大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
工欲善其事必先利其器,在使用该网络之前要先了解该网络的具体细节,我今天也是第一次查资料,然后加上自己的理解去写这篇学习成长文章。
残差模块
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1, dowansample=None):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, 3, stride, 1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, 3, 1, 1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.dowansample=dowasample
def forward(self, x):
out = self.left(x)
residual = x if self.dowansample is None else self.dowansample(x)
out += residual
return F.relu(out)
这是残差模块的代码,下面用一张图来具体介绍
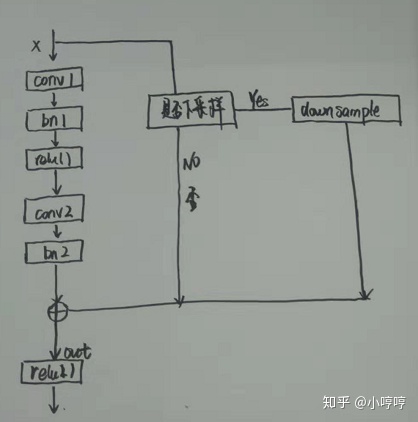
 根据这张图和上面的代码,我们可以看出大概的一个过程,在前向传播函数中可以看到,数据传下来后会先通过两次卷积,也就是此案执行 self.left()函数,downsample是一个下采样函数,根据结果来判断是否执行想采样,残差模块的代码很简单,相信可以看明白。
根据这张图和上面的代码,我们可以看出大概的一个过程,在前向传播函数中可以看到,数据传下来后会先通过两次卷积,也就是此案执行 self.left()函数,downsample是一个下采样函数,根据结果来判断是否执行想采样,残差模块的代码很简单,相信可以看明白。
主干网络模块
网络卷积图
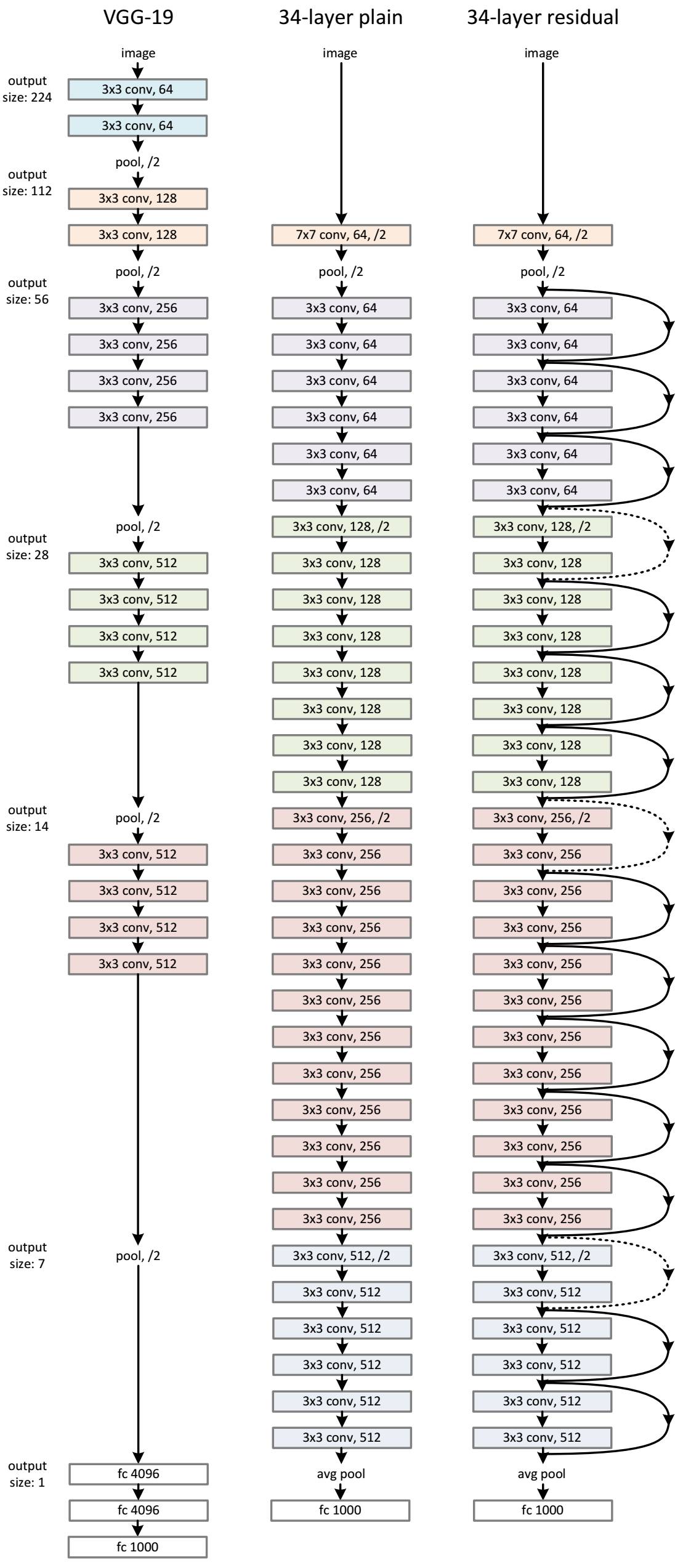 图片上的右边是resnet34残差网络的整体卷积过程,慢慢来逐个理解一下。
图片上的右边是resnet34残差网络的整体卷积过程,慢慢来逐个理解一下。
代码:
class ResNet34(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet34, self).__init__()
self.pre = nn.Sequential(
nn.Conv2d(3, 64, 7, 2 ,3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 1, 1)
)
self.layer1 = self._make_layer(64, 128, 3) ### 3 个 64 通道的残差单元,输出 128通道,共6层
self.layer2 = self._make_layer(128, 256, 4, stride=2) ### 4 个 128通道的残差单元,输出 256通道,共8层
self.layer3 = self._make_layer(256, 512, 6, stride=2) ### 6 个 256通道的残差单元,输出 512通道,共12层
self.layer4 = self._make_layer(512, 512, 3, stride=2) ### 3 个 512通道的残差单元,输出 512通道,共6层
### fc,1层
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
dowansample= nn.Sequential(
nn.Conv2d(inchannel, outchannel, 1, stride, bias=False),
