大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
机器学习的一般框架:
训练集 => 提取特征向量 => 结合一定的算法(分类器:比如决策树、KNN)=>得到结果
1. SVM
支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。SVM 适合中小型数据样本、非线性、高维的分类问题。
SVM 最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出,目前的版本(soft margin)是由 Corinna Cortes 和 Vapnik 在1993年提出,并在1995年发表。深度学习(2012)出现之前,SVM 被认为机器学习中近十几年来最成功,表现最好的算法。
1.1 SVM 基本概念
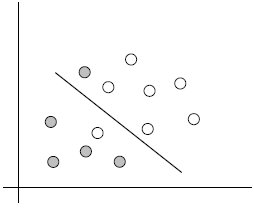
将实例的特征向量(以二维为例)映射为空间中的一些点,如下图的实心点和空心点,它们属于不同的两类。SVM 的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
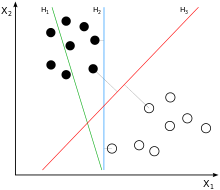

Q1:能够画出多少条线对样本点进行区分?
答:线是有无数条可以画的,区别就在于效果好不好,每条线都可以叫做一个划分超平面。比如上面的绿线就不好,蓝线还凑合,红线看起来就比较好。我们所希望找到的这条效果最好的线就是具有 “最大间隔的划分超平面”。
Q2:为什么要叫作“超平面”呢?
答:因为样本的特征很可能是高维的,此时样本空间的划分就不是一条线了。
Q3:画线的标准是什么?/ 什么才叫这条线的效果好?/ 哪里好?
答:SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。比较好的划分超平面,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
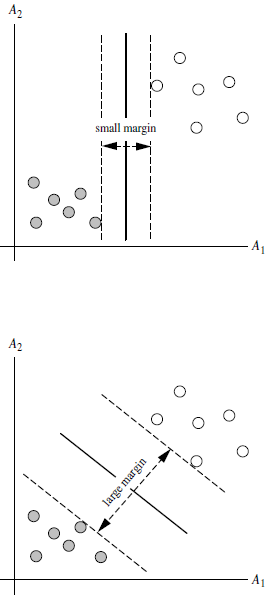
Q4:间隔(margin)是什么?
答:对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。比如下图中两条虚线构成的带状区域就是 margin,虚线是由距离中央实线最近的两个点所确定出来的(也就是由支持向量决定)。但此时 margin 比较小,如果用第二种方式画,margin 明显变大也更接近我们的目标。
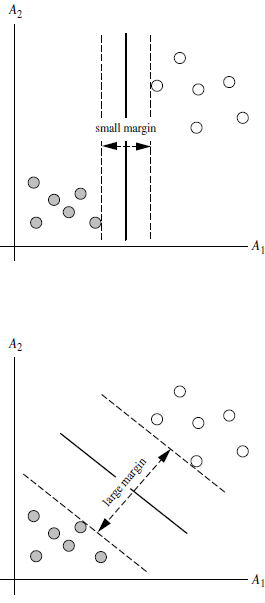
Q5:为什么要让 margin 尽量大?
答:因为大 margin 犯错的几率比较小,也就是更鲁棒啦。
Q6:支持向量是什么?
