大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
- 一、概述
- 二、基于定位-识别的方法
- 三、基于网络集成的方法
- 四、高阶特征编码
- 总结
- 其它相关
一、概述
资源
Awesome Fine-grained Visual Classification
Awesome Fine-Grained Image Analysis – Papers, Codes and Datasets—-weixiushen
什么是细粒度图像分类
细粒度图像分类问题是对大类下的子类进行识别。细粒度图像分析任务相对通用图像(General/Generic Images)任务的区别和难点在于其图像所属类别的粒度更为精细。
以图1为例,通用图像分类其任务诉求是将“袋鼠”和“狗”这两个物体大类(蓝色框和红色框中物体)分开,可见无论从样貌、形态等方面,二者还是很容易被区分的;而细粒度图像的分类任务则要求对“狗”该类类别下细粒度的子类,即分别为“哈士奇”和“爱斯基摩犬”的图像分辨开来。正因同类别物种的不同子类往往仅在耳朵形状、毛色等细微处存在差异,可谓“差之毫厘,谬以千里”。不止对计算机,对普通人来说,细粒度图像任务的难度和挑战无疑也更为巨大。


意义
细粒度图像分类无论在工业界还是学术界都有着广泛的研究需求与应用场景。与之相关的研究课题主要包括识别不同种类的鸟、狗、花、车、飞机等。在实际生活中,识别不同的子类别又存在着巨大的应用需求。例如, 在生态保护中, 有效识别不同种类的生物,是进行生态研究的重要前提。如果能够借助于计算机视觉的技术, 实现低成本的细粒度图像识别, 那么无论对于学术界, 还是工业界而言, 都有着非常重要的意义。
细粒度图像分类的挑战
由于分类的粒度很小,细粒度图像分类非常困难,在某些类别上甚至专家都难以区分。主要原因有三:
子类之间差异细微:只在某个局部上有细微差异,如狗的眼睛
子类内部差异巨大:如姿态、背景带来的差异
受视角、背景、遮挡等因素影响较大
细粒度分类常用方法
目前细粒度图像分类基本上都 采用深度学习的方法,取得不错的效果。具体来说,大致可以分为以下几类:
- 使用通用DCNN(Deep Convolutional Neural Network,深度卷积神经网络)进行细粒度分类,该方法难以捕获有区别性的局部细节,目前已经不太常用;
- 基于定位-识别的方法:先找到有区分度的局部,然后进行特征提取和分类,该方法又可分为强监督和弱监督两种;
- 基于网络集成的方法:使用多个DCNN对细粒度识别中的相似特征进行判别;
- 卷积特征的高阶编码方法:将cnn特征进行高阶转换然后进行分类,主要有fisher vector、双线性模型、核融合等。
二、基于定位-识别的方法
人类区分相似物体时,通常会通过快速扫描的方式先找到具有区别性的区域,然后在该区域仔细进行比对识别。与人类的方式类似,基于定位-识别的方法将细粒度图像识别分为两个部分:区别性区域定位和区域中的细粒度特征学习。在区别性区域定位时,通常会以强监督或弱监督的方式利用深度神经网络的卷积特征响应;而在细粒度特征学习时,则从定位到的各个区域中分别抽取特征,并将各特征组合到一起最后进行分类。
强监督的方法不仅需要类别标签,而且需要部件标注和关键部位框,该种方法取得了不错的效果,但缺点在于需要昂贵的人工标注,而且人工标注的位置不一定是最佳的区别性区域,这完全依赖于标注者的认知水平。
进来,很多弱监督的方法被提出来。该类方法利用注意力机制、聚类等手段来自动发现区别性区域,不需要部件标注,仅仅有分类标签即可完成训练。
当前有很多方法在朝这方面努力,从大的发展趋势来看,基于定位-分类的细粒度图像分类方法经历了从手工特征工程到多阶段方法再到end to end的发展过程。
2.1 强监督
所谓“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(Object Bounding Box)和部位标注点(Part Annotation)等额外的人工标注信息,如下图所示。
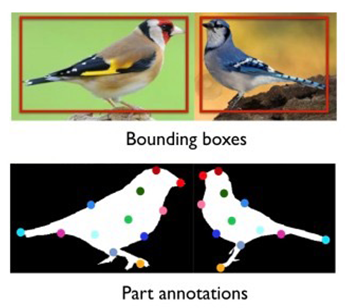
2.1.1 Part-based R-CNN
<Part-based R-CNNs for fine-grained category detection – ECCV2014>
相信大家一定对R-CNN不陌生,顾名思义,Part-based R-CNN就是利用R-CNN算法对细粒度图像进行物体级别(例如鸟类)与其局部区域(头、身体等部位)的检测,其总体流程如下图所示。
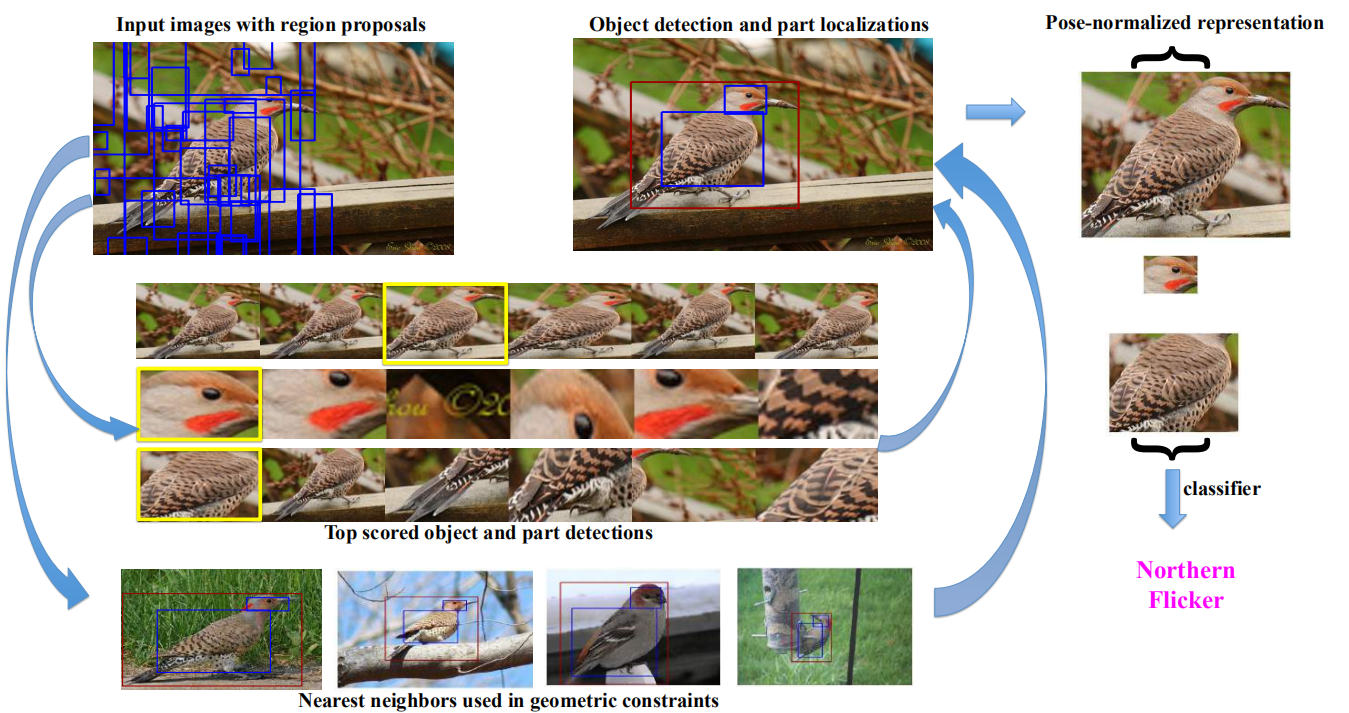
首先利用Selective Search等算法在细粒度图像中产生物体或物体部位可能出现的候选框(Object Proposal)。之后用类似于R-CNN做物体检测的流程,借助细粒度图像中的Object Bounding Box和Part Annotation可以训练出三个检测模型(Detection Model):一个对应细粒度物体级别检测;一个对应物体头部检测;另一个则对应躯干部位检测。然后,对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位,以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果(如图3右上)。
