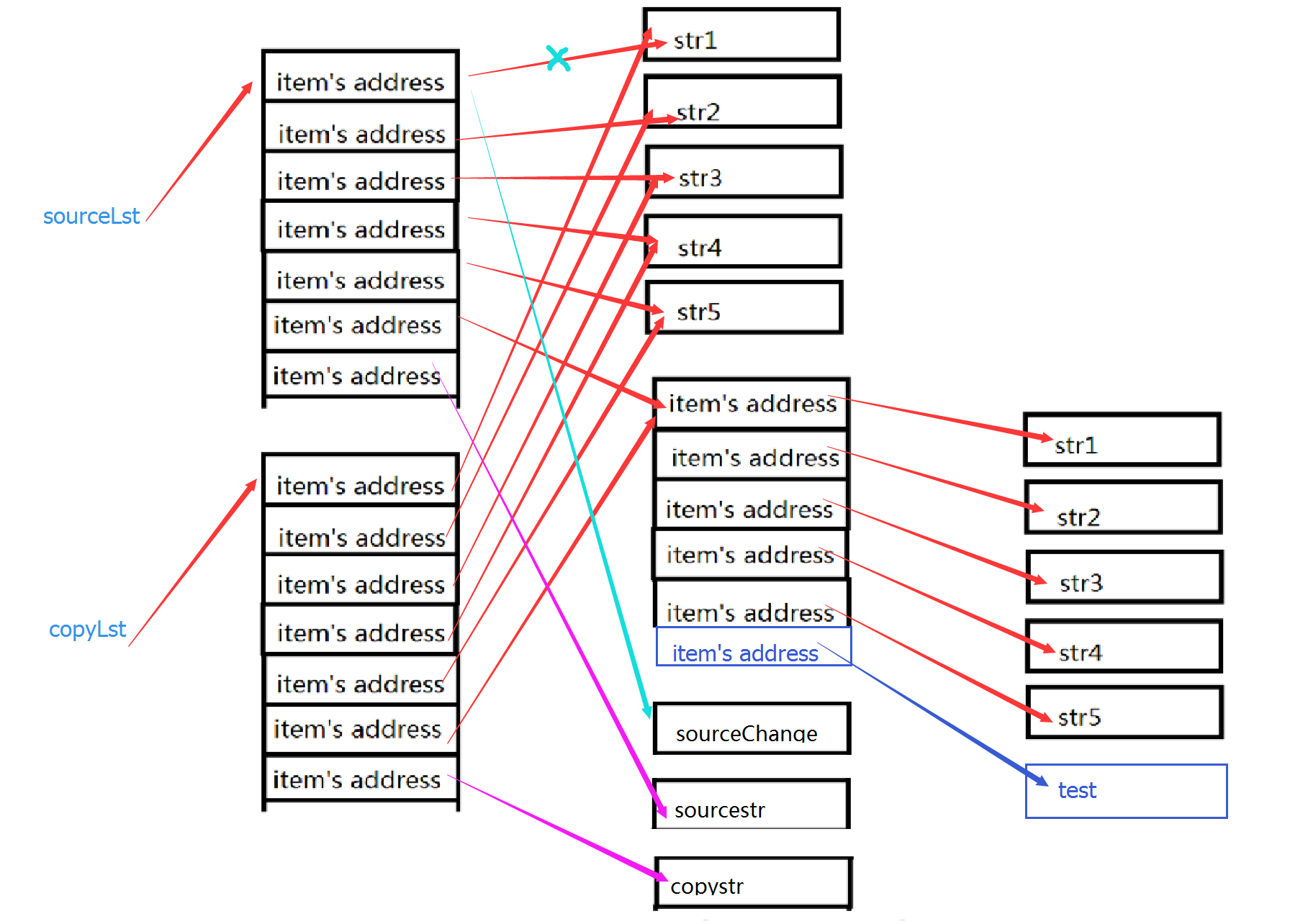
我们可以知道sourceLst和copyLst列表中都存储了一坨地址,当我们修改了sourceLst1的元素时,相当于用’sourceChange’的地址替换了原来’str1’的地址,所以sourceLst的第一个元素发生了变化。而copyLst还是存储了str1的地址,所以copyLst不会发生改变。
当sourceLst列表发生变化,copyLst中存储的lst内存地址没有改变,所以当lst发生改变的时候,sourceLst和copyLst两个列表就都发生了改变。
这种情况发生在字典套字典、列表套字典、字典套列表,列表套列表,以及各种复杂数据结构的嵌套中,所以当我们的数据类型很复杂的时候,用copy去进行浅拷贝就要非常小心。。。
深拷贝
刚刚我们了解了浅拷贝的意义,但是在写程序的时候,我们就是希望复杂的数据结构之间完全copy一份并且它们之间又没有一毛钱关系,应该怎么办呢?
