大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
简介
在Java的Socket编程中,若使用阻塞式(BIO),则往往通过ServerSocket的accept()方法获取到客户端Socket之后,再使用客户端Socket的InputStream和OutputStream进行读写。Socket.getInputstream.read(byte[] b)和Socket.getOutputStream.write(byte[] b)的方法中的参数都是字节数组。这种阻塞式的Socket编程显然已经远远不能满足目前的并发式访问需求。
所以最近在项目中学习使用了Java原生NIO,这时则需要通过ServerSocketChannel的accept()方法获取到客户端的SocketChannel,再使用客户端SocketChannel直接进行读写。但SocketChannel.read(ByteBuffer dst)和SocketChannel.write(ByteBuffer src)的方法中的参数则都变为了java.nio.ByteBuffer,该类型就是JavaNIO对byte数组的一种封装,其中包括了很多基本的操作,在此记录一下备忘。
ByteBuffer包含几个基本的属性:
- position:当前的下标位置,表示进行下一个读写操作时的起始位置;
- limit:结束标记下标,表示进行下一个读写操作时的(最大)结束位置;
- capacity:该ByteBuffer容量;
- mark: 自定义的标记位置;
无论如何,这4个属性总会满足如下关系:mark <= position <= limit <= capacity。目前对mark属性了解的不多,故在此暂不做讨论。其余3个属性可以分别通过ByteBuffer.position()、ByteBuffer.limit()、ByteBuffer.capacity()获取;其中position和limit属性也可以分别通过ByteBuffer.position(int newPos)、ByteBuffer.limit(int newLim)进行设置,但由于ByteBuffer在读取和写出时是非阻塞的,读写数据的字节数往往不确定,故通常不会使用这两个方法直接进行修改。
初始化
首先无论读写,均需要初始化一个ByteBuffer容器。如上所述,ByteBuffer其实就是对byte数组的一种封装,所以可以使用静态方法wrap(byte[] data)手动封装数组,也可以通过另一个静态的allocate(int size)方法初始化指定长度的ByteBuffer。初始化后,ByteBuffer的position就是0;其中的数据就是初始化为0的字节数组;limit = capacity = 字节数组的长度;用户还未自定义标记位置,所以mark = -1,即undefined状态。下图就表示初始化了一个容量为16个字节的ByteBuffer,其中每个字节用两位16进制数表示:


向ByteBuffer写数据
手动写入数据
可以手动通过put(byte b)或put(byte[] b)方法向ByteBuffer中添加一个字节或一个字节数组。ByteBuffer也方便地提供了几种写入基本类型的put方法:putChar(char val)、putShort(short val)、putInt(int val)、putFloat(float val)、putLong(long val)、putDouble(double val)。执行这些写入方法之后,就会以当前的position位置作为起始位置,写入对应长度的数据,并在写入完毕之后将position向后移动对应的长度。下图就表示了分别向ByteBuffer中写入1个字节的byte数据和4个字节的Integer数据的结果:
