大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
前面介绍了MySQL批量插入可以通过存储过程的方式来实现,这里介绍批量插入100W记录,并做一个优化。
建表语句:create_table.sql
drop table if exists xx_user;
create table xx_user(
id int primary key auto_increment,
name varchar(20),
age int);直接插入:proc.sql
delimiter //
drop procedure if exists add_user;
create procedure add_user()
begin
declare i int default 0;
set i=0;
while i<=1000000 do
set i=i+1;
insert into xx_user(name,age) values (concat('user-',i),20);
end while;
end;
//
delimiter ;默认情况下,直接调用生成的存储过程,批量插入100w条记录,耗时如下:
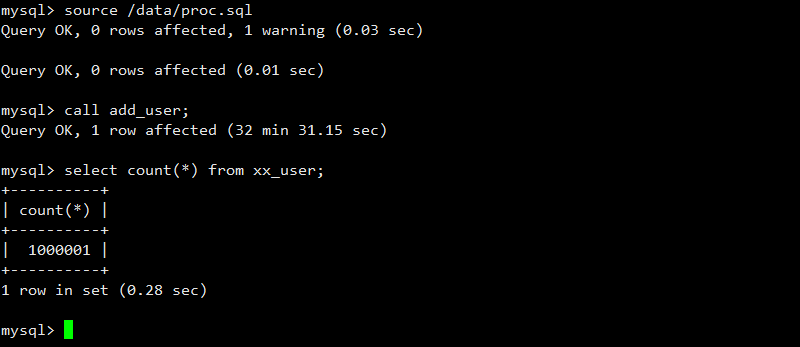

这种循环单条记录插入的方式建议不要直接操作,非常耗时。
多values插入:batch.sql
drop procedure if exists batch_insert;
delimiter //
create procedure batch_insert()
begin
declare i int;
set i = 0;
set @sqlstr='insert into xx_user(name,age) values ';
while i<=1000000 do
set i=i+1;
set @sqlstr=concat(@sqlstr,'(concat(''user-'',',i,'),18)');
if mod(i,5000)=0 then
prepare stmt from @sqlstr;
execute stmt;
deallocate prepare stmt;
set @sqlstr='insert into xx_user(name,age) values ';
else
set @sqlstr=concat(@sqlstr,',');
end if;
end while;
end;
//
delimiter ;这个是利用了多个values批量插入的办法,速度明显要高于第一种循环单条记录插入的办法,如下图所示,时间缩短到接近90秒:
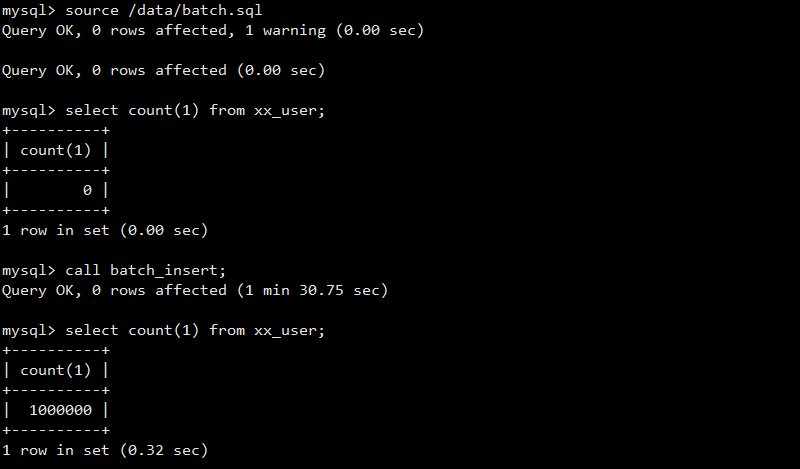
优化参数:
set global bulk_insert_buffer_size=104857600;
set session autocommit=off;
set session unique_checks=off;
当使用以上优化之后,第一个循环插入单条记录的办法,速度提升的惊人,效果如下,时间接近60秒:
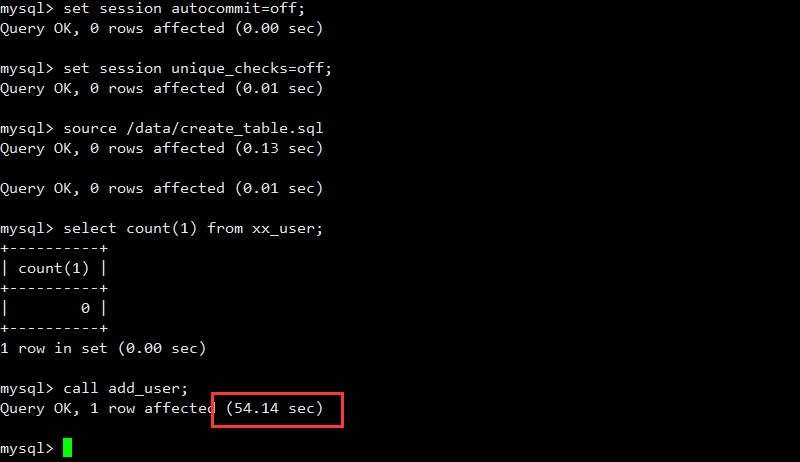
当我们利用优化后的环境进行多values批量插入测试,发现速度并没有明显的改变。如下所示:
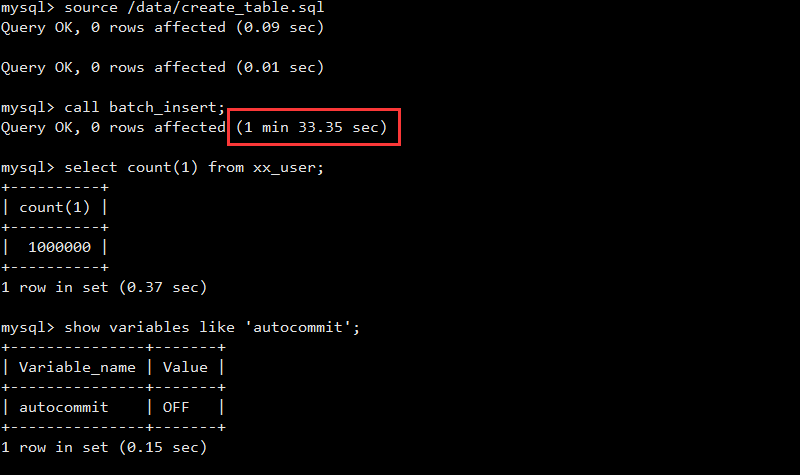
这个速度接近于90秒,和不做参数修改时差不多。
以上两个插入对比,如果不修改参数的情况下,多values批量插入的办法比普通循环插入的效率要高很多,如果更改了环境变量参数,那么普通循环插入单条记录的效率提升非常快,甚至超过了多values批量插入的效率。
一般而言,如果修改了autocommit,unique_checks为off,那么需要在批量插入之后,将变量值修改回来。比如:
set session autocommit=on;
set session unique_checks=on;
根据很多建议修改bulk_insert_buffer_size大小,默认是8m即8388608,修改为100m,即104857600,无论是循环插入单条记录,还是多values插入,均没有明显的提升效率,所以这里并没有特别的介绍。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185459.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