答:从上图可以看出,虚线上的点到划分超平面的距离都是一样的,实际上只有这几个点共同确定了超平面的位置,因此被称作 “支持向量(support vectors)”,“支持向量机” 也是由此来的。
1.2 hard-margin SVM
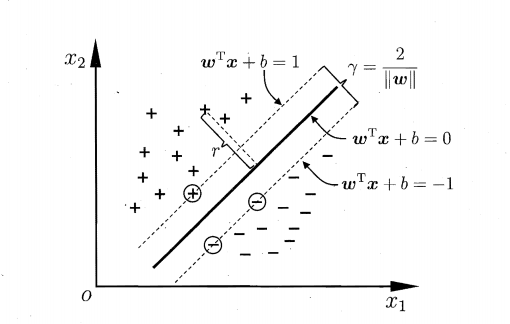
划分超平面可以定义为一个线性方程: w T X + b = 0 w^TX+b=0 wTX+b=0,其中:
- w = { w 1 ; w 2 ; . . . ; w d } w = \{w_1;w_2;…;w_d\} w={
w1;w2;...;wd} 是一个法向量,决定了超平面的方向, d d d 是特征值的个数 - X X X 为训练样本
- b b b 为位移项,决定了超平面与原点之间的距离
只要确定了法向量 w w w 和位移 b b b,就可以唯一地确定一个划分超平面。划分超平面和它两侧的边际超平面上任意一点的距离为 1 ∣ ∣ w ∣ ∣ \frac{1}{||w||} ∣∣w∣∣1。
利用一些数学推导,公式 y i ∗ ( w 0 + w 1 x 1 + w 2 x 2 ) ≥ 1 , ∀ i y_i*(w_0+w_1x_1+w_2x_2)\geq1,\ \forall i yi∗(w0+w1x1+w2x2)≥1, ∀i 可变为有限制的凸优化问题(convex quadratic optimization)
利用 Karush-Kuhn-Tucker (KKT)条件和拉格朗日公式,可以推出 MMH 可以被表示为以下“决定边界 (decision boundary)”
d ( X T ) = ∑ i = 1 l y i α i X i X T + b 0 d(X^T)=\sum_{i=1}^ly_i\alpha_iX_iX^T+b_0 d(XT)=i=1∑lyiαiXiXT+b0
此方程就代表了边际最大化的划分超平面。
- l l l 是支持向量点的个数,因为大部分的点并不是支持向量点,只有个别在边际超平面上的点才是支持向量点。那么我们就只对属于支持向量点的进行求和;
- X i X_i Xi 为支持向量点的特征值;
- y i y_i yi 是支持向量点 X i X_i Xi的类别标记(class label),比如+1还是-1;
- X T X^T XT 是要测试的实例,想知道它应该属于哪一类,把它带入该方程
- α i \alpha _i αi 和 b 0 b_0 b0 都是单一数值型参数,由以上提到的最优算法得出, α i \alpha _i αi 是拉格朗日乘数。
每当有新的测试样本 X X X,将它带入该方程,看看该方程的值是正还是负,根据符号进行归类。
1.3 SVM 应用实例
看一下 SVM 如何求出一个划分超平面。
我们已经知道了两个支持向量点(1,1)和(2,3),设置权重为 w = ( a , 2 a ) w = (a,2a) w=(a,2a),那么将这两个支持向量点坐标分别带入公式 w T x + b = ± 1 w^Tx+b=\pm1 wTx+b=±1 中,可以得到:
a + 2 a + w 0 = − 1 , u s i n g p o i n t ( 1 , 1 ) a+2a+w_0=-1,\ \ \ using\ point\ (1,1) a+2a+w0=−1, using point (1,1)
2 a + 6 a + w 0 = 1 , u s i n g p o i n t ( 2 , 3 ) 2a+6a+w_0=1,\ \ \ using \ point\ (2,3) 2a+6a+w0=1, using point (2,3)
那么未知数就是 a a a 和 w 0 w_0 w0,解方程组可得: a = 2 5 a=\frac{2}{5} a=52, w 0 = − 11 5 w_0=-\frac{11}{5} w0=−511
带回到权重向量 w w w 中有: w = ( a , 2 a ) = ( 2 5 , 4 5 ) w=(a,2a)=(\frac{2}{5},\frac{4}{5}) w=(a,2a)=(52,54)
那么划分超平面为 x 1 + 2 x 2 − 5.5 = 0 x_1+2x_2-5.5=0 x1+2x2−5.5=0
最后可以用点(2,0)验证一下这个划分超平面的分类效果。
由于 SVM 算法本身的实现非常复杂,所以不研究如何实现 SVM,而是采用 sklearn 库来学习 SVM 的应用问题。
# sklearn 库中导入 svm 模块
from sklearn import svm
# 定义三个点和标签
X = [[2, 0], [1, 1], [2,3]]
y = [0, 0, 1]
# 定义分类器,clf 意为 classifier,是分类器的传统命名
clf = svm.SVC(kernel = 'linear') # .SVC()就是 SVM 的方程,参数 kernel 为线性核函数
# 训练分类器
clf.fit(X, y) # 调用分类器的 fit 函数建立模型(即计算出划分超平面,且所有相关属性都保存在了分类器 cls 里)
# 打印分类器 clf 的一系列参数
print(clf)
# 支持向量
print(clf.support_vectors_)
# 属于支持向量的点的 index
print(clf.support_)
# 在每一个类中有多少个点属于支持向量
print(clf.n_support_)
# 预测一个新的点
print(clf.predict([[2,0]]))
输出结果:
# 打印分类器 clf 的一系列参数
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto_deprecated',
kernel='linear', max_iter=-1, probability=False, random_state=None,
shrinking=True, tol=0.001, verbose=False)
# 支持向量
[[1. 1.]
