大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
前言
数据可视化,是指将相对晦涩的的数据通过可视的、交互的方式进行展示,从而形象、直观地表达数据蕴含的信息和规律。
早期的数据可视化作为咨询机构、金融企业的专业工具,其应用领域较为单一,应用形态较为保守。步入大数据时代,各行各业对数据的重视程度与日俱增,随之而来的是对数据进行一站式整合、挖掘、分析、可视化的需求日益迫切,数据可视化呈现出愈加旺盛的生命力,表现之一就是视觉元素越来越多样,从朴素的柱状图/饼状图/折线图,扩展到地图、气泡图、树图、仪表盘等各式图形。表现之二是可用的开发工具越来越丰富,从专业的数据库/财务软件,扩展到基于各类编程语言的可视化库,相应的应用门槛也越来越低。
数据可视化,不仅仅是统计图表。本质上,任何能够借助于图形的方式展示事物原理、规律、逻辑的方法都叫数据可视化。
数据可视化不仅是一门包含各种算法的技术, 还是一个具有方法论的学科。一般而言,完整的可视化流程包括以下内容:
-
可视化输入:包括可视化任务的描述,数据的来源与用途,数据的基本属性、概念模型等;
-
可视化处理:对输入的数据进行各种算法加工,包括数据清洗、筛选、降维、聚类等操作,并将数据与视觉编码进行映射;
-
可视化输出:基于视觉原理和任务特性,选择合理的生成工具和方法,生成可视化作品。


实际上,从“数据可视化”的命名,便很容易看出数据可视化从业者如何开始可视化设计,那便是:处理数据,设计视觉,完成从数据空间到可视空间的映射, 必要时重复数据处理和图形绘制的循环组合。
1. 分析数据
首先,我们需要对数据做一个全面而细致的解读,数据的特点决定着可视化的设计原则。每项数据都有特定的属性(或称特征、维度)和对应的值,一组属性构成特征列表。按照属性的类型,数据可以分为数值型、有序型、类别型,数值型又可以进一步分为固定零点和非固定零点。其中,固定零点数据囊括了我们大多数的数据对象,它们都可以对应到数轴上的某个点;非固定零点主要包括以数值表示的特定含义,如表示地理信息的经纬度、表示日期的年月日等,在分析非固定零点数据时,我们更在意的是它们的区间。
在对数据做过预处理和分析之后,我们就能够观察出待处理数据的分布和维度,再结合业务逻辑和可视化目标,有可能还要对数据做某些变换,这些变换包括:
-
标准化,常用的手段包括(0,1)标准化或(-1,1)标准化,分别对应的是sigmoid函数和tanh函数,这么做的目的在于使数据合法和美观,但在这一过程中可能丢失影响数据分布、维度、趋势的信息,应该予以特别注意;
-
拟合/平滑,为表现数据变化趋势,使受众对数据发展有所预测,我们会引入回归来对数据进行拟合,以达到减少噪音,凸显数据趋势的目的;
-
采样,有些情况下,数据点过多,以至于不易可视化或者影响视觉体验,我们会使用随机采样的方法抽取部分数据点,抽样结果与全集近似分布,同时不影响可视化元素的对比或趋势;
-
降维,一般而言,同一可视化图表中能够承载的维度有限(很难超过3个维度),必须对整个数据集进行降维处理。
2. 可视化设计
在开始设计之前,我们需要对人类视觉以及注意力作简要分析,这决定着我们如何在第一时间抓住受众的注意力。
人类视觉感知到心理认知的过程要经过信息的获取、分析、归纳、解码、储存、概念、提取、使用等一系列加工阶段,每个阶段需要不同的人体组织和器官参与。简单来讲,人类视觉的特点是:
