大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
建模的评估一般可以分为回归、分类和聚类的评估,本文主要介绍回归和分类的模型评估:
一、回归模型的评估
主要有以下方法:
| 指标 | 描述 | metrics方法 |
|---|---|---|
| Mean Absolute Error(MAE) | 平均绝对误差 | from sklearn.metrics import mean_absolute_error |
| Mean Square Error(MSE) | 平均方差 | from sklearn.metrics import mean_squared_error |
| R-Squared | R平方值 | from sklearn.metrics import r2_score |
#sklearn的调用
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
mean_absolute_error(y_test,y_predict)
mean_squared_error(y_test,y_predict)
r2_score(y_test,y_predict)
(一)平均绝对误差(Mean Absolute Error,MAE)
平均绝对误差就是指预测值与真实值之间平均相差多大 :
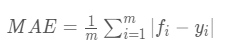

平均绝对误差能更好地反映预测值误差的实际情况.
(二)均方误差(Mean Squared Error,MSE)
观测值与真值偏差的平方和与观测次数的比值:
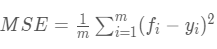
这也是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
(三)R-square(决定系数)
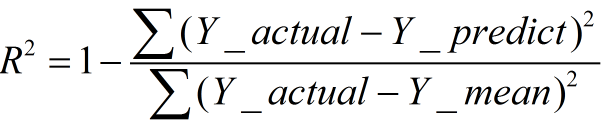
数学理解: 分母理解为原始数据的离散程度,分子为预测数据和原始数据的误差,二者相除可以消除原始数据离散程度的影响
其实“决定系数”是通过数据的变化来表征一个拟合的好坏。
理论上取值范围(-∞,1], 正常取值范围为[0 1] ——实际操作中通常会选择拟合较好的曲线计算R²,因此很少出现-∞
越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
越接近0,表明模型拟合的越差
经验值:>0.4, 拟合效果好
缺点:数据集的样本越大,R²越大,因此,不同数据集的模型结果比较会有一定的误差
(四)Adjusted R-Square (校正决定系数)
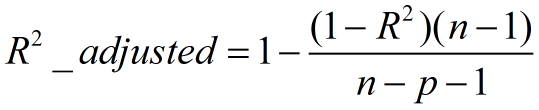
n为样本数量,p为特征数量
- 消除了样本数量和特征数量的影响
(五)交叉验证(Cross-Validation)
