大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
ByteBuffer是NIO里用得最多的Buffer,它包含两个实现方式:HeapByteBuffer是基于Java堆的实现,而DirectByteBuffer则使用了unsafe的API进行了堆外的实现。这里只说HeapByteBuffer。
在NIO中,数据的读写操作始终是与缓冲区相关联的.读取时信道(SocketChannel)将数据读入缓冲区,写入时首先要将发送的数据按顺序填入缓冲区.缓冲区是定长的,基本上它只是一个列表,它的所有元素都是基本数据类型.ByteBuffer是最常用的缓冲区,它提供了读写其他数据类型的方法,且信道的读写方法只接收ByteBuffer.因此ByteBuffer的用法是有必要牢固掌握的.
1.创建ByteBuffer
1.1 使用allocate()静态方法
ByteBuffer buffer=ByteBuffer.allocate(256);
以上方法将创建一个容量为256字节的ByteBuffer,如果发现创建的缓冲区容量太小,唯一的选择就是重新创建一个大小合适的缓冲区.
1.2 通过包装一个已有的数组来创建
如下,通过包装的方法创建的缓冲区保留了被包装数组内保存的数据.
ByteBuffer buffer=ByteBuffer.wrap(byteArray);
如果要将一个字符串存入ByteBuffer,可以如下操作:
String sendString=”你好,服务器. “;
ByteBuffer sendBuffer=ByteBuffer.wrap(sendString.getBytes(“UTF-16”));
2.回绕缓冲区
buffer.flip();
这个方法用来将缓冲区准备为数据传出状态,执行以上方法后,输出通道会从数据的开头而不是末尾开始.回绕保持缓冲区中的数据不变,只是准备写入而不是读取.
3.清除缓冲区
buffer.clear();
这个方法实际上也不会改变缓冲区的数据,而只是简单的重置了缓冲区的主要索引值.不必为了每次读写都创建新的缓冲区,那样做会降低性能.相反,要重用现在的缓冲区,在再次读取之前要清除缓冲区.
4.从套接字通道(信道)读取数据
int bytesReaded=socketChannel.read(buffer);
执行以上方法后,通道会从socket读取的数据填充此缓冲区,它返回成功读取并存储在缓冲区的字节数.在默认情况下,这至少会读取一个字节,或者返回-1指示数据结束.
5.向套接字通道(信道)写入数据
socketChannel.write(buffer);
此方法以一个ByteBuffer为参数,试图将该缓冲区中剩余的字节写入信道.
———————–
ByteBuffer俗称缓冲器, 是将数据移进移出通道的唯一方式,并且我们只能创建一个独立的基本类型缓冲器,或者使用“as”方法从 ByteBuffer 中获得。ByteBuffer 中存放的是字节,如果要将它们转换成字符串则需要使用 Charset , Charset 是字符编码,它提供了把字节流转换成字符串 ( 解码 ) 和将字符串转换成字节流 ( 编码) 的方法。
private byte[] getBytes (char[] chars) {//将字符转为字节(编码)
Charset cs = Charset.forName (“UTF-8”);
CharBuffer cb = CharBuffer.allocate (chars.length);
cb.put (chars);
cb.flip ();
ByteBuffer bb = cs.encode (cb)
return bb.array();
}
private char[] getChars (byte[] bytes) {//将字节转为字符(解码)
Charset cs = Charset.forName (“UTF-8”);
ByteBuffer bb = ByteBuffer.allocate (bytes.length);
bb.put (bytes);
bb.flip ();
CharBuffer cb = cs.decode (bb);
return cb.array();
}
通道也就是FileChannel,可以由FileInputStream,FileOutputStream,RandomAccessFile三个类来产生,例如:FileChannel fc = new FileInputStream().getChannel();与通道交互的一般方式就是使用缓冲器,可以把通道比如为煤矿(数据区),而把缓冲器比如为运煤车,想要得到煤一般都通过运煤车来获取,而不是直接和煤矿取煤。用户想得到数据需要经过几个步骤:
一、用户与ByteBuffer的交互
向ByteBuffer中输入数据,有两种方式但都必须先为ByteBuffer指定容量
ByteBuffer buff = ByteBuffer.allocate(BSIZE);
a) buff = ByteBuffer.wrap(“askjfasjkf”.getBytes())注意:wrap方法是静态函数且只能接收byte类型的数据,任何其他类型的数据想通过这种方式传递,需要进行类型的转换。
b) buff.put();可以根据数据类型做相应调整,如buff.putChar(chars),buff.putDouble(double)等
二、FileChannel 与 ByteBuffer的交互:
缓冲器向通道输入数据
FileChannel fc = new FileInputStream().getChannel();
fc.write(buff);
fc.close();
三、 用户与ByteBuffer交互
通道向缓冲器送入数据
FileChannel fc = new FileOutputStream().getChannel();