接下来将得到的图像块(Image Patch)作为输入,分别训练一个CNN,则该CNN可以学习到针对该物体/部位的特征。最终将三者的全连接层特征级联(Concatenate)作为整张细粒度图像的特征表示。显然,这样的特征表示既包含全部特征(即物体级别特征),又包含具有更强判别性的局部特征(即部位特征:头部特征/躯干特征),因此分类精度较理想。
Part R-CNN的进步是明显的. 从局部区域的检测定位, 到特征的提取, 该算法均基于卷积神经网络, 并针对细粒度图像的特点进行改进优化, 以改进通用物体定位检测算法在该任务上的不足, 达到了一个相对比较高的准确度. 同时,该算法进一步放松了对标记信息的依赖程度, 在测试时无需提供任何标记信息, 大大增强了算法的实用性. 、
其不足之处在于,第一是 利用自底向上的区域产生方法, 会产生大量无关区域, 这会在很大程度上影响算法的速度. 第二是不仅在训练时需要借助Bounding Box和Part Annotation,为了取得满意的分类精度,在测试时甚至还要求测试图像提供Bounding Box,这便限制了Part-based R-CNN在实际场景中的应用。第三是该算法本身的创新性十分有限, 既然局部区域对于细粒度图像而言是关键所在, 那么对其进行定位检测则是必要的途径. 只是引入现有的通用定位算法, 似乎并不能很好地解决该问题。
2.1.2Pose Normalized CNN
<Bird Species Categorization Using Pose Normalized Deep Convolutional Nets – 2014>
姿态归一化CNN的创新之处在于使用原型对图像进行了姿态对齐操作, 并针对不同的局部区域提取不同网络层的特征, 以试图构造一个更具区分度的特征表示. 它在原有的局部区域模型的基础上, 进一步考虑了鸟类的不同姿态的干扰, 减轻了类内方差造成的影响, 从而取得了较好的性能表现. 但是, 该算法对于关键点的检测精度较为敏感, 利用DP算法对关键点进行检测, 其精度为75.7%。
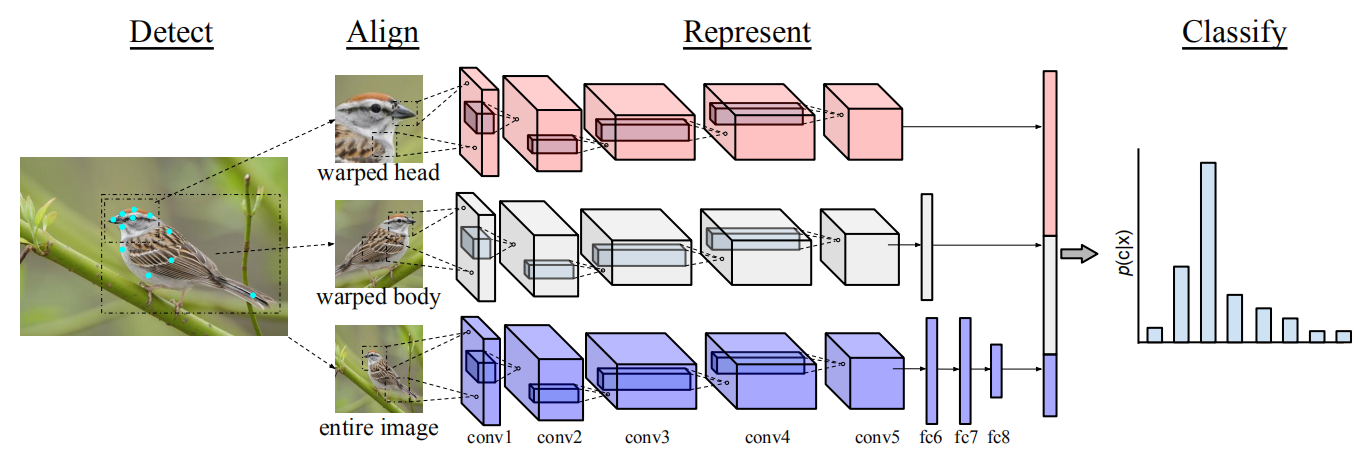
有感于Part-based R-CNN,S. Branson等人提出在用DPM算法得到Part Annotation的预测点后同样可以获得物体级别和部位级别的检测框,如下图所示。与之前工作不同的是,Pose Normalized CNN对部位级别图像块做了姿态对齐操作。
此外,由于CNN不同层的特征具有不同的表示特性(如浅层特征表示边缘等信息,深层特征更具高层语义),该工作还提出应针对细粒度图像不同级别的图像块,提取不同层的卷积特征。该网络将经过姿态归一化提取的conv5、fc6等底层特征与未对齐的fc8高级特征进行融合。
训练阶段,姿态归一化网络使用DPM预测2D位置及13个语义部位关键点,或者直接使用已提供的物体框及部位标注信息学习姿态原型。将不同的部位图像进行弯曲,并且使用不同的DCNN(AlexNet)提取其特征。最后拼接各个部位及整张图像的特征训练分类器。
最终,还是将不同级别特征级联作为整张图像的表示。如此的姿态对齐操作和不同层特征融合方式,使得Pose Normalized CNN在使用同样多标记信息时取得了相比Part-based R-CNN高2%的分类精度。
2.1.3 基于多候选区集成的部件定位(Part localization using multi-proposal consensus)
<Part Localization using Multi-Proposal Consensus for Fine-Grained Categorization – BMVA2015>
使用基于AlexNet的单个DCNN定位关键点和区域。
将AlexNet最后的fc8层替换为两个产生关键点及视觉特征的输出层。使用边缘框分块(edge box crops)方法将图像分块,之后产生其特征点位置及视觉特征,去除自信度低的预测结果。之后取剩余预测结果的中心点,作为最终关键点预测结果。并使用将部件检测网络中关键点位置的特征,将其拼接,使用200路一对所有SVM分类器进行分类。
2.1.4部件堆积CNN(Part-stack CNN,PS-CNN)
<Part-stacked CNN for fine-grained visual categorization – CVPR2016>
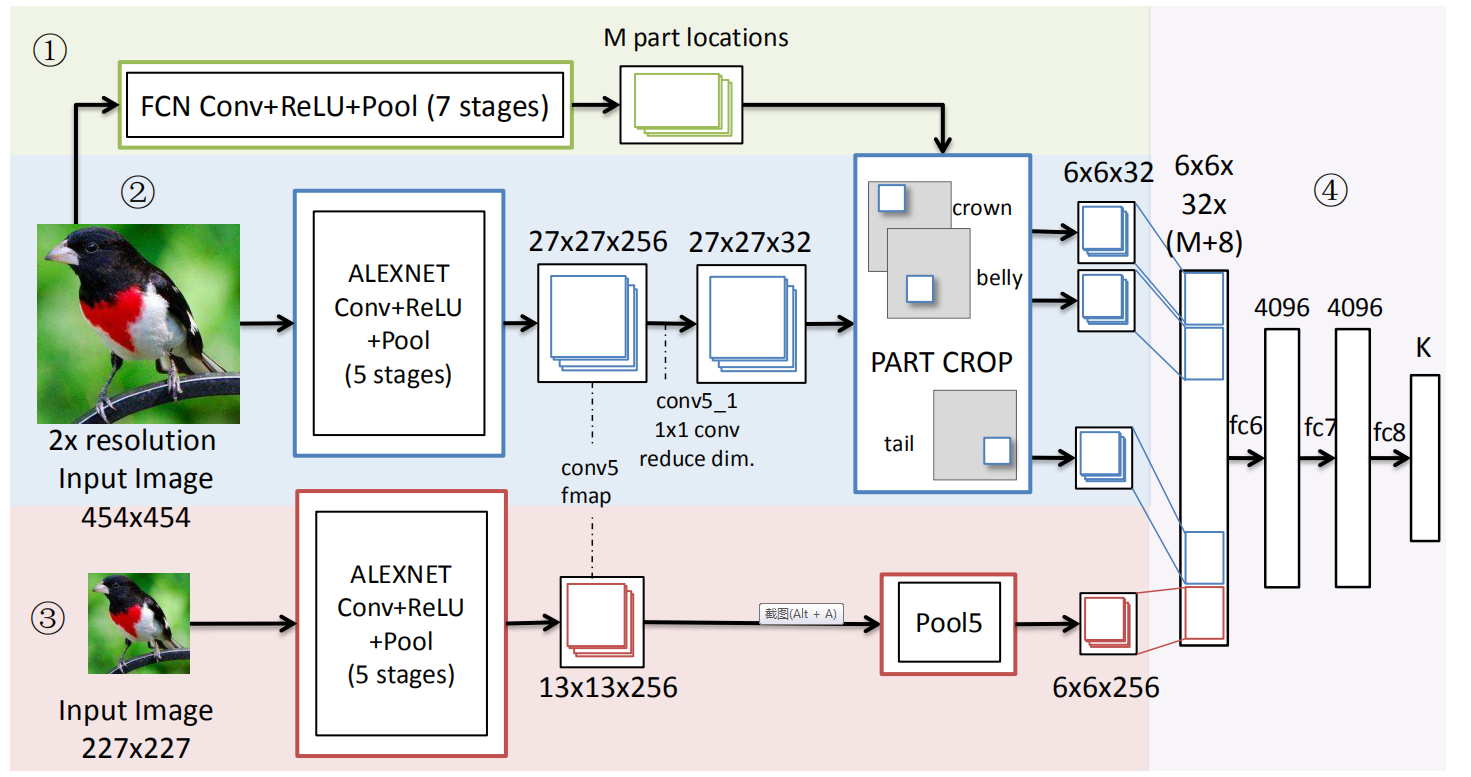
基于人工标记的强部件标注信息,PS-CNN使用全卷积网络进行部件定位和一个双流的分类网络对物体及部件的特征进行编码。
全卷积网络将CNN中的全连接层使用1×1的卷积代替,其输出特征图的维度小于输入图像维度。输出特征图的每个像素点对应输入图像的一个区域,该区域称为其感受野。FCN具有以下优点:1)其特征图可以直接作为部件的定位结果应用于分类网络;2)FCN能够同时得到多部件的定位结果;3)FCN的学习及推理较为高效。
使用FCN得到conv5中M个关键点的位置之后,将定位结果输入到分类网络,使用两级架构分析图像物体级及部件级的特征。