-
对亮度、运动、差异更敏感,对红色相对于其他颜色更为敏感;
-
对于具备某些特点的视觉元素具备很强的“脑补”能力,比如空间距离较近的点往往被认为具有某些共同的特点;
-
对眼球中心正面物体的分辨率更高,这是由于人类晶状体中心区域锥体细胞分布最为密集;
-
人们在观察事物时习惯于将具有某种方向上的趋势的物体视为连续物体;
-
人们习惯于使用“经验”去感知事物整体,而忽略局部信息。
这里引入一个概念——可视编码,它数据信息映射为可视化元素的技术,其通常具有表达直观、易于理解和记忆的特性。数据包含属性和值,相应可视编码也由两部分组成:标记和视觉通道,标记代表数据属性的分类,视觉通道表示人眼所能看到的各种元素的属性,包括大小、形状、颜色等,往往用来展示属性的定量信息。例如,对于柱状图而言,标记就是矩形,视觉通道就是矩形的颜色、高度或宽度等。
数据可视化的设计目标和制作原则在于信、达、雅,即一要精准展现数据的差异、趋势、规律,二要准确传递核心思想,三要简洁美观,不携带冗余信息。结合人的视觉特点,很容易总结出好的数据可视化作品的基本特征:
-
让用户的视线聚焦在可视化结果中最重要的部分;
-
对于有对比需求的数据,使用亮度、大小、形状来进行编码更佳;
-
使用尽量少的视觉通道编码数据,避免干扰信息。
3. 可视编码的选择
如同只学过视听语言并不能设计出可用的电影分镜一样,数据可视化这一艺术设计色彩浓厚的工作绝非做过几个饼图、柱状图就能胜任。在开始涉足实践讲解之前,我们需要解决以下疑问:
可视化设计中优先选择哪些视觉通道?有多少种视觉通道可供使用?某个视觉通道能编码什么信息,能包含多少信息量?视觉通道表达信息能力的区别?哪些视觉通道互不相关而哪些又相互影响?
看看下图,或许能从一定程度上给出答案:
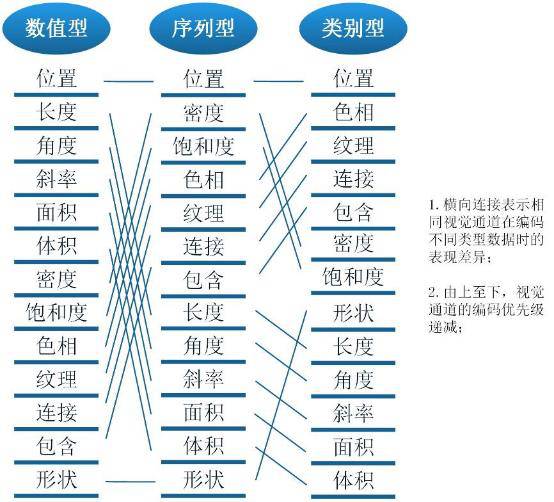
上图列举了数据可视化作品中常用的视觉编码通道,针对同种数据类型,采用不同的视觉通道带来的主观认知差异很大。数值型适合用能够量化的视觉通道表示,如坐标、长度等,使用颜色表示的效果就大打折扣,且容易引起歧义;类似地,序列型适合用区分度明显的视觉通道表示,类别型适合用易于分组的视觉通道。
需要指出的是,上图蕴含的理念可以应对绝大多数应用场景下可视化图形的设计“套路”,但数据可视化作为视觉设计的本质决定了“山无常势,水无常形”,任何可视化效果都拒绝生搬硬套,更不要说数据可视化的应用还要受到业务、场景和受众的影响。
4. 配色
相信每一个码农出身的数据分析师在做可视化设计时,都会对色彩如何搭配产生过困惑。色彩理论看起来简单却又乏味,用起来却不是那么得心应手。那么,如何让数据可视化作品简约、灵动、美观?下面介绍一些通用技巧。
1)色调与明度的跨度都要大
要确保配色非常容易辨识与区分,它们的明度差异一定要够大。明度差异需要全局考虑。但是,有一组明度跨度大的配色还不够。配色越多样,用户越容易将数据与图像联系起来。如果能善加利用色调的变化,就能使用户接受起来更加轻松。对于明度与色调,跨度越大,就能承载越多的数据。下图展示了相同色系下不同明度的色阶对比:

2)仿照自然的配色