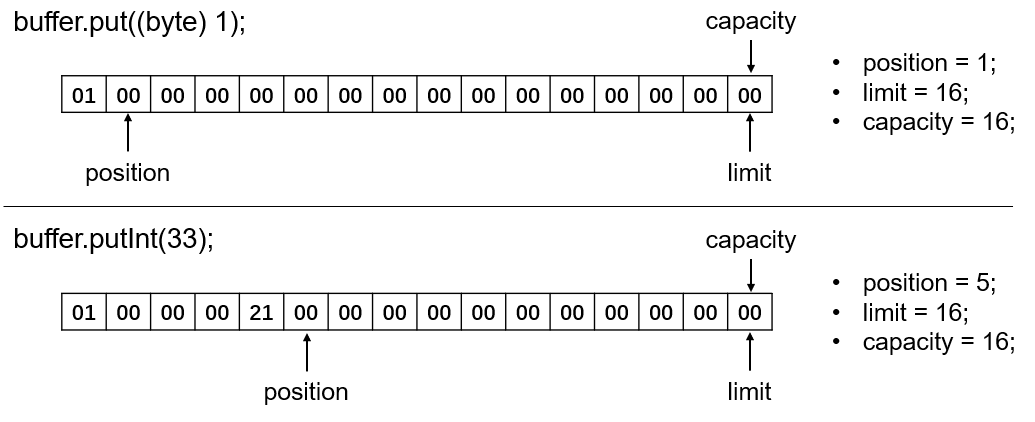
但是当想要写入的数据长度大于ByteBuffer当前剩余的长度时,则会抛出BufferOverflowException异常,剩余长度的定义即为limit与position之间的差值(即 limit – position)。如上述例子中,若再执行buffer.put(new byte[12]);就会抛出BufferOverflowException异常,因为剩余长度为11。可以通过调用ByteBuffer.remaining();查看该ByteBuffer当前的剩余可用长度。
从SocketChannel中读入数据至ByteBuffer
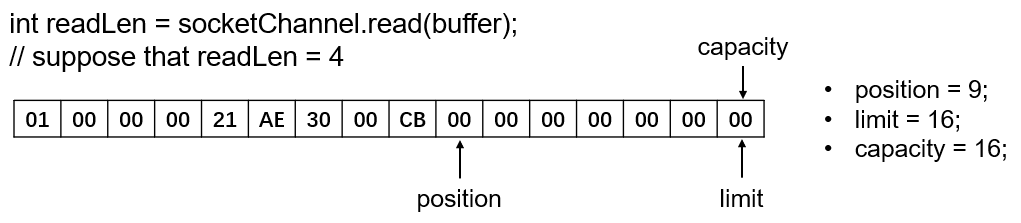
在实际应用中,往往是调用SocketChannel.read(ByteBuffer dst),从SocketChannel中读入数据至指定的ByteBuffer中。由于ByteBuffer常常是非阻塞的,所以该方法的返回值即为实际读取到的字节长度。假设实际读取到的字节长度为 n,ByteBuffer剩余可用长度为 r,则二者的关系一定满足:0 <= n <= r。继续接上述的例子,假设调用read方法,从SocketChannel中读入了4个字节的数据,则buffer的情况如下:
从ByteBuffer中读数据
复位position
现在ByteBuffer容器中已经存有数据,那么现在就要从ByteBuffer中将这些数据取出来解析。由于position就是下一个读写操作的起始位置,故在读取数据后直接写出数据肯定是不正确的,要先把position复位到想要读取的位置。
首先看一个rewind()方法,该方法仅仅是简单粗暴地将position直接复原到0,limit不变。这样进行读取操作的话,就是从第一个字节开始读取了。如下图:
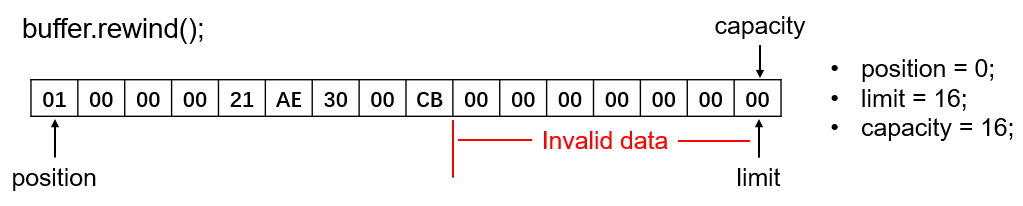
该方法虽然复位了position,可以从头开始读取数据,但是并未标记处有效数据的结束位置。如本例所述,ByteBuffer总容量为16字节,但实际上只读取了9个字节的数据,因此最后的7个字节是无效的数据。故rewind()方法常常用于字节数组的完整拷贝。
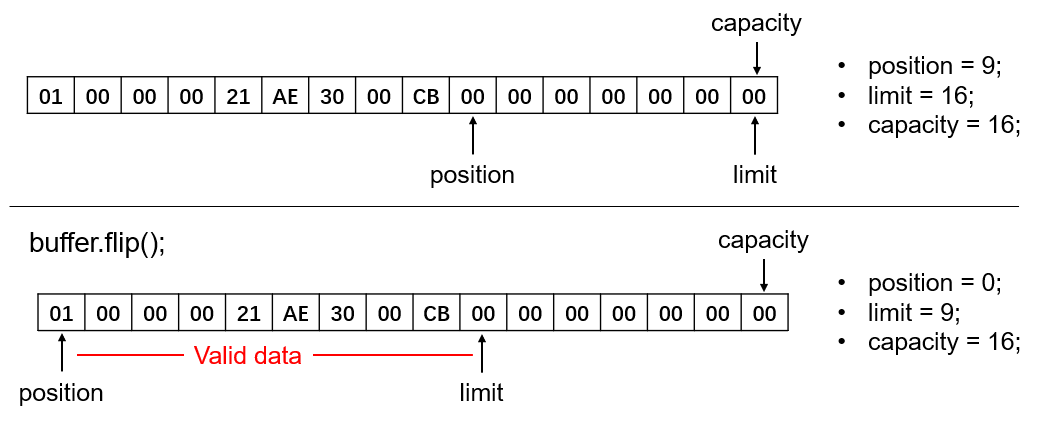
实际应用中更常用的是flip()方法,该方法不仅将position复位为0,同时也将limit的位置放置在了position之前所在的位置上,这样position和limit之间即为新读取到的有效数据。如下图:
读取数据
在将position复位之后,我们便可以从ByteBuffer中读取有效数据了。类似put()方法,ByteBuffer同样提供了一系列get方法,从position开始读取数据。get()方法读取1个字节,getChar()、getShort()、getInt()、getFloat()、getLong()、getDouble()则读取相应字节数的数据,并转换成对应的数据类型。如getInt()即为读取4个字节,返回一个Int。在调用这些方法读取数据之后,ByteBuffer还会将position向后移动读取的长度,以便继续调用get类方法读取之后的数据。