部件级网络首先通过共享层提取特征,之后分别计算关键点周围的部件特征。物体级别网络使用标注框提取对象级CNN特征,及pool5特征。之后将部件级网络及物体级网络特征图合并,进行分类。
2.1.5 Deep LAC(Location Alignment Classification)
<Deep LAC: Deep localization, alignment and classification for fine-grained recognition – CVPR2015>
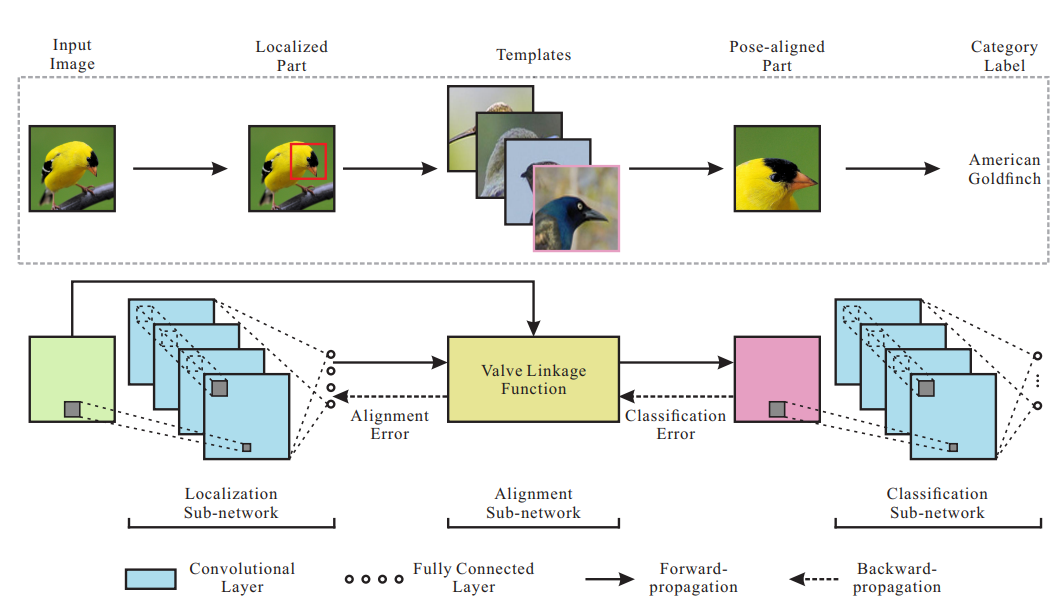
Deep LAC在同一个网络中进行部件定位、对齐及分类,提出了VLF(valve linkage function,阀门连接函数)函数,进行Deep LAC中的反向传播,其能够自适应地减小分类及对齐的误差,并且更新定位结果。
部件定位子网络包含5个卷积层及3个全连接层。输出为框的左上角及右下角点的坐标。
对齐子网络接收部件定位结果,执行模板对齐,产生姿态对齐的部件图像。对齐子网络进行平移、缩放、旋转等操作用于姿态对齐区域的生成。同时,该子网络还负责反向传播过程中分类及定位结果的桥接作用。
对齐子网络中的VLF是一个非常关键的模块,优化定位及分类子网络间的连接,协调分类结果与定位结果。使网络达到稳定状态。
Mask-CNN
<Mask-CNN : Localizing Parts and Selecting Descriptors for Fine-Grained Image Recognition –Pattern Recognition, 2018>
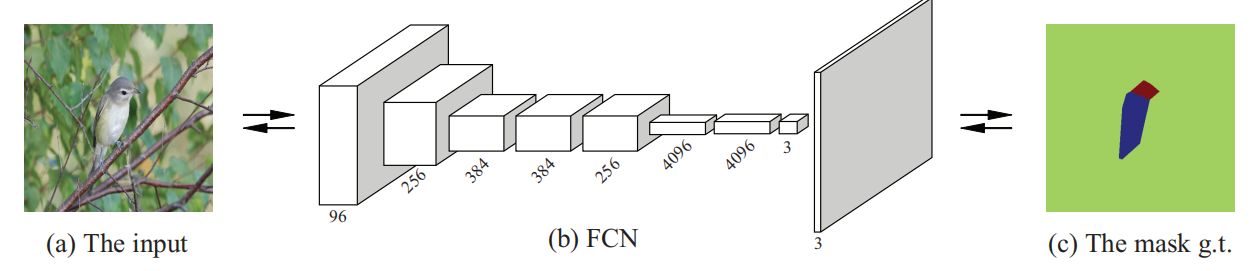
该模型亦分为两个模块,第一是Part Localization;第二是全局和局部图像块的特征学习。需要指出的是,与前两个工作的不同在于,在Mask-CNN中,借助FCN学习一个部位分割模型(Part-Based Segmentation Model)。其真实标记是通过Part Annotation得到的头部和躯干部位的最小外接矩形,如下图(c)所示。在FCN中,Part Localization这一问题就转化为一个三分类分割问题,其中,一类为头部、一类为躯干、最后一类则是背景。
FCN训练完毕后,可以对测试集中的细粒度图像进行较精确地part定位,下图展示了一些定位效果图。可以发现,基于FCN的part定位方式可以对大多数细粒度图像进行较好的头部和躯干定位。同时,还能注意到,即使FCN的真实标记是粗糙的矩形框,但其预测结果中针对part稍精细些的轮廓也能较好地得到。在此,我们称预测得到的part分割结果为Part Mask。不过,对于一些复杂背景图像(如图6右下)part定位结果还有待提高。
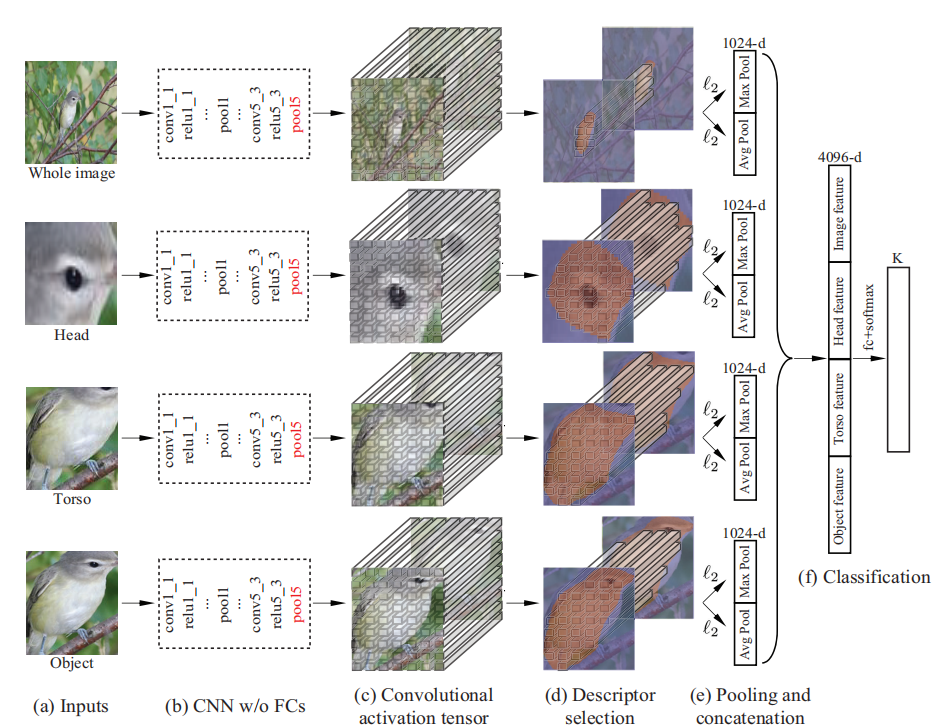
在得到Part Mask后,可以通过Crop获得对应的图像块。同时,两个Part Mask组合起来刚好可组成一个较完整的Object Mask。同样,基于物体/部位图像块,Mask-CNN训练了三个子网络。
在此需要特别指出的是,在每个子网络中,上一步骤中学到的Part/Object Mask还起到了一个关键作用,即“筛选关键卷积特征描述子”(Selecting Useful Convolutional Descriptor),如图7( c)-(d)。这个模块也是我们首次在细粒度图像分类中提出的。筛选特征描述子的好处在于,可以保留表示前景的描述子,而去除表示背景的卷积描述子的干扰。筛选后,对保留下来的特征描述子进行全局平均和最大池化(Global Average/Max Pooling)操作,后将二者池化后的特征级联作为子网络的特征表示,最后将三个子网特征再次级联作为整张图像的特征表示。
实验表明,基于筛选的Mask-CNN在仅依靠训练时提供的Part Annotation(不需要Bounding Box,同时测试时不需额外监督信息)取得了目前细粒度图像分类最高的分类精度(在经典CUB数据上,基于ResNet的模型对200类不同鸟类分类精度可达87.3%)。此外,借助FCN学习Part Mask来进行Part定位的做法也取得了Part定位的最好结果。
2.2 弱监督
值得借鉴的思想:目标检测中—基于弱监督的目标定位
Weakly Supervised Object Localization
cvpr2020-南大提伪监督目标定位方法,弱监督目标定位的最新SOTA
2.2.1 两级注意力(Two-level attention)
两级注意力(Two Level Attention)算法第一个尝试不依赖额外的标注信息, 而仅仅使用类别标签来完成细粒度图像分类的工作。 两级注意力结合了三种类型的注意力:生成候选图像块的自底向上注意力、选择相关块形成特定物体的对象级自顶向下注意力、定位判别性部件的部件级自底向上注意力。通过整合这些类型的注意力机制训练特定的DCNN,以提取前景物体及特征较强的部件。该模型容易泛化,不需要边界框及部件标注。
之后基于FilterNet选择出来的框训练DomainNet。特别地,使用相似矩阵将中间层分为K个簇,簇的作用域部件检测器相同。之后各个簇筛选出的图像块被缩放到DomainNet输入大小,生成其激活值,之后将不同部件的激活值汇总并训练一对多SVM分类器。最终,将物体级与部件级注意力预测结果合并,以利用两级注意力的优势。
