大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
数据库的模型包含关系型、key-value 型、Document 型等很多种,那么为什么新型的时序数据库成为监控数据存储的新宠呢? 下面就会从
为什么需要时序数据库?
时序数据库的数据结构
两个方面来介绍一下时序数据库。
1. 为什么需要时序数据库
1.1 时序数据特点
时序数据有如下几个特点:
基本上是插入操作较多且无更新的需求
数据带有时间属性,且数据量随着时间递增
插入数据多,每秒钟插入需要可到达千万甚至是上亿的数据量
查询、聚合等操作主要针对近期插入的数据
时序数据能够还原数据的变化状态
可以通过分析过去时序数据的变化、检测现在的变化,以达到预测未来如何变化的目的
时序数据使用需求:
能够按照指标筛选数据
能够按照区间、时间范围、统计信息聚合展示数据
1.2 why
为什么不用一个「常规」 的数据库?
事实上,你完全可以可以使用非时序序列的数据库,并且也确实有人是这样做的。
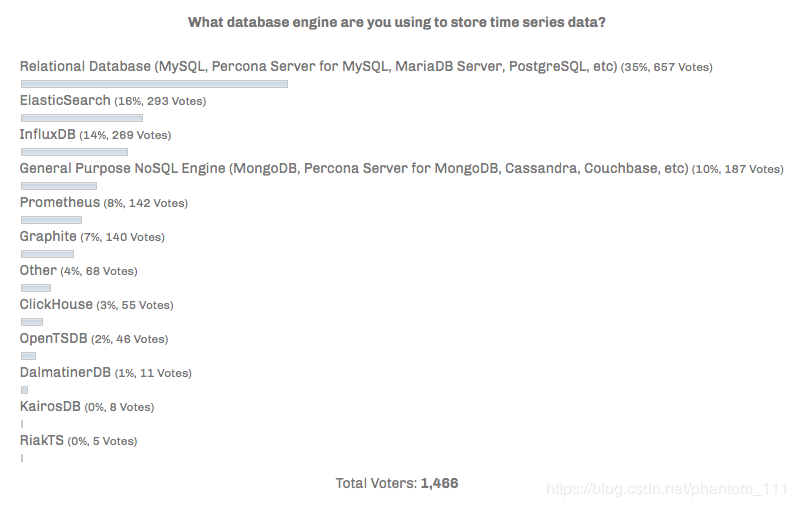

**注**: 数据源 Percona,2017 年 2 月.
为什么需要时序数据库?
规模
时间数据的特点是累计速度非常快,常规数据库在设计之初,并非是为了处理这种规模的数据,而且关系型数据库在处理大规模的数据集的效果非常差。
使用特性
时序数据库能够提供一些通用的对时间序列数据分析的功能和操作,比如数据保留策略、连续查询、灵活的时间聚合,此外时序数据库以时间为维度,也提供更快的大规模查询、更好的数据压缩等。
1.3 场景选择
是否所有的数据都适合用时序数据库来存储?
答案:是否定的,时序数据库提供了针对大量数据的插入操作,但同时数据的读取延迟也相对增加。而且时序数据库不支持 SQL 的数据查询。
主要适用时序数据库的场景:
监控软件系统: 虚拟机、容器、服务、应用
监控物理系统: 水文监控、工厂的设备监控、国家安全相关的数据监控、通讯监控、传感器数据、血糖仪、血压变化、心率等
资产跟踪应用: 汽车、卡车、物理容器、运货托盘
金融交易系统: 传统证券、新兴的加密数字货币
事件应用程序: 跟踪用户、客户的交互数据
商业智能工具: 跟踪关键指标和业务的总体健康情况
2. 时序数据库的数据结构
传统数据库存储采用的都是 B+ tree,原因是查询和顺序插入时有利于减少寻道次数的。然而对于 90% 以上场景都是写入的时序数据库,使用了 LSM tree 更合适。
2.1 LSM产生背景
LSM (Log Structured Merge Trees) 通过减少随机的本地更新操作来达到更好的写操作的吞吐量。
影响写操作吞吐量的主要原因还是磁盘的随机操作慢,顺序读写快,解决办法是将文件的随机存储改为顺序存储,因为完全是顺序的,提升写操作性能,比如日志文件就是顺序写入。
写数据的问题解决了,那如何快速的读出数据呢?