各行各业的设计师都知道这个小秘密,对于数据可视化工程师而言,这招更是屡试不爽。一个简单有效的方法是:找出心仪的图片,比如唯美的风景照片,使用photoshop中“滤镜—马赛克—调整多边形形状和大小”即可看到该图片中包含的各种颜色,然后利用吸管工具选出几种颜色即可:


3)使用渐变
无论你需要2种颜色还是10种,渐变中都能提取出这些颜色,让可视化图表感觉自然,同时保有足够的色调与明度差异。一个使用渐变的好方法就是:在Photoshop中拉辅助线到断点位置,与数据的数量对应上,然后持续对渐变进行测试与调整。
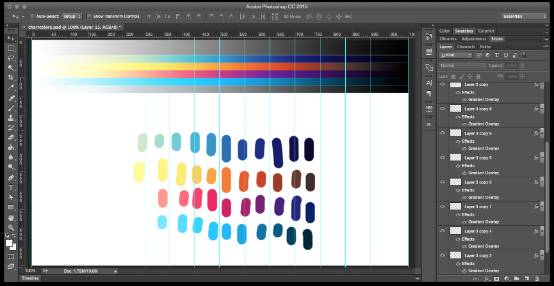
可以看到,配色表紧挨着顶部的灰度渐变,调整渐变叠加(之后就能得到精确的渐变色值),然后从那些断点处选取颜色,测试配色在实际运用中的效果。
4)使用配色工具
网上各种免费资源比比皆是,对于想设计出靓丽效果又无计可施的人而言,多参考以下这些工具是一个好办法:
-
ColorHunt——高质量配色方案,能够快速预览,如果你只需要4种颜色,这是绝佳的资源;
-
Kuler——photoshop配色工具,Adobe家出的,应该错不了;
-
Chroma.js——Chroma.js是一个微型的JavaScript库,适用于各种颜色处理的,可实现各种颜色的转换和色阶处理;
-
Color brewer——地图配色利器,如果你对基于地图的可视化配色方案感到困惑,这个在线工具应该能够帮到你。
此外,关于配色还有一些小技巧可供参考:遵循公司既定的品牌风格;根据数据描述的对象来定,如数据描述的是咖啡,则可以考虑使用咖色系;使用季节或者节日相关主题的色彩;如果你实在对颜色搭配感到头疼,那就多使用万能的“灰色”和阴影。
统计图表
统计图表是使用最早的可视化图形,在数百年的进化过程中,逐渐形成了基本“套路”,符合人类感知和认知,进而被广泛接受。
常见于各种分析报告的有柱状图、折线图、饼图、散点图、气泡图、雷达图,对于这些最常用的图表类型,下表可以为你指明大致方向:
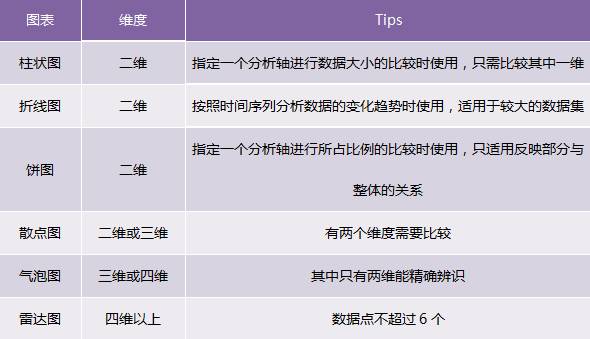
我们在制作可视化图表时,首先要从业务出发,优先挑选合理的、符合惯例的图表,尤其是如果你的用户层次比较多样的情况下,请兼顾各个年龄段或者不同认知能力的用户的需求;其次是根据数据的各种属性和统计图表的特点来选择,例如饼图并不适合用作展示绝对数值,只适用于反映各部分的比例。对于常用图表,带着目的出发,遵循各种约束,相信你能找到合适的图表:
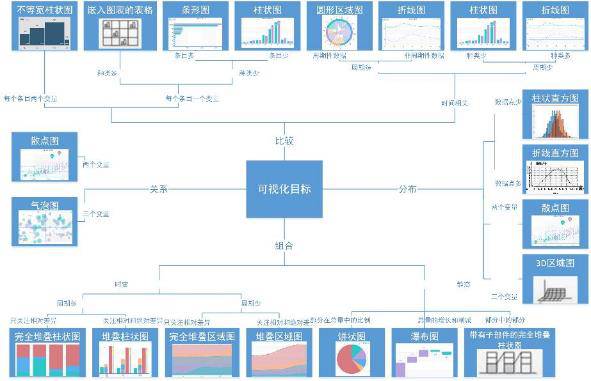
除了常用的图表之外,可供我们选择的还有:
-
漏斗图:漏斗图适用于业务流程比较规范、周期长、环节多的流程分析,通过漏斗各环节业务数据的比较,能够直观地发现和说明问题所在。
-
(矩形)树图:一种有效的实现层次结构可视化的图表结构,适用于表示类似文件目录结构的数据集;
-
热力图:以特殊高亮的形式显示访客热衷的页面区域和访客所在的地理区域的图示,它基于GIS坐标,用于显示人或物品的相对密度;
-
关系图:基于3D空间中的点—线组合,再加以颜色、粗细等维度的修饰,适用于表征各节点之间的关系;
-
词云:各种关键词的集合,往往以字体的大小或颜色代表对应词的频次;
-
桑基图:一种有一定宽度的曲线集合表示的图表,适用于展现分类维度间的相关性,以流的形式呈现共享同一类别的元素数量,比如展示特定群体的人数分布等;
-