交叉验证,有的时候也称作循环估计(Rotation Estimation),是一种统计学上将数据样本切割成较小子集的实用方法,该理论是由Seymour Geisser提出的。在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预报了一次而且仅被预报一次。把每个样本的预报误差平方加和,称为PRESS(predicted Error Sum of Squares)。
交叉验证的基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set or test set)。首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。
无论分类还是回归模型,都可以利用交叉验证,进行模型评估,示例代码:
from sklearn.cross_validation import cross_val_score
print(cross_val_score(knn, X_train, y_train, cv=4))
print(cross_cal_score(lr, X, y, cv=2))参考文献:
https://blog.csdn.net/qq_37279279/article/details/81041470
https://blog.csdn.net/shy19890510/article/details/79375062
https://blog.csdn.net/chocolate_chuqi/article/details/81112051
https://blog.csdn.net/chao2016/article/details/84960257
二、分类模型的评估:
准确率、精确率、召回率、f1_score,混淆矩阵,ks,ks曲线,ROC曲线,psi等。
(一)模型准确度评估
1、准确率、精确率、召回率、f1_score
1.1 准确率(Accuracy)的定义是:对于给定的测试集,分类模型正确分类的样本数与总样本数之比;
1.2 精确率(Precision)的定义是:对于给定测试集的某一个类别,分类模型预测正确的比例,或者说:分类模型预测的正样本中有多少是真正的正样本;
1.3 召回率(Recall)的定义为:对于给定测试集的某一个类别,样本中的正类有多少被分类模型预测正确召回率的定义为:对于给定测试集的某一个类别,样本中的正类有多少被分类模型预测正确;
1.4 F1_score,在理想情况下,我们希望模型的精确率越高越好,同时召回率也越高越高,但是,现实情况往往事与愿违,在现实情况下,精确率和召回率像是坐在跷跷板上一样,往往出现一个值升高,另一个值降低,那么,有没有一个指标来综合考虑精确率和召回率了,这个指标就是F值。F值的计算公式为:
式中:P: Precision, R: Recall, a:权重因子。
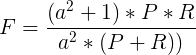
