大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
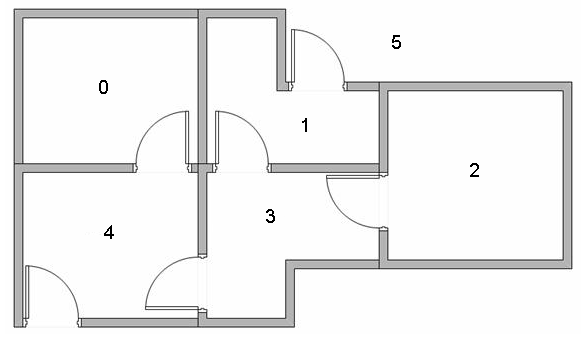
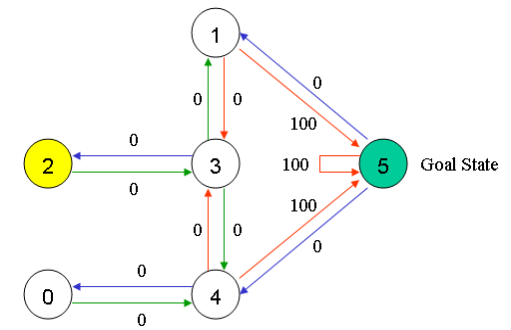
假设我们的楼层内共有5个房间,房间之间通过一道门相连,正如下图所示。我们将房间编号为房间0到房间4,楼层的外部可以被看作是一间大房间,编号为5。注意到房间1和房间4可以直接通到房间5。

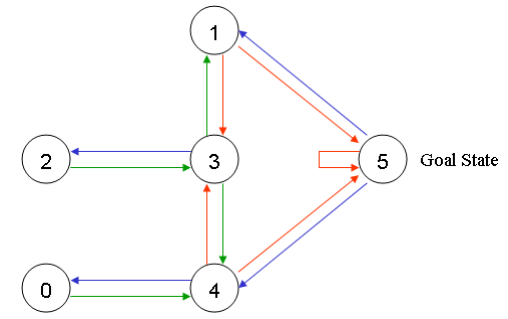

Q-学习的转换规则非常简单,为下面的式子:
Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])
依据这个公式,矩阵Q中的一个元素值就等于矩阵R中相应元素的值与学习变量Gamma乘以到达下一个状态的所有可能动作的最大奖励值的总和。
我们虚拟的智能体将从经验中学习,不需要教师指导信号(这被称为非监督学习)。智能体将从一个状态到另一个状态进行探索,直到它到达目标状态。我们将每一次探索作为一次经历,每一次经历包括智能体从初始状态到达目标状态的过程。每次智能体到达了目标状态,程序将会转向下一次探索。
1、设置参数Gamma,以及矩阵R中的环境奖励值;
2、初始化Q矩阵为0;
3、对每一次经历:
随机选择一个状态;
Do while 目标状态未到达
对当前状态的所有可能的动作中,选择一个可能的动作;
使用这个可能的动作,到达下一个状态;
对下一个状态,基于其所有可能的动作,获得最大的Q值;
计算:Q(state, action)=R(state, action) + Gamma * Max(Q[next state, all actions])
设置下一个状态作为当前状态;
End For
参数Gamma的取值在0到1之间(0<=Gamma<=1),如果Gamma越接近于0,智能体更趋向于仅仅考虑即时奖励;如果Gamma更接近于1,智能体将以更大的权重考虑未来的奖励,更愿意将奖励延迟。
为了使用矩阵Q,智能体仅仅简单地跟踪从起始状态到目标状态的状态序列,这个算法在矩阵Q中,为当前状态寻找到具有最高奖励值的动作。
利用矩阵Q的算法如下:
1、设置当前状态=初始状态;
2、从当前状态开始,寻找具有最高Q值的动作;
3、设置当前状态=下一个状态;
4、重复步骤2和3,直到当前状态=目标状态。
上述的算法将返回从初始状态到目标状态的状态序列。
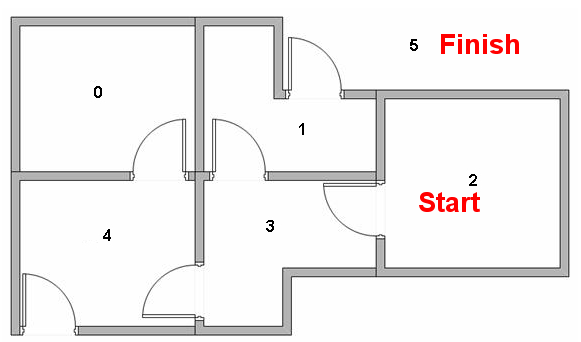
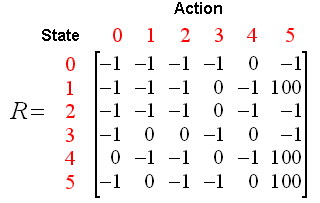
我们设置学习率Gamma等于0.8,初始的状态是房间1。
初始的矩阵Q作为一个零矩阵,如下:

Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
由于矩阵Q此时依然被初始化为0,Q(5, 1), Q(5, 4), Q(5, 5)全部是0,因此,Q(1, 5)的结果是100,因为即时奖励R(1,5)等于100。
下一个状态5现在变成了当前状态,因为状态5是目标状态,因此我们已经完成了一次尝试。我们的智能体的大脑中现在包含了一个更新后的Q矩阵。

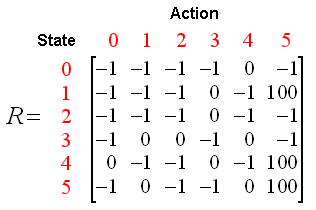
观察R矩阵的第4行,有3个可能的动作,到达状态1,2和4。我们随机选择到达状态1作为当前状态的动作。
现在,我们想象我们在状态1,观察矩阵R的第2行,具有2个可能的动作:到达状态3或者状态5。现在我们计算Q值:
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(3, 1) = R(3, 1) + 0.8 * Max[Q(1, 2), Q(1, 5)] = 0 + 0.8 * Max(0, 100) = 80
我们使用上一次尝试中更新的矩阵Q得到:Q(1, 3) = 0 以及 Q(1, 5) = 100。因此,计算的结果是Q(3,1)=80,因为奖励值为0。现在,矩阵Q变为:
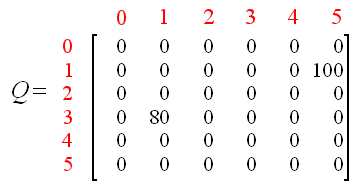
因此,我们从当前状态1开始一次新的循环,此时有2个可能的动作:到达状态3或者状态5。我们幸运地选择到达了状态5。
Q(state, action) = R(state, action) + Gamma * Max[Q(next state, all actions)]
Q(1, 5) = R(1, 5) + 0.8 * Max[Q(5, 1), Q(5, 4), Q(5, 5)] = 100 + 0.8 * 0 = 100
更新后的矩阵Q中,Q(5, 1), Q(5, 4), Q(5, 5)依然是0,故Q(1, 5)的值是100,因为即时奖励R(5,1)是100,这并没有改变矩阵Q。
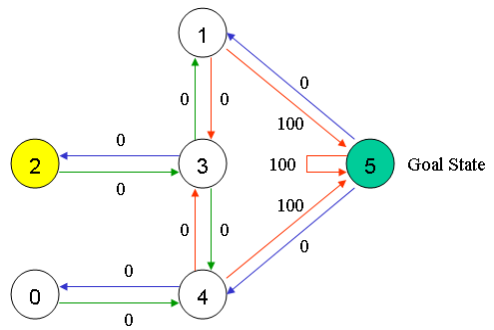
因为状态5是目标状态,我们完成了这次尝试。我们的智能体大脑中包含的矩阵Q更新为如下所示:
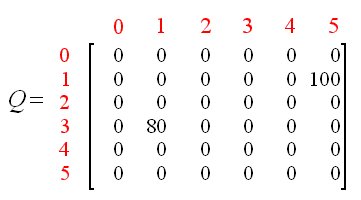