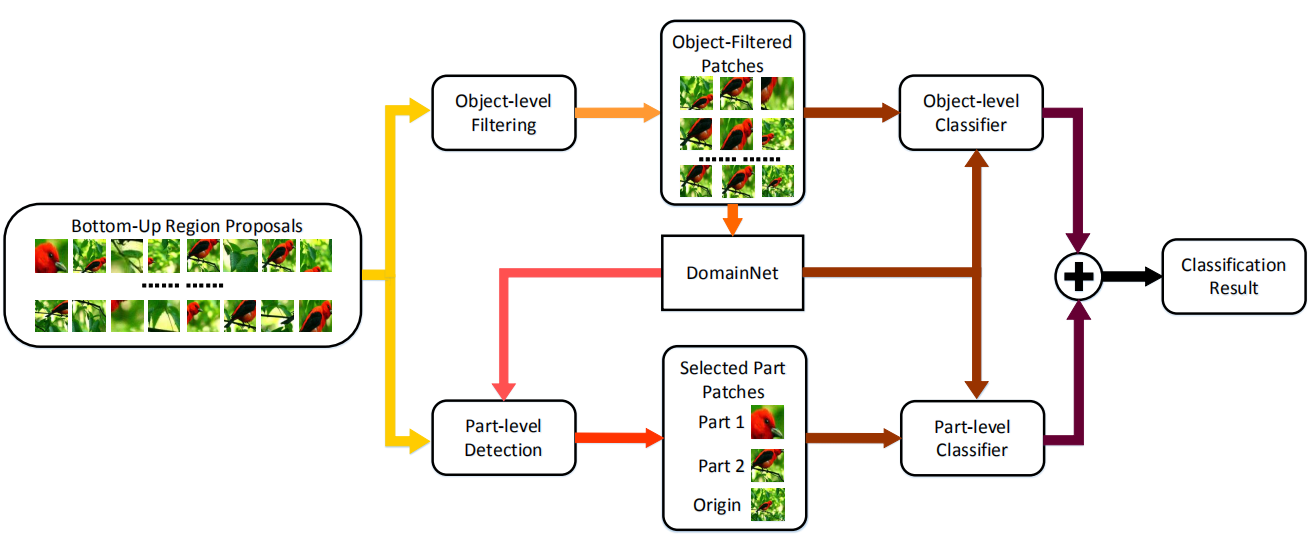
总体上来看, 两级注意力模型较好地解决了在只有类别标签的情况下, 如何对局部区域进行检测的问题. 但是, 利用聚类算法所得到的局部区域, 准确度十分有限. 在同样使用Alex Net的情况下, 其分类精度要低于强监督的Part R-CNN算法。
2.2.2 细粒度分类的注意力(Attention for fine-grained categorization)
<Attention for fine-grained categorization – RCLR2015>
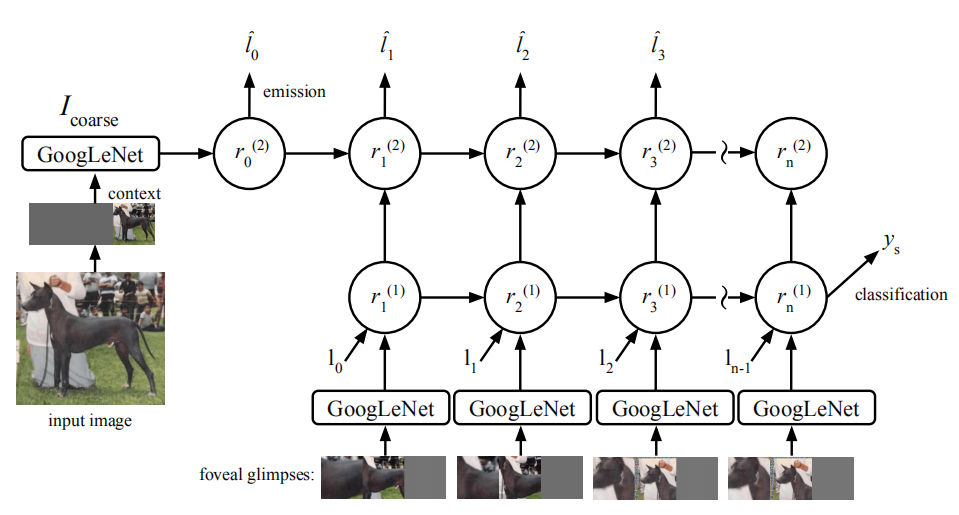
人类在识别时通常不断移动物体以观察相关的特征,并不断将特征添加到图像表征序列中。
AFGC(细粒度分类注意力模型)是一个基于GoogLeNet的RNN( deep recurrent neural network,深度递归神经网络),在每个时间步处理一个多分辨率的图像块。网络使用该图像块更新图像的表征,并与之前的激活值相结合,输出下一注意点的位置或输出物体最终分类结果。
2.2.3 FCN注意力模型(FCN attention)
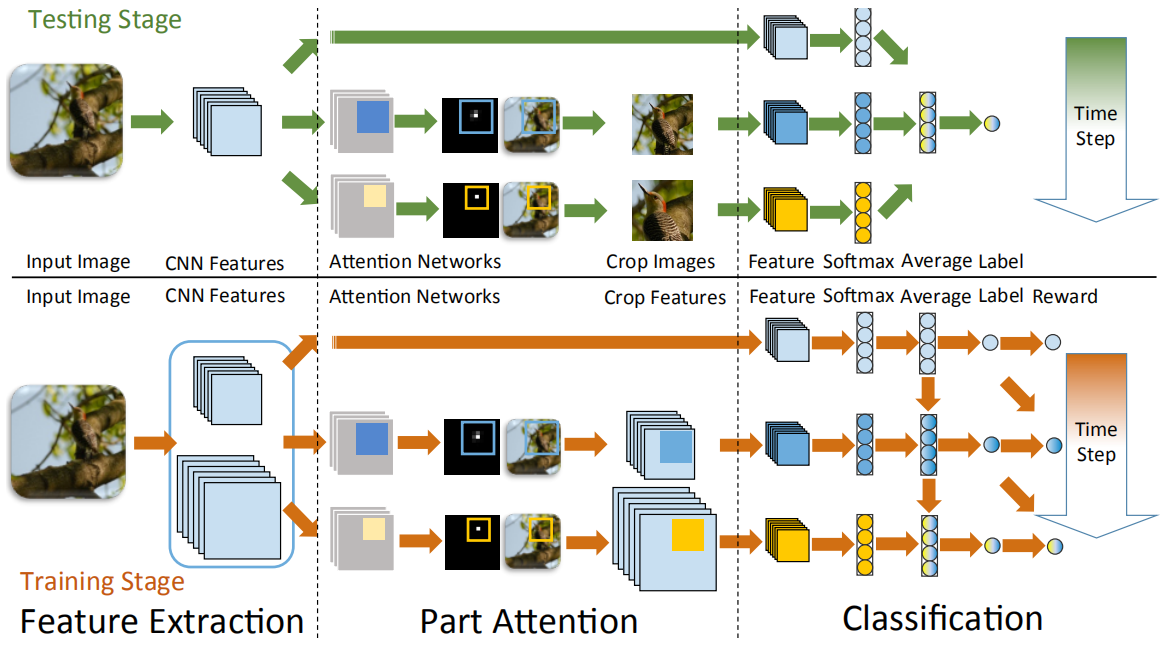
FCN attention是基于强化学习的全卷积注意力定位网络,其能够自适应地选择多任务驱动的注意力区域。由于其基于FCN架构,因而更加高效,并且能够对多个物体部件进行定位,同时提取多个注意力区域的特征。其中,不同部件可以有不同的预定义大小。网络共包括局部定位模块和分类模块。
局部定位模块使用全卷积网络进行部件定位,其基于VGG16模型,输出单通道的自信度映射图。置信度最高的区域被选择作为部件位置。每个时间步都生成一个特定的部件位置。
分类模块对所有部件及整张图像进行分类。对局部图像裁剪到模型输入大小,最后取所有部件及全局预测的均值。
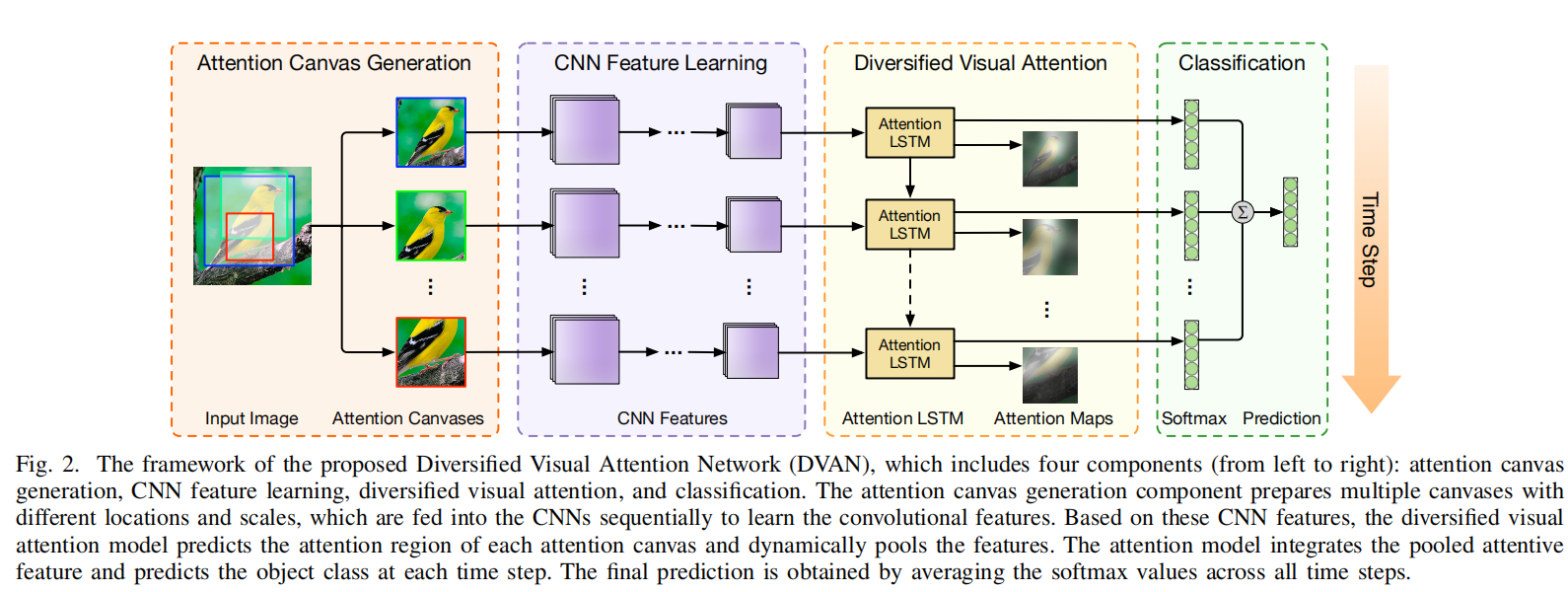
2.2.4 多样化视觉注意力(Diversified visual attention)
DVAN(diversified visual attention network,多样注意力网络 )提高视觉注意力多样性以提取最大程度的判别性特征。包括四个部分:注意力区域生成、CNN特征提取、多样性视觉注意力、分类。 该网络**采用LSTM作为注意力机制**,在不同时间步生成不同的注意力区域。传统注意力模型只关注单个位置,DVAN使用特定的损失函数联合判别多个位置的特征。同时每个时间步都会预测物体类别,最后采用各预测结果的均值。
RACNN
本文中,提出了一个全新的循环注意力卷积神经网络(recurrent attention convolutional neural network——RA-CNN),用互相强化的方式对判别区域注意力(discriminative region attention)和基于区域的特征表征(region-based feature representation)进行递归学习。
在网络结构设计上主要包含3个scale子网络,每个scale子网络的网络结构都是一样的,只是网络参数不一样,在每个scale子网络中包含两种类型的网络:分类网络和APN网络。数据流程为:输入图像通过分类网络提取特征并进行分类,然后attention proposal network(APN)网络基于提取到的特征进行训练得到attention区域信息,再将attention区域crop出来并放大,再作为第二个scale网络的输入,这样重复进行3次就能得到3个scale网络的输出结果,通过融合不同scale网络的结果能达到更好的效果。
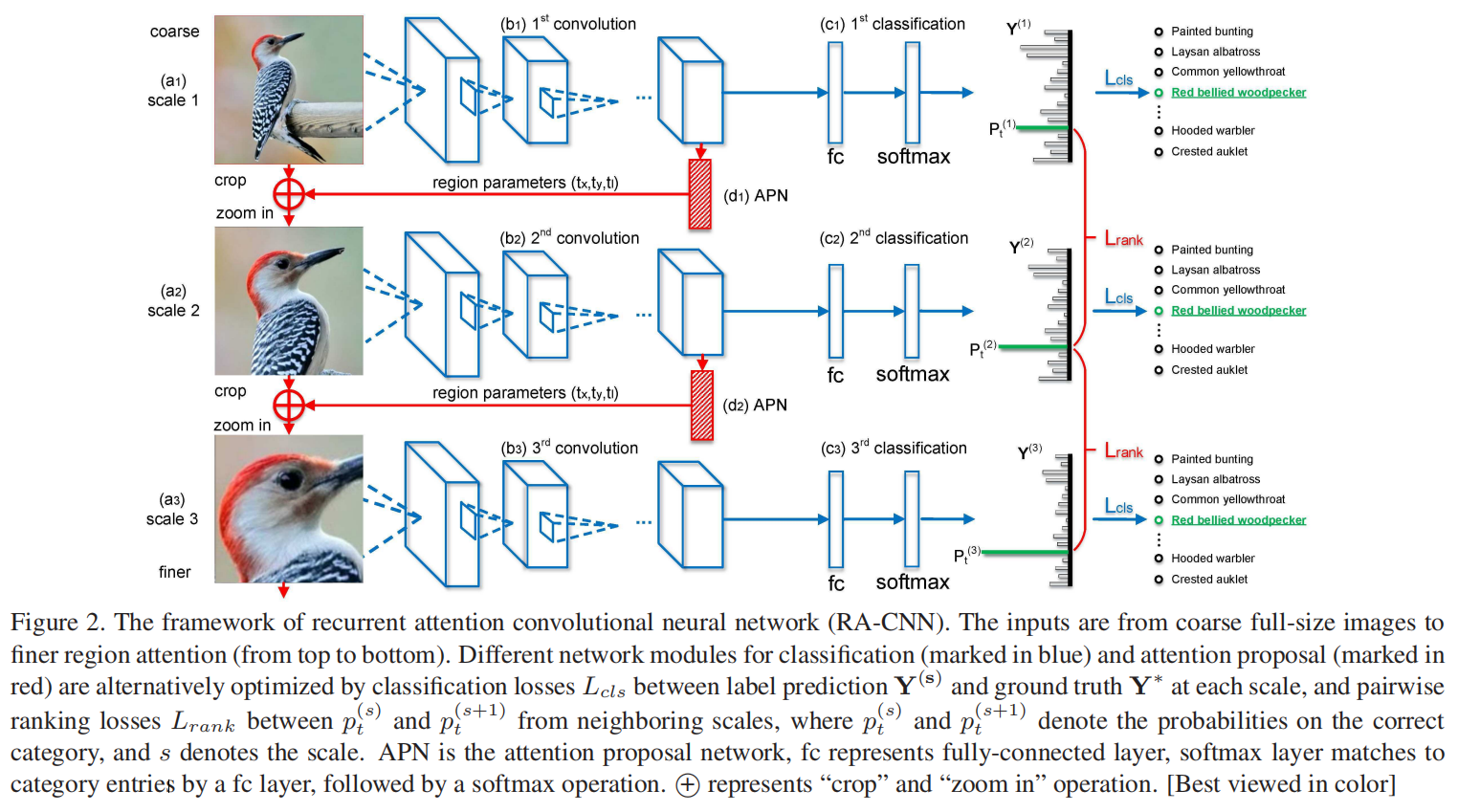
RA-CNN 通过尺度内分类损失(intra-scale classification loss)和尺度间排序损失(inter-scale ranking loss)进行优化,以相互学习精准的区域注意力(region attention)和细粒度表征(fine-grained representation)。RA-CNN 并不需要边界框(bounding box)或边界部分的标注(part annotations),而且可以进行端到端的训练。
本文采用交替优化的方式进行训练。
MACNN
这篇文章提出了一个多注意力卷积神经网络(MA-CNN),让part generation 和 feature learning能互相强化。同时模型抛弃手工标记attention part 的方法,采用弱监督学习方法。(手工标注attention part 难定标注位置,且耗费人力)
本文亮点:
- 利用feature map 不同通道(channels)关注的视觉信息不同,峰值响应区域也不同这一特点,聚类响应区域相近的通道,得到 attention part。
- 由于1中part 定位方式特殊,本文提出了一个channel grouping loss,目的让part内距离更近(intra-class similarity),不同part距离尽量远(inter-class separability)。
