大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
云从的多粒度网络(MGN)的结构设计与技术实现-ReID
1.简介
全局特征和局部特征的结合是提高人的再识别(re-ID)任务识别性能的一种有效方法。以前的基于部分的方法主要集中在定位具有特定预定义语义的区域来学习局部表示,这增加了学习的难度,但对具有较大方差的场景却没有效率或鲁棒性。本文提出了一种融合不同粒度判别信息的端到端特征学习策略。我们仔细设计了多粒度网络(MGN),这是一个多分支的深层网络结构,由一个分支用于全局特征表示,两个分支用于局部特征表示。我们不需要学习语义区域,而是将图像均匀地分割成若干条带,并在不同的局部分支中改变部分的数目,从而获得具有多个粒度的局部特征表示。在Market-1501、DukeMTMC-reid和CUHK03等主流评价数据集上进行的综合实验表明,我们的方法能够很好地实现最新的性能,并且在很大程度上优于任何现有方法。例如,在单查询模式下的Market-1501数据集上,用该方法重新排序后,得到的结果为Rank-1/mAP=96.6%/94.2%。
本文提出了一种不同粒度的全局和局部信息相结合的特征学习策略。如图1所示,不同数量的分区条带引入了内容粒度的多样性。我们定义原始图像只包含一个全局信息的整体分割为最粗情况,并且随着分割数目的增加,局部特征可以更多地集中在每个部分条带中更精细的判别信息,过滤其他条带上的信息。由于深度学习机制可以从整个图像中获取主体上的近似响应偏好,因此也可以从较小的局部区域中提取出更细粒度的局部特征显著性。请注意,这些部分区域不必是具有特定语义的定位分区,而只需要原始图像上的一块等分条带。从观察中我们发现,随着水平条纹数的增加,区分反应的粒度确实变得更细。基于这一动机,我们从ResNet-50[13]骨干网的第四剩余阶段设计了多粒度网络(MGN),一个多分支网络体系结构,将其分为一个全局分支和两个局部分支,并对其参数进行了细化。在MGN的每个局部分支中,我们参考文献[36]中的方法,将全局汇集的特征映射划分为不同数量的条带作为部分区域,以独立地学习局部特征表示。
与以往的基于部分的方法相比,我们的方法只利用等分部分进行局部表示,但在性能上优于以往的所有方法。此外,我们的方法完全是一个端到端的学习过程,易于学习和实现。大量实验结果表明,我们的方法可以在几个主流的Re-ID数据集上实现最新的性能,即使没有任何额外的外部数据或重新排序[50]操作。
2.网络结构
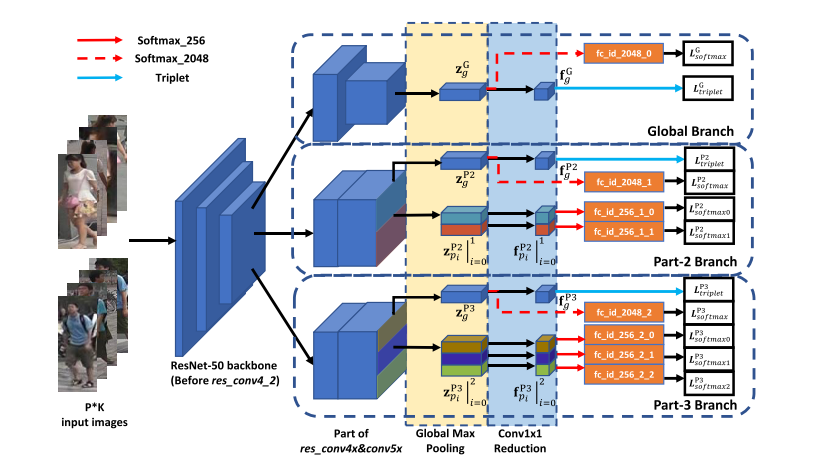

我们网络的主干是ResNet-50,它有助于在一些Re-ID系统中实现竞争性能。与原版本最明显的不同之处在于,我们将res_conv4_1块后的后续部分划分为三个独立的分支,与原ResNet-50共享相似的架构。
在测试阶段,为了获得最强大的识别能力,将所有降到256维的特征串接为最终特征,结合全局和局部信息来完善对学习特征的综合性。
看一下 global 分支。上面第一块的 Loss 设计。这个地方对 2048 维做了SoftmaxLoss,对 256 维做了一个 TripletLoss,这是对 global 信息通用的方法。下面两个部分 global 的处理方式也是一样的,都是对 2048 做一个 SoftmaxLoss,对 256 维做一个 TripletLoss。中间 part-2 地方有一个全局信息,有 global 特征,做 SoftmaxLoss+TripletLoss。
但是,下面两个 Local 特征看不到 TripletLoss,只用了 SoftmaxLoss,这个在文章里也有讨论,我们当时做了实验,如果对细节当和分支做 TripletLoss,效果会变差。为什么效果会变差?
