大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
在使用sklearn训练完分类模型后,下一步就是要验证一下模型的预测结果,对于分类模型,sklearn中通常提供了predict_proba、predict、decision_function三种方法来展示模型对于输入样本的评判结果。
说明一下,在sklearn中,对于训练好的分类模型,模型都有一个classes_属性,classes_属性中按顺序保存着训练样本的类别标记。下面是使用Logistic Regression分类器在为例,展示一下分类器的classes_属性。
1、先看一下样本标签从0开始的场景下训练分类模型
import numpy as np
from sklearn.linear_model import LogisticRegression
x = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([2, 2, 3, 3, 0, 0, 1, 1])
clf = LogisticRegression()
clf.fit(x, y)
print(clf.classes_)
"""
输出结果:[0 1 2 3]
"""2、下面看一下样本标签不是从0开始的场景下训练分类模型
import numpy as np
from sklearn.linear_model import LogisticRegression
x = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([6, 6, 2, 2, 4, 4, 8, 8])
clf = LogisticRegression()
clf.fit(x, y)
print(clf.classes_)
"""
输出结果:[2 4 6 8]
"""注意观察上述两种情况下classes_属性的输出结果,该输出结果的顺序就对应后续要说predict_proba、predict、decision_function输出结果的顺序或顺序组合。
在了解了分类模型classes_的标签顺序之后,下面看一下分类模型predict_proba、predict、decision_function三种函数输出结果的含义,以及他们之间的相关性。
1、predict_proba: 模型预测输入样本属于每种类别的概率,概率和为1,每个位置的概率分别对应classes_中对应位置的类别标签。以上述类别标签为[2 4 6 8]的那个分类器为例,查看一下分类模型预测的概率。


输入的[-1, -1]刚好是训练分类器时使用的数据,训练数据中[-1, -1]属于类别6,在predict_proba输出概率中,最大概率值出现在第三个位置上,第三个位置对应的classes_类别刚好也是类别6。这也就是说,predict_proba输出概率最大值索引位置对应的classes_元素就是样本所属的类别。下面就来看一下predict的预测结果与predict_proba的预测结果是否一致。
2、predict: 模型预测输入样本所属的类别,是则输出1,不是则输出0。
在上一步中知道了predict_proba是输出样本属于各个类别的概率,且取概率最大的类别作为样本的预测结果,下面看一下predict的预测结果与predict_proba的最大值是否一致。

predict的预测结果为类别6,对应于classes_中的第三个元素,也同时对应于predict_proba中的第三个元素,且是概率值最大的元素。
对于分类模型来说,通常知道模型的预测结果predict和预测概率predict_proba就可以了,那分类模型中的decision_function是干什么的呢?
3、decision_function: 帮助文档中给出的解释是“The confidence score for a sample is the signed distance of that sample to the hyperplane.”。意思就是使用样本到分隔超平面的有符号距离来度量预测结果的置信度,反正我是有点懵逼。放大招,灵魂三问。他是谁?他从哪里来?他到哪里去?
他是谁?
看一下支持向量机SVM中关于decision_function的解释是怎样的?

说了两件事情,其一是说评估样本X的的decision_function(等于没说,哈哈哈),其二是说,如果decision_dunction_shape=’ovr’,则输出的decison_function形状是(n_samples, n_classes), n_samples是输入样本的数量,n_classes是训练样本的类别数。这里再补充一点,如果decision_dunction_shape=’ovo,则输出的decison_function形状是(n_samples, n_classes * (n_classes – 1) / 2)。‘ovr’和‘ovo’又是啥?莫急,莫急。暂且知道是用于训练多分类的就行。
大致解释下decison_function就是用来衡量待预测样本到分类模型各个分隔超平面的距离(没找到太直观的解释方法)。
他从哪里来?
据说这家伙来自遥远的SVM星球。上面说这哥们能和分隔超平面扯上关系,熟悉SVM的会知道,SVM中通过支持向量来选择分隔超平面,分隔超平面将训练样本分为正反两派,支持向量的作用就是使得选择的分隔超平面离两边的类别都比较远,这样模型具有更强的健壮性。
他到哪里去?
说了半天,decison_function这玩意到底有啥用?莫急,莫急。下面先说一下上面提到的’ovr’和’ovo’分别是什么东东?