日历图:顾名思义,以日历为基本维度的对单元格加以修饰的图表。
数据可视化的工具
新型的数据可视化产品层出不穷,基本上各种语言都有自己的可视化库,传统数据分析及BI软件也都扩展出一定的可视化功能,再加上专门的用于可视化的成品软件,我们的可选范围实在是太多了。那么,我们要选择的可视化工具,必须满足互联网爆发的大数据需求,必须快速的收集、筛选、分析、归纳、展现决策者所需要的信息,并根据新增的数据进行实时更新。
-
实时性:数据可视化工具必须适应大数据时代数据量的爆炸式增长需求,必须快速的收集分析数据、并对数据信息进行实时更新;
-
简单操作:数据可视化工具满足快速开发、易于操作的特性,能满足互联网时代信息多变的特点;
-
更丰富的展现:数据可视化工具需具有更丰富的展现方式,能充分满足数据展现的多维度要求;
-
多种数据集成支持方式:数据的来源不仅仅局限于数据库;很多数据可视化工具都支持团队协作数据、数据仓库、文本等多种方式,并能够通过互联网进行展现。
数据可视化主要通过编程和非编程两类工具实现。主流编程工具包括以下三种类型:从艺术的角度创作的数据可视化,比较典型的工具是 Processing,它是为艺术家提供的编程语言;从统计和数据处理的角度,既可以做数据分析,又可以做图形处理,如R,SAS;介于两者之间的工具,既要兼顾数据处理,又要兼顾展现效果,D3.js、Echarts都是很不错的选择,二者这种基于Javascript的数据可视化工具更适合在互联网上互动的展示数据。
1. 入门级
入门级的意思是该工具是可视化工作者必须掌握的技能,难度不一定小、门槛也不一定低。相反,对于可视化大拿来说,这些工具依旧起到四两拨千斤的妙用。
-
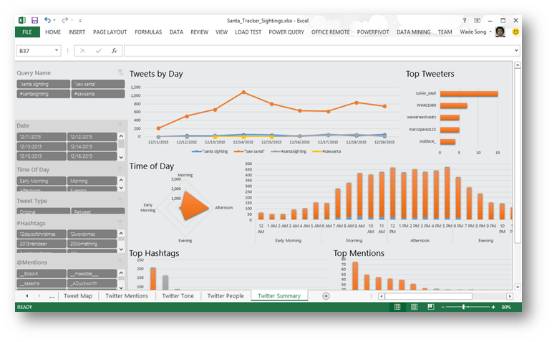
Excel
别以为EXCEL只会处理表格,你可以把它当成数据库,也可以把它当成IDE,甚至可以把它当成数据可视化工具来使用。它可以创建专业的数据透视表和基本的统计图表,但由于默认设置了颜色、线条和风格,使其难以创建用于看上去“高大上”视觉效果。尽管如此,我仍然推荐你使用Excel。
-
Tableau
相信每一个接触到数据可视化的人都听说过Tableau,它需要一些结构化的数据, 也需要你懂一些BI。 它不需要编程,而仅仅通过简单的拖拽操作即可完成惊艳的效果。对比Excel,它是专业应对数据可视化方案的利器,主要表现在数据可视化、聚焦/深挖、灵活分析、交互设计等功能。Tableau最大的缺点在于它是商业软件,个人使用的话只有14天的免费期,而官方售价不菲。
2. 在线数据可视化
-
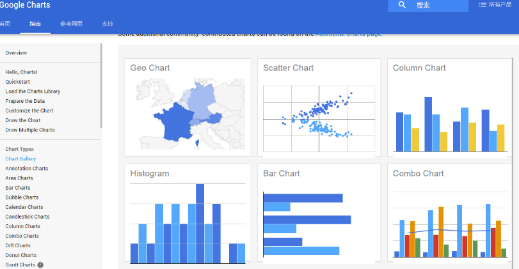
Google Charts
Google Charts是一个免费的开源js库,使用起来非常简单,只需要在script标签中将src指向https://www.gstatic.com/charts/loader.js然后即可开始绘制。它支持HTML5/SVG,可以跨平台部署,并特意为兼容旧版本的IE采用了vml。
在新版google charts 发布之前,google有个类似的产品叫做Google Charts API,不同之处在于后者使用http请求的方式将参数提交到api,而后接口返回一张png图片。如打开http://chart.proxy.ustclug.org/chart?cht=bvg&chs=250×150&chd=s:Monkeys&chxt=x,y&chxs=0,ff0000,12,0,lt|1,0000ff,10,1,lt,即可显示下图:
