大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1.基础
1.1 时序数据的定义
什么是时间序列数据(Time Series Data,TSD,以下简称时序)从定义上来说,就是一串按时间维度索引的数据。用描述性的语言来解释什么是时序数据,简单的说,就是这类数据描述了某个被测量的主体在一个时间范围内的每个时间点上的测量值。它普遍存在于IT基础设施、运维监控系统和物联网中。
对时序数据进行建模的话,会包含三个重要部分,分别是:主体,时间点和测量值。套用这套模型,你会发现你在日常工作生活中,无时无刻不在接触着这类数据。
如果你是一个股民,某只股票的股价就是一类时序数据,其记录着每个时间点该股票的股价。
如果你是一个运维人员,监控数据是一类时序数据,例如对于机器的CPU的监控数据,就是记录着每个时间点机器上CPU的实际消耗值。
时序数据从时间维度上将孤立的观测值连成一条线,从而揭示软硬件系统的状态变化。孤立的观测值不能叫时序数据,但如果把大量的观测值用时间线串起来,我们就可以研究和分析观测值的趋势及规律。
1.2 时序数据的特点
1.2.1 时序数据的数学模型
上面介绍了时序数据的基本概念,也说明了分析时序数据的意义。那么时序数据该怎样存储呢?数据的存储要考虑其数学模型和特点,时序数据当然也不例外。所以这里先介绍时序数据的数学模型和特点。
下图为一段时序数据,记录了一段时间内的某个集群里各机器上各端口的出入流量,每半小时记录一个观测值。这里以图中的数据为例,介绍下时序数据的数学模型(不同的时序数据库中,基本概念的称谓有可能不同,这里以腾讯CTSDB为准):
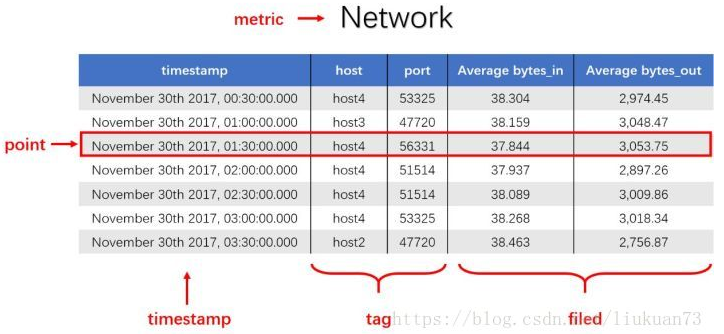

measurement: 度量的数据集,类似于关系型数据库中的 table;
point: 一个数据点,类似于关系型数据库中的 row;
timestamp: 时间戳,表征采集到数据的时间点;
tag: 维度列,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用;
field: 指标列,代表数据的测量值,随时间平滑波动,不需要查询。
如上图所示,这组数据的measurement为Network,每个point由以下部分组成:
timestamp:时间戳
两个tag:host、port,代表每个point归属于哪台机器的哪个端口
两个field:bytes_in、bytes_out,代表piont的测量值,半小时内出入流量的平均值
同一个host、同一个port,每半小时产生一个point,随着时间的增长,field(bytes_in、bytes_out)不断变化。如host:host4,port:51514,timestamp从02:00 到02:30的时间段内,bytes_in 从 37.937上涨到38.089,bytes_out从2897.26上涨到3009.86,说明这一段时间内该端口服务压力升高。
1.2.2 时序数据特点
数据模式: 时序数据随时间增长,相同维度重复取值,指标平滑变化:这点从上面的Network表的数据变化可以看出。
写入: 持续高并发写入,无更新操作:时序数据库面对的往往是百万甚至千万数量级终端设备的实时数据写入(如摩拜单车2017年全国车辆数为千万级),但数据大多表征设备状态,写入后不会更新。
查询: 按不同维度对指标进行统计分析,且存在明显的冷热数据,一般只会频繁查询近期数据。
1.3 时序数据的存储
1.3.1 传统关系型数据库存储时序数据的问题
有了时序数据后,该存储在哪里呢?首先我们看下传统的关系型数据库解决方案在存储时序数据时会遇到什么问题。
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题。但时序数据往往是由百万级甚至千万级终端设备产生的,写入并发量比较高,属于海量数据场景。
MySQL在海量的时序数据场景下存在如下问题:
存储成本大:对于时序数据压缩不佳,需占用大量机器资源;
维护成本高:单机系统,需要在上层人工的分库分表,维护成本高;
写入吞吐低:单机写入吞吐低,很难满足时序数据千万级的写入压力;
查询性能差:适用于交易处理,海量数据的聚合分析性能差。
