大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
ods层设计要点
保留原始数据,不做处理
如何设计表?
1)ODS层的表结构设计依托于从业务系统同步过来的数据结构
2)ODS层要保存全部历史数据,故其压缩格式应选择压缩比较高的,此处选择gzip。
3)ODS层表名的命名规范为: ods_表名_单分区增量全量标识(inc/full)。
1.创建数据库
现在数仓环境已经搭建好了;
数据也都已经采集到hdfs上了;
1)启动hive
[atguigu@hadoop102 hive]$ bin/hive
2)显示数据库
hive (default)> show databases;
3)创建数据库
hive (default)> create database gmall;
4)使用数据库
hive (default)> use gmall;
2. ODS层
1.用户行为数据
(1)建表分析
- 一行数据是什么:一条日志
- 有哪些字段:只有一个字段
- 如何分区:按天分区,每天存放一天的用户日志
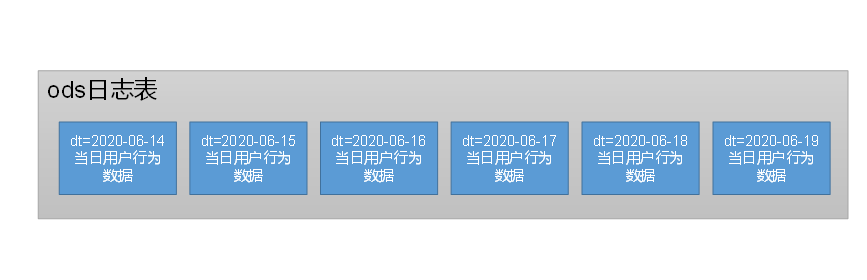

- ods层数据存储
(2)建表语句
方案1
直接将json字符串当做一个字段,后续用json函数进行解析
drop table if exists ods_log;
CREATE EXTERNAL TABLE ods_log (`line` string)
PARTITIONED BY (`dt` string) -- 按照时间创建分区
STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_log'-- 指定数据在hdfs上的存储位置
;
Inputformat: 从这张表中读取数据时用的format;取决于这张表中存储的数据的文件格式,是lzo压缩的格式。
需要注意: 在使用hive读取表的时候,如果不走MR任务,会按照此表指定的InputFormat格式来读取,如果走MR任务,会按照Hive自身默认的读取格式来读取;