-
Flot
Flot是一个很棒的线图和条形图创建工具,可以运用于支持canvas的所有浏览器——意味着大多数主流浏览器。这是一个jQuery库,如果你已经熟悉jQuery,你就可以容易的对图像进行回调、风格和行为操作。 浮悬的优点是你可以访问大量的调用函数,这样就可以运行你自己的代码。设定一种风格,可以让在用户悬停鼠标、点击、移开鼠标时展示不同的效果。比起其他制图工具,浮悬给予你更多的灵活空间。浮悬提供的选项不多,但它可以很好地执行常见的功能。
-
D3
D3(Data Driven Documents)是支持SVG渲染的另一种JavaScript库。但是D3能够提供大量线性图和条形图之外的复杂图表样式,例如Voronoi图、树形图、圆形集群和单词云等。D3.js是数据驱动文件(Data-Driven Documents)的缩写,他通过使用HTML\CSS和SVG来渲染精彩的图表和分析图。D3对网页标准的强调足以满足在所有主流浏览器上使用的可能性,使你免于被其他类型架构所捆绑的苦恼,它可以将视觉效果很棒的组件和数据驱动方法结合在一起。
-
Echarts
百度出品的优秀产品之一,也是国内目前开源项目中少有的精品。一个纯 Javascript 的图表库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器,底层依赖轻量级的 Canvas 类库 ZRender,提供直观,生动,可交互,可高度个性化定制的数据可视化图表。3.0版本中更是加入了更多丰富的交互功能以及更多的可视化效果,并且对移动端做了深度的优化。Echarts最令人心动的是它丰富的图表类型,以及极低的上手难度。
-
Highcharts
在Echarts出现之初,功能还不是那么完善,可视化工作者往往会选择HighCharts。Highcharts 系列软件包含 Highcharts JS,Highstock JS,Highmaps JS 共三款软件,均为纯 JavaScript 编写的 HTML5 图表库。Highcharts 是一个用纯 JavaScript 编写的一个图表库, 能够很简单便捷的在 Web 网站或是 Web 应用程序添加有交互性的图表。Highstock 是用纯 JavaScript 编写的股票图表控件,可以开发股票走势或大数据量的时间轴图表,Highmaps 是一款基于 HTML5 的优秀地图组件。
-
R
严格来说,R是一种数据分析语言,与matlab、GNU Octave并列。然而ggplot2的出现让R成功跻身于可视化工具的行列,作为R中强大的作图软件包,ggplot2牛在其自成一派的数据可视化理念。它将数据、数据相关绘图、数据无关绘图分离,并采用图层式的开发逻辑,且不拘泥于规则,各种图形要素可以自由组合。当熟悉了ggplot2的基本套路后,数据可视化工作将变得非常轻松而有条理。
-
DataV
阿里出品的数据可视化解决方案,之所以推荐DataV这个后起之秀,完全是因为淘宝双“11”活动中实时互动大屏幕太抢眼了。DataV支持多种数据源,尤其是和阿里系各种数据库完美衔接,如果你的数据本身就存在阿里云上,那选用DataV肯定是个省时省力的好办法。图表方面,DataV内置了丰富的图表模板,支持实时数据采集和解析。