一张图片分成从上到下两部分的时候,最完美的情况当然是上面部分是上半身,下面部分是下半身,但是在实际的图片中,有可能整个人都在上半部分,下半部分全是背景,这种情况用上、下部分来区分,假设下半部分都是背景,把这个背景放到 TripletLoss 三元损失里去算这个 Loss,就会使得这个模型学到莫名其妙的特征。
比如背景图是个树,另外一张图是某个人的下半身,比如一个女生的下半身是一个裙子,你让裙子跟另外图的树去算距离,无论是同类还是不同类,算出来的距离是没有任何物理意义或实际意义的。从模型的角度来讲,它属于污点数据,这个污点数据会引导整个模型崩溃掉或者学到错误信息,使得预测的时候引起错误。所以以后有同学想复现我们方法的时候要注意一下, Part-2、part-3 的 Local 特征千万不要加 TripletLoss。
3.解读
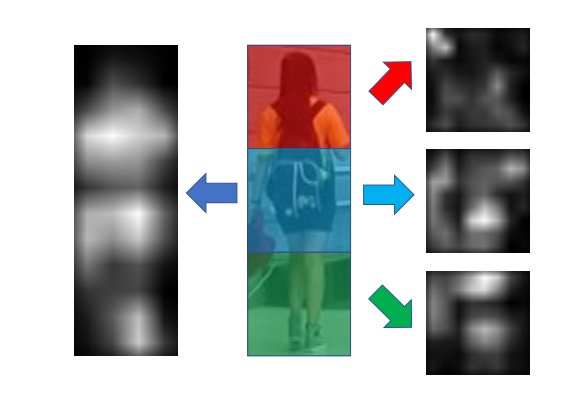
上图显示了从IDE基线模型[47]和基于IDE的部件模型中提取的特定图像的特征响应图。我们可以观察到,即使没有明确的注意机制来增强对某些显著成分的偏好,深层网络仍然可以根据不同身体部位的内在语义来初步区分它们的反应偏好。然而,为了消除复杂度高的行人图像中无关模式的干扰,更高的响应只集中在行人的主体上,而不是任何具有语义模式的具体身体部位。当我们缩小表示区域的范围并将其训练为学习局部特征的分类任务时,我们可以观察到局部特征映射上的响应开始聚集在一些显著的语义模式上,这些语义模式也随着表示区域的大小而变化。
这一观察反映了图像内容量(即区域的粒度)与深度网络关注特定表示模式的能力之间的关系。我们相信这种现象是由于信息在有限区域内的局限性造成的。一般来说,从全局图像比较,很难从局部区域区分行人的身份。分类任务的监控信号强制将特征正确分类为目标身份,这也推动了学习过程试图在有限的信息中探索有用的细粒度细节。实际上,以前基于零件的方法中的局部特征学习
仅在有或无经验先验知识的情况下,将分区的基本粒度多样性引入到整个特征学习过程中。假设存在适当级别的粒度,则具有最具歧视性信息的细节可能最集中于深层网络。基于以上的观察和分析,我们提出了多粒度网络(MGN)架构,将全局和多粒度局部特征学习相结合,以获得更强大的行人表示。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185563.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