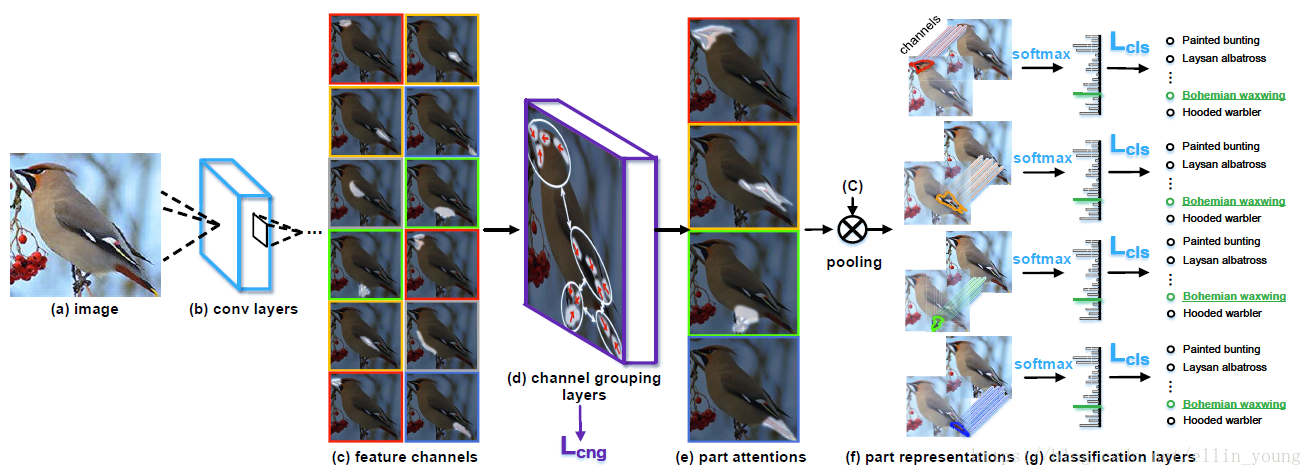
MA-CNN框架如上图所示。模型分为三部分,base network、channel grouping layers 和part classification sub-networks.
输入一张图片(a)给网络,通过base network 产生feature map(b);将(b)中的各通道展开,以12个通道为例,得到(c),可见每个通道都有一个峰值响应区域(白色部分),同时有些通道的峰值响应区域相近(同一种颜色外框表示);文中通过堆叠的全连接层达到聚类效果,把相近的区域归为一类,如图(e),图中划为4类。同类的channel相加,取sigmoid(归一化到0-1)产probabilities,等效于产生4个空间注意区域,即4个mask(局部定位!),这四个mask分别和feature map 进行点乘,得到4个局部精细化的特征,分别进行分类。
MA-CNN 通过交替优化的学习方式(轮流优化两个loss函数),使对每个part的softmax分类损失,及对每个part的channel grouping loss(Lcng)收敛。
MAMC
很多工作是独立的检测一个物体的多个关键性区域,忽略了物体的多个关键性区域的内在关联,因此,学习到的注意力模块很可能集中在同一个区域,并且缺乏本地化多个具有区别特征的部分的能力,这些特征可以区分类似的细粒度类。另外,很多方法都是multi-stage的,不够高效;或者需要很复杂的一些初始化,工作量大。
从大量的实验研究中,作者观察到一种有效的细粒度分类的视觉注意机制应该遵循三个标准:1)检测到的部分要均匀分布在目标体上,提取出不相关的特征;2)各部分特征应该可以单独对不同类的对象进行区分;3)局部区域提取器应轻量化,以便在实际应用中按比例放大。
本文提出的弱监督方法可以高效精确地获取判别区域。如下图所示,本文方法框架有两部分组成:1)压缩-多扩展one-squeeze multi-excitation(OSME)模块,轻微增加计算量(也不算太轻),从多个注意力区域提取特征。2)多注意力多类别约束multi-attention multi-class constraint(MAMC),加强注意力区域之间的通信。本文方法比其他方法具有端到端单阶段的优势。
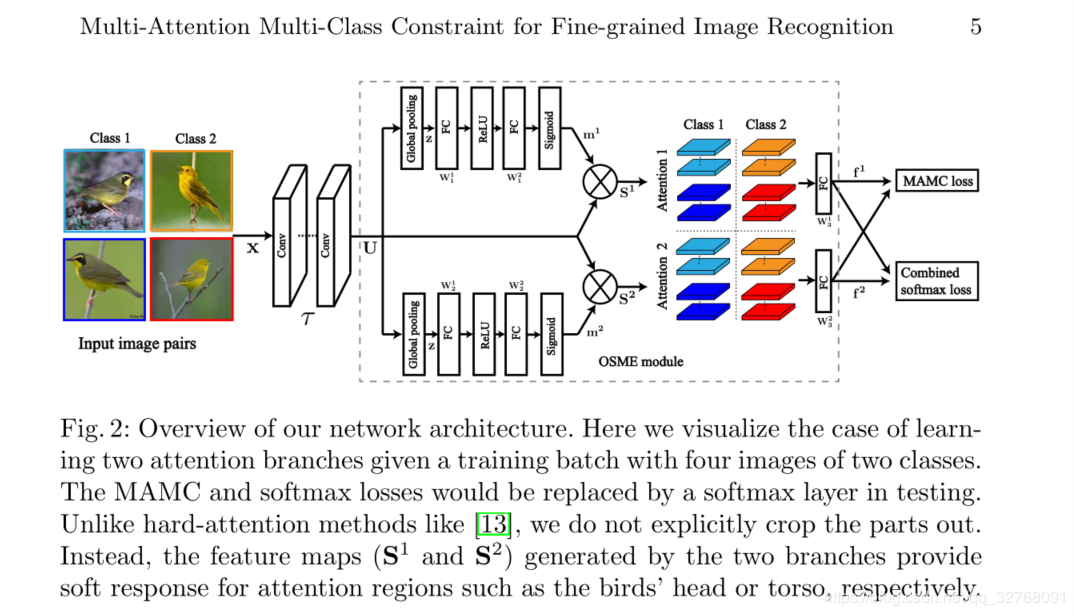
OSME
也是一种弱监督下的部件定位的注意力方法。先前工作总结:1)部件检测。往往将部件检测和特征提取分开,计算开销增大。2)软注意力,来自响应可视化。
如上图,我们的框架以ResNet50作为baseline, SEnet通过压缩-扩展操作对输出特征图再校准。为了产生P个特定注意力的特征图,我们从SEnet延伸,把一次扩展操作换成多次扩展操作。
在压缩操作中,我们聚合特征图空间产生通道级的描述子,和通道数一致。全局平均池化是一种简单高效的通道统计特征描述方法。
在扩展操作中,对通道描述子施加多个独立门机制,产生多个注意力图。门机制中是FC+Relu+FC+Sigmoid,由于sigmoid特性,其输出对通道间的非互斥关系进行了编码。我们利用其输出对起初Resnet50的输出进行再次加权,得到特定注意力图。
为了对每个特定注意力图进行特征提取,将这些特定注意力图展平成向量之后输入进FC层。
简单而言,本文通过对baseline输出全剧平均池化之后进行多次门操作获得P个特征向量。并认为这些特征向量是对不同非互斥部件/特征的聚类(这里还不能称为判别性特征)。
MAMC
下面解决的问题可以描述为,如何让以上模块产生的注意力特征指向类别,产生判别性注意力特征。先前方法总结: 1)把以上注意力特征合并进行softmax loss(指交叉熵损失函数),softmax loss不能掌握两两注意力特征之间的关系,2)递归搜索机制,会把初代误差迭代方放大。还要使用强化学习以及一些复杂的初始化方法。我们的方法在训练中增强两两部件之间的关系。这种方法就是多注意力多类别机制。以下就是度量学习的框架了。
训练集组织:我们有图像-类别对,为了刻画图片之间的注意力和同一子类内的注意力之间的关系,我们重新组织输入Batch(参考度量学习)。参考文章 Improved Deep Metric Learning with Multi-class N-pair Loss Objective中的N-pair采样方法。具体而言就是,每个batch中有N对图片,每对两张图片来自同一个子类,取一个图片为锚点(anchor),另一个为此anchor的正样本,然后给出他们所属类别。那么经过OSME模块,假设有P个excitation,那么每个样本就各自产生P个注意力特征向量。
Learning a Discriminative Filter Bank within a CNN(DFL-CNN)
<Learning a Discriminative Filter Bank within a CNN for Fine-grained Recognition – CVPR2018>
端到端的细粒度识别可以分为两类:一个是定位-分类子网络 ,另一个是端到端特征编码。