[2. 3.]]
# 属于支持向量的点的 index
[1 2]
# 在每一个类中有多少个点属于支持向量
[1 1]
# 预测一个新的点
[0]
print(__doc__)
# 导入相关的包
import numpy as np
import pylab as pl # 绘图功能
from sklearn import svm
# 创建 40 个点
np.random.seed(0) # 让每次运行程序生成的随机样本点不变
# 生成训练实例并保证是线性可分的
# np._r表示将矩阵在行方向上进行相连
# random.randn(a,b)表示生成 a 行 b 列的矩阵,且随机数服从标准正态分布
# array(20,2) - [2,2] 相当于给每一行的两个数都减去 2
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
# 两个类别 每类有 20 个点,Y 为 40 行 1 列的列向量
Y = [0] * 20 + [1] * 20
# 建立 svm 模型
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# 获得划分超平面
# 划分超平面原方程:w0x0 + w1x1 + b = 0
# 将其转化为点斜式方程,并把 x0 看作 x,x1 看作 y,b 看作 w2
# 点斜式:y = -(w0/w1)x - (w2/w1)
w = clf.coef_[0] # w 是一个二维数据,coef 就是 w = [w0,w1]
a = -w[0] / w[1] # 斜率
xx = np.linspace(-5, 5) # 从 -5 到 5 产生一些连续的值(随机的)
# .intercept[0] 获得 bias,即 b 的值,b / w[1] 是截距
yy = a * xx - (clf.intercept_[0]) / w[1] # 带入 x 的值,获得直线方程
# 画出和划分超平面平行且经过支持向量的两条线(斜率相同,截距不同)
b = clf.support_vectors_[0] # 取出第一个支持向量点
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1] # 取出最后一个支持向量点
yy_up = a * xx + (b[1] - a * b[0])
# 查看相关的参数值
print("w: ", w)
print("a: ", a)
print("support_vectors_: ", clf.support_vectors_)
print("clf.coef_: ", clf.coef_)
# 在 scikit-learin 中,coef_ 保存了线性模型中划分超平面的参数向量。形式为(n_classes, n_features)。若 n_classes > 1,则为多分类问题,(1,n_features) 为二分类问题。
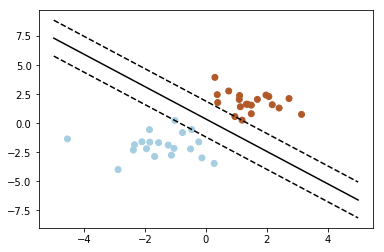
# 绘制划分超平面,边际平面和样本点
pl.plot(xx, yy, 'k-')
pl.plot(xx, yy_down, 'k--')
pl.plot(xx, yy_up, 'k--')
# 圈出支持向量
pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()
输出结果:
Automatically created module for IPython interactive environment
w: [0.90230696 0.64821811]
a: -1.391980476255765
support_vectors_: [[-1.02126202 0.2408932 ]
[-0.46722079 -0.53064123]
[ 0.95144703 0.57998206]]
clf.coef_: [[0.90230696 0.64821811]]
2. 核方法
使用核方法的动机
在线性 SVM 中转化为最优化问题时求解的公式计算都是以内积(dot product)形式出现的,其中 ϕ ( X ) \phi(X) ϕ(X) 是把训练集中的向量点转化到高维的非线性映射函数,因为内积的算法复杂度非常大,所以我们利用核函数来取代计算非线性映射函数的内积。
以下核函数和非线性映射函数的内积等同,但核函数 K 的运算量要远少于求内积。
K ( X i , X j ) = ϕ ( X i ) ⋅ ϕ ( X j ) K(X_i,X_j)=\phi(X_i)·\phi(X_j) K(Xi,Xj)=ϕ(Xi)⋅ϕ(Xj)
常用的核函数(kernel functions)
h 度多项式核函数(polynomial kernel of degree h):
K ( X i , X j ) = ( X i , X j + 1 ) h K(X_i,X_j)=(X_i,X_j+1)^h K(Xi,Xj)=(Xi,Xj+1)h
高斯径向基核函数(Gaussian radial basis function kernel):
K ( X i , X j ) = e − ∣ ∣ X i − X j ∣ ∣ 2 / 2 σ 2 K(X_i,X_j)=e^{-||X_i-X_j||^2/2\sigma^2} K(Xi,Xj)=e−∣∣Xi−Xj∣∣2/2σ2
S 型核函数(Sigmoid function kernel):
K ( X i , X j ) = t a n h ( k X i ⋅ X j − δ ) K(X_i,X_j)=tanh(kX_i·X_j-\delta) K(Xi,Xj)=tanh(kXi⋅Xj−δ)
如何选择使用哪个 kernel ?
