大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
为什么会在RocketMQ系列里面参杂一篇ByteBuffer的文章呢?因为RocketMQ存储消息,是存储在文件中的,而且刚好使用的是ByteBuffer。这个属于Java NIO的内容,平时用到的非常少,如果像我一样没有相关的知识做铺垫,强行看RocketMQ消息存储相关的代码会比较头疼。为了减少学习难度,这里很有必要先介绍一下ByteBuffer相关的知识。
Buffer就是缓冲区的意思。如果数据直接来了就写入磁盘,那么肯定I/O操作太频繁,效率上不去。如果先写入缓冲区,等缓冲区数据量够了再一次性写入磁盘,是不是就好多了。
ByteBuffer就是存放字节的缓冲区。ByteBuffer继承了Buffer类,主要属性如下所示:
private int mark = -1; // 标记位,配合mark()和reset()方法使用,可以记录某一次访问的位置。
private int position = 0; // 访问位置,每访问一个byte就+1
private int limit; // 读写限制位置,ByteBuffer的读写都不能超过这个位置
private int capacity; // 容量,初始化后就不会再变了
long address; // 访问地址,仅仅针对DirectByteBuffer,使用的是堆外内存。
final byte[] hb; // 堆内内存时存放的内容
final int offset; // 偏移量,使用byte数组初始化ByteBuffer时,数组的偏移量
boolean isReadOnly; // 是否只读
上面的属性没有完全理解,也没有关系,后面会再次涉及到的,有个初步印象即可。
初始化
虽然ByteBuffer有构造函数,但是我们一般不用,转而使用ByteBuffer下面的几个静态函数来构造ByteBuffer对象。
/** * 分配一个使用堆外内存的ByteBuffer */
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
/**分配一个堆内内存的ByteBuffer*/
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
/**把给定的byte数组包装成一个byteBuffer*/
public static ByteBuffer wrap(byte[] array,
int offset, int length)
{
try {
return new HeapByteBuffer(array, offset, length);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}
/**同上*/
public static ByteBuffer wrap(byte[] array) {
return wrap(array, 0, array.length);
}
例如:
final int CAPACITY = 1024 * 1024 * 50;
ByteBuffer byteBufferHeap = ByteBuffer.allocate(CAPACITY);
ByteBuffer byteBufferDirect = ByteBuffer.allocateDirect(CAPACITY);
byte[] array = new byte[]{
1,2,3};
ByteBuffer byteBuffer = ByteBuffer.wrap(array);
基本读写操作
下面是Thinking in java中关于缓冲器(ByteBuffer,又叫缓冲区)和通道(Channel)之间关系的描述:


从上述描述中,我们大致可以认为文件资源可以转换成一个通道,然后通过ByteBuffer读写文件。下面是一个简单的文件读取到byteBuffer的例子:
public static void main(String[] args) throws Exception {
String path = "d:" + File.separator + "bill"; // 文件内容是"abcdefg1234567890"
FileInputStream fileInputStream = new FileInputStream(path);
FileChannel fileChannel = fileInputStream.getChannel(); // 我们可以通过FileInputStream和FileOutPutStream提供FileChannel对象。
final int CAPACITY = 20; // 容量20个字节
ByteBuffer byteBufferHeap = ByteBuffer.allocate(CAPACITY);
fileChannel.read(byteBufferHeap); // 读取文件到缓冲区
System.out.println(byteBufferHeap.position()); // 结果是17,读一个byte,position+1
System.out.println(byteBufferHeap.capacity()); // 结果是20
System.out.println(byteBufferHeap.limit()); // 结果是20
byteBufferHeap.flip();// flip(翻转)操作会将当前position记录到limit中, 然后position翻转指回0,mark置为-1.