另外,使用Hadoop生态(Hadoop、Spark等)存储时序数据会有以下问题:
数据延迟高:离线批处理系统,数据从产生到可分析,耗时数小时、甚至天级;
查询性能差:不能很好的利用索引,依赖MapReduce任务,查询耗时一般在分钟级。
可以看到时序数据库需要解决以下几个问题:
时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
时序数据的读取:如何支持在秒级对上亿数据的分组聚合运算。
成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
1.3.2 时序数据库
时序数据库产品的发明都是为了解决传统关系型数据库在时序数据存储和分析上的不足和缺陷,这类产品被统一归类为时序数据库。
针对时序数据的特点对写入、存储、查询等流程进行了优化,这些优化与时序数据的特点息息相关:
存储成本:
利用时间递增、维度重复、指标平滑变化的特性,合理选择编码压缩算法,提高数据压缩比;
通过预降精度,对历史数据做聚合,节省存储空间。
高并发写入:
批量写入数据,降低网络开销;
数据先写入内存,再周期性的dump为不可变的文件存储。
低查询延时,高查询并发:
优化常见的查询模式,通过索引等技术降低查询延时;
通过缓存、routing等技术提高查询并发。
1.3.3 时序数据的存储原理
传统数据库存储采用的都是 B tree,这是由于其在查询和顺序插入时有利于减少寻道次数的组织形式。我们知道磁盘寻道时间是非常慢的,一般在 10ms 左右。磁盘的随机读写慢就慢在寻道上面。对于随机写入 B tree 会消耗大量的时间在磁盘寻道上,导致速度很慢。我们知道 SSD 具有更快的寻道时间,但并没有从根本上解决这个问题。
对于 90% 以上场景都是写入的时序数据库,B tree 很明显是不合适的。
业界主流都是采用 LSM tree 替换 B tree,比如 Hbase, Cassandra 等 nosql 。这里我们详细介绍一下。
LSM tree 包括内存里的数据结构和磁盘上的文件两部分。分别对应 Hbase 里的 MemStore 和 HLog;对应 Cassandra 里的 MemTable 和 sstable。
LSM tree 操作流程如下:
数据写入和更新时首先写入位于内存里的数据结构。为了避免数据丢失也会先写到 WAL 文件中。
内存里的数据结构会定时或者达到固定大小会刷到磁盘。这些磁盘上的文件不会被修改。
随着磁盘上积累的文件越来越多,会定时的进行合并操作,消除冗余数据,减少文件数量。
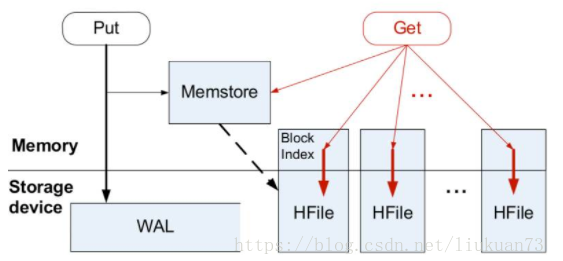
可以看到 LSM tree 核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。但同时也牺牲了读取性能,因为同一个 key 的值可能存在于多个 HFile 中。为了获取更好的读取性能,可以通过 bloom filter 和 compaction 得到,这里限于篇幅就不详细展开。
1.3.4 分布式存储
时序数据库面向的是海量数据的写入存储读取,单机是无法解决问题的。所以需要采用多机存储,也就是分布式存储。
分布式存储首先要考虑的是如何将数据分布到多台机器上面,也就是分片(sharding)问题。下面我们就时序数据库分片问题展开介绍。分片问题由分片方法的选择和分片的设计组成。
分片方法
时序数据库的分片方法和其他分布式系统是相通的。
哈希分片:这种方法实现简单,均衡性较好,但是集群不易扩展。
一致性哈希:这种方案均衡性好,集群扩展容易,只是实现复杂。代表有 Amazon 的 DynamoDB 和开源的 Cassandra。
范围划分:通常配合全局有序,复杂度在于合并和分裂。代表有 Hbase。
分片设计
分片设计简单来说就是以什么做分片,这是非常有技巧的,会直接影响写入读取的性能。
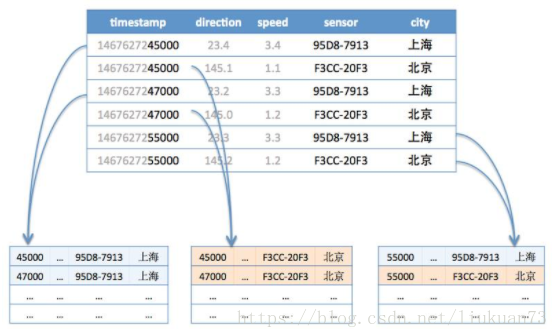
**结合时序数据库的特点,根据 measurement+tags 分片是比较好的一种方式,因为往往会按照一个时间范围查询,这样相同 metric 和 tags 的数据会分配到一台机器上连续存放,顺序的磁盘读取是很快的。**再结合上面讲到的单机存储内容,可以做到快速查询。
进一步我们考虑时序数据时间范围很长的情况,需要根据时间范围再分成几段,分别存储到不同的机器上,这样对于大范围时序数据就可以支持并发查询,优化查询速度。