nn.BatchNorm2d(outchannel)
)
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, dowansample)) ### 先来一个残差单元,主要是改变通道数
for i in range(1, block_num+1):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
### 第1层
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
### 注意 resnet 最后的池化是把一个 feature map 变成一个特征,故池化野大小等于最后 x 的大小
x = F.avg_pool2d(x, 2) ### 这里用的 cifar10 数据集,此时的 x size 为 512x2x2,所以池化野为2
x = x.view(x.size(0), -1)
return self.fc(x)
结合上图和代码,可以在初始化函数中看到self.pre()函数,这个函数主要是数据输进来时先通过一个7×7的卷积核来改变数据,也就是上图中 7×7, conv, 64 ,/2 这一行,初始化函数中还有一个self.layer1() , self.layer2() , self.layer3(),self.layer4()这几个函数,这几个分别对应上图的 3×3,conv,64。 3×3,conv,128。 3×3,conv,256 。 3×3,conv,512。
再看他们的函数定义的内容:
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
downsample= nn.Sequential(
nn.Conv2d(inchannel, outchannel, 1, stride, bias=False),
nn.BatchNorm2d(outchannel)
)
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, downsample))
for i in range(1, block_num+1):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
先是一个downsample,里面是一个卷积,然后是一个数组,数组中先放一个残差模块,并且有dawnsample参数,这是在改变两个模块之间的通道数,比如上边3×3,conv,64。 3×3,conv,128。之间,在通道数转变的时候才执行。继续往下看,是一个for循环,循环里面还是向数组中放入残差模块,不同的是这次没有downsample参数了,通过这几行代码产生了上图中3个3×3,conv,64 4个 3×3,conv,128。一次类推,应该可以看明白,self.layer1() , self.layer2() , self.layer3(),self.layer4()这几个函数就是产生了上图竖着的那几十个卷积,接下来就是前向传播了,前向传播很简单,需要明白的是下采样downsample是在两个卷积时通道数不同的时候才执行,如64通过转变成128通道时。这一块也是最经典的地方,加深卷积后,先判断是否有变化,如果有变化,我就把变化加上,然后继续执行下边的卷积,如果没有变化,我就不加,还是继续执行下边的卷积,这样理论上就可以一直往下添加卷积层了。
以上就是我的理解,目前对一些实战中各个卷积层输入输出通道数的选择和卷积核的选择还是有一点疑惑和不解的,需要继续学习。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185457.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
