大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、安装:
Kali下:
git clone https://github.com/maurosoria/dirsearch
cd dirsearch/
Windows下:
GitHub的下载地址为:https://github.com/maurosoria/dirsearch
其中,db文件夹为自带字典文件夹;reports为扫描日志文件夹;dirsearch.py为主程序文件 ;安装完成后将目录地址改为主程序解压地址,使用管理员cmd启动dirsearch。
注:dirsearch程序必须使用python3以上才能运行
二、使用
使用python.exe dirsearch.py -h可以查看到各种命令
以我的192.168.52.143环境为例:
常用:python.exe dirsearch.py -u http://192.168.52.143/ -e *
-u:url
-e:-e EXTENSIONS, –extensions=EXTENSIONS。扩展名列表用逗号隔开(例如:php,asp)
其他:-l =urllist.txt(里面存放着所有需要扫描的目录)
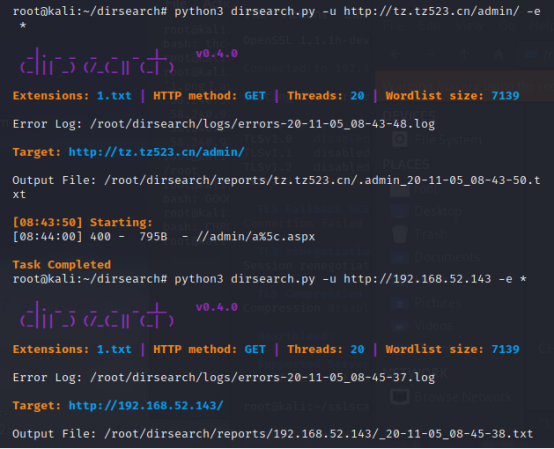

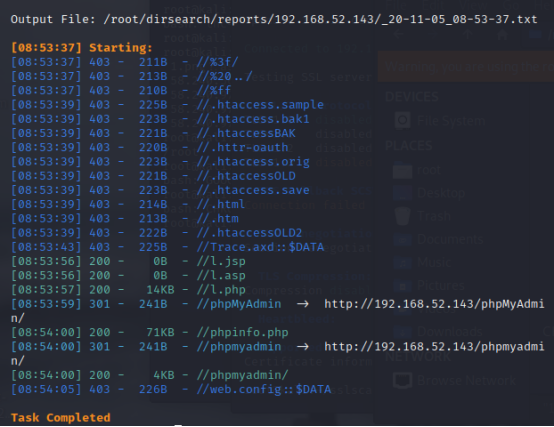
python3 dirsearch.py -u http://192.168.52.143 -e * -w /root/dirsearch/db/dicc.txt
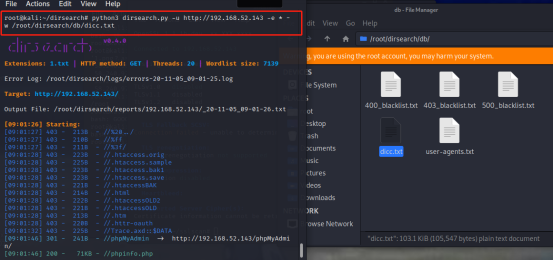
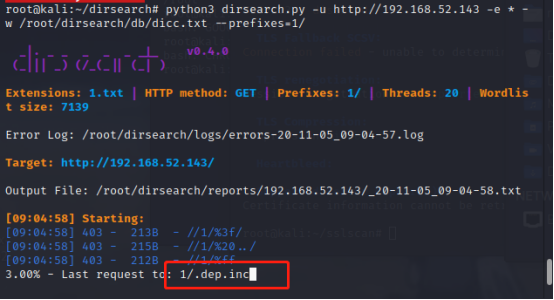
python3 dirsearch.py -u http://192.168.52.143 -e * -w /root/dirsearch/db/dicc.txt –prefixes=1/
python3 dirsearch.py -u http://192.168.52.143 -e * -w /root/dirsearch/db/dicc.txt –prefixes=2222 -f %a% –no-dot-extensions -U
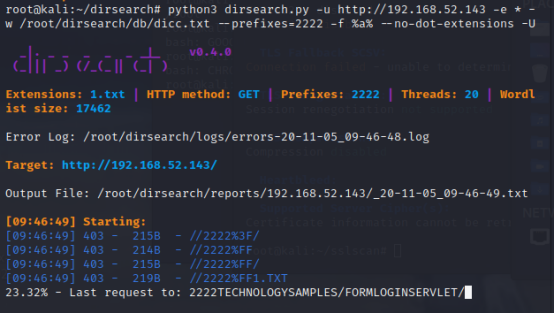
python3 dirsearch.py -u http://192.168.52.143 -e * -w /root/dirsearch/db/dicc.txt -r –suppress-empty -i 200 –full-url
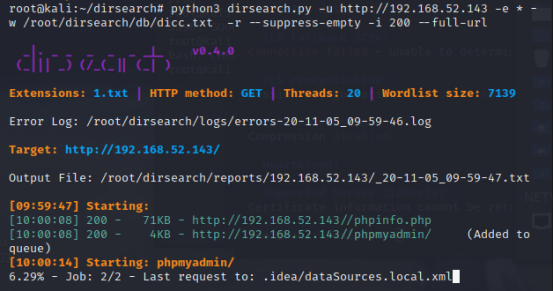
将检查结果以xml形式存放(其他存放形式json等)
python3 dirsearch.py -u http://192.168.52.143 -e * -i 200 –full-url –xml-report=1.xml
python.exe dirsearch.py -h 如下所示:
|
Usage: dirsearch.py [-u|–url] target [-e|–extensions] extensions [options]
Options: -h, –help 显示此帮助消息并退出
Mandatory:强制的 -u URL, –url=URL URL目标 -l URLLIST, –url-list=URLLIST URL列表文件 -e EXTENSIONS, –extensions=EXTENSIONS 以逗号分隔的扩展列表(示例:php,asp) -E, –extensions-list 使用公共扩展的预定义列表 -X EXCLUDEEXTENSIONS, –exclude-extensions=EXCLUDEEXTENSIONS 排除用逗号分隔的扩展名列表(示例:asp,jsp)
Dictionary Settings: 词典设置 -w WORDLIST, –wordlist=WORDLIST 自定义单词表(用逗号分隔) –prefixes=PREFIXES 为所有条目添加自定义前缀(用逗号分隔) –suffixes=SUFFIXES 为所有条目添加自定义后缀,忽略目录(用逗号分隔) -f, –force-extensions 强制扩展每个词列表项。将%NOFORCE%添加到您不想强制执行的单词列表项的末尾 –no-extension 删除所有单词表项中的扩展名(示例:admin.php->admin) –no-dot-extensions 删除扩展名之前的“.”字符 -C, –capitalization 标准化 -U, –uppercase 大写单词表 -L, –lowercase 小写单词表