fc.read( buff);
fc.flip();
四、呈现给用户(三种方式)
1)String encoding = System.getProperty(“file.encoding”);
System.out.println(“Decoded using ” + encoding + “: ” + Charset.forName(encoding).decode(buff));
2)System.out.println(buff.asCharBuffer());//这种输出时,需要在输入时就进行编码getBytes(“UTF-8”)
3) System.out.println(buff.asCharBuffer());//通过CharBuffer向ByteBuffer输入 buff.asCharBuffer().put。
fc.rewind();
附录上图帮助大家理解:
使用
ByteBuffer最核心的方法是put(byte)和get()。分别是往ByteBuffer里写一个字节,和读一个字节。
值得注意的是,ByteBuffer的读写模式是分开的,正常的应用场景是:往ByteBuffer里写一些数据,然后flip(),然后再读出来。
这里插两个Channel方面的对象,以便更好的理解Buffer。
ReadableByteChannel是一个从Channel中读取数据,并保存到ByteBuffer的接口,它包含一个方法:
1 |
public int read(ByteBuffer dst) throws IOException; |
WritableByteChannel则是从ByteBuffer中读取数据,并输出到Channel的接口:
1 |
public int write(ByteBuffer src) throws IOException; |
那么,一个ByteBuffer的使用过程是这样的:
1 |
byteBuffer = ByteBuffer.allocate(N); |
2 |
//读取数据,写入byteBuffer |
3 |
readableByteChannel.read(byteBuffer); |
4 |
//变读为写 |
5 |
byteBuffer.flip(); |
6 |
//读取byteBuffer,写入数据 |
7 |
writableByteChannel.write(byteBuffer); |
看到这里,一般都不太明白flip()干了什么事,先从ByteBuffer结构说起:
ByteBuffer内部字段
byte[] buff
buff即内部用于缓存的数组。
position
当前读取的位置。
mark
为某一读过的位置做标记,便于某些时候回退到该位置。
capacity
初始化时候的容量。
limit
读写的上限,limit<=capacity。
图解
put
写模式下,往buffer里写一个字节,并把postion移动一位。写模式下,一般limit与capacity相等。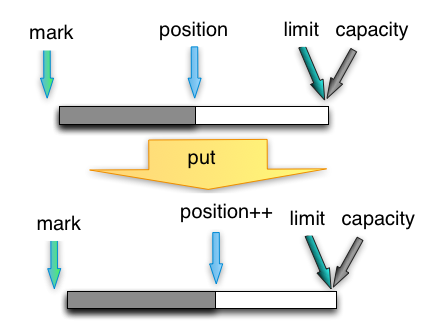
flip
写完数据,需要开始读的时候,将postion复位到0,并将limit设为当前postion。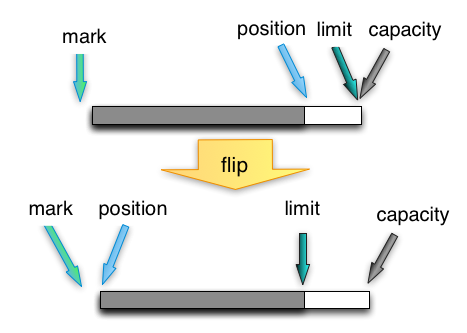
get
从buffer里读一个字节,并把postion移动一位。上限是limit,即写入数据的最后位置。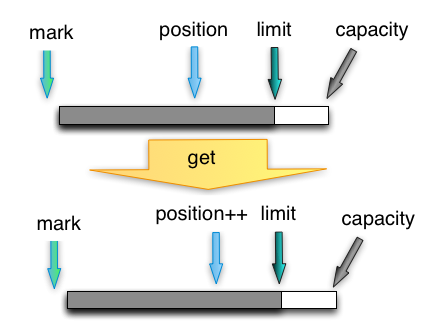
clear
将position置为0,并不清除buffer内容。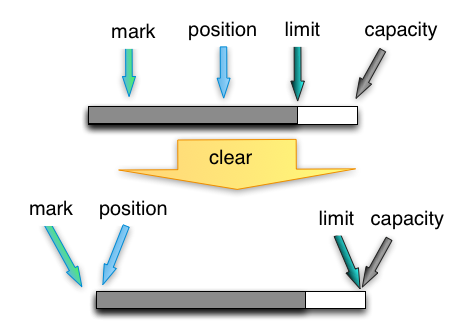
mark相关的方法主要是mark()(标记)和reset()(回到标记),比较简单,就不画图了。
实例实战:
import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.nio.ByteBuffer;import java.nio.channels.FileChannel;public class ChannelCopy { public static final int BSIZE = 1024; /** * @param args * @throws Exception */ public static void main(String[] args) throws Exception { String arg1 = "E:/test/in.txt"; String arg2 = "E:/test/out.txt"; FileChannel inChannel = new FileInputStream(new File(arg1)).getChannel(); FileChannel outChannel = new FileOutputStream(new File(arg2),false).getChannel();//false:覆盖写,true:追加写 ByteBuffer buffer = ByteBuffer.allocate(BSIZE); while(inChannel.read(buffer)!=-1) { buffer.flip();//一定要加上 ,read操作后需要次方法 outChannel.write(buffer); buffer.clear();/一定要加上,如果read一次后,还需要对缓冲区进一步read,那么也必须要加上次方法 } System.out.println("Sucess!"); }}


这个程序很简单,就不要做过多的介绍,但是需要注意的是,是最后几行代码。