当a=1时,F值便是F1值,代表精确率和召回率的权重是一样的,是最常用的一种评价指标。
F1的计算公式为:
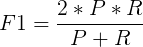
代码示例:
#1、准确率
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
accuracy_score(y_true, y_pred)
Out[127]: 0.33333333333333331
accuracy_score(y_true, y_pred, normalize=False) # 类似海明距离,每个类别求准确后,再求微平均
Out[128]: 3
#2、分类报告:输出包括了precision/recall/fi-score/均值/分类个数
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 2, 0]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
#3、特别的对于用predict_proba进行预测计算,那么必须用roc_auc_score,否则会报错
#示例代码
from sklearn.metrics import roc_auc_score
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(C = 0.0001,class_weight='balanced') # c 正则化参数
lr.fit(poly_train, target)
lr_poly_pred = lr.predict_proba(poly_test)[:,1]
lr_poly_pred2= lr.predict_proba(poly_train)[:,1]
# submission dataframe
submit = Id.copy()
submit['TARGET'] = lr_poly_pred
print('score:',roc_auc_score(target,lr_poly_pred2))2、混淆矩阵
2.1 基本概念:混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
2.1.1 混淆矩阵一级指标(最底层的):
真实值是positive,模型认为是positive的数量(True Positive=TP);
真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error);
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error);
真实值是negative,模型认为是negative的数量(True Negative=TN)
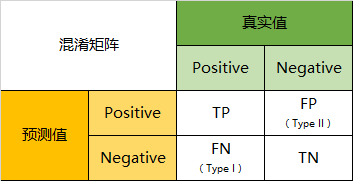
2.1.2 二级指标