// byteBufferHeap.clear(); // 后面会讲解
System.out.println(byteBufferHeap.position()); // 结果是0
System.out.println(byteBufferHeap.capacity()); // 容量不变,还是20
System.out.println(byteBufferHeap.limit()); // 结果17
while(byteBufferHeap.hasRemaining()){
// 如果Postion和limit之间还有元素
System.out.print((char)byteBufferHeap.get());
}
fileChannel.close();
}
下面来一个简单的byteBuffer写文件例子:
public static void main(String[] args) throws Exception{
String content = "我是内容";
ByteBuffer byteBufferHeap = ByteBuffer.wrap(content.getBytes("UTF-8")); // 通过warp创建ByteBuffer
String path = "d:" + File.separator + "out.txt";
FileChannel fileChannel = new FileOutputStream(path).getChannel();
fileChannel.write(byteBufferHeap); // 把ByteBuffer内容写入channel
String append = "我是追加内容";
fileChannel.position(fileChannel.size());// 移动到文件尾
fileChannel.write(ByteBuffer.wrap(append.getBytes("UTF-8")));
fileChannel.close();
}
flip()和clear()
flip(翻转)操作会将当前position记录到limit中, 然后position翻转指回0,mark置为-1。而clear操作则将limit重置为capacity,position重置为0,mark置为-1。
这里的clear是一种逻辑上的清除操作,内容并没有真的消除。例如上面的读例子中,我们将 byteBufferHeap.flip();替换为 byteBufferHeap.clear();运行结果如下:

我们可以看到,内容仍然可以读取出来。使用clear的目的是方便我们重新读取数据到ByteBuffer中。当我们理解了flip()和clear()的意思之后,我们才知道什么时候该用哪个方法:
当我们第一次读取Channel内容到ByteBuffer中的时候,这时position已经是读取的长度,为了获取ByteBuffer的内容,我们需要flip()一下,使得position重新回到0,然后就可以读取ByteBuffer中的内容了。当我们需要向ByteBuffer重新写内容的时候(覆盖),我们需要clear()一下,然后读取Channel内容到ByteBuffer中。
当我们需要将ByteBuffer的内容写回Channel的时候,我们需要flip()一下,然后写入Channel。写Channel的时候,clear()没什么使用场景。
为什么需要flip()这么奇怪的方法呢?从Channel读取内容后,直接读取ByteBuffer多好!据Thinking in java说,这么做是为了效率!但是似乎没看到相关的解释,猜测和position的使用有关。
mark()和reset()
mark()可以立即保存当前的position(),方便后面使用reset()复位到之前的position的位置,所以mark()和reset()这里放在了一起进行说明。在RocketMQ中,mark()的一个使用场景是:
写入message前先记录ByteBuffer的position位置,然后保存内容到文件。如果下次读取的内容,文件已经没有剩余的空间保存了,那么需要使用reset()恢复到上次读取的位置。
rewind()
