大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
最近面临这样的场景:
2亿+数据需要调用后端服务A,业务需要1min处理完成,那么A服务承载的tps达到惊人的300w……必须想办法降低tps。
那么方案来了:1、把时间窗口拉长 2、降低待处理数据量。
拉长时间业务肯定是接受不了的,但是按照以往的经验,这部分数据并不全部需要处理,可能仅有一半真正需要调用A服务,所以我们可以把1亿数据给过滤掉。
这里我们维护一个布隆过滤器来进行数据的过滤。
1. 布隆过滤器的概念(百科)
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
2. 布隆过滤器应用场景
deny list
数据判重
预过滤
3. 原理
核心是一个长度为m的bit array和k个hash方法。
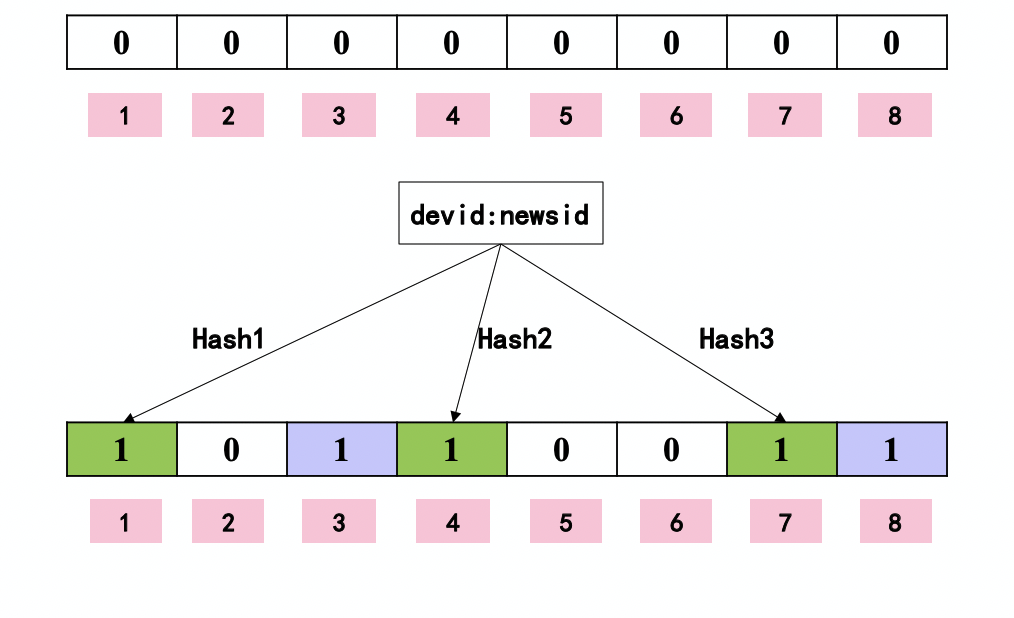
如下图,我们将一个newsid通过3个hash方法映射到长为8的数组上。
判断newsid是否存在,则看数组中3个位置是否都取到1:全为1,newsid可能存在于集合中;不全为1,newsid一定不存在于集合中。

4. 特性
容易发现,布隆过滤器存在假阳性的情况,即将不在集合中的元素误判为在集合中。过滤器中的元素个数越多,假阳性的可能性越大。
同时,元素可以被加入过滤器,但很难从过滤器中删除(有可能删除的当前元素与其他元素共享了某一个bit,造成假阴性)。
根据假阳性率计算公式:
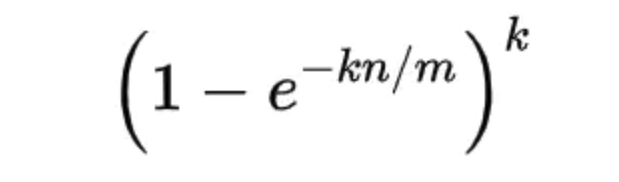
可知在哈希函数的个数k一定的情况下:
- 位数组长度m越大,假阳性率越低;
- 已插入元素的个数n越大,假阳性率越高。
5. 上代码
// CalBloomSize 计算布隆过滤器位图大小
// elemNum 元素个数
// errorRate 误判率
func CalBloomSize(elemNum uint64, errRate float64) uint64 {
var bloomBitsSize = float64(elemNum) * math.Log(errRate) / (math.Log(2) * math.Log(2)) * (-1)
return uint64(math.Ceil(bloomBitsSize))
}
// CalHashFuncNum 计算需要的哈希函数数量
// elemNum 元素个数
// bloomSize 布隆过滤器位图大小
func CalHashFuncNum(elemNum, bloomSize uint64) uint64 {
var k = math.Log(2) * float64(bloomSize) / float64(elemNum)
return uint64(math.Ceil(k))
}
// Filter
type Filter struct {
ElemNum uint64
BloomSize uint64
HashFuncNum uint64
ErrRate float64
bitMap *bitset.BitSet
keys map[uint32]bool
}
// NewFilter NewFilter
func NewFilter(elemNum, bloomSize, hashFuncNum uint64, errRate float64) *Filter {
return &Filter{ElemNum: elemNum, BloomSize: bloomSize, HashFuncNum: hashFuncNum, ErrRate: errRate}
}
// Init 初始化布隆过滤器
func (f *Filter) Init() {
// 分配布隆过滤器位图
f.bitMap = bitset.New(uint(f.BloomSize))
// 初始化哈希函数
// 是否是类似HMAC-SHA256那种通过改变passphase值形成不同的哈希函数
f.keys = make(map[uint32]bool)
for uint64(len(f.keys)) < f.HashFuncNum {
randNum, err := rand.Int(rand.Reader, new(big.Int).SetUint64(math.MaxUint32))
if err != nil {
panic(err)
}
f.keys[uint32(randNum.Uint64())] = true
}
}
// Add Add
func (f *Filter) Add(elem []byte) {
var buf [4]byte
for k := range f.keys {
binary.LittleEndian.PutUint32(buf[:], k)
hashResult := new(big.Int).SetBytes(HMACWithSHA128(elem, buf[:]))
result := hashResult.Mod(hashResult, big.NewInt(int64(f.BloomSize)))
// 把result对应的bit置1
f.bitMap.Set(uint(result.Uint64()))
}
}
// IsContain 判断元素是否在集合里面
func (f *Filter) IsContain(elem []byte) bool {
var buf [4]byte
for k := range f.keys {
binary.LittleEndian.PutUint32(buf[:], k)
hashResult := new(big.Int).SetBytes(HMACWithSHA128(elem, buf[:]))
result := hashResult.Mod(hashResult, big.NewInt(int64(f.BloomSize)))
// 查询result对应的bit是否被置1
if !f.bitMap.Test(uint(result.Uint64())) {
return false
}
}
return true
}
// HMACWithSHA128 通过加盐生成不同的hash值
func HMACWithSHA128(seed []byte, key []byte) []byte {
hmac512 := hmac.New(sha1.New, key)
hmac512.Write(seed)
return hmac512.Sum(nil)
}测试:2亿长16B的元素,失误率0.0001,分配到过滤器需要0.4G,如果放hash表,则需要3.2G
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185284.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
