大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
看懂ResNet,需要理解两个点:shortcut的处理,以及网络结构
理解1——Identity Mapping by Shortcuts(快捷恒等映射)
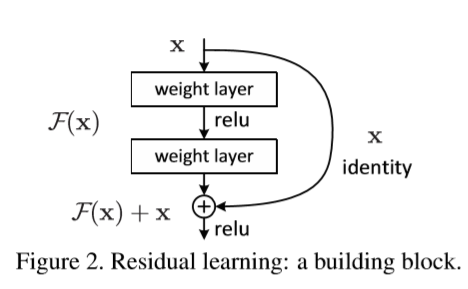

我们每隔几个堆叠层采用残差学习。构建块如图2所示。在本文中我们考虑构建块正式定义为
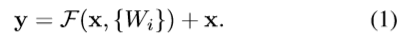
x和y是考虑的层的输入和输出向量。函数F(x,Wi)表示要学习的残差映射。图2中的例子有两层,F=W2σ(W1x)中σ表示ReLU[29],为了简化忽略偏置项。F+x操作通过快捷连接和各个元素相加来执行。在相加之后我们采纳了第二种非线性(即σ(y),看图2)。
公式(1)中的快捷连接既没有引入外部参数又没有增加计算复杂度。这不仅在实践中有吸引力,而且在简单网络和残差网络的比较中也很重要。我们可以公平地比较同时具有相同数量的参数,相同深度,宽度和计算成本的简单/残差网络(除了不可忽略的元素加法之外)。
方程(1)中x和F的维度必须是相等的。如果不是这种情况(例如,当更改输入/输出通道时),我们可以对快捷连接执行线性投影Ws(进行卷积操作)来匹配维度:
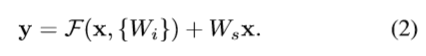
我们也可以在方程(1)中使用方阵Ws。但是我们将通过实验表明,恒等映射足以解决退化问题,并且是合算的,因此Ws仅在匹配维度时使用。
理解2——网络架构:

简单网络:我们简单网络的基准(图3,中间)主要受到VGG网络[40](图3,左图)的启发。卷积层主要有3×3的滤波器,并遵循两个简单的设计规则:(i)对于相同的输出特征图尺寸,每层具有相同数量的滤波器;(ii)如果特征图尺寸减半,则滤波器数量加倍,以便保持每层的时间复杂度。我们直接用步长为2的卷积层进行下采样。网络以全局平均池化层和具有softmax的1000维全连接层结束。图3(中间)的加权层总数为34。
残差网络。 基于上述的简单网络,我们插入快捷连接(图3,右),将网络转换为其对应的残差版本。当输入和输出具有相同的维度时(图3中的实线连接)时,可以直接使用恒等快捷连接(方程(1))。当维度增加(图3中的虚线连接)时,我们考虑两个选项:(A)快捷连接仍然执行恒等映射,额外填充零输入以增加维度。此选项不会引入额外的参数;(B)方程(2)中的投影快捷连接Ws用于匹配维度(由1×1卷积完成)。对于这两个选项,当快捷连接跨越两种尺寸的特征图时,它们执行时步长为2。
B比A好一点,所以代码里用的是B。
文章后面比较了optionA,B,C 。恒等和投影快捷连接我们已经表明没有参数,恒等快捷连接有助于训练。接下来我们调查投影快捷连接(方程2)。我们比较了三个选项:(A) 零填充快捷连接用来增加维度,所有的快捷连接是没有参数的(与表2和图4右相同);(B)投影快捷连接用来增加维度,其它的快捷连接是恒等的;(C)所有的快捷连接都是投影。
表3显示,所有三个选项都比对应的简单网络好很多。选项B比A略好。我们认为这是因为A中的零填充确实没有残差学习。选项C比B稍好,我们把这归因于许多(十三)投影快捷连接引入了额外参数。但A/B/C之间的细微差异表明,投影快捷连接对于解决退化问题不是至关重要的。因为我们在本文的剩余部分不再使用选项C,以减少内存/时间复杂性和模型大小。恒等快捷连接对于不增加下面介绍的瓶颈结构的复杂性尤为重要。
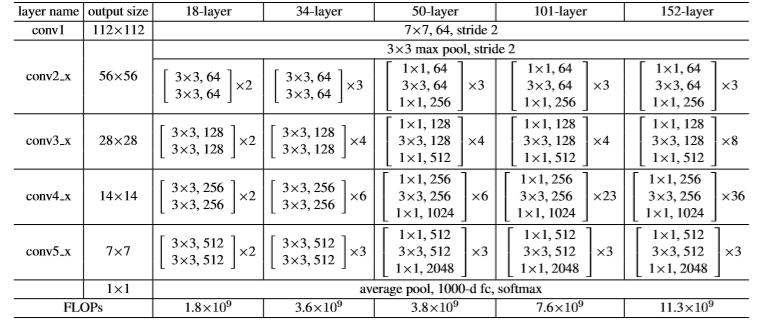
表1。ImageNet架构。构建块显示在括号中,以及构建块的堆叠数量。下采样通过步长为2的conv3_1, conv4_1和conv5_1执行。
ResNet34实现代码:
import torch.nn as nn
import torch
from torch.nn import functional as F
class ResidualBlock(nn.Module):
#实现子module:Residual Block
def __init__(self, in_ch, out_ch, stride=1, shortcut=None):
super(ResidualBlock,self).__init__()
self.left = nn.Sequential(