- 根据先验知识,比如图像分类,通常使用 RBF(高斯径向基核函数),文字不使用 RBF。
- 尝试不同的 kernel,根据结果准确度而定尝试不同的 kernel,根据结果准确度而定。
核函数举例
假设定义两个向量: x = ( x 1 , x 2 , x 3 ) x = (x_1, x_2, x_3) x=(x1,x2,x3), y = ( y 1 , y 2 , y 3 ) y = (y_1, y_2, y_3) y=(y1,y2,y3)
定义方程:
f ( x ) = ( x 1 x 1 , x 1 x 2 , x 1 x 3 , x 2 x 1 , x 2 x 2 , x 2 x 3 , x 3 x 1 , x 3 x 2 , x 3 x 3 ) f(x) = (x_1x_1, x_1x_2, x_1x_3, x_2x_1, x_2x_2, x_2x_3, x_3x_1, x_3x_2, x_3x_3) f(x)=(x1x1,x1x2,x1x3,x2x1,x2x2,x2x3,x3x1,x3x2,x3x3)
核函数: K ( x , y ) = ( < x , y > ) 2 K(x,y ) = (<x,y>)^2 K(x,y)=(<x,y>)2
假设: x = ( 1 , 2 , 3 ) x = (1, 2, 3) x=(1,2,3), y = ( 4 , 5 , 6 ) y = (4, 5, 6) y=(4,5,6)
不用核函数,直接求内积:
f ( x ) = ( 1 , 2 , 3 , 2 , 4 , 6 , 3 , 6 , 9 ) f(x) = (1, 2, 3, 2, 4, 6, 3, 6, 9) f(x)=(1,2,3,2,4,6,3,6,9)
f ( y ) = ( 16 , 20 , 24 , 20 , 25 , 36 , 24 , 30 , 36 ) f(y) = (16, 20, 24, 20, 25, 36, 24, 30, 36) f(y)=(16,20,24,20,25,36,24,30,36)
< f ( x ) , f ( y ) > = 16 + 40 + 72 + 40 + 100 + 180 + 72 + 180 + 324 = 1024 <f(x), f(y)> = 16 + 40 + 72 + 40 + 100+ 180 + 72 + 180 + 324 = 1024 <f(x),f(y)>=16+40+72+40+100+180+72+180+324=1024
使用核函数:
K ( x , y ) = ( 4 + 10 + 18 ) 2 = 3 2 2 = 1024 K(x, y) = (4 + 10 + 18 ) ^2 = 32^2 = 1024 K(x,y)=(4+10+18)2=322=1024
同样的结果,使用 kernel 方法计算容易很多。而这只是 9 维的情况,如果维度更高,那么直接求内积的方法运算复杂度会非常大。
所以使用 kernel 的意义在于:
- 将向量的维度从低维映射到高维
- 降低运算复杂度降低运算复杂度
相关概念补充
线性可区分和线性不可区分
能够用一条直线对样本点进行分类的属于线性可区分(linear separable),否则为线性不可区分(linear inseparable)。
以下三个例子,都是线性不可区分的,即无法用一条直线将两类样本点区分开。
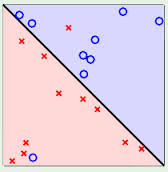
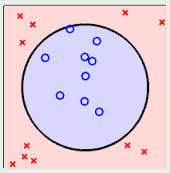
而刚才的例子就是线性可区分的。
在线性不可分的情况下,数据集在空间中对应的向量无法被一个超平面区分开,如何处理?
