大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用

提取码:mqic
为什么要进行垃圾分类?
当废物处理不当 – 时,就会发生回收污染 – ,就像回收带有油的比萨盒(堆肥)一样。 或者当废物得到正确处理但未正确准备 – 时,例如回收未冲洗过的果酱罐。
污染是回收行业的一个巨大问题,可以通过自动化废物分类来缓解。 只是为了踢球,我想我会尝试制作一个图像分类器的原型来对垃圾和可回收物进行分类 – 这个分类器可以在光学分拣系统中得到应用。
构建图像分类器
在这个项目中,我将训练一个卷积神经网络,使用 fastai 库(构建在 PyTorch 上)将图像分类为
waste_types = ['hazardous_waste_dry_battery',
'hazardous_waste_expired_drugs',
'hazardous_waste_ointment',
'kitchen_waste_bone',
'kitchen_waste_eggshell',
'kitchen_waste_fish_bone',
'kitchen_waste_fruit_peel',
'kitchen_waste_meal',
'kitchen_waste_pulp',
'kitchen_waste_tea',
'kitchen_waste_vegetable',
'other_garbage_bamboo_chopsticks',
'other_garbage_cigarette',
'other_garbage_fast_food_box',
'other_garbage_flowerpot',
'other_garbage_soiled_plastic',
'other_garbage_toothpick',
'recyclables_anvil',
'recyclables_bag',
'recyclables_bottle',
'recyclables_can',
'recyclables_cardboard',
'recyclables_cosmetic_bottles',
'recyclables_drink_bottle',
'recyclables_edible_oil_barrel',
'recyclables_glass_cup',
'recyclables_metal_food_cans',
'recyclables_old_clothes',
'recyclables_paper_bags',
'recyclables_pillow',
'recyclables_plastic_bowl',
'recyclables_plastic_hanger',
'recyclables_plug_wire',
'recyclables_plush_toys',
'recyclables_pot',
'recyclables_powerbank',
'recyclables_seasoning_bottle',
'recyclables_shampoo_bottle',
'recyclables_shoes',
'recyclables_toys']我的建模管道:
下载并提取图像
将图像组织到不同的文件夹中
训练模型
做出和评估测试预测
下一步
一些基本的准备
%reload_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format = 'retina'from fastai.vision import *
from fastai.metrics import error_rate
from pathlib import Path
from glob2 import glob
from sklearn.metrics import confusion_matrix
import pandas as pd
import numpy as np
import os
import zipfile as zf
import shutil
import re
import seaborn as sns1. 提取数据
首先,我们需要提取“train.zip”的内容。
files = zf.ZipFile("dataset-resized.zip",'r')
files.extractall()
files.close()解压缩后,数据集调整大小的文件夹有40个子文件夹:

os.listdir(os.path.join(os.getcwd(),"dataset-resized"))2. 将图片整理到不同的文件夹中
现在我们已经提取了数据,我将按照 50-25-25 的比例将图像分成训练、验证和测试图像文件夹。 首先,我定义了一些有助于我快速构建它的函数。 如果你对构建数据集不感兴趣,则可以直接运行忽略它。
## helper functions ##
## splits indices for a folder into train, validation, and test indices with random sampling
## input: folder path
## output: train, valid, and test indices
def split_indices(folder,seed1,seed2):
n = len(os.listdir(folder))
full_set = list(range(1,n+1))
## train indices
random.seed(seed1)
train = random.sample(list(range(1,n+1)),int(.5*n))
## temp
remain = list(set(full_set)-set(train))
## separate remaining into validation and test
random.seed(seed2)
valid = random.sample(remain,int(.5*len(remain)))
test = list(set(remain)-set(valid))
return(train,valid,test)
## gets file names for a particular type of trash, given indices
## input: waste category and indices
## output: file names
def get_names(waste_type,indices):
file_names = [waste_type+str(i)+".jpg" for i in indices]
return(file_names)
## moves group of source files to another folder
## input: list of source files and destination folder
## no output
def move_files(source_files,destination_folder):
for file in source_files:
shutil.move(file,destination_folder)之后训练集和验证集里面各有四十个文件夹

