大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
1 .什么是InfluxDB
InfluxDB是一个开源的、高性能的时序型数据库,在时序型数据库DB-Engines Ranking上排名第一。
在介绍InfluxDB之前,先来介绍下时序数据。按照时间顺序记录系统、设备状态变化的数据被称为时序数据(Time Series Data),如CPU利用率、某一时间的环境温度等。
时序数据以时间作为主要的查询纬度,通常会将连续的多个时序数据绘制成线,制作基于时间的多纬度报表,用于揭示数据背后的趋势、规律、异常,进行实时在线预测和预警,时序数据普遍存在于IT基础设施、运维监控系统和物联网中。随着物联网时代的到来,时序数据的数据量呈井喷式爆发,针对于这一数据细分的优化存储显得越来越重要。
最初,使用通用存储系统存储时序数据,如MySQL。第一代时序平台,如KDB +、RRDtool、Graphite等,在20年前就推出了,主要用于存储和分析数据中心的时序数据,以及高频金融数据、股票波动率等。
根据DB-Engines等数据库趋势跟踪和行业分析网站发布的信息,时序型数据库是数据库市场中份额增长最快的部分。原因很明显,计算机虚拟世界,如数据库、网络、容器、系统、应用程序等,和物理世界,如家用设备、城市基础设施、工厂机器、电力设施等,正在创建海量的时序数据。
现在更多的企业会通过时序存储和数据分析来获得预测能力和实时决策能力,从而为客户提供更好的使用体验。这意味着底层数据平台需要发展以应对新的工作负载的挑战,以及更多的数据点、数据源、监控维度、控制策略和精度更高的实时响应,对下一代时序中台提出了更高的要求
2.那么时序数据有什么特点呢?
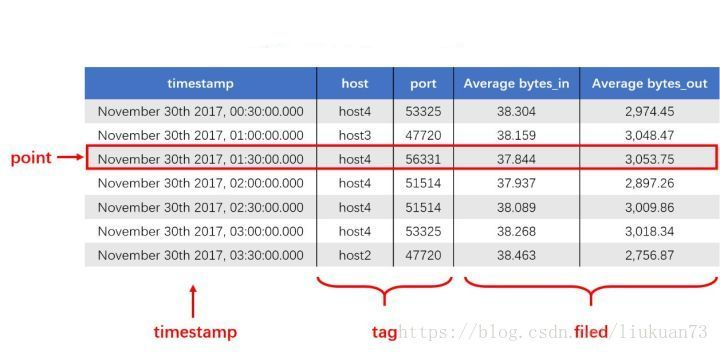
时序数据有这几个属性:
度量的数据集(measurement),类似于关系型数据库中的 table;
一个数据点(point),类似于关系型数据库中的 row;
时间戳(timestamp),表征采集到数据的时间点;
维度列(tag),代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用;
指标列(field),代表数据的测量值,随时间平滑波动。
如下图所示的数据:

3.对于时序数据,我们总结了以下特点:
1.数据特点:数据量大,数据随着时间增长,相同维度重复取值,指标平滑变化(某辆车的某个设备上传上来平滑变化的轨迹坐标)。
2.写入特点:高并发写入,且不会更新(轨迹不会更新)【基本上都是插入,没有更新的需求】。
3.查询特点:按不同维度对指标进行统计分析,存在明显的冷热数据,一般只会查询近期数据(一般我们只会关心近期的轨迹数据)。
4. 数据基本上都有时间属性,随着时间的推移不断产生新的数据。
5. 数据量大,每秒钟需要写入千万、上亿条数据
4.业务方常见需求
1. 获取最新状态,查询最近的数据(例如传感器最新的状态)
2. 展示区间统计,指定时间范围,查询统计信息,例如平均值,最大值,最小值,计数等。。。
3. 获取异常数据,根据指定条件,筛选异常数据
举例:
监控软件系统: 虚拟机、容器、服务、应用
监控物理系统: 水文监控、制造业工厂中的设备监控、国家安全相关的数据监控、通讯监控、传感器数据、血糖仪、血压变化、心率等
资产跟踪应用: 汽车、卡车、物理容器、运货托盘
金融交易系统: 传统证券、新兴的加密数字货币
事件应用程序: 跟踪用户、客户的交互数据
商业智能工具: 跟踪关键指标和业务的总体健康情况
在互联网行业中,也有着非常多的时序数据,例如用户访问网站的行为轨迹,应用程序产生的日志数据等等
5.时序数据库为了解决什么问题?
传统数据库通常记录数据的当前值,时序型数据库则记录所有的历史数据,在处理当前时序数据时又要不断接收新的时序数据,同时时序数据的查询也总是以时间为基础查询条件,并专注于解决以下海量数据场景的问题:
- 专为时序存储和高性能读写而设计:计算机虚拟世界的各种系统和应用,以及物理世界的IoT设备等都在创建海量的时序数据,每秒千万级的数据吞吐量是很常见的,而且这些数据还需要可以以非阻塞方式接收并且可压缩以节省有限的存储资源。如何支持千万级/秒数据的写入。如何支持千万级/秒数据的聚合和查询。
- 专为实时操作而设计:预测能力和实时决策能力,需要收到数据后,就能实时输出最新的数据分析结果,执行预定义的操作。
- 专为高可用性而设计:现代软件系统需要全天候可用,除了基本的集群能力,还需要根据需求自动扩容和缩容,支持柔性可用等。
- 成本敏感:海量数据存储带来的是成本问题,如何更低成本地存储这些数据,是时序型数据库需要解决的关键问题。
6.InfluxDB的优势
InfluxData选择从头开始构建InfluxDB以支持下一代时序中台的需求,InfluxDB通过实现高度可扩展的数据接收和存储引擎,可以高效地实时收集、存储、查询、可视化显示和执行预定义操作。它通过连续查询提升查询效率和缩短延迟,通过数据保留策略,及时高效地删除过期冷数据,提升存储效率。
为什么通用数据库在时序场景上不是最优的选择呢?许多通用数据库正在为时序数据添加一些支持,虽然可能很容易使用,但它们基本上都不是针对海量时序数据的吞吐量和实时操作而设计的。
与InfluxDB相比,通用数据库,如Cassandra、MongoDB、HBase等,需要开发人员投入大量的时间进行代码编写,以开发与InfluxDB类似的功能。具体来说,开发人员需要做如下工作:
- 编写代码实现跨集群数据分片功能、聚合运算和采样功能、数据生命周期管理功能等。
- 实现丰富的API接口。
- 编写用于数据采集的工具。
- 实现实时处理模块并编写用于监控和警报的代码。
- 编写可视化引擎以向用户显示时序数据。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185716.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