混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。因此混淆矩阵在基本的统计结果上又延伸了如下4个指标,我称他们是二级指标(通过最底层指标加减乘除得到的):
准确率(Accuracy)—— 针对整个模型
精确率(Precision)
灵敏度(Sensitivity):就是召回率(Recall)
特异度(Specificity)
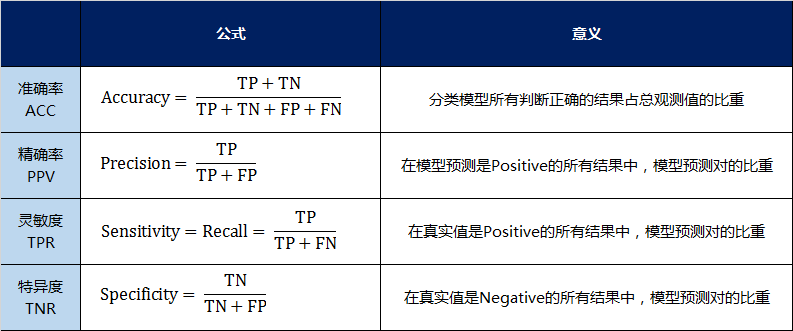
2.1.3 三级指标
F1 Score,公式如下
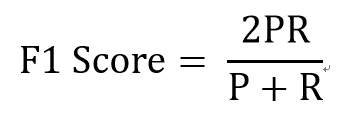
其中,P代表Precision,R代表Recall。F1-Score指标综合了Precision与Recall的产出的结果。
2.1.4 示例及实现代码
# 假如有一个模型在测试集上得到的预测结果为:
y_true = [1, 0, 0, 2, 1, 0, 3, 3, 3] # 实际的类别
y_pred = [1, 1, 0, 2, 1, 0, 1, 3, 3] # 模型预测的类别
# 使用sklearn 模块计算混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_mat = confusion_matrix(y_true, y_pred)
print(confusion_mat) #看看混淆矩阵长啥样
[[2 1 0 0]
[0 2 0 0]
[0 0 1 0]
[0 1 0 2]]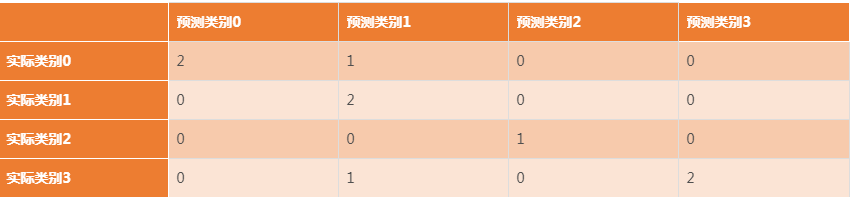
2.2 混淆矩阵可视化
def plot_confusion_matrix(confusion_mat):
'''''将混淆矩阵画图并显示出来'''
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.gray)
plt.title('Confusion matrix')
plt.colorbar()
tick_marks = np.arange(confusion_mat.shape[0])
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
plot_confusion_matrix(confusion_mat)
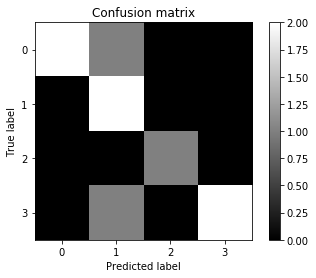
3、ROC曲线和AUC计算
3.1计算ROC值
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
FPR:负正类率((False Positive Rate),FPR=1-TNR
ROC曲线图
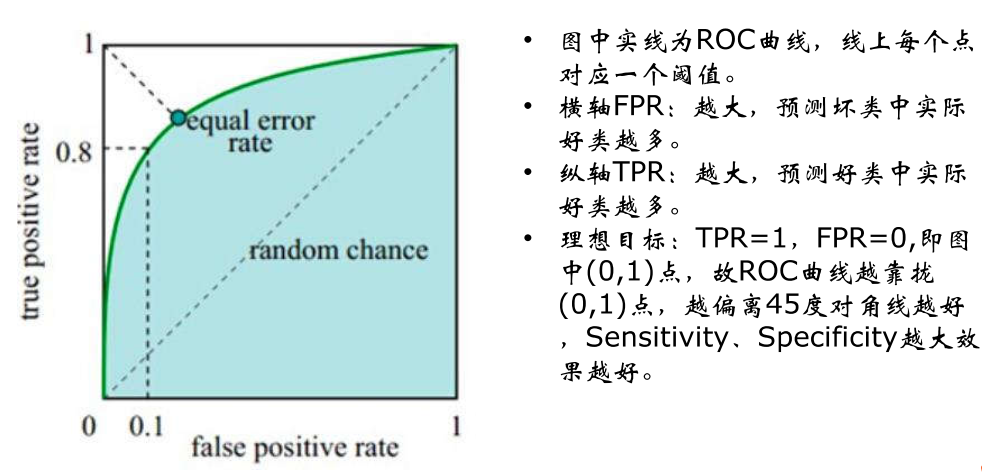
3.2 AUC(Area Under Curve)