rewind类似于flip(),但是它只重置position=0,mark=-1,对于limit它是不处理的,默认limit已经在正确的位置。
堆内内存和堆外内存
之前的例子,创建的ByteBuffer都是分配的堆内内存,也就是jvm里面的内存。下面的例子,我们通过allocateDirect()申请堆外内存:
public static void main(String[] args) throws Exception{
String path = "d:" + File.separator + "bill";
FileChannel fileChannel = new FileInputStream(path).getChannel();
final int CAPACITY = 20;
ByteBuffer byteBufferHeap = ByteBuffer.allocateDirect(CAPACITY); // 申请堆外内存
while(fileChannel.read(byteBufferHeap) != -1){
// 读取内容到byteBuffer中,直到文件末尾
byteBufferHeap.flip();// 翻转byteBuffer,为了后面读取byteBuffer内容
while(byteBufferHeap.hasRemaining()){
// ByteBuffer还有内容
System.out.print((char)byteBufferHeap.get());
}
byteBufferHeap.clear();// 清空byteBuffer,为了后面读取内容到ByteBuffer。
}
}
allocateDirect返回的是DirectByteBuffer对象,其继承关系如下所示(这个图是后面参考文章的):
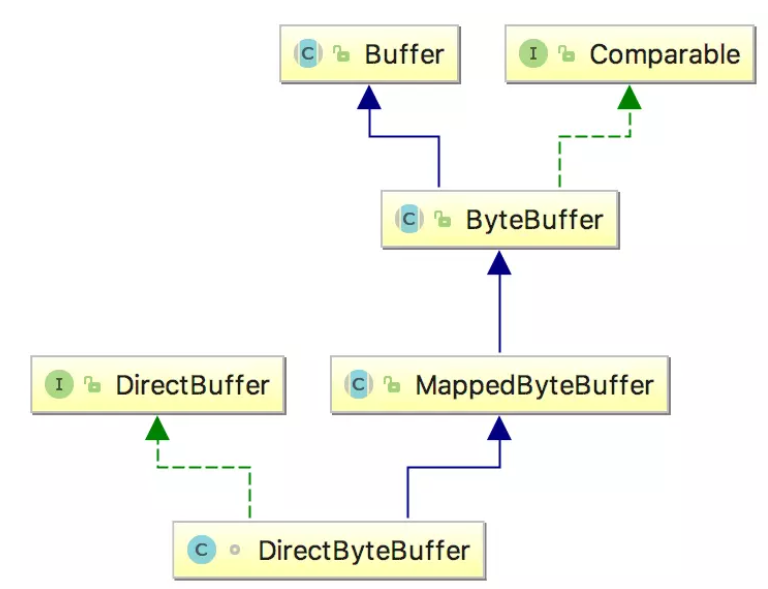 DirectByteBuffer的使用与ByteBuffer几乎没什么区别,但是它们所蕴含的意思大不一样。DirectByteBuufer使用的是堆外内存,而我们平时的ByteBuffer使用的是堆内内存。我们之前介绍属性的时候,有下面两个属性:
DirectByteBuffer的使用与ByteBuffer几乎没什么区别,但是它们所蕴含的意思大不一样。DirectByteBuufer使用的是堆外内存,而我们平时的ByteBuffer使用的是堆内内存。我们之前介绍属性的时候,有下面两个属性:
long address; // 访问地址,仅仅针对DirectByteBuffer,使用的是堆外内存。
final byte[] hb; // 堆内内存时存放的内容
分配堆外内存,会返回堆外内存的地址,并存放在address里面。如果是堆内内存,那么内容就存放在hb里面。所以这两者是互斥的。
对于需要频繁操作的内存,并且仅仅是临时存在一会的,都建议使用堆外内存,并且做成缓冲池,不断循环利用这块内存。
更详情的内容可以查看后面的参考文章,这里限于篇幅和知识,就不画蛇添足了。
零拷贝技术
RocketMQ号称使用了零拷贝技术,其实就是这里的堆外内存。应用程序读取磁盘文件,看似很简单,其实在操作系统底层做了多次拷贝。首先系统将磁盘文件拷贝进入内核缓冲区,然后再切换到用户态,将内容拷贝到用户的内存缓冲区。这里不仅有系统内核态、用户态的切换,而且还有多次拷贝。如果使用了堆外内存,那么系统内核将与应用共享一片缓存区,那么磁盘文件从磁盘拷贝到共享缓冲区后,应用程序就可以直接访问了,从而免去了拷贝操作。这里讲的很粗糙,如果感兴趣可以查看后面的参考文章。
好了,到这里我们基本上对ByteBuffer有了一个大致的了解,后面就是RockeMQ消息三部曲:消息发送、消息存储和消息消费的内容了,敬请期待。
参考文章
1-浅析Linux中的零拷贝技术
2-JVM源码分析之堆外内存完全解读
3-堆外内存之DirectByteBuffer
4-JAVA NIO之浅谈内存映射文件原理与DirectMemory
5-堆内内存还是堆外内存?
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186597.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