Outputformat: 往这张表写数据时用的;只对insert方式起作用;
ods层的表都是从hdfs直接load过来的,因此这里outputformat的设置没有什么意义;
说明Hive的LZO压缩:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+LZO
方案2:直接解析Json
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
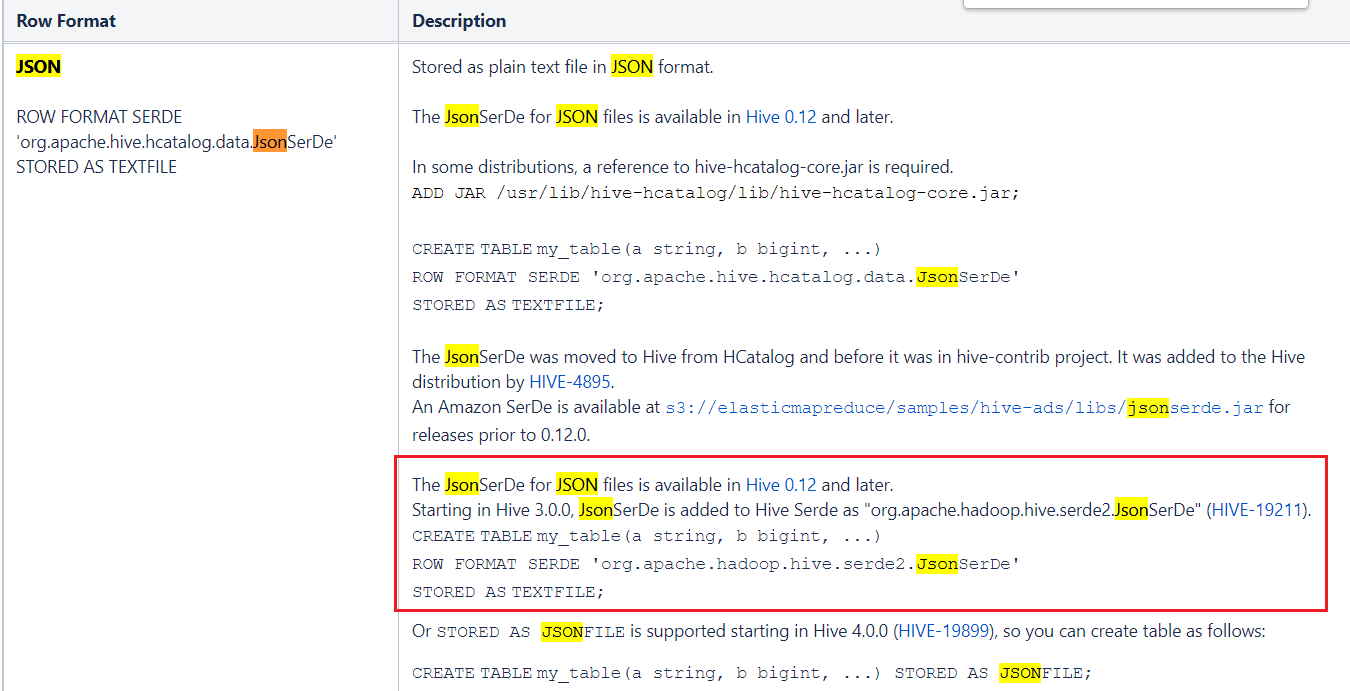
CREATE TABLE my_table(a string, b bigint, ...)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
STORED AS TEXTFILE;
-
ROW FORMAT:指定分隔符;
-
SerDe:序列化和反序列化;
ROW FORMAT SERDE 是指定序列化和反序列化器; -
STORED AS TEXTFILE : hdfs存储格式;
-
字段依赖于Json字符串
什么是SerDe
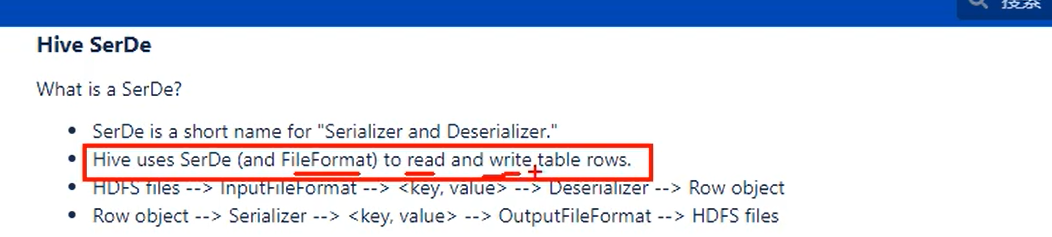
SerDe 用于读写文件中的行;
hvie通过io将文件数据读取到jvm进程中,将记录封装成对象进行处理;
读的流程:
hdfs file -> inputFileFormat -> <K,V> -> Deserializer -> Row object
写的流程:
Row object -> Serializer -> <K,V> -> OutputFileFormat -> HDFS files
Hive在建表的时候,底层都会将表解析成3个组件:
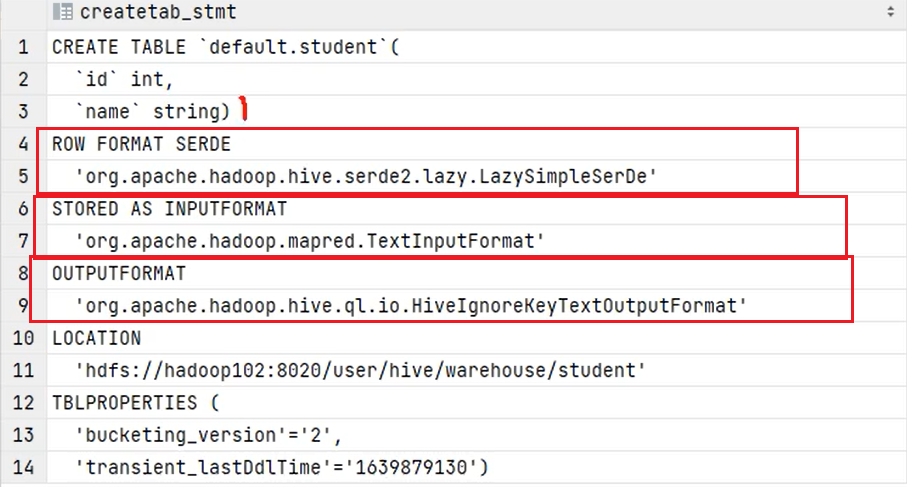
建表
- json表 的字段名必须和Json中的Key保持一致!