AUC就是ROC 曲线下的面积,通常情况下数值介于0.5-1之间,可以评价分类器的好坏,数值越大说明越好。
AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
AUC评价:
AUC = 1采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在AUC < 0.5的情况。
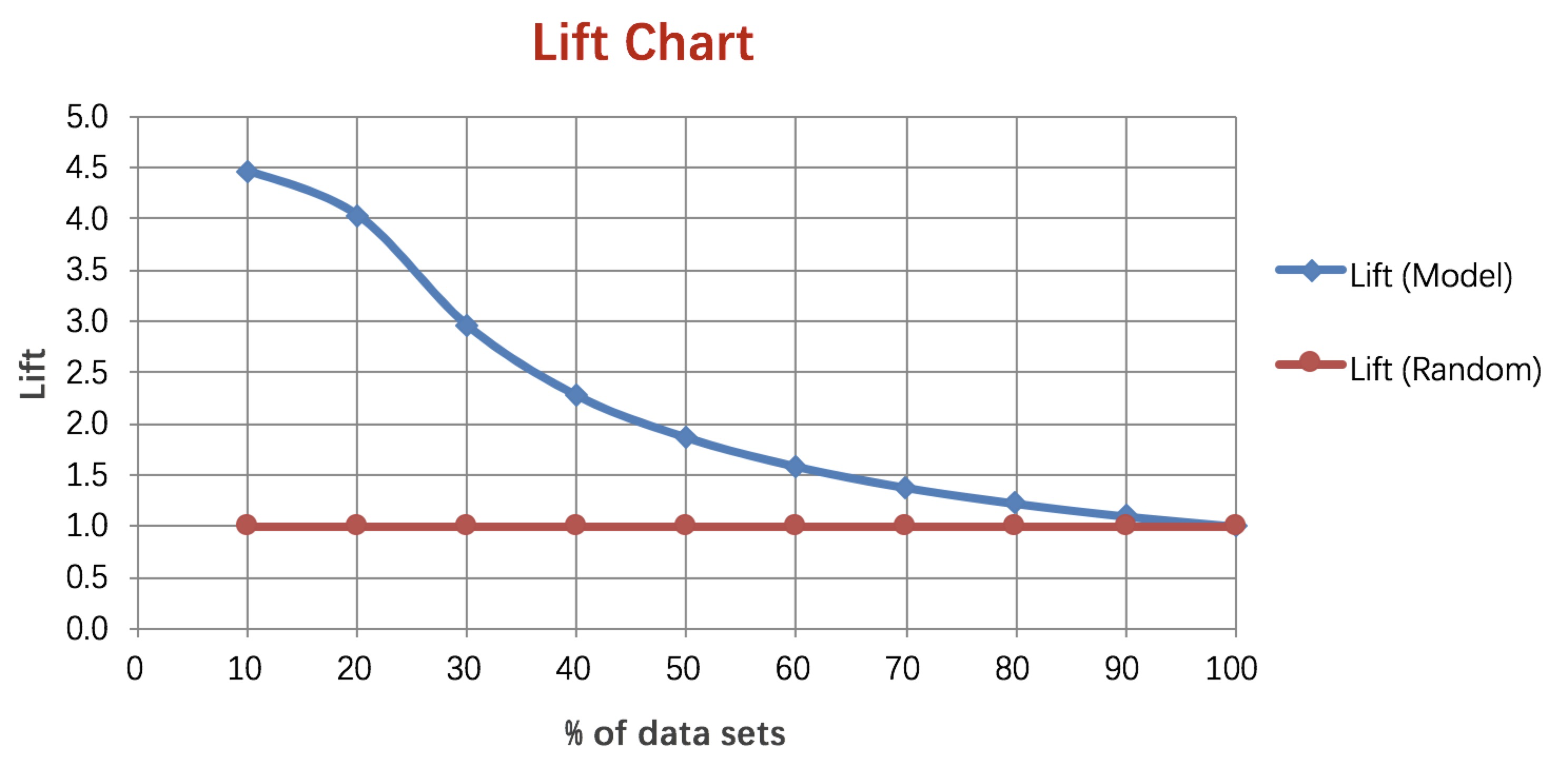
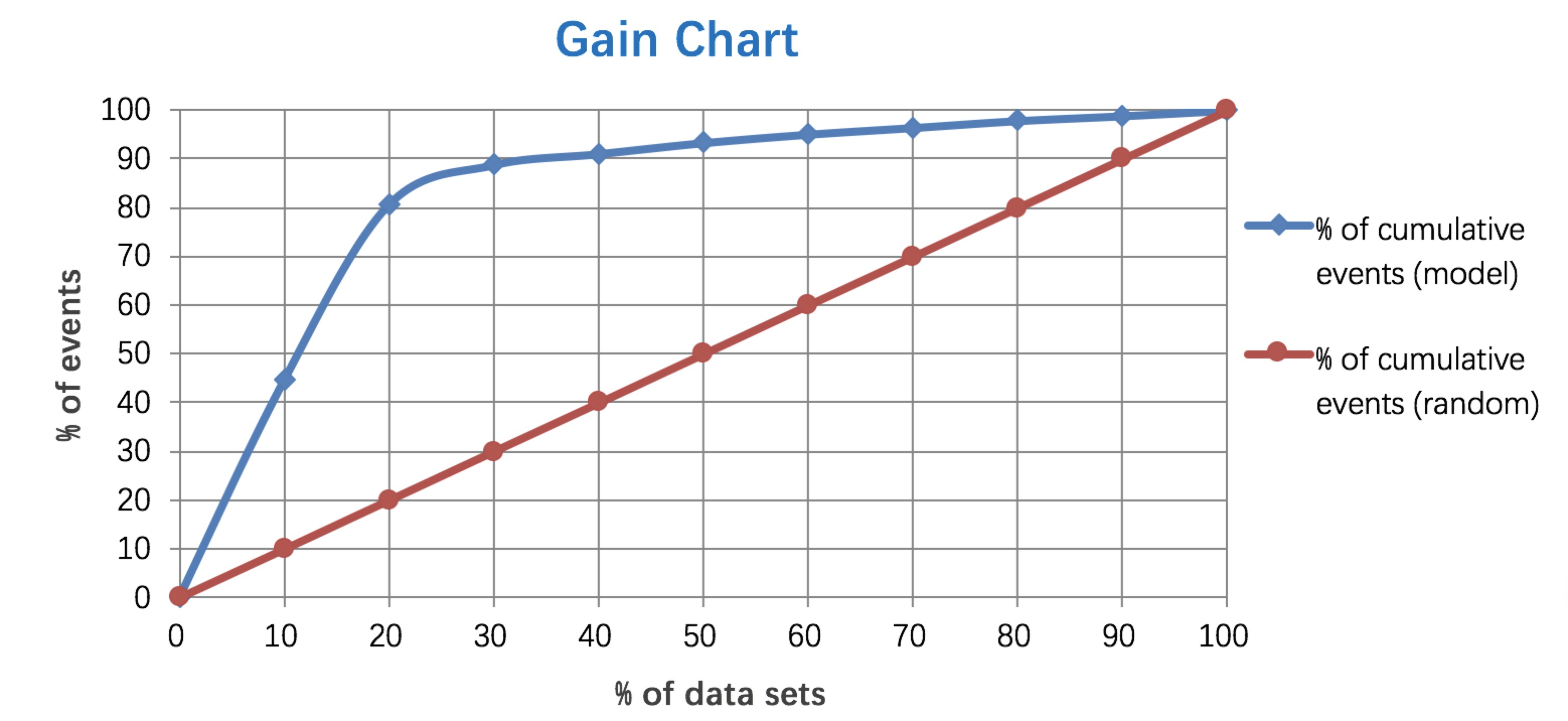
4、LIft和gain
Lift图衡量的是,与不利用模型相比,模型的预测能力“变好”了多少,lift(提升指数)越大,模型的运行效果越好。
Gain图是描述整体精准度的指标。
计算公式如下:

作图步骤:
(1) 根据学习器的预测结果(注意,是正例的概率值,非0/1变量)对样本进行排序(从大到小)—–这就是截断点依次选取的顺序;
(2) 按顺序选取截断点,并计算Lift和Gain —也可以只选取n个截断点,分别在1/n,2/n,3/n等位置
(二)模型区分度
金融建模评分卡模型的结果需要能对好、坏人群给出区分,衡量的方法主要有:
(1)好、坏人群的分数(或违约概率)的分布的差异:KS;
(2)好、坏人群的分数(或违约概率)的距离:Divegence;
(3)好、坏人群浓度的差异:Gini。
1、KS值
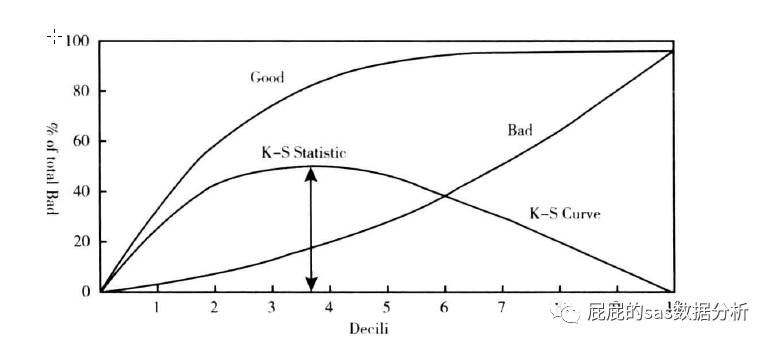
ks曲线是将每一组的概率的好客户以及坏客户的累计占比连接起来的两条线,ks值是当有一个点,好客户减去坏客户的数量是最大的。那么ks的值的意义在于,我在那个违约概率的点切下去,创造的效益是最高的,就图中这张图来说就是我们大概在第三组的概率的中间的这个概率切下,我可以最大的让好客户进来,会让部分坏客户进来,但是也会有少量的坏客户进来,但是这已经是损失最少了,所以可以接受。那么在建模中是,模型的ks要求是达到0.3以上才是可以接受的。
1.1 KS的计算步骤如下:
(1)计算每个评分区间的好坏账户数;
(2) 计算每个评分区间的累计好账户数占总好账户数比率(good%)和累计坏账户数占总坏账户数比率(bad%);
(3)计算每个评分区间累计坏账户占比与累计好账户占比差的绝对值(累计good%-累计bad%), 然后对这些绝对值取最大值即得此评分卡的K-S值。
1.2 KS评价:
KS: <20% : 差
KS: 20%-40% : 一般
KS: 41%-50% : 好
KS: 51%-75% : 非常好
KS: >75% : 过高,需要谨慎的验证模型
KS值的不足:ks只能区分度最好的分数的区分度,不能衡量其他分数。
2、Divergence
计算公式如下:
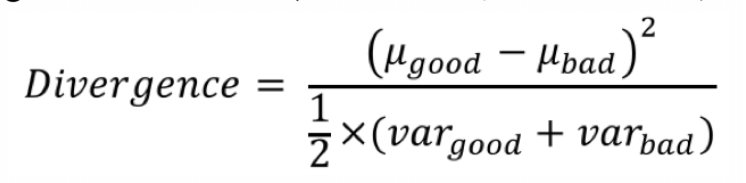 其中,u表示好、坏分数的均值,var表示好、坏分数的标准差。Divergence越大说明区分度越好。