第一类方法,定位-分类子网络,包含了由定位网络辅助的分类网络。分类网络的中级学习是由定位网络中定位信息(部位定位和分割掩码)加强的。早期工作是依赖于数据集的额外部位标注信息,最近的只需要分类标签。不管标注信息,这些方法的的共同当即就是先寻找到匹配的部位在比较它们的外观。 第一步要求对象类间的语义部分可以共享,鼓励不同部位之间的表示相似,但是,为了有区分性,第二步鼓励在不同类别之间部位表示是不同的。这种微妙的冲突可能需要在定位网络和分类网络进行权衡,这可能会降低单个集成网络的分类表现。这种权衡也涉及到实践,在训练时,这两个网络往往分开交替训练,因此网络会变得复杂。
第二类方法,端到端的特征编码方法,利用了卷积特征的高阶统计编码(如 bilinear pooling)增强了CNN中层学习能力。与定位分类自网络比较来说,端到端的网络虽然有效,但可解释性和在严格非严格领域的性能很难保持一致性。
作者的主要贡献设计了一个CNN框架中,不需要额外的部分或边框注释,以端到端的方式就可以学习有区别的mid_level patches.这样我们的辨别性patch就不用各个类之间共享,只需要有辨别性的apperance就行了。因此,我们的网络完全专注于classification,避免了识别和定位之间的权衡。
实现是通过1×1的卷积核作为小的‘’部位检测子“设计一个非对称的、多支路的结构来利用patch-level信息和全局外观表示,并且引入了非随机初始化滤波器监督去激活特征块的滤波器。
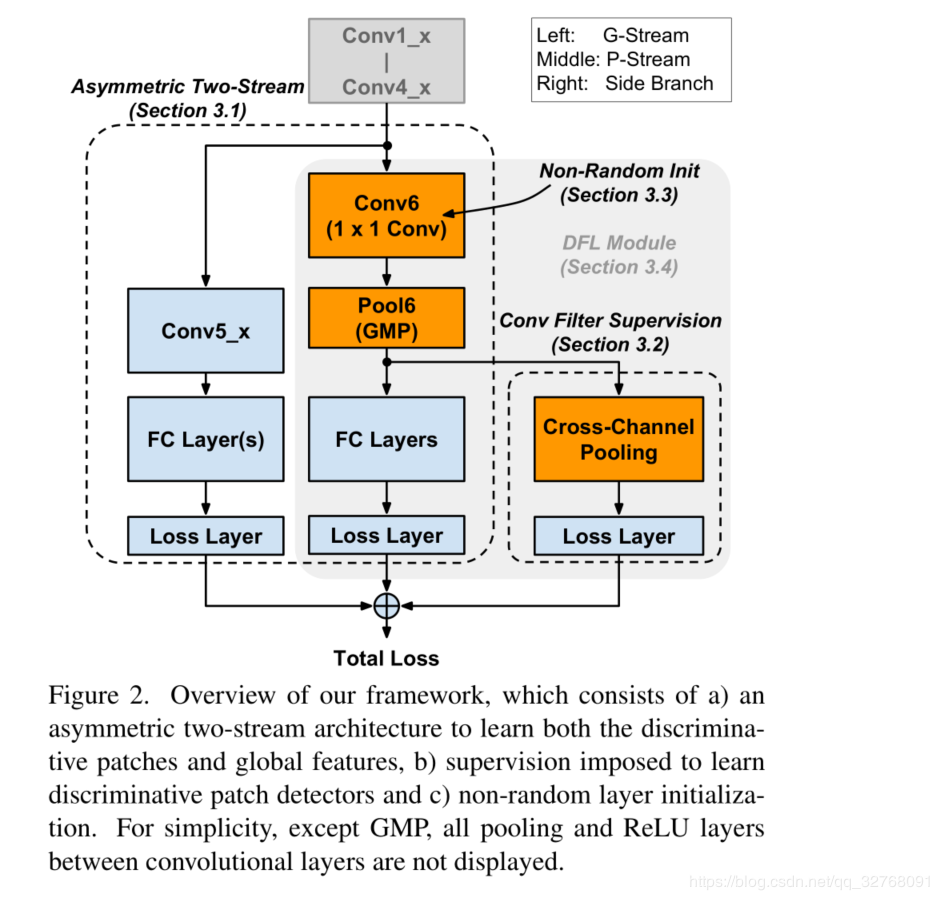
非对称结构的两条支路核心组件如上图所示。
**P-stream:**这个组件后接分类器(比如全连接层和softmax层)形成网络判别的P-stream,其中预测是通过判断判别性块检测子的响应来预测的。P-stream是使用Conv4_3的输出,并且对这个特征图使用较小的感受野,一片的大小为92×92,跨步是8。
**G-stream:**细粒度图像识别还要依赖于全局形状和表观,所以另一个支路保存的是更深的卷积核和全连接,第一个全连接编码全局信息通过线性结合整个卷积特征图。因为这个支路关注于全局信息,所以我们称之为G-stream。
**side-branch:**为了让框架学习特定于类的判别补丁检测器,我们通过引入跨通道池层和softmax损耗层,对多个通道的特征进行综合。
(ECCV 2018) Learning to Navigate for Fine-grained Classification
三、基于网络集成的方法
将细粒度数据集划分为几个相似的子集分别进行分类,或直接使用多个神经网络来提高细粒度分类的性能。
3.1子集特征学习网络(Subset feature learning networks)
Subset feature learning for fine-grained category classification—CVPR2015
包括通用CNN及特定CNN两个部分。
使用大规模数据集上预训练的通用CNN并在细粒度数据集上迁移学习。同时,在其fc6特征上使用LDA降维。
将细粒度数据集中外观相似的类聚类为K个子类,并训练K个特定的CNN。
在测试时,使用子集CNN选择器(subset selector CNN ,SCNN)选择输入图像相应的子集CNN。SCNN使用K个聚类结果作为类标签,将fc8的softmax输出数量改为K。之后,使用最大投票法确定其子类。

3.2 混合DCNN(Mixture of deep CNN)
Fine-grained classification via mixture of deep convolutional neural networks—CVPR2015
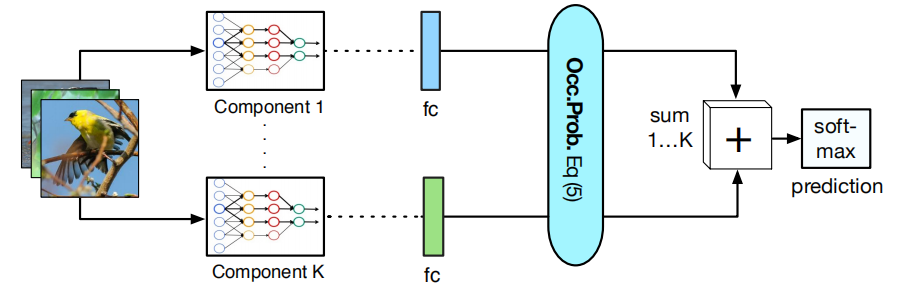
MixDCNN不对数据集进行划分,学习K个特定的CNN。输入图像经过K个CNN,K个子CNN的分类结果通过分类占位概率(occupation probability)进行融合,其定义如下,通过占位概率,MixDCNN可以实现端到端训练。
α k = e C k ∑ c = 1 K e C c \alpha_{k}=\frac{e^{C_{k}}}{\sum_{c=1}^{K} e^{C_{c}}} αk=∑c=1KeCceCk
其中,Ck为第K个CNN的最佳分类结果。
3.3 CNN树(CNN tree)
Learning finegrained features via a CNN tree for large-scale classification —CVPR2015
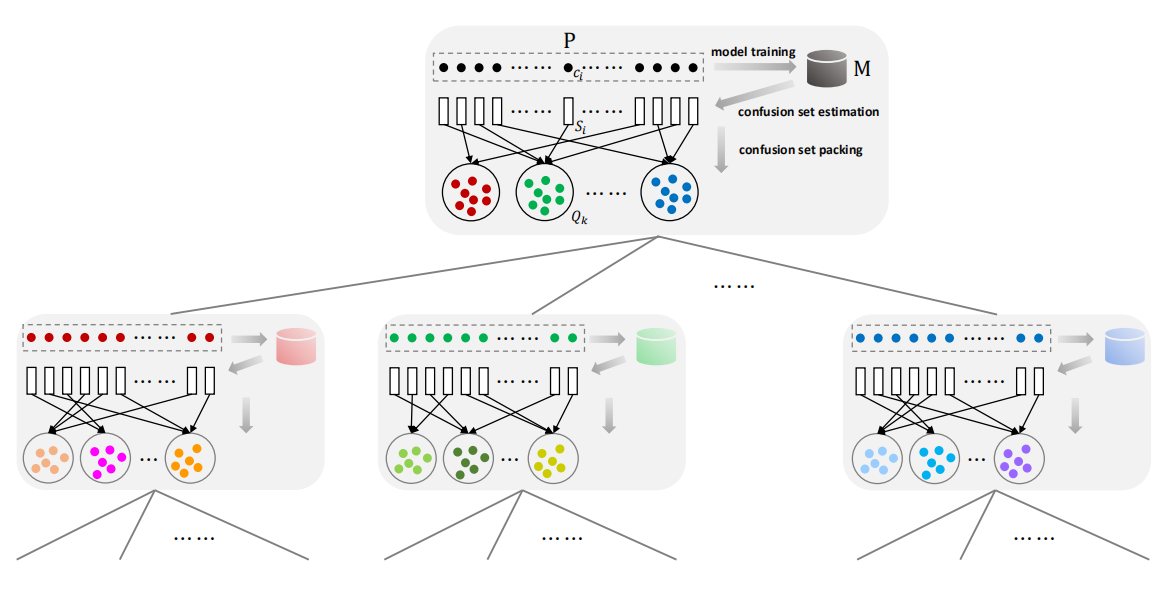
在多分类问题中,某个类通常与其他几个类相混淆,这些容易相互混淆的类被称为混淆集。在混淆集中,应该使用判决性更强的特征对其进行区分。
首先在类集合上训练模型,之后评估训练好模型每个类的混淆集,将各类的混淆集合并为几个混淆超集。之后将混淆超集做为子节点,在其上进一步学习,重复该过程,直到CNN树达到最大深度。
3.4 多粒度CNN( Multiple granularity CNN)
Multiple granularity descriptors for fine-grained categorization —ICCV2015