这一系列get方法也都有对应的接收一个int参数的重载方法,参数值表示从指定的位置读取对应长度的数据。如getDouble(2)则表示从下标为2的位置开始读取8个字节的数据,转换为double返回。不过实际应用中往往对指定位置的数据并不那么确定,所以带int参数的方法也不是很常用。get()方法则有两个重载方法:
get(byte[] dst, int offset, int length):表示尝试从 position 开始读取 length 长度的数据拷贝到 dst 目标数组 offset 到 offset + length 位置,相当于执行了
for (int i = off; i < off + len; i++)
dst[i] = buffer.get();
get(byte[] dst):尝试读取 dst 目标数组长度的数据,拷贝至目标数组,相当于执行了
buffer.get(dst, 0, dst.length);
此处应注意读取数据后,已读取的数据也不会被清零。下图即为从例子中连续读取1个字节的byte和4个字节的int数据:
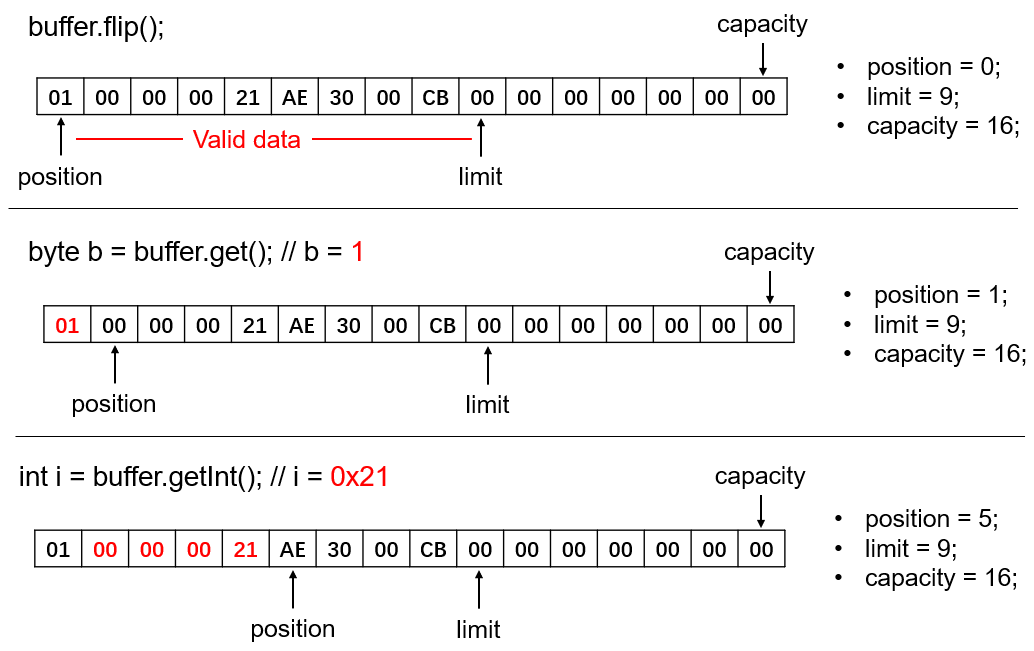
此处同样要注意,当想要读取的数据长度大于ByteBuffer剩余的长度时,则会抛出 BufferUnderflowException 异常。如上例中,若再调用buffer.getLong()就会抛出 BufferUnderflowException 异常,因为 remaining 仅为4。
确保数据长度
为了防止出现上述的 BufferUnderflowException 异常,最好要在读取数据之前确保 ByteBuffer 中的有效数据长度足够。在此记录一下我的做法:
private void checkReadLen(
long reqLen,
ByteBuffer buffer,
SocketChannel dataSrc
) throws IOException {
int readLen;
if (buffer.remaining() < reqLen) {
// 剩余长度不够,重新读取
buffer.compact(); // 准备继续读取
System.out.println("Buffer remaining is less than" + reqLen + ". Read Again...");
while (true) {
readLen = dataSrc.read(buffer);
System.out.println("Read Again Length: " + readLen + "; Buffer Position: " + buffer.position());
if (buffer.position() >= reqLen) {
// 可读的字节数超过要求字节数
break;
}
}
buffer.flip();
System.out.println("Read Enough Data. Remaining bytes in buffer: " + buffer.remaining());
}
}
字节序处理
基本类型的值在内存中的存储形式还有字节序的问题,这种问题在不同CPU的机器之间进行网络通信时尤其应该注意。同时在调用ByteBuffer的各种get方法获取对应类型的数值时,ByteBuffer也会使用自己的字节序进行转换。因此若ByteBuffer的字节序与数据的字节序不一致,就会返回不正确的值。如对于int类型的数值8848,用16进制表示,大字节序为:0x 00 00 22 90;小字节序为:0x 90 22 00 00。若接收到的是小字节序的数据,但是却使用大字节序的方式进行解析,获取的就不是8848,而是-1876819968,也就是大字节序表示的有符号int类型的 0x 90 22 00 00。