我们常见的分类器,比如LR和SVM都是只能支持二分类的,回想一下LR分类器,通过判断线性模型的预测结果是否大于0,进而判断sigmoid的输出结果是否大于0.5来判断模型属于正类还是负类。SVM也一样,前面讲了,SVM通过分隔超平面将样本分到两边去,也就是进行二分类。那么怎么能将二分类的分类算法应用到多分类任务上去呢?这就是‘ovr’和‘ovo’要解决的问题。
‘ovr’:全称是One-vs-Rest。就是一个人和对面一群人干一次架(群殴)。假如我们训练数据中包含[0, 1, 2, 3]四个分类,那么分别将0, 1, 2, 3作为正样本,其余的123, 023, 013, 012作为负样本,训练4个分类器,每个分类器预测的结果表示属于对应正类也就是0, 1, 2, 3 的概率。这样对于一个输入样本就相当于要进行4个二分类,然后取输出结果最大的数值对应的classes_类别。
‘ovo’:全称是One-vs-One。就是一个人分别和对面的每个人干一次架(单挑,车轮战术)。同样,假如我们训练数据中包含[0, 1, 2, 3]四个分类,先将类别0作为正样本,类别1,类别2,类别3依次作为负样本训练3个分类器,然后以类别1为正样本,类别0,类别2, 类别3作为负样本训练3个分类器,以此类推。由于类别0为正样本,类别1为负样本和类别1为正样本、类别0为负样本实质上是一样的,所以不需要重复训练。
通过上面的描述可知,假如训练样本有n_classes个类别,则’ovr’模式需要训练n_classes个分类器,‘ovo’模式需要训练n_classes * (n_classes – 1) / 2 个分类器。那么问题来了,有多少个分类器是不是就得有多少个分隔超平面,有多少个分隔超平面是不是就得有多少个decision_function值。这也就对应了“他是谁?”那部分所说的decison_function输出形状的描述。
下面进入正题,来看一下decision_function的真面目。
1、二分类的decison_function
二分类模型中,decision_function返回的数组形状等于样本个数,也就是一个样本返回一个decision_function值。并且,此时的decision_function_shape参数失效 ,因为只需要训练一个分类器就行了,就不存在是单挑还是群殴的问题了。下面以SVM二分类的实例来看一下结果:
import numpy as np
from sklearn.svm import SVC
x = np.array([[1,2,3],
[1,3,4],
[2,1,2],
[4,5,6],
[3,5,3],
[1,7,2]])
y = np.array([3, 3, 3, 2, 2, 2])
clf = SVC(probability=True)
clf.fit(x, y)
print(clf.decision_function(x))
# 返回array([2, 3]),其中2为negetive,3为positive
print(clf.classes_)在二分类的情况下,分类模型的decision_function返回结果的形状与样本数量相同,且返回结果的数值表示模型预测样本属于positive正样本的可信度。并且,二分类情况下classes_中的第一个标签代表是负样本,第二个标签代表正样本。
模型在训练集上的decision_function以及predict_procaba、predict结果如下:
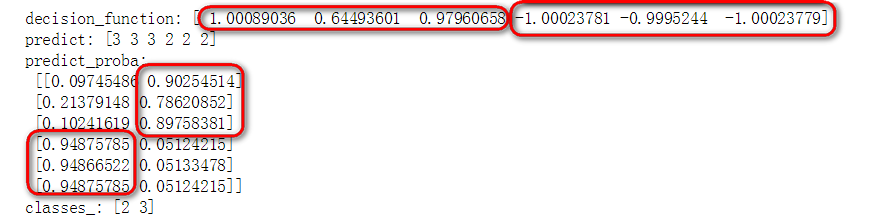
还记得前面讲过的decision_function是有符号的吧,大于0表示正样本的可信度大于负样本,否则可信度小于负样本。所以对于前3个样本,decison_function都认为是正样本的可信度高,后3个样本是负样本的可信度高。那么再看一下predict的结果,前3个预测为正样本3(ps:二分类情况下正样本对应的是classes_中的第二个类别),后3个样本预测为负样本2。再看一下predict_proba预测的样本所属的类别概率,可以看到前3个样本属于类别3的概率更大,后3个样本属于类别2的概率更大。
2、多分类的decision_function
多分类模型中,decision_function返回的数组形状依据使用的模式是‘ovr’还是‘ovo’而分别返回n_classes个和n_classes * (n_classes – 1) / 2个数值。下面以SVM多分类的实例来看一下结果:
One-vs-Rest多分类实例:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
X = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([2, 2, 3, 3, 0, 0, 1, 1])
# SVC多分类模型默认采用ovr模式
clf = SVC(probability=True, decision_function_shape="ovr")