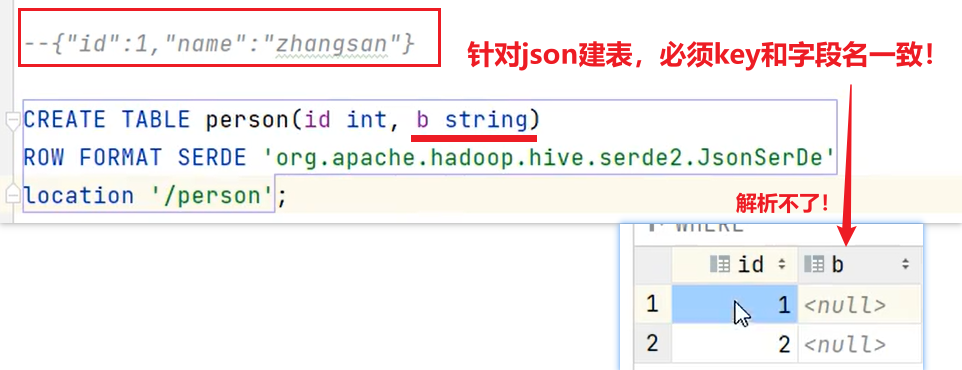
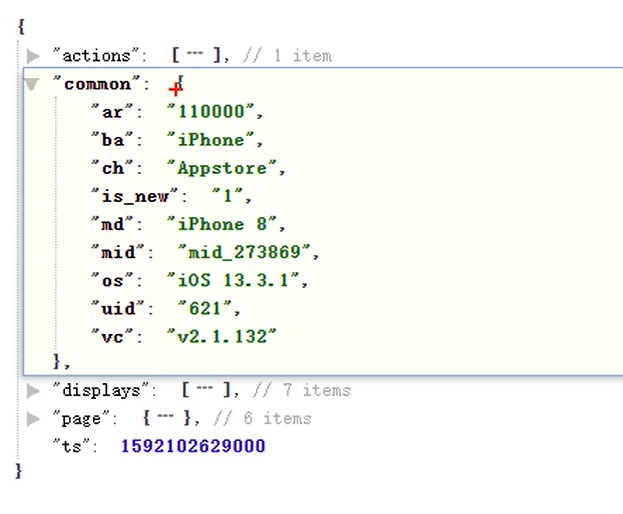
页面日志 :
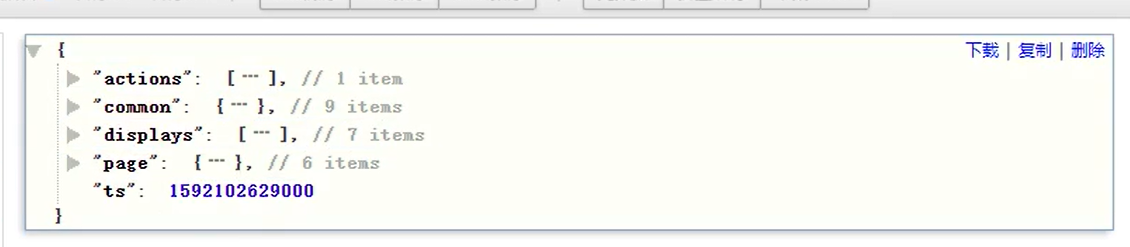
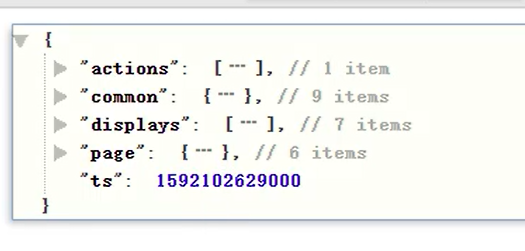
启动日志:
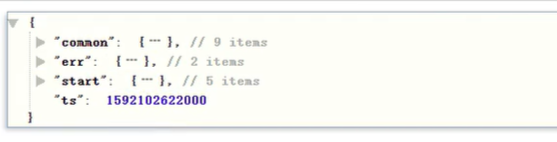
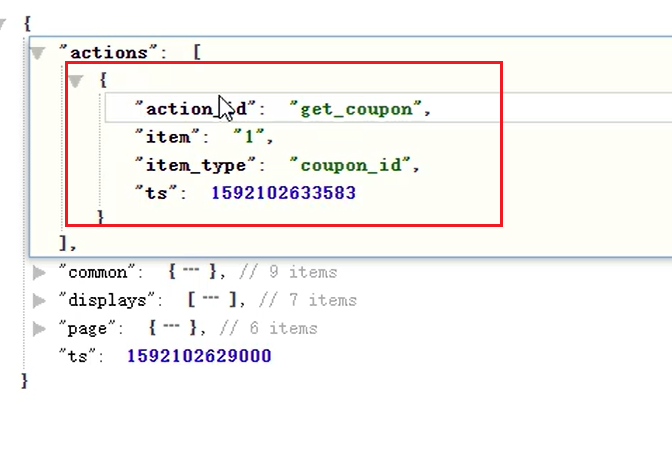
注意:不能用map,map结构,key和value的类型都固定了;这里每个k-v是独立的,所以用struct;

CREATE EXTERNAL TABLE ods_log_inc
(
`common` STRUCT<ar :STRING,ba :STRING,ch :STRING,is_new :STRING,md :STRING,mid :STRING,os :STRING,uid :STRING,vc
:STRING> COMMENT '公共信息',
`page` STRUCT<during_time :STRING,item :STRING,item_type :STRING,last_page_id :STRING,page_id
:STRING,source_type :STRING> COMMENT '页面信息',