我们引入一个深拷贝的概念,深拷贝——即python的copy模块提供的另一个deepcopy方法。深拷贝会完全复制原变量相关的所有数据,在内存中生成一套完全一样的内容,在这个过程中我们对这两个变量中的一个进行任意修改都不会影响其他变量。下面我们就来试验一下。
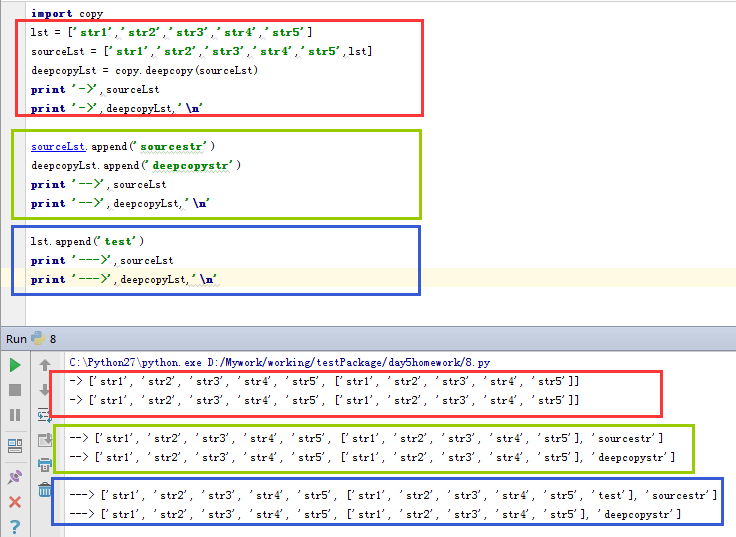
看上面的执行结果,这一次我们不管是对直接对列表进行操作还是对列表内嵌套的其他数据结构操作,都不会产生拷贝的列表受影响的情况。我们再来看看这些变量在内存中的状况:
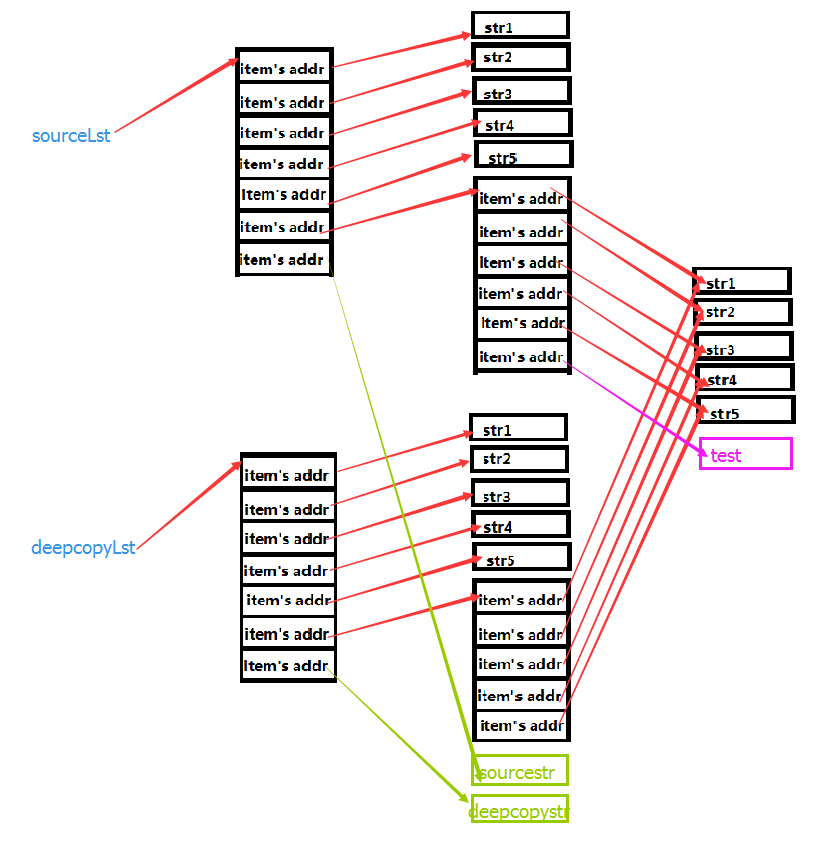
看了上面的内容,我们就知道了深拷贝的原理。其实深拷贝就是在内存中重新开辟一块空间,不管数据结构多么复杂,只要遇到可能发生改变的数据类型,就重新开辟一块内存空间把内容复制下来,直到最后一层,不再有复杂的数据类型,就保持其原引用。这样,不管数据结构多么的复杂,数据之间的修改都不会相互影响。这就是深拷贝~~~
关于copy()和deepcopy()的第二篇博客
其实呢,copy()与deepcopy()之间的区分必须要涉及到python对于数据的存储方式。
首先直接上结论:
—–我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
—–而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。
对于简单的 object,用 shallow copy 和 deep copy 没区别复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。
看不懂文字没关系我们来看代码:
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2可以看到 cop1,也就是 shallow copy 跟着 origin 改变了。而 cop2 ,也就是 deep copy 并没有变。
似乎 deep copy 更加符合我们对「复制」的直觉定义: 一旦复制出来了,就应该是独立的了。如果我们想要的是一个字面意义的「copy」,那就直接用 deep_copy 即可。
那么为什么会有 shallow copy 这样的「假」 copy 存在呢? 这就是有意思的地方了。
python的数据存储方式
Python 存储变量的方法跟其他 OOP 语言不同。它与其说是把值赋给变量,不如说是给变量建立了一个到具体值的 reference。
当在 Python 中 a = something 应该理解为给 something 贴上了一个标签 a。当再赋值给 a 的时候,就好象把 a 这个标签从原来的 something 上拿下来,贴到其他对象上,建立新的 reference。 这就解释了一些 Python 中可能遇到的诡异情况:
>> a = [1, 2, 3]
>>> b = a
>>> a = [4, 5, 6] //赋新的值给 a
>>> a
[4, 5, 6]
>>> b
[1, 2, 3]
# a 的值改变后,b 并没有随着 a 变
>>> a = [1, 2, 3]
>>> b = a
>>> a[0], a[1], a[2] = 4, 5, 6 //改变原来 list 中的元素
>>> a
[4, 5, 6]
>>> b
[4, 5, 6]