JavaNIO提供了java.nio.ByteOrder枚举类来表示机器的字节序,同时提供了静态方法ByteOrder.nativeOrder()可以获取到当前机器使用的字节序,使用ByteBuffer中的order()方法即可获取该buffer所使用的字节序。同时也可以在该方法中传递一个ByteOrder枚举类型来为ByteBuffer指定相应的字节序。如调用buffer.order(ByteOrder.LITTLE_ENDIAN)则将buffer的字节序更改为小字节序。
一开始并不知道还可以这样操作,比较愚蠢地手动将读取到的数据进行字节序的转换。不过觉得还是可以记下来,也许在别的地方用得到。JDK中的 Integer 和 Long 都提供了一个静态方法reverseBytes()来将对应的 int 或 long 数值的字节序进行翻转。而若想读取 float 或 double,也可以先读取 int 或 long,然后调用 Float.intBitsToFloat(int val) 或 Double.longBitsToDouble(long val) 方法将对应的 int 值或 long 值进行转换。当ByteBuffer中的字节序与解析的字节序相反时,可以使用如下方法读取:
int i = Integer.reverseBytes(buffer.getInt());
float f = Float.intBitsToFloat(Integer.reverseBytes(buffer.getInt()));
long l = Long.reverseBytes(buffer.getLong());
double d = Double.longBitsToDouble(buffer.getLong());
继续写入数据
由于ByteBuffer往往是非阻塞式的,故不能确定新的数据是否已经读完,但这时候依然可以调用ByteBuffer的compact()方法切换到读取模式。该方法就是将 position 到 limit 之间还未读取的数据拷贝到 ByteBuffer 中数组的最前面,然后再将 position 移动至这些数据之后的一位,将 limit 移动至 capacity。这样 position 和 limit 之间就是已经读取过的老的数据或初始化的数据,就可以放心大胆地继续写入覆盖了。仍然使用之前的例子,调用 compact() 方法后状态如下:
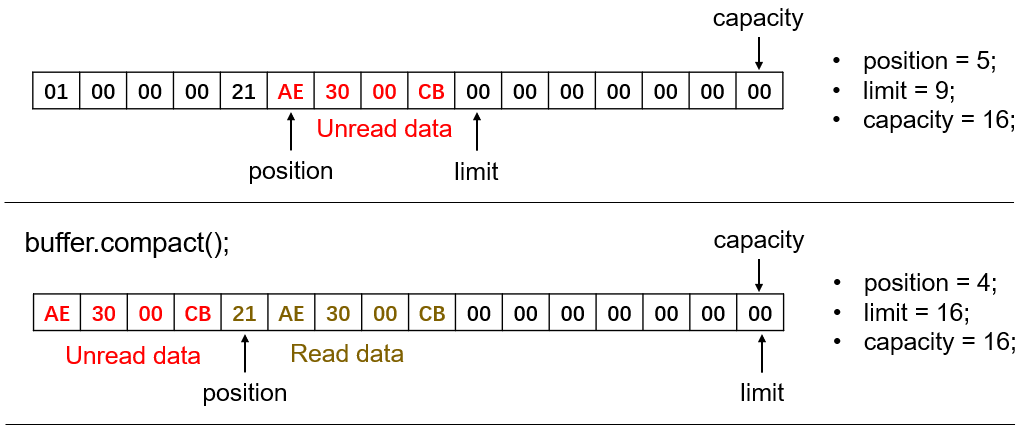
总结
总之ByteBuffer的基本用法就是:
初始化(allocate)–> 写入数据(read / put)–> 转换为写出模式(flip)–> 写出数据(get)–> 转换为写入模式(compact)–> 写入数据(read / put)…
参考资料
- java字节序、主机字节序和网络字节序扫盲贴:https://blog.csdn.net/aitangyong/article/details/23204817
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186533.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