`actions` ARRAY<STRUCT<action_id:STRING,item:STRING,item_type:STRING,ts:BIGINT>> COMMENT '动作信息',
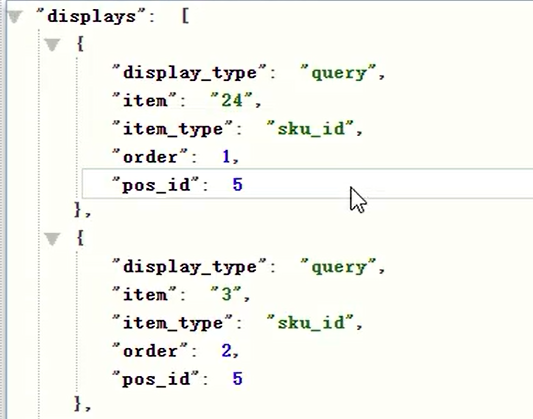
`displays` ARRAY<STRUCT<display_type :STRING,item :STRING,item_type :STRING,`order` :STRING,pos_id
:STRING>> COMMENT '曝光信息',
`start` STRUCT<entry :STRING,loading_time :BIGINT,open_ad_id :BIGINT,open_ad_ms :BIGINT,open_ad_skip_ms
:BIGINT> COMMENT '启动信息',
`err` STRUCT<error_code:BIGINT,msg:STRING> COMMENT '错误信息',
`ts` BIGINT COMMENT '时间戳'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'
LOCATION '/warehouse/gmall/ods/ods_log_inc/';
建表的时候,将启动日志的字段和页面日志的合并到一起!