clf.fit(X, y)
# 计算样本距离每个分类边界的距离
# One-vs-One 按照decision_function的得分[01, 02, 03, 12, 13, 23]判断每个分类器的分类结果,然后进行投票
# One-vs-Rest 选择decision_function的得分[0-Rest, 1-Rest, 2-Rest, 3-Rest]最大的作为分类结果
print("decision_function:\n", clf.decision_function(X))
# precidt预测样本对应的标签类别
print("predict:\n", clf.predict(X))
# predict_proba 预测样本对应各个类别的概率
print("predict_proba:\n", clf.predict_proba(X)) #这个是得分,每个分类器的得分,取最大得分对应的类。
print("classes_:", clf.classes_)模型在训练集上的decision_function以及predict_procaba、predict结果如下:
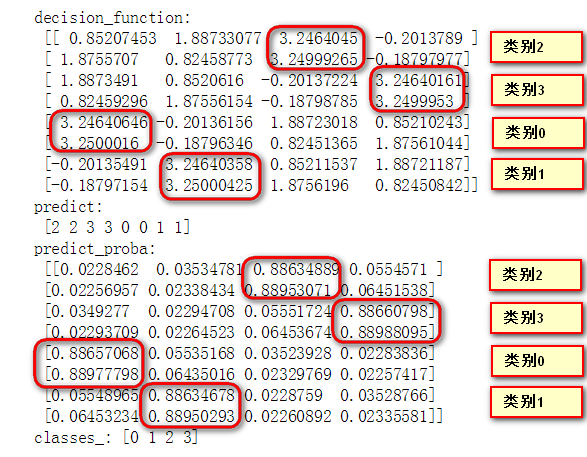
在ovr场景下,decision_function输出的最大值对应的正样本类别就是decision_function认为置信度最高的预测类别。下面看一下One-vs-One场景下的多分类。
One-vs-One多分类实例:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
X = np.array(
[
[-1, -1],
[-2, -1],
[1, 1],
[2, 1],
[-1, 1],
[-1, 2],
[1, -1],
[1, -2]
]
)
y = np.array([2, 2, 3, 3, 0, 0, 1, 1])
# SVC多分类模型默认采用ovr模式
clf = SVC(probability=True, decision_function_shape="ovo")
clf.fit(X, y)
# 计算样本距离每个分类边界的距离
# One-vs-One 按照decision_function的得分[01, 02, 03, 12, 13, 23]判断每个分类器的分类结果,然后进行投票
# One-vs-Rest 选择decision_function的得分[0-Rest, 1-Rest, 2-Rest, 3-Rest]最大的作为分类结果
print("decision_function:\n", clf.decision_function(X))
# precidt预测样本对应的标签类别
print("predict:\n", clf.predict(X))
# predict_proba 预测样本对应各个类别的概率
print("predict_proba:\n", clf.predict_proba(X)) #这个是得分,每个分类器的得分,取最大得分对应的类。
print("classes_:", clf.classes_)模型在训练集上的decision_function以及predict_procaba、predict结果如下:
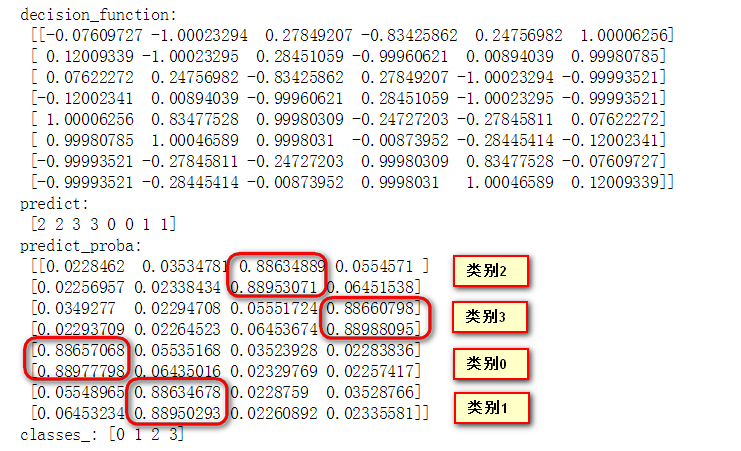
ovo模式下,4个类别的训练数据,需要训练6个二分类器,得到6个decition_function值,依照classes_的类别顺序,6个二分类器分别是[01, 02, 03, 12, 13, 23],前面的数字表示正类,后面的表示负类。以decision_function的第一行输出结果为例:
-0.07609727 对应 01分类器,且数值小于0,则分类结果为后者,即类别1
-1.00023294 对应 02分类器,且数值小于0,则分类结果为后者,即类别2
0.27849207 对应 03分类器,且数值大于0,则分类结果为前者,即类别0
-0.834258626 对应 12分类器,且数值小于0,则分类结果为后者,即类别2
0.24756982 对应 13分类器,且数值大于0,则分类结果为前者,即类别1
1.00006256 对应 23分类器,且数值大于0,则分类结果为前者,即类别2
最终得票数:{类别0: 1, 类别1: 2, 类别2: 3, 类别3: 0}
对以上分类结果voting投票,多数获胜,即最终分类结果为类别2。通过上面讲的这些大概也能得出decision_function、predict_procaba、predict之间的联系了:
decision_function:输出样本距离各个分类器的分隔超平面的置信度,并由此可以推算出predict的预测结果
predict_procaba:输出样本属于各个类别的概率值,并由此可以推算出predict的预测结果
predict:输出样本属于具体类别的预测结果
怎么用?