顺序写入的日志文件,在读取一些数据的时候需要全文扫描,但这一操作耗时取决于需要读取的数据在日志文件中的位置,所以其使用场景有限,适用于数据被整体的访问的情况下,像大部分数据的 WAL。
对于读操作,可以记录更多的内容比如 key、range 来提高性能,比较常用的方法有:
二分查找:将文件数据有序保存,使用二分查找来完成特定 key 的查找。
哈希:用哈希将数据分为不同的 bucket。
B+ 树:使用 B+ 树,减少外部文件的存取。
以上的方案都是将数据按照特定的方式存储,对于读操作友好,但写操作的性能必然下降,主要原因是这种存储数据产生的是磁盘的随机读写,不适用于时序数据库 90% 都是写入的场景。
2.2 LSM 算法
LSM 是将之前使用的一个大的查找结构(造成随机读写,影响写性能的结构,比如 B+ 树),变换为将写操作顺序的保存到有序文件中,且每个文件只保存短时间内的改动。文件是有序的,所以读取的时候,查找会非常快 。且文件不可修改,新的更新操作只会写入到新的文件中。读操作检查有序的文件。然后周期性的合并文件来减少文件的个数。
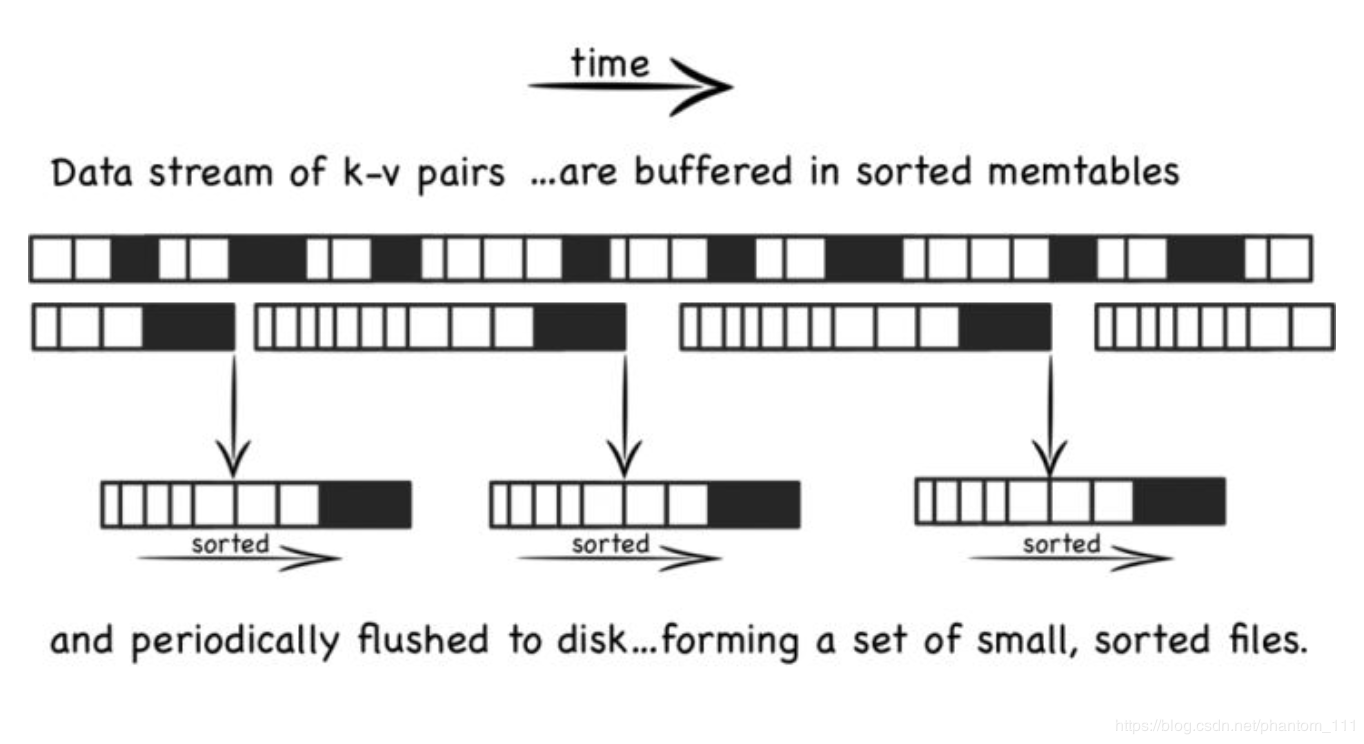
写入操作
数据先在内存中缓存(memtable) 中,memtable 使用树的结构来保持 key 是有序的,同时使用 WAL 的方式备份数据到磁盘。当 memtable 中数据达到一定规模后会刷新数据到磁盘生成文件。