如下图,第一行和第三行都是同样的 tag(sensor=95D8-7913;city= 上海),所以分配到同样的分片,而第五行虽然也是同样的 tag,但是根据时间范围再分段,被分到了不同的分片。第二、四、六行属于同样的 tag(sensor=F3CC-20F3;city= 北京)也是一样的道理。
1.4 开源时序数据库介绍
1.4.1开源时序数据库对比
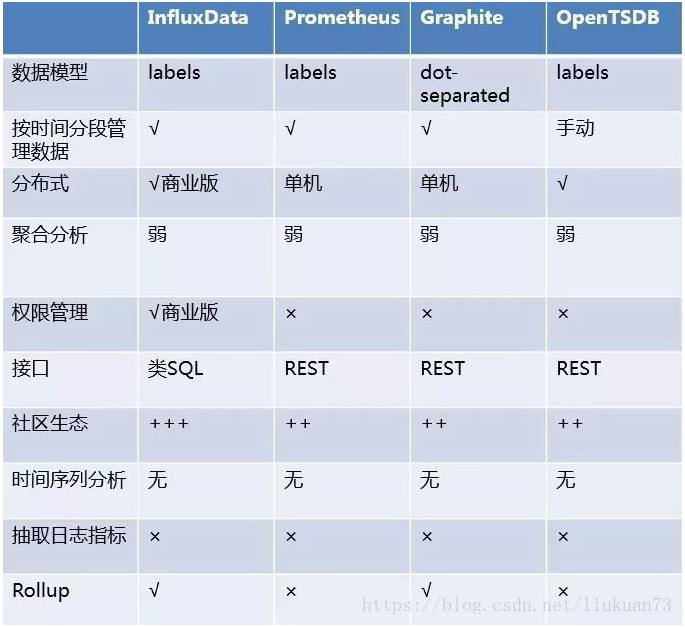
目前行业内比较流行的开源时序数据库产品有 InfluxDB、OpenTSDB、Prometheus、Graphite,还有Druid等,其产品特性对比如下图所示:
1.4.2 InfluxDB介绍
InfluxDB是一个开源的时序数据库,使用GO语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。而InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。
重要概念
influxdb里面有一些重要概念:database,timestamp,field key, field value, field set,tag key,tag value,tag set,measurement, retention policy ,series,point。结合下面的例子数据来说明这几个概念:
name: census
-————————————
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 12 23 1 langstroth
2015-08-18T00:00:00Z 1 30 1 perpetua
2015-08-18T00:06:00Z 11 28 1 langstroth
2015-08-18T00:06:00Z 3 28 1 perpetua
2015-08-18T05:54:00Z 2 11 2 langstroth
2015-08-18T06:00:00Z 1 10 2 langstroth
2015-08-18T06:06:00Z 8 23 2 perpetua
2015-08-18T06:12:00Z 7 22 2 perpetua
timestamp
既然是时间序列数据库,influxdb的数据都有一列名为time的列,里面存储UTC时间戳。
field key,field value,field set
butterflies和honeybees两列数据称为字段(fields),influxdb的字段由field key和field value组成。其中butterflies和honeybees为field key,它们为string类型,用于存储元数据。
而butterflies这一列的数据12-7为butterflies的field value,同理,honeybees这一列的23-22为honeybees的field value。field value可以为string,float,integer或boolean类型。field value通常都是与时间关联的。
field key和field value对组成的集合称之为field set。如下:
butterflies = 12 honeybees = 23
butterflies = 1 honeybees = 30
butterflies = 11 honeybees = 28
butterflies = 3 honeybees = 28
butterflies = 2 honeybees = 11
butterflies = 1 honeybees = 10
butterflies = 8 honeybees = 23
butterflies = 7 honeybees = 22
在influxdb中,字段必须存在。注意,字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下,fields相当于SQL的没有索引的列。
tag key,tag value,tag set