General Settings: 常规设置 -d DATA, –data=DATA HTTP请求数据 -r, –recursive 递归爆破目录 -R RECURSIVE_LEVEL_MAX, –recursive-level-max=RECURSIVE_LEVEL_MAX 最大递归级别(子目录)(默认值:0[无限]) –suppress-empty 禁止空响应 –minimal=MINIMUMRESPONSESIZE 响应时间最短 –maximal=MAXIMUMRESPONSESIZE 最大响应长度 –scan-subdirs=SCANSUBDIRS 扫描给定URL的子目录(以逗号分隔) –exclude-subdirs=EXCLUDESUBDIRS 递归扫描期间排除以下子目录(以逗号分隔) -t THREADSCOUNT, –threads=THREADSCOUNT 线程数 -i INCLUDESTATUSCODES, –include-status=INCLUDESTATUSCODES 仅显示包含的状态码,以逗号分隔 (例如:301、500) -x EXCLUDESTATUSCODES, –exclude-status=EXCLUDESTATUSCODES 不显示排除的状态代码,以逗号分隔(例如:301、500) –exclude-sizes=EXCLUDESIZES 按大小排除响应,以逗号分隔(示例:123B,4KB) –exclude-texts=EXCLUDETEXTS 排除文字回应,并以逗号分隔(例如:“未找到”,“错误”) –exclude-regexps=EXCLUDEREGEXPS 用正则表达式排除响应,并用逗号分隔(例如:“未找到[a-z] {1}”,“ ^ Error $”) -H HEADERS, –header=HEADERS HTTP request header, support multiple flags (Example: -H “Referer: example.com” -H “Accept: */*”) HTTP请求标头,支持多个标志(例如:-H“引用者:example.com” -H“接受:* / *”) –header-list=HEADERLIST File contains HTTP request headers 文件包含HTTP请求标头 –user-agent=USERAGENT –random-agent, –random-user-agent –cookie=COOKIE -F, –follow-redirects –full-url 在输出中打印完整的URL -q, –quiet-mode
Connection Settings: –timeout=TIMEOUT 连接超时 –ip=IP 服务器IP地址 -s DELAY, –delay=DELAY 请求之间的延迟(支持浮动数字) –proxy=HTTPPROXY Proxy URL, support HTTP and SOCKS proxy (Example: localhost:8080, socks5://localhost:8088) 代理URL,支持HTTP和SOCKS代理(示例:localhost:8080,socks5://localhost:8088) –proxy-list=PROXYLIST 文件包含代理服务器 -m HTTPMETHOD, –http-method=HTTPMETHOD HTTP方法,默认值:GET –max-retries=MAXRETRIES -b, –request-by-hostname By default dirsearch will request by IP for speed. This will force requests by hostname 默认情况下,dirsearch将通过IP请求速度。这将强制按主机名请求 –stop-on-error 发生错误时停止
Reports: 报告 –simple-report=SIMPLEOUTPUTFILE 只找到路径 –plain-text-report=PLAINTEXTOUTPUTFILE 找到带有状态代码的路径 –json-report=JSONOUTPUTFILE –xml-report=XMLOUTPUTFILE
You can change the dirsearch default configurations (default extensions, timeout, wordlist location, …) by editing the “default.conf” file. More information at https://github.com/maurosoria/dirsearch. |
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185414.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