说了这么多,也知道decision_function的具体含义了,那么使用decison_function可以干什么呢?(没用说个毛线)
还是以SVM分类器为例,SVM分类器有个参数用来控制是否输出预测样本的概率值,probability=True时SVM分类器具有predict_proba函数,可以输出样本的预测概率,但是当probability=False,SVM分类器没有predict_proba函数,也就没办法得到样本预测结果的置信度(简单理解为概率)。但是我们又知道,当我们想要计算分类器的性能时,常常需要用到ROC和AUC,ROC曲线表示分类器预测结果FPR和TPR的变化趋势,AUC表示ROC曲线以下的面积。也就是说,要想得到ROC和AUC,就需要得到一组FPR和TPR,FPR和TPR的计算通常是基于一组样本的预测置信度,分别选择不同的置信度阈值,得到一组FPR和TPR值,然后得到ROC曲线的。现在没有predict_proba就得不到样本预测的置信度。But,还记得我们前面解释decison_function时说过的,decision_function表示通过度量样本距离分隔超平面距离的来表示置信度。那么我们是不是可以使用decision_function的置信度来计算ROC呢?答案当然是可以的啦。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import roc_curve, roc_auc_score, auc, plot_roc_curve
from sklearn.multiclass import OneVsOneClassifier, OneVsRestClassifier
from sklearn.preprocessing import label_binarize
from sklearn import datasets
from sklearn.model_selection import train_test_split
np.random.seed(100)
# 加载iris数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
print(X.shape, y.shape)
n_samples, n_features = X.shape
# iris数据集加入噪声,使得ROC不是那么完美
X = np.c_[X, np.random.randn(n_samples, 50 * n_features)]
# y = label_binarize(y, classes=[0, 1, 2])
# n_classes = y.shape[1]
# 训练样本的类别数量
n_classes = 3
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5, random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# 使用One-vs-Rest模式训练SVM分类器
clf = OneVsRestClassifier(SVC(kernel="linear"))
clf.fit(X_train, y_train)
# 计算分类器在测试集上的决策值
y_scores = clf.decision_function(X_test)
print(y_scores.shape)
# 绘制每个类别的ROC曲线
fig, axes = plt.subplots(2, 2, figsize=(8, 8))
colors = ["r", "g", "b", "k"]
markers = ["o", "^", "v", "+"]
y_test = label_binarize(y_test, classes=clf.classes_)
for i in range(n_classes):
# 计算每个类别的FPR, TPR
fpr, tpr, thr = roc_curve(y_test[:, i], y_scores[:, i])
# print("classes_{}, fpr: {}, tpr: {}, threshold: {}".format(i, fpr, tpr, thr))
# 绘制ROC曲线,并计算AUC值
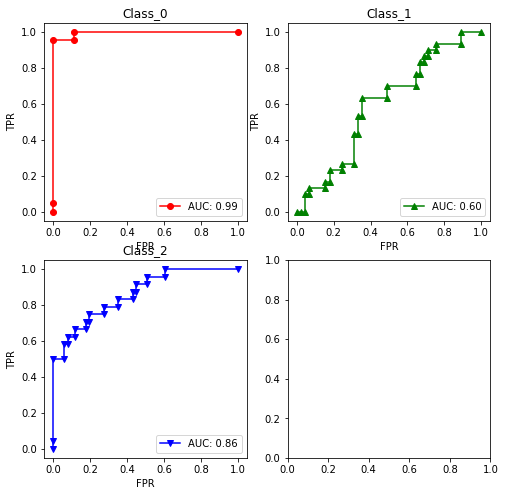
axes[int(i / 2), i % 2].plot(fpr, tpr, color=colors[i], marker=markers[i], label="AUC: {:.2f}".format(auc(fpr, tpr)))
axes[int(i / 2), i % 2].set_xlabel("FPR")
axes[int(i / 2), i % 2].set_ylabel("TPR")
axes[int(i / 2), i % 2].set_title("Class_{}".format(clf.classes_[i]))
axes[int(i / 2), i % 2].legend(loc="lower right")
print("AUC:", roc_auc_score(y_test, clf.decision_function(X_test), multi_class="ovr", average=None))输出结果如下:AUC: [0.99470899 0.5962963 0.8619281 ]
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185418.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