## paths will be train/cardboard, train/glass, etc...
subsets = ['train','valid']
waste_types = waste_types = ['hazardous_waste_dry_battery',
'hazardous_waste_expired_drugs',
'hazardous_waste_ointment',
'kitchen_waste_bone',
'kitchen_waste_eggshell',
'kitchen_waste_fish_bone',
'kitchen_waste_fruit_peel',
'kitchen_waste_meal',
'kitchen_waste_pulp',
'kitchen_waste_tea',
'kitchen_waste_vegetable',
'other_garbage_bamboo_chopsticks',
'other_garbage_cigarette',
'other_garbage_fast_food_box',
'other_garbage_flowerpot',
'other_garbage_soiled_plastic',
'other_garbage_toothpick',
'recyclables_anvil',
'recyclables_bag',
'recyclables_bottle',
'recyclables_can',
'recyclables_cardboard',
'recyclables_cosmetic_bottles',
'recyclables_drink_bottle',
'recyclables_edible_oil_barrel',
'recyclables_glass_cup',
'recyclables_metal_food_cans',
'recyclables_old_clothes',
'recyclables_paper_bags',
'recyclables_pillow',
'recyclables_plastic_bowl',
'recyclables_plastic_hanger',
'recyclables_plug_wire',
'recyclables_plush_toys',
'recyclables_pot',
'recyclables_powerbank',
'recyclables_seasoning_bottle',
'recyclables_shampoo_bottle',
'recyclables_shoes',
'recyclables_toys']
## create destination folders for data subset and waste type
for subset in subsets:
for waste_type in waste_types:
folder = os.path.join('data',subset,waste_type)
if not os.path.exists(folder):
os.makedirs(folder)
if not os.path.exists(os.path.join('data','test')):
os.makedirs(os.path.join('data','test'))
## move files to destination folders for each waste type
for waste_type in waste_types:
source_folder = os.path.join('train',waste_type)
train_ind, valid_ind, test_ind = split_indices(source_folder,1,1)
## move source files to train
train_names = get_names(waste_type,train_ind)
train_source_files = [os.path.join(source_folder,name) for name in train_names]
train_dest = "data/train/"+waste_type
move_files(train_source_files,train_dest)
## move source files to valid
valid_names = get_names(waste_type,valid_ind)
valid_source_files = [os.path.join(source_folder,name) for name in valid_names]
valid_dest = "data/valid/"+waste_type
move_files(valid_source_files,valid_dest)
## move source files to test
test_names = get_names(waste_type,test_ind)
test_source_files = [os.path.join(source_folder,name) for name in test_names]
## I use data/test here because the images can be mixed up
move_files(test_source_files,"data/test")为了可重复性,我将两个随机样本的种子设置为 1。 现在数据已经组织好,我们可以开始模型训练了。
## get a path to the folder with images
path = Path(os.getcwd())/"data"
pathout:PosixPath('/home/jupyter/data')
tfms = get_transforms(do_flip=True,flip_vert=True)
data = ImageDataBunch.from_folder(path,test="test",ds_tfms=tfms,bs=16)
data #可以把data打印出来看看data.show_batch(rows=4,figsize=(10,8)) #显示图片训练模型!
什么是resnet34?
残差神经网络是具有很多层的卷积神经网络 (CNN)。特别是,resnet34 是一个 34 层的 CNN,已经在 ImageNet 数据库上进行了预训练。预训练的 CNN 将在新的图像分类任务上表现得更好,因为它已经学习了一些视觉特征并且可以将这些知识转移(因此是转移学习)。
由于它们能够描述更多的复杂性,理论上深度神经网络在训练数据上应该比浅层网络表现得更好。但实际上,深度神经网络在经验上的表现往往比浅层神经网络差。