3. 类GUI数据可视化
-
Crossfilter
Crossfilter 是一个用来展示大数据集的 JavaScript 库,它可以把数据可视化和GUI控件结合起来,按钮、下拉和滑块演变成更复杂的界面元素,使你扩展内容,同时改变输入参数和数据。交互速度超快,甚至在上百万或者更多数据下都很快。Crossfilter也是一种JavaScript库,它可以在几乎不影响速度的前提下对数据创建过滤器,将过滤后的数据用于展示,且涉及有限维度,因此可以完成对海量数据集的筛选与加载。
4. 进阶工具
-
Processing
Processing 是用 Java 编程语言写的,并且 Java 语言也是在语言树中最接近 Processing 的。所以,如果您熟悉 C 或 Java 语言,Processing 将很容易学。Processing 并不包括 Java 语言的一些较为高级的特性,但这些特性中的很多特性均已集成到了 Processing。如今,围绕它已经形成了一个专门的社区(https://www.openprocessing.org),致力于构建各种库以供用这种语言和环境进行动画、可视化、网络编程以及很多其他的应用。
Processing 是一个很棒的进行数据可视化的环境,具有一个简单的接口、一个功能强大的语言以及一套丰富的用于数据以及应用程序导出的机制。

-
Weka
Weka是一个能根据属性分类和集群大量数据的优秀工具,Weka不但是数据分析的强大工具,还能生成一些简单的图表。weka首先是一个数据挖掘的利器,它能够快速导入我们的结构化数据,然后对数据属性做分类、聚类分析,帮助我们理解数据。但他的可视化功能同样不逊色,选择界面中的visualization,你会立刻明白:是它让你理解数据,然后你才让用户可视化数据。
结语
我们所处的这个时代,是一个知识大爆发的时代。仅就编程这项技能来说,现在几乎人人都能写上一两行,程序员这个群体也比十年前有了更多维度上的扩展。各种工具的使用门槛越来越低,带来的是行业壁垒日渐消弭。会用某种可视化手段,并不是区分小白与专家的唯一标准,笔者曾听说有人拿unity、易语言这样的神器来实现可视化。所以,眼花缭乱的工具永远只是辅助,真正决定你在可视化道路上走多远的,是你对可视化理念的准确把握和执着坚守。
参考资料:
1. 清华大学数据可视化课程讲义——张松海
2.《基本图表的特点和适用场合》
3.《20 款数据可视化工具》
4.《50个大数据可视化分析工具》
END
转自:数据派THU 公众号;本文获授权;
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
关联阅读
原创系列文章:
数据运营 关联文章阅读:
数据分析、数据产品 关联文章阅读:
80%的运营注定了打杂?因为你没有搭建出一套有效的用户运营体系
商务合作|约稿 请加qq:365242293
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186782.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