其中,u表示好、坏分数的均值,var表示好、坏分数的标准差。Divergence越大说明区分度越好。
3、Gini系数
GINI统计值衡量坏账户数在好账户数上的的累积分布与随机分布曲线之间的面积,好账户与坏账户分布之间的差异越大,GINI指标越高,表明模型的风险区分能力越强。
GINI系数的计算步骤如下:
(1)计算每个评分区间的好坏账户数。
(2) 计算每个评分区间的累计好账户数占总好账户数比率(累计good%)和累计坏账户数占总坏账户数比率(累计bad%)。
(3) 按照累计好账户占比和累计坏账户占比得出下图所示曲线ADC。
(4)计算出图中阴影部分面积,阴影面积占直角三角形ABC面积的百分比,即为GINI系数。
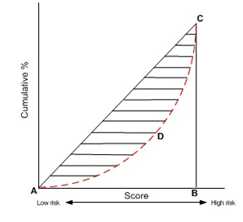
如上图Gini系数=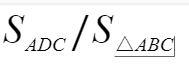
(二)模型区稳定度
群体稳定性指标PSI(Population Stability Index)是衡量模型的预测值与实际值偏差大小的指标。一般psi是在放款观察期(如6个月)后开始计算,来判断模型的稳定情况,如果出现比较大的偏差再进行模型的调整。说的明白些PSI表示的就是按分数分档后,针对不同样本,或者不同时间的样本,population分布是否有变化,就是看各个分数区间内人数占总人数的占比是否有显著变化,通常要求psi<0.25。公式如下:
PSI = sum((实际占比-预期占比)* ln(实际占比/预期占比))
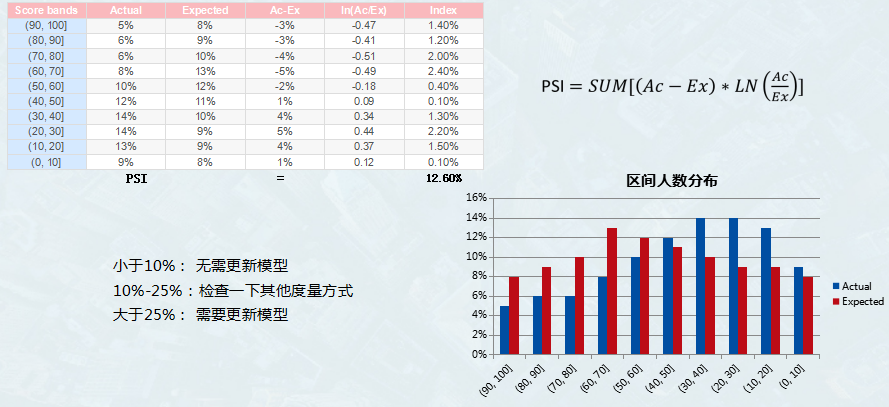
PSI实际应用范例:
(1)样本外测试,针对不同的样本测试一下模型稳定度,比如训练集与测试集,也能看出模型的训练情况,我理解是看出模型的方差情况。
(2)时间外测试,测试基准日与建模基准日相隔越远,测试样本的风险特征和建模样本的差异可能就越大,因此PSI值通常较高。至此也可以看出模型建的时间太长了,是不是需要重新用新样本建模了。
特别:模型调优
模型需要进行必要的调优,当遇到如下情形时:
(1)监控结果不满足要求,如连续3个月的KS低于30%,AUC低于70%,PSI高于25% ;
(2)产品发生变化 额度提高,周期提高,利率降低 ;
(3)人群发生变化 准入政策发生变化 ;
(4)其他宏观因素发生变化。
参考文献:
https://blog.csdn.net/dingustb/article/details/81348430
https://blog.csdn.net/chocolate_chuqi/article/details/81112051
http://www.sohu.com/a/196865493_99950807
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185467.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