# a 的值改变后,b 随着 a 变了上面两段代码中,a 的值都发生了变化。区别在于,第一段代码中是直接赋给了 a 新的值(从 [1, 2, 3] 变为 [4, 5, 6]);而第二段则是把 list 中每个元素分别改变。
而对 b 的影响则是不同的,一个没有让 b 的值发生改变,另一个变了。怎么用上边的道理来解释这个诡异的不同呢?
首次把 [1, 2, 3] 看成一个物品。a = [1, 2, 3] 就相当于给这个物品上贴上 a 这个标签。而 b = a 就是给这个物品又贴上了一个 b 的标签。

第一种情况:
a = [4, 5, 6] 就相当于把 a 标签从 [1 ,2, 3] 上撕下来,贴到了 [4, 5, 6] 上。
在这个过程中,[1, 2, 3] 这个物品并没有消失。 b 自始至终都好好的贴在 [1, 2, 3] 上,既然这个 reference 也没有改变过。 b 的值自然不变。

第二种情况:
a[0], a[1], a[2] = 4, 5, 6 则是直接改变了 [1, 2, 3] 这个物品本身。把它内部的每一部分都重新改装了一下。内部改装完毕后,[1, 2, 3] 本身变成了 [4, 5, 6]。
而在此过程当中,a 和 b 都没有动,他们还贴在那个物品上。因此自然 a b 的值都变成了 [4, 5, 6]。
搞明白这个之后就要问了,对于一个复杂对象的浅copy,在copy的时候到底发生了什么?
再看一段代码:
>>> import copy
>>> origin = [1, 2, [3, 4]]
#origin 里边有三个元素:1, 2,[3, 4]
>>> cop1 = copy.copy(origin)
>>> cop2 = copy.deepcopy(origin)
>>> cop1 == cop2
True
>>> cop1 is cop2
False
#cop1 和 cop2 看上去相同,但已不再是同一个object
>>> origin[2][0] = "hey!"
>>> origin
[1, 2, ['hey!', 4]]
>>> cop1
[1, 2, ['hey!', 4]]
>>> cop2
[1, 2, [3, 4]]
#把origin内的子list [3, 4] 改掉了一个元素,观察 cop1 和 cop2学过docker的人应该对镜像这个概念不陌生,我们可以把镜像的概念套用在copy上面。
概念图如下:

copy对于一个复杂对象的子对象并不会完全复制,什么是复杂对象的子对象呢?就比如序列里的嵌套序列,字典里的嵌套序列等都是复杂对象的子对象。对于子对象,python会把它当作一个公共镜像存储起来,所有对他的复制都被当成一个引用,所以说当其中一个引用将镜像改变了之后另一个引用使用镜像的时候镜像已经被改变了。
所以说看这里的origin[2],也就是 [3, 4] 这个 list。根据 shallow copy 的定义,在 cop1[2] 指向的是同一个 list [3, 4]。那么,如果这里我们改变了这个 list,就会导致 origin 和 cop1 同时改变。这就是为什么上边 origin[2][0] = “hey!” 之后,cop1 也随之变成了 [1, 2, [‘hey!’, 4]]。
而deepcopy概念图如下:

deepcopy的时候会将复杂对象的每一层复制一个单独的个体出来。
这时候的 origin[2] 和 cop2[2] 虽然值都等于 [3, 4],但已经不是同一个 list了。即我们寻常意义上的复制。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186832.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