:两个步骤来解决:
- 利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中(比如下图将二维空间中的点映射到三维空间)
- 在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理
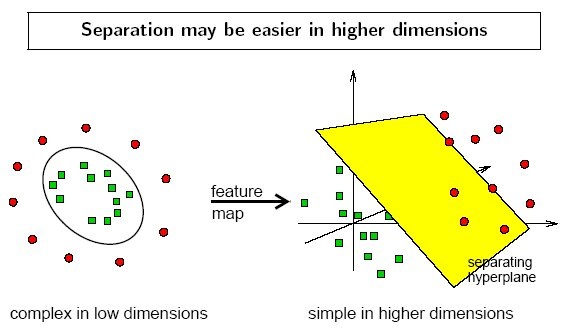
比如想要将红点和蓝点变成线性可分的,那么就将映射 y = x y=x y=x 变成映射 y = x 2 y=x^2 y=x2,这样就线性可分了。

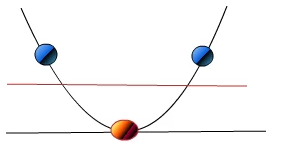
视觉化演示:https://www.youtube.com/watch?v=3liCbRZPrZA
如何利用非线性映射将原始数据转化到高维空间中去?
例子:
有一个 3 维输入向量: X = ( x 1 , x 2 , x 3 ) X=(x_1,x_2,x_3) X=(x1,x2,x3)
将其转化到 6 维空间 Z 中去:
ϕ 1 ( X ) = x 1 , ϕ 2 ( X ) = x 2 , ϕ 3 ( X ) = x 3 , ϕ 4 ( X ) = ( x 1 ) 2 , ϕ 5 ( X ) = x 1 x 2 , a n d ϕ 6 ( X ) = x 1 x 3 \phi_1(X)=x_1,\phi_2(X)=x_2,\phi_3(X)=x_3,\phi_4(X)=(x_1)^2,\phi_5(X)=x_1x_2,and\ \phi_6(X)=x_1x_3 ϕ1(X)=x1,ϕ2(X)=x2,ϕ3(X)=x3,ϕ4(X)=(x1)2,ϕ5(X)=x1x2,and ϕ6(X)=x1x3
新的决策超平面: d ( Z ) = W Z + b d(Z)=WZ+b d(Z)=WZ+b,其中 W 和 Z 是向量,这个超平面是线性的。
解出 W 和 b 之后,并且带入回原方程:
d ( Z ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 4 ( x 1 ) 2 + w 5 x 1 x 2 + w 6 x 1 x 3 + b = w 1 z 1 + w 2 z 2 + w 3 z 3 + w 4 z 4 + w 5 z 5 + w 6 z 6 + b d(Z)=w_1x_1+w_2x_2+w_3x_3+w_4(x_1)^2+w_5x_1x_2+w_6x_1x_3+b=w_1z_1+w_2z_2+w_3z_3+w_4z_4+w_5z_5+w_6z_6+b d(Z)=w1x1+w2x2+w3x3+w4(x1)2+w5x1x2+w6x1x3+b=w1z1+w2z2+w3z3+w4z4+w5z5+w6z6+b
思考问题:
- 如何选择合理的非线性转化把数据转到高维空间中?
- 如何解决计算内积时算法复杂度非常高的问题?
:使用核方法(kernel trick)
SVM 可扩展到多分类问题
SVM 扩展可解决多个类别分类问题:
对于每个类,有一个当前类和其他类的二类分类器(one-vs-rest)
将多分类问题转化为 n 个二分类问题,n 就是类别个数。
SVM 算法特性
- 训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以 SVM 不太容易产生 overfitting。
- SVM 训练出来的模型完全依赖于支持向量,即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
- 一个 SVM 如果训练得出的支持向量个数比较少,那么SVM 训练出的模型比较容易被泛化。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185441.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