location和scientist这两列称为标签(tags),标签由tag key和tag value组成。location这个tag key有两个tag value:1和2,scientist有两个tag value:langstroth和perpetua。tag key和tag value对组成了tag set,示例中的tag set如下:
location = 1, scientist = langstroth
location = 2, scientist = langstroth
location = 1, scientist = perpetua
location = 2, scientist = perpetua
tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型 如果你的常用场景是根据butterflies和honeybees来查询,那么你可以将这两个列设置为tag,而其他两列设置为field,tag和field依据具体查询需求来定。
measurement
measurement是fields,tags以及time列的容器,measurement的名字用于描述存储在其中的字段数据,类似mysql的表名。如上面例子中的measurement为census。measurement相当于SQL中的表,本文中我在部分地方会用表来指代measurement。
retention policy
retention policy指数据保留策略,示例数据中的retention policy为默认的autogen。它表示数据一直保留永不过期,副本数量为1。你也可以指定数据的保留时间,如30天。
series
series是共享同一个retention policy,measurement以及tag set的数据集合。示例中数据有4个series,如下:
Arbitrary series number Retention policy Measurement Tag set
series 1 autogen census location = 1,scientist = langstroth
series 2 autogen census location = 2,scientist = langstroth
series 3 autogen census location = 1,scientist = perpetua
series 4 autogen census location = 2,scientist = perpetua
point
point则是同一个series中具有相同时间的field set,points相当于SQL中的数据行。如下面就是一个point:
name: census
—————–
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 1 30 1 perpetua
database
上面提到的结构都存储在数据库中,示例的数据库为my_database。一个数据库可以有多个measurement,retention policy, continuous queries以及user。influxdb是一个无模式的数据库,可以很容易的添加新的measurement,tags,fields等。而它的操作却和传统的数据库一样,可以使用类SQL语言查询和修改数据。
influxdb不是一个完整的CRUD数据库,它更像是一个CR-ud数据库。它优先考虑的是增加和读取数据而不是更新和删除数据的性能,而且它阻止了某些更新和删除行为使得创建和读取数据更加高效。
更多详细介绍请见:https://www.jianshu.com/p/a1344ca86e9b
———————
作者:liukuan73
来源:CSDN
原文:https://blog.csdn.net/liukuan73/article/details/79950329
版权声明:本文为博主原创文章,转载请附上博文链接!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/186009.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