1)一旦调用read来告知FileChannel向ByteBuffer存储字节,那就必须调用缓冲区的flip方法,让别人做好读取字节的准备,在上述程序中,如果没有flip()方法,那么就无法把内容写到目标文件中(其实写了,但是内容是空白)。为什么会出现这种情况呢,下面是加上flip()方法和没有加上flip()方法ByteBuffer对象的状态。
java.nio.HeapByteBuffer[pos=0 lim=21 cap=1024] (加上flip()方法)
java.nio.HeapByteBuffer[pos=21 lim=1024 cap=1024](没有加上flip()方法)
我们可以很清楚的看到,如果不加上flip方法,那么读取的内容其实是缓冲区当前位置往后的内容(之后的内容当然是空白了,缓冲区还没数据写到那呢。),而真正的内容应该是当前位置之前的内容。 个人觉得read操作后,必须就跟上flip()方法。
2)write()操作后,信息仍然在缓冲区中,接着clear()操作会重新设置缓冲区内部的指针,以便缓冲区在另一个read()操作期间能够做好接受数据的准备。换句话说,如果我们打算使用缓冲区执行进一步的read()操作,我们也必须得调用clear()方法来为每个read()做好准备。为什么?我代码没有跟下去,如果没有clear()方法,inChnanel.read(buffer)会一直等于0,导致了死循环,有高人解释下为什么?
ByteBuffer缓冲区的细节
1)ByteBuffer是唯一能将数据写入或读出的方式,我们只能使用通过创建一个独立的基本类型缓冲器,或者使用“as”方法从ByteBuffer中获得。也就说,我们不能
把基本类型的缓冲器转换成ByteBuffer(这个其实看源码就知道了,他们直接表示继承关系,不能强制转化)
2)Buffer由数据和可以高效地访问及操纵这些数据的四个索引组成,这四个索引分别是:mark(标记,其实我没明白这个的作用),position(位置),limit(界限),capacity(容量)。下面是用于设置和复位索引以及查询它们值的方法。
| capacity() | 返回缓冲区容量 |
| clear() | 清空缓冲区,将position置为0,limit设置为容量大小(其实数据并没有清楚,只是次方法后,每次重头开始写入数据,覆盖了原有数据) |
| flip() | 将limit置为position,position置为0. |
| limit() | 返回limit值 |
| limit(int lim) | 设置limit值 |
| mark() | 将mark设置为position |
| position() | 返回position的值 |
| position(int pos) | 设置position的值 |
| remaining() | 返回(limit-position) |
| hasRemaining() | return position < limit; |
| reset() | 把postion设置为mark |
内存映射文件
内存映射文件允许我们创建和修改那些因为太大而不能放入内存的文件,有了内存映射文件,我们就可以假定整个文件都在内存中,而且完全可以把他们当做非常大的数组来访问。
我们可以看到ByteBuffer是一个abstract class.其有两个子类,一个是HeapByteBuffer,我们之前将的nio的操作,就是通过其来实现的。另一个就是MappedByteBuffer这个就是我们内存映射文件需要用到的。我们看到在FileChannel有一个map方法,如下所示,该方法就可以得到相应的MappedByteBuffer
* @see java.nio.channels.FileChannel.MapMode * @see java.nio.MappedByteBuffer */ public abstract MappedByteBuffer map(MapMode mode, long position, long size) throws IOException; //mode = FileChannel.MapMode.READ_WRITE等等,position = 映射文件的起始位置,size = 映射区域大小
注意:“映射读”可以通过FileInpuStream.getChannel().map()来处理,但是”映射写(读写)“ 必须得用RandomAccesssFile().getChannel().map(),而不能通过FileOutputStream得到缓冲器。
补充内容:
不同的机器可能会使用不同的字节排序方法来存储数据,”big endian”(高位优先)将最重要的字节地址存放地址最低的存储器单元( 最低地址存放高位字节),”big endian”存放方式正是我们的书写方式,大数先写(比如,总是按照千、百、十、个位来书写数字)。而“little endian”(低位优先)则是将最重要的字节放在地址最高的存储单元( 最低地址存放低位字节)。当存储量大雨一个字节是(如short,int,float)就要考虑字节的顺序问题了。ByteBuffer是以高位优先的形式存储数据的,但是可以通过order()方法来改变顺序。参数是ByteOrder.BIG_ENDIAN ,ByteOrder.LITTLE_ENDIAN。
看下面的例子
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
如果我们以short方式读取数据
1)以默认的高位优先方式:则得到的数字时97(二进制为00000000 01100001)
2)低位优先的方式,则得到的数字是24832(二进制为01100001 00000000)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186773.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