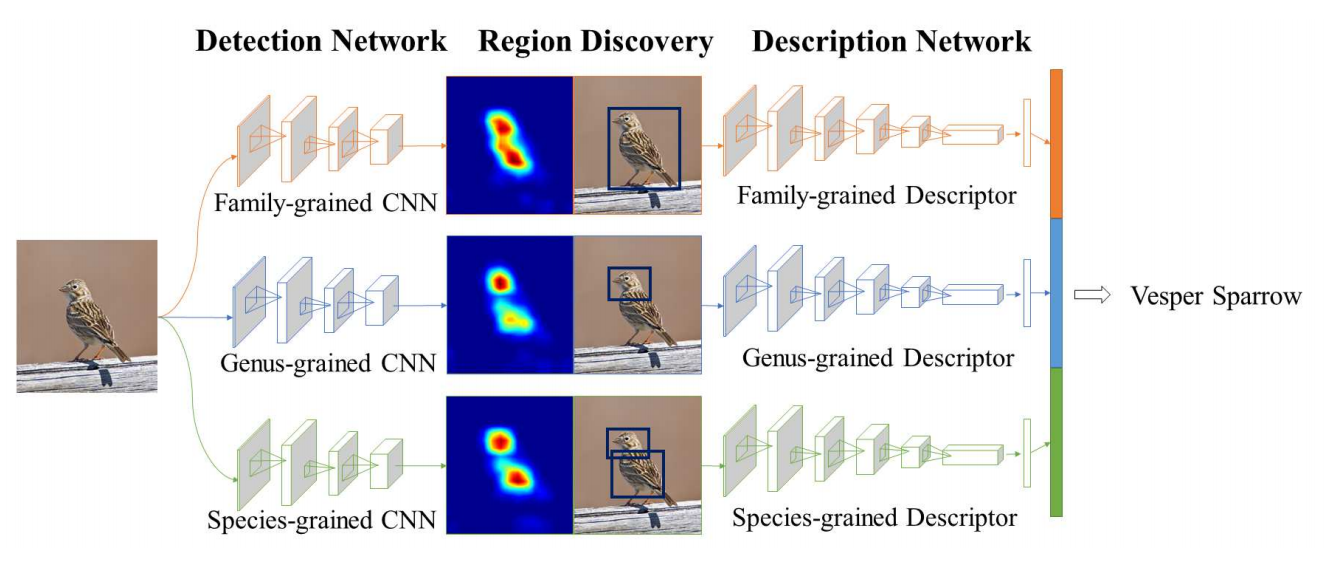
子类标签包含某实体在该类中的层次信息。使用这些层次信息可以训练一系列不同粒度的CNN模型。这些模型的内部特征表示有不同的兴趣域,能够提取覆盖所有粒度的判别性特征。
多粒度CNN包含多个CNN,每个CNN都在给定的粒度进行分类。即多粒度CNN是由多个单粒度识别CNN组成。ROI通过自底向上的区域生成方法生成,与粒度相关。同时,ROI的选择是跨粒度相关的,细粒度的ROI通常是由粗粒度的ROI采样而来。之后,将ROI输入到各个粒度的特征提取网络提取其多粒度特征,最后将多粒度特征合并,产生最终的分类结果。
四、高阶特征编码
双线性汇合(bilinear pooling)在细粒度图像分析及其他领域的进展综述
【AAAI2020系列解读 01】新角度看双线性池化,冗余、突发性问题本质源于哪里?
Bilinear CNN Models for Fine-grained Visual Recognition—ICCV2015
源码
双线性汇合(bilinear pooling)计算不同空间位置的外积,并对不同空间位置计算平均汇合以得到双线性特征。外积捕获了特征通道之间成对的相关关系,并且这是平移不变的。双线性汇合提供了比线性模型更强的特征表示,并可以端到端地进行优化,取得了和使用部位(parts)信息相当或甚至更高的性能。
另一种对Bilinear CNN模型的解释是,网络A的作用是对物体/部件进行定位,即完成前面介绍算法的物体与局部区域检测工作,而网络B则是用来对网络A检测到的物体位置进行特征提取。两个网络相互协调作用,完成了细粒度图像分类过程中两个最重要的任务:物体、局部区域的检测与特征提取。另外,值得一提的是,bilinear模型由于其优异的泛化性能,不仅在细粒度图像分类上取得了优异效果,还被用于其他图像分类任务,如行人重检测(person Re-ID)。
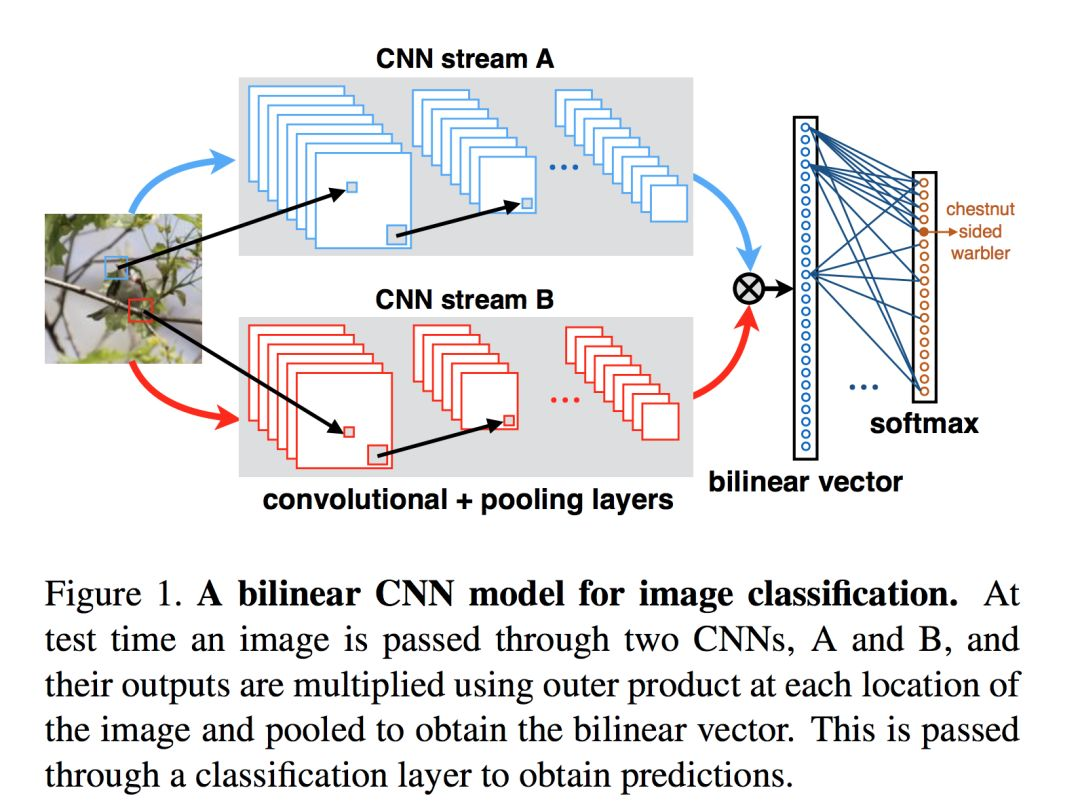
网络架构很简单,主要就是用外积(matrix outer product)来组合两个CNN(A和B)的feature map (当然也可以不用CNN),bilinear layer如下:
bilinear ( l , I , f A , f B ) = f A ( l , I ) T f B ( l , I ) \left(l, I, f_{A}, f_{B}\right)=f_{A}(l, I)^{T} f_{B}(l, I) (l,I,fA,fB)=fA(l,I)TfB(l,I)
- 其中位置 l l l 涵盖了位置和尺度, I I I 是图像。
- fA和fB分别指两个CNN特征提取器,将输入图像I与位置区域L映射为一个cXD 维的特征。f 的维度是(K,D),D是指channel。
- 如果A和B输出的特征维度分别是(K,M)和(K,N),经过bilinear后维度变为(M,N)。
- 求和池化函数(sum pooling)的作用是将所有位置的Bilinear特征汇聚成一个特征。
由于特征的位置维度被池化掉了,得到的bilinear特征是orderless的。另外注意,外积导致特征的维度D 增大为原来的平方。
最后将bilinear特征经过符号平方根变换,并增加l2标准化(elementwise normalization layer),然后输入分类器,完成分类任务。
这里的两个CNN可以共享部分参数,三种不同的方式如下图:

后续研究方向
后续双向性汇合研究方向大致分为两类:设计更好的双线性汇合过程,以及精简双线性汇合。其中,对双线性汇合过程的设计主要包括对汇合结果规范化过程的选择及其高效实现,以及融合一阶和二阶信息。精简双线性汇合设计大致有三种思路:利用PCA降维、近似核计算、以及低秩双线性分类器。
Low-rank Bilinear Pooling for Fine-Grained Classification-CVPR2017
这篇文章的目的是要降低Bilinear pooling模型的参数维度,同时提高模型的精度。论文与第一篇论文模型不同的是,这篇论文采用对称的网络模型,也就是两个steam是相同的,那么只需要训练一个CNN过程就好,大大的减少了计算的开支。同时特征的意义就变为在位置i上特征的相关性矩阵。最后论文采用了一个低秩的分类器进行分类。
Hierarchical Bilinear Pooling for Fine-Grained Visual Recognition
源码:https://github.com/luyao777/HBP-pytorch
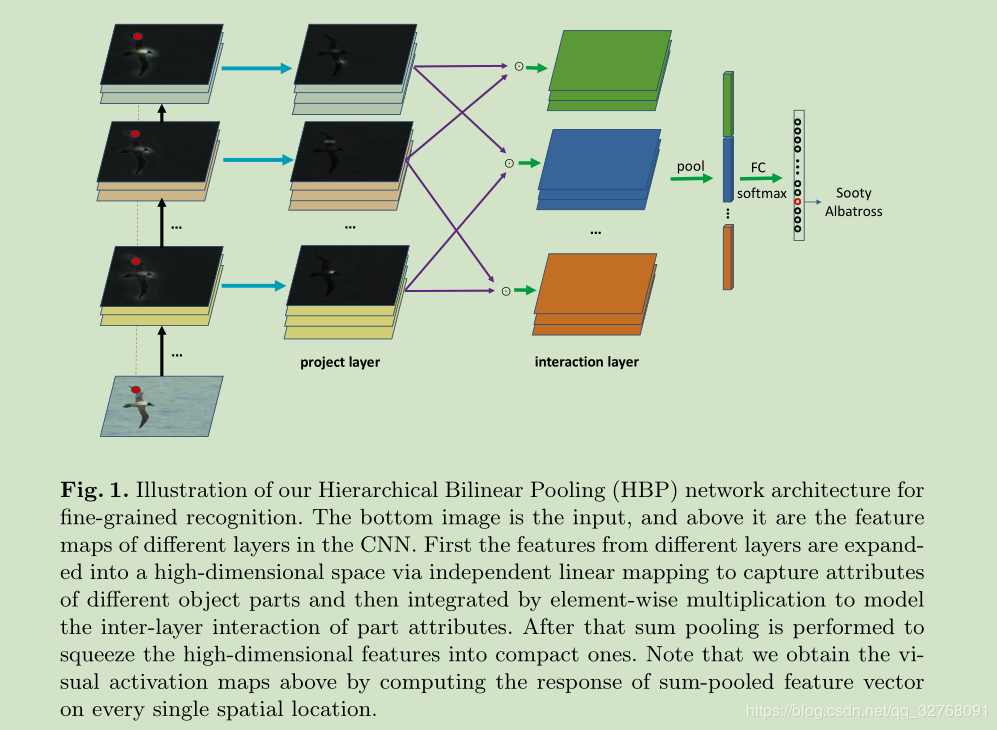
基于Bilinear pooling的模型已经被实验验证了在细粒度认知的有效性,然而很多之前的方法忽略了层间局部特征的交互和细粒度特征的学习是相互关联的同时也能强化彼此。
以此为出发点,作者提出来一种跨层的bilinear pooling方法来捕获层间局部特征关系,然后在这个基础上提出了一种新的分层双线性池框架来集成多个跨层双线性特征,以提高它们的表示能力。