更新写入操作
文件不允许被编辑,所以新的内容或修改只是简单的生成新的文件。当越多的数据存储到系统中,就会有越多的不可修改、顺序的有序文件被创建。但比较旧的文件不会被更新,重复的激流只会通过创建新的记录来达到覆盖的目的,但这这就产生了冗余的数据。
系统会周期性的执行合并的操作,合并操作用于移除重复的更新或者删除记录,同时还能够减少文件个数的增加,保证读操作的性能。
读取操作
查询的时候首先检查内存数据(memtable),如果没有找到这个 key,就会逆序的一个个的检查磁盘上的文件,但读操作耗时会随着磁盘上文件个数的增加而增加。(O(K log N), K为文件个数, N 为文件平均大小)。可以使用如下策略减少耗时
将文件按照 LRU 缓存到内存中
周期性的合并文件,减少文件的个数
使用布隆过滤器避免大量的读文件操作(如果bloom说一个key不存在,就一定不存在,而当bloom说一个文件存在是,可能是不存在的,只是通过概率来保证)
2.3 时序数据库的存储
单机上的存储
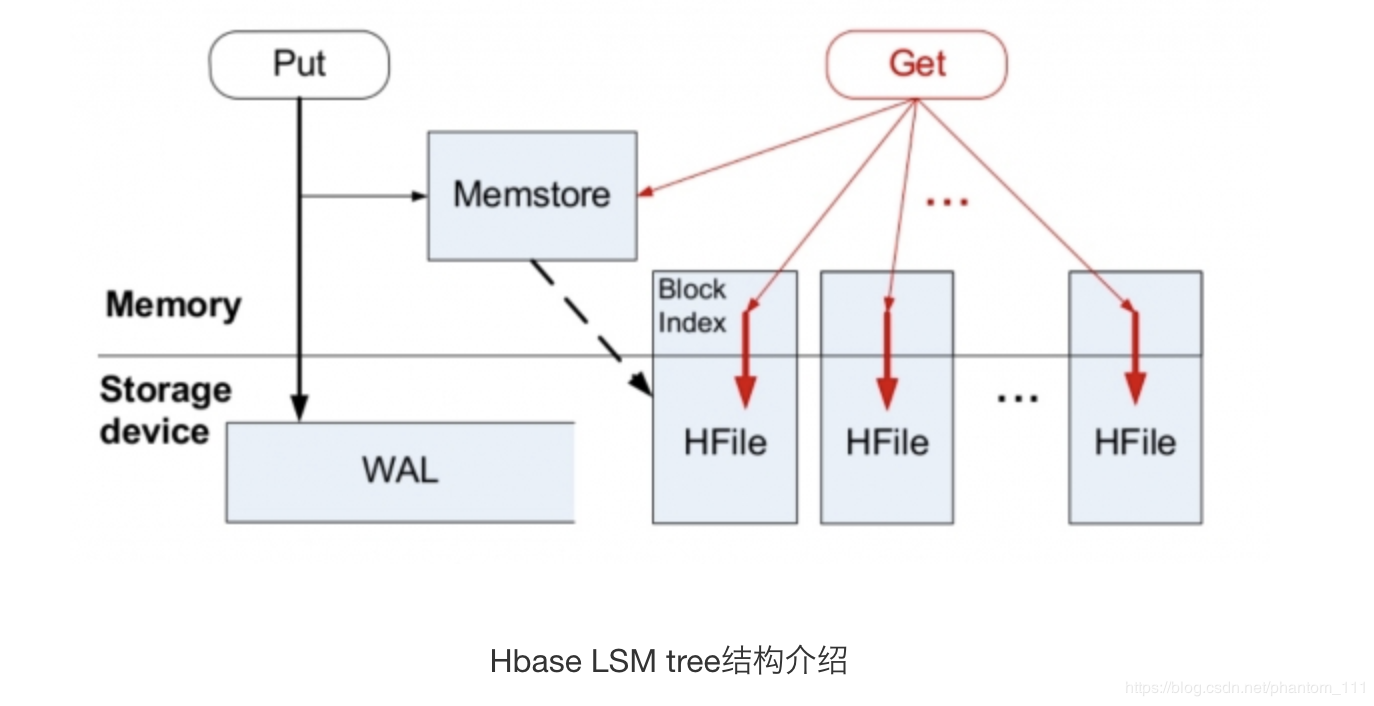
核心就是通过内存写和后序磁盘的顺序写入获取更高的写入性能,避免随机写入,但同时也牺牲了读取性能
分布式存储
分布式存储需要考虑如何将数据分布到多台机器上面,即分片(sharding)的问题。分片问题包括分片方法的选择和分片的设计问题。
分片方法:
哈希分片: 均衡性较好,但集群不易扩展
执行哈希:均衡性好,集群扩展易,但实现复杂
范围划分:复杂度在于合并和分裂,全局有序
分片设计
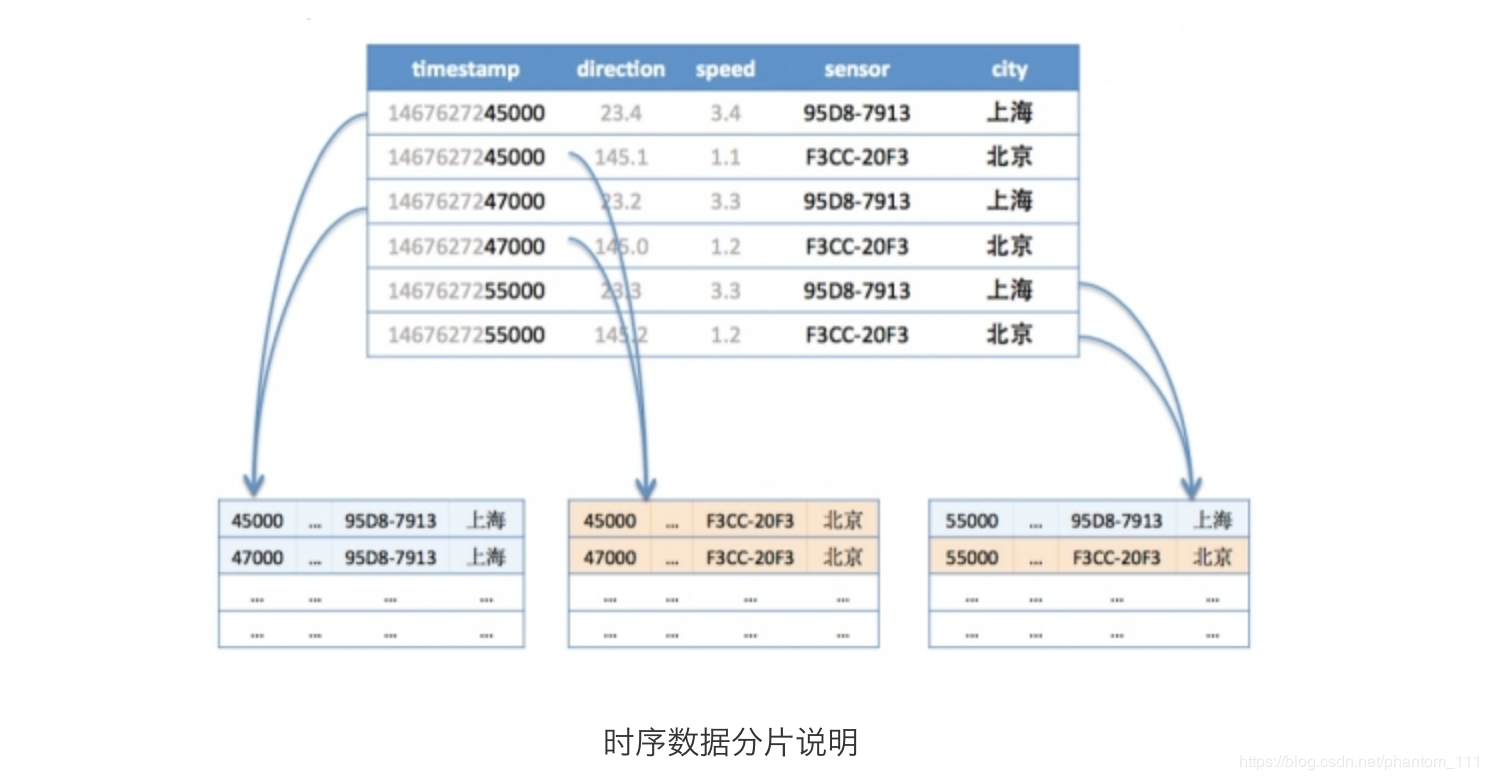
分片的会直接影响到写入的性能,结合时序数据库的特点,根据 metric + tags 分片是比较好的方式,查询大都是按照一个时间范围进行的,这样形同的 metric + tags 数据会被分配到一台机器上连续存放,顺序的磁盘读取是很快的。
在时间范围很长的情况下,可以根据时间访问再进行分段,分别存储到不同的机器上,这样大范围的数据就可以支持并发查询,优化查询速度。
如下图,第一行和第三行都是同样的tag(sensor=95D8-7913;city=上海),所以分配到同样的分片,而第五行虽然也是同样的tag,但是根据时间范围再分段,被分到了不同的分片。第二、四、六行属于同样的tag(sensor=F3CC-20F3;city=北京)也是一样的道理。
计划后面写一篇 关于InfluxDB 的文章,上文的大部分内容是 google + 个人理解,如果发现哪里有误,欢迎指出。
3. 参考资料
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185813.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