直接load进textFile格式就行了!
(3)加载数据
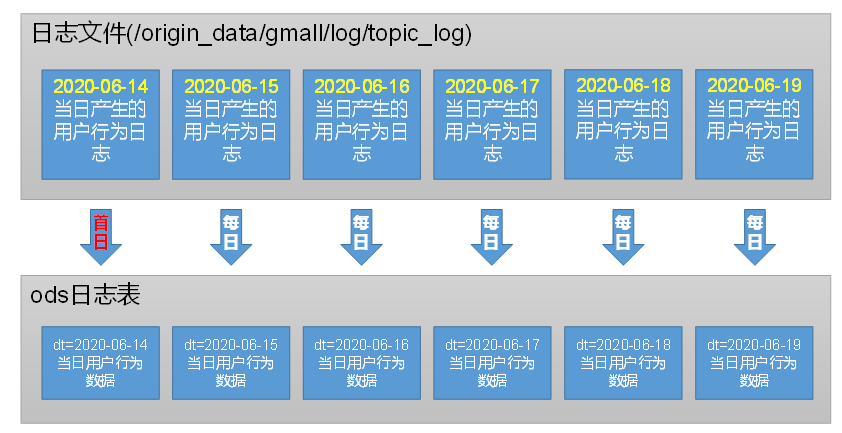
每天装载昨天的数据到ods_log表中;
load data inpath '/origin_data/gmall/log/topic_log/2020-06-14' \
into table ods_log partition(dt='2020-06-14');
注意:时间格式都配置成YYYY-MM-DD格式,这是Hive默认支持的时间格式
最后,如果是lzo压缩的文件,需要为lzo压缩文件创建索引
2. 全量表 建表
(1)分区规划
- 每日都全量同步到ods层当天的分区中!
(2)建表
Lzo索引格式文件建表:
DROP TABLE IF EXISTS ods_activity_info;
CREATE EXTERNAL TABLE ods_activity_info(
`id` STRING COMMENT '编号',
`activity_name` STRING COMMENT '活动名称',
`activity_type` STRING COMMENT '活动类型',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_activity_info/';
DataX同步过来的建表方式

- NULL DEFINED AS ‘’ :Hive中的Null为 /NA,这里用’’;
- DataX没有将Mysql中的null值转换为Hdfs中/NA,会转换成空字符串’’,为了保证hive能识别,就让hive的空值保存格式和DataX的空值格式保持一致!
- 反之,hdfs数据导入到Mysql中,有空值的配置!
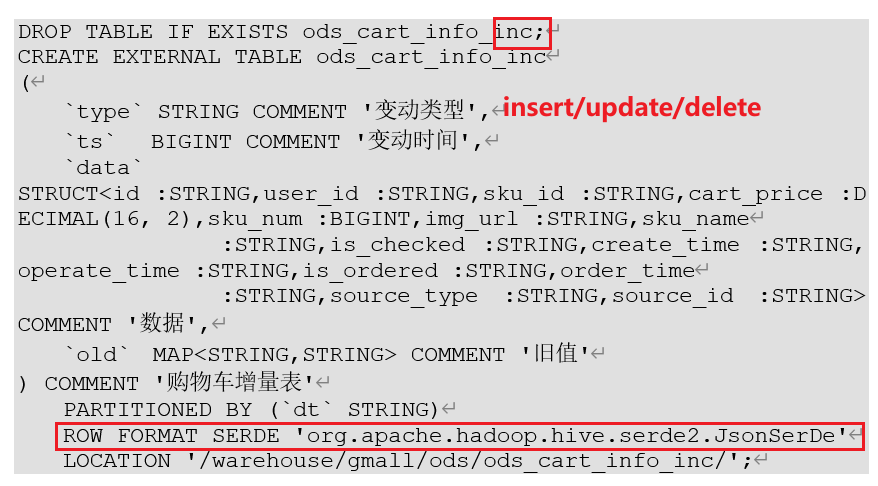
3.增量表建表
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185678.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