和之前的定位局部来学习细粒度特征不同,作者将来自不同卷积层的激活视为对不同部件属性的响应,而不是显式地定位对象局部,利用跨层双线性池捕获局部特性的跨层间交互,这对于细粒度识别非常有用。
Higher-Order Integration of Hierarchical Convolutional Activations for Fine-Grained Visual Categorization ICCV2017
针对细粒度分类的难点,1. part annotation 和 detection 需要专业知识且很多part-based方法都是为了训练精确的 part detector 而严重依赖于精确地 part annotation; 2. Parts 通常有很多尺寸,而深度计卷积中的每个点对应一个特定的感受野,因此单层卷积层在描述不同尺寸的 part 时能力有限;3. Part 与 part 之间的关系是复杂的,高阶的。对于目标外形建模的关键在于发掘目标局部的共同外形。但缺陷是只能发掘很少 part 的一阶关系。
本文针对以上问题,提出了基于融合高阶的多等级的卷积特征(Hierarchical convolutional activations) 。如果把卷积特征作为局部描述子 ,那么多等级的卷及特征就可以是不同尺度的局部特描述子。在处理 part interaction 的问题时,作者通过核融合的方法,使用多项式描述子将不同层的特征综合在一起。本文的创新点在于为融合不同层的的卷积响应开辟了新视角。
总结
在细粒度分类任务由于存在较大的类内差异和细微的内间差异,导致传统的人工特征工程无法达到理想效果。深度学习的出现,为该任务带来巨大的效果提升,在许多场景中达到实用的水平。本文综述了目前常见的三类基于深度学习的细粒度图像分类方法。
基于定位-分类的方法借鉴了人类进行细粒度分类的过程,研究相对充分,是最主流的方法。早期,基于定位-分类的方法多采用强监督学习,需要大量的人工来标注图像的关键区域。Part R-CNN[3]是较早采用区域定位技术的细粒度分类算法,其进步是明显的. 从局部区域的检测定位, 到特征的提取, 该算法均基于卷积神经网络, 并针对细粒度图像的特点进行改进优化, 以改进通用物体定位检测算法在该任务上的不足, 达到了一个相对比较高的准确度. 其不足之处在于, 利用自底向上的区域产生方法, 会产生大量无关区域, 这会在很大程度上影响算法的速度. 另一方面, 该算法本身的创新性十分有限, 既然局部区域对于细粒度图像而言是关键所在, 那么对其进行定位检测则是必要的途径. 只是引入现有的通用定位算法, 似乎并不能很好地解决该问题。在此基础上,后续有很多改进算法,例如Pose Normalized CNN[4]通过姿态对齐操作,减小了类内差异。而part stacked CNN[5] 和mask-CNN[6]则利用FCN进行区域定位,提高了定位精度。
近年来,由于工业领域的应用需要,基于定位-分类方法的研究逐渐向弱监督学习转移,通过注意力机制、通道聚类等方法构建定位子网络,实现区分性区域的发现。其中,两级注意力(Two Level Attention)算法[7]是第一个尝试不依赖额外的标注信息, 而仅仅使用类别标签来完成细粒度图像分类的工作,该方法通过聚类实现区域定位,准确度有限。此后,RNN、LSTM以及FCN等网络被当做注意力机制引入弱监督方法中来,进一步提升定位的准确度。在定位子网络的基础上,MAMC[12]等网络引入了空间约束,改善定位区域的辨识度。
高阶编码方法通过将CNN特征进行高阶综合,提升特征的表达能力,其最主要的技术路线是双线性模型[13],此外,Higher-Order Integration of Hierarchical Convolutional Activations[2]通过核融合方式为高阶编码提供了新的视角。
Bilinear模型提供了比线性模型更强的特征表示,并可以端到端地进行优化,取得了和使用部位(parts)信息相当或甚至更高的性能,其缺点在于外积导致特征的维度 增大为原来的平方。
后续双向性汇合研究方向大致分为两类:设计更好的双线性汇合过程,以及精简双线性汇合。其中,对双线性汇合过程的设计主要包括对汇合结果规范化过程的选择及其高效实现,以及融合一阶和二阶信息。精简双线性汇合设计大致有三种思路:利用PCA降维、近似核计算、以及低秩双线性分类器。
网络集成方法采用了分而治之的思想,主要方法是将细粒度数据集划分为几个相似的子集分别进行分类,或直接使用多个神经网络来提高细粒度分类的性能。当某些类特别容易混淆时,采用该方法能取得不错的效果,缺点是认为干预的因素较多,不能采用端到端的学习方式。
其它相关
or-wavelet:https://blog.csdn.net/qq_41332469/article/details/93197565
消除Aliasing!加州大学&英伟达提出深度学习下采样新思路:自适应低通滤波器层
ECCV2020 | Cityscapes上83.7 mIoU,通过解耦的主体和边缘监督改进语义分割
【图像分类】细粒度图像分类—-文末有细粒度分类的相关竞赛介绍
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186097.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