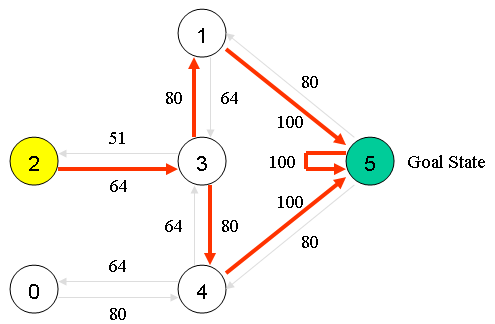
例如,从初始状态2,智能体在矩阵Q的指导下进行移动:
在状态2时,由矩阵Q中最大的值可知下一个动作应该是到达状态3;
在状态3时,矩阵Q给出的建议是到达状态1或者4,我们任意选择,假设选择了到达状态1;
在状态1时,矩阵Q建议到达状态5;
因此,智能体的移动序列是2-3-1-5。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% Q learning of single agent move in N rooms
% Matlab Code companion of
% Q Learning by Example
%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function q=ReinforcementLearning
clc;
format short
format compact
% Two input: R and gamma
% immediate reward matrix;
% row and column = states; -Inf = no door between room
R=[-inf,-inf,-inf,-inf, 0, -inf;
-inf,-inf,-inf, 0,-inf, 100;
-inf,-inf,-inf, 0,-inf, -inf;
-inf, 0, 0,-inf, 0, -inf;
0,-inf,-inf, 0,-inf, 100;
-inf, 0,-inf,-inf, 0, 100];
gamma=0.80; % learning parameter
q=zeros(size(R)); % initialize Q as zero,q的行数和列数等于矩阵R的。
q1=ones(size(R))*inf; % initialize previous Q as big number
count=0; % counter
for episode=0:50000
% random initial state
y=randperm(size(R,1));%产生1到6的随机数%a=size(R,1)把矩阵R的行数返回给a,b=size(R,2)把矩阵R的列数返回给b
state=y(1); %取1到6的随机数的第一个数
% select any action from this state
x=find(R(state,:)>=0); % find possible action of this state.返回矩阵R第state行所有列中不小于零的数据的下标
if size(x,1)>0,
x1=RandomPermutation(x); % randomize the possible action
x1=x1(1); % select an action
end
qMax=max(q,[],2);
q(state,x1)= R(state,x1)+gamma*qMax(x1); % get max of all actions
% break if convergence: small deviation on q for 1000 consecutive
if sum(sum(abs(q1-q)))<0.0001 & sum(sum(q >0))
if count>1000,
episode % report last episode
break % for
else
count=count+1; % set counter if deviation of q is small
end
else
q1=q;
count=0; % reset counter when deviation of q from previous q is large
end
end
%normalize q
g=max(max(q));
if g>0,
q=100*q/g;
end
% The code above is using basic library RandomPermutation below
function y=RandomPermutation(A)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% return random permutation of matrix A
% unlike randperm(n) that give permutation of integer 1:n only,
% RandomPermutation rearrange member of matrix A randomly
% This function is useful for MonteCarlo Simulation,
% Bootstrap sampling, game, etc.
%
% Copyright Kardi Teknomo(c) 2005
% (http://people.revoledu.com/kardi/)
%
% example: A = [ 2, 1, 5, 3]
% RandomPermutation(A) may produce [ 1, 5, 3, 2] or [ 5, 3, 2, 3]
%
% example:
% A=magic(3)
% RandomPermutation(A)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
[r,c]=size(A);
b=reshape(A,r*c,1); % convert to column vector
x=randperm(r*c); % make integer permutation of similar array as key
w=[b,x’]; % combine matrix and key
d=sortrows(w,2); % sort according to key
y=reshape(d(:,1),r,c); % return back the matrix
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186217.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