nn.Conv2d(in_ch,out_ch,3,stride,padding=1,bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace = True),#inplace = True原地操作
nn.Conv2d(out_ch,out_ch,3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(out_ch)
)
self.right = shortcut
def forward(self,x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
out += residual
return F.relu(out)
class ResNet34(nn.Module):#224x224x3
#实现主module:ResNet34
def __init__(self, num_classes=1):
super(ResNet34,self).__init__()
self.pre = nn.Sequential(
nn.Conv2d(3,64,7,stride=2,padding=3,bias=False),# (224+2*p-)/2(向下取整)+1,size减半->112
nn.BatchNorm2d(64),#112x112x64
nn.ReLU(inplace = True),
nn.MaxPool2d(3,2,1)#kernel_size=3, stride=2, padding=1
)#56x56x64
#重复的layer,分别有3,4,6,3个residual block
self.layer1 = self.make_layer(64,64,3)#56x56x64,layer1层输入输出一样,make_layer里,应该不用对shortcut进行处理,但是为了统一操作。。。
self.layer2 = self.make_layer(64,128,4,stride=2)#第一个stride=2,剩下3个stride=1;28x28x128
self.layer3 = self.make_layer(128,256,6,stride=2)#14x14x256
self.layer4 = self.make_layer(256,512,3,stride=2)#7x7x512
#分类用的全连接
self.fc = nn.Linear(512,num_classes)
def make_layer(self,in_ch,out_ch,block_num,stride=1):
#当维度增加时,对shortcut进行option B的处理
shortcut = nn.Sequential(#首个ResidualBlock需要进行option B处理
nn.Conv2d(in_ch,out_ch,1,stride,bias=False),#1x1卷积用于增加维度;stride=2用于减半size;为简化不考虑偏差
nn.BatchNorm2d(out_ch)
)
layers = []
layers.append(ResidualBlock(in_ch,out_ch,stride,shortcut))
for i in range(1,block_num):
layers.append(ResidualBlock(out_ch,out_ch))#后面的几个ResidualBlock,shortcut直接相加
return nn.Sequential(*layers)
def forward(self,x): #224x224x3
x = self.pre(x) #56x56x64
x = self.layer1(x) #56x56x64
x = self.layer2(x) #28x28x128
x = self.layer3(x) #14x14x256
x = self.layer4(x) #7x7x512
x = F.avg_pool2d(x,7)#1x1x512
x = x.view(x.size(0),-1)#将输出拉伸为一行:1x512
x = self.fc(x) #1x1
# nn.BCELoss:二分类用的交叉熵,用的时候需要在该层前面加上 Sigmoid 函数
return nn.Sigmoid()(x)#1x1,将结果化为(0~1)之间
Reference:
ResNet原文
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185627.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