创建 Resnets 是为了使用一种称为快捷连接的黑客来规避这个故障。如果某个层中的某些节点具有次优值,则可以调整权重和偏差;如果一个节点是最优的(它的残差为 0),为什么不把它放在一边?仅根据需要对节点进行调整(当存在非零残差时)。
当需要调整时,快捷连接应用恒等函数将信息传递给后续层。这在可能的情况下缩短了神经网络,并允许 resnet 具有深层架构并表现得更像浅层神经网络。 resnet34中的34只是指层数。
Anand Saha 在这里给出了更深入的解释。
learn = create_cnn(data,models.resnet34,metrics=error_rate)
learn.modellearn.lr_find(start_lr=1e-6,end_lr=1e1)
learn.recorder.plot()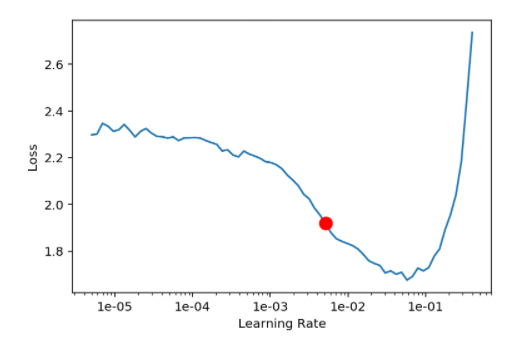
learn.fit_one_cycle(20,max_lr=5.13e-03)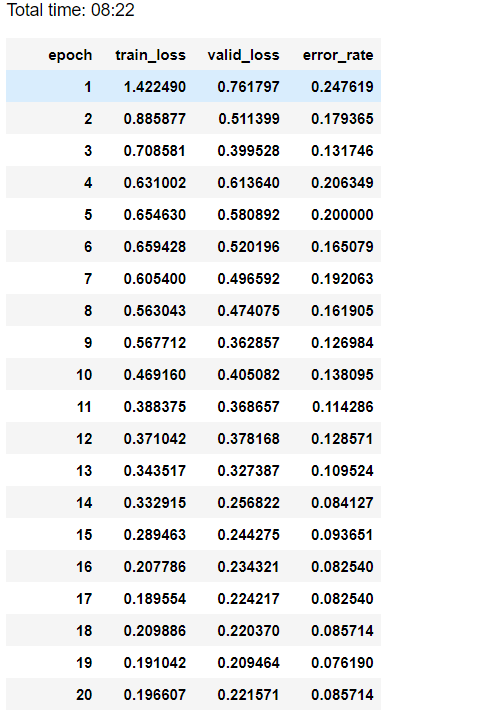
我的模型运行了 20 个 epoch。 这种拟合方法的酷炫之处在于,学习率随着每个 epoch 的增长而降低,让我们越来越接近最佳状态。 在 8.6% 时,验证错误看起来非常好……让我们看看它在测试数据上的表现如何。
首先,我们可以看看哪些图像分类错误最多。
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
interp.plot_top_losses(9, figsize=(15,11))doc(interp.plot_top_losses)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)interp.most_confused(min_val=2)
现在就到了最激动人心的时刻
4. 对测试数据做出新的预测
要了解这种模式的真正表现,我们需要对测试数据进行预测。 首先,我将使用 learner.get_preds() 方法对测试数据进行预测。
注意:learner.predict() 只对单个图像进行预测,而 learner.get_preds() 对一组图像进行预测。 我强烈建议阅读文档以了解有关 predict() 和 get_preds() 的更多信息。
preds = learn.get_preds(ds_type=DatasetType.Test)get_preds(ds_type) 中的 ds_type 参数采用 DataSet 参数。 示例值为 DataSet.Train、DataSet.Valid 和 DataSet.Test。 我提到这一点是因为我错误地传入了实际数据 (learn.data.test_ds),这给了我错误的输出并且花了很长时间进行调试。 不要犯这个错误! 不要传入数据——传入数据集类型!
print(preds[0].shape)
preds[0]结果就在yhat里面!
## saves the index (0 to 5) of most likely (max) predicted class for each image
max_idxs = np.asarray(np.argmax(preds[0],axis=1))
yhat = []
for max_idx in max_idxs:
yhat.append(data.classes[max_idx])
yhat…..
recyclables_plush_toys kitchen_waste_eggshell recyclables_edible_oil_barrel hazardous_waste_expired_drugs kitchen_waste_eggshell recyclables_shoes recyclables_plug_wire kitchen_waste_vegetable recyclables_shoes recyclables_toys recyclables_seasoning_bottle recyclables_bag kitchen_waste_fruit_peel other_garbage_cigarette recyclables_can recyclables_anvil other_garbage_cigarette recyclables_shoes recyclables_paper_bags kitchen_waste_fish_bone other_garbage_bamboo_chopsticks other_garbage_bamboo_chopsticks other_garbage_flowerpot recyclables_bottle kitchen_waste_vegetable kitchen_waste_pulp recyclables_edible_oil_barrel recyclables_plastic_bowl other_garbage_fast_food_box recyclables_pot recyclables_cardboard recyclables_glass_cup recyclables_plastic_hanger recyclables_paper_bags recyclables_seasoning_bottle kitchen_waste_bone recyclables_seasoning_bottle recyclables_powerbank recyclables_drink_bottle kitchen_waste_fruit_peel recyclables_seasoning_bottle recyclables_powerbank recyclables_plush_toys recyclables_plush_toys recyclables_seasoning_bottle recyclables_bottle recyclables_edible_oil_barrel recyclables_edible_oil_barrel recyclables_plastic_bowl recyclables_metal_food_cans other_garbage_cigarette hazardous_waste_expired_drugs kitchen_waste_fish_bone recyclables_shoes kitchen_waste_pulp recyclables_plastic_bowl recyclables_powerbank
….
或者可以看另外两篇图像分类的
最简单的直接用训练好的模型
猫狗图像分类:
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185544.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
