大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
hash原理
。
一个应用是Hash table(散列表,也叫哈希表),是根据哈希值 (Key value) 而直接进行访问的数据结构。也就是说,它通过把哈希值映射到表中一个位置来访问记录,以加快查找的速度。下面是一个典型的 hash 函数 / 表示意图:

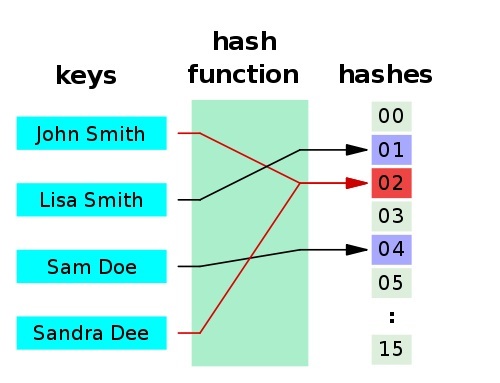
哈希函数有以下两个特点:
- 如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
- 散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的。但也可能不同,这种情况称为 “散列碰撞”(或者 “散列冲突”)。
缺点: 引用吴军博士的《数学之美》中所言,哈希表的空间效率还是不够高。如果用哈希表存储一亿个垃圾邮件地址,每个email地址 对应 8bytes, 而哈希表的存储效率一般只有50%,因此一个email地址需要占用16bytes. 因此一亿个email地址占用1.6GB,如果存储几十亿个email address则需要上百GB的内存。除非是超级计算机,一般的服务器是无法存储的。
所以要引入下面的 Bloom Filter。
布隆过滤器原理
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢。
Bloom Filter 是一种空间效率很高的随机数据结构,Bloom filter 可以看做是对 bit-map 的扩展, 它的原理是:
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:
- 如果这些点有任何一个 0,则被检索元素一定不在;
- 如果都是 1,则被检索元素很可能在。
布隆过滤器优点
它的优点是
空间效率
和
查询时间
都远远超过一般的算法,布隆过滤器存储空间和插入 / 查询时间都是常数
O(k)
。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器缺点
误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
(误判补救方法是:再建立一个小的白名单,存储那些可能被误判的信息。)
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加 1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。(google guava实现的布隆过滤器里面就没有包含删除元素)
google guava实现的布隆过滤器简单使用
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>package com.tlk.guava;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.UUID;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* google guava 布隆过滤器的使用
*
* @author tanlk 2017年10月24日 下午11:44:16
*/
public class BloomFilterTest {
private static final int insertions = 1000000;// 100万
public static void main(String[] args) {
// 初始化一个存储string数据的布隆过滤器,默认fpp(误差率) 0.03
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), insertions);
Set<String> set = new HashSet<String>(insertions);
List<String> list = new ArrayList<String>(insertions);
for (int i = 0; i < insertions; i++) {
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
set.add(uuid);
list.add(uuid);
}
int wrong = 0; // 布隆过滤器误判的次数
int right = 0;// 布隆过滤器正确次数
for (int i = 0; i < 10000; i++) {
String str = i % 100 == 0 ? list.get(i / 100) : UUID.randomUUID().toString();
if (bf.mightContain(str)) {
if (set.contains(str)) {
right++;
} else {
wrong++;
}
}
}
//right 为100
System.out.println("right:" + right);
//因为误差率为3%,所以一万条数据wrong的值在300左右
System.out.println("wrong:" + wrong);
}
}布隆过滤器的应用场景
1.Google著名的分布式数据库Bigtable以及Hbase使用了布隆过滤器来查找不存在的行或列,以减少磁盘查找的IO次数。
2.检查垃圾邮件地址
假定我们存储一亿个电子邮件地址,我们先建立一个十六亿二进制(比特),即两亿字节的向量,然后将这十六亿个二进制全部设置为零。对于每一个电子邮件地址 X,我们用八个不同的随机数产生器(F1,F2, ...,F8) 产生八个信息指纹(f1, f2, ..., f8)。再用一个随机数产生器 G 把这八个信息指纹映射到 1 到十六亿中的八个自然数 g1, g2, ...,g8。现在我们把这八个位置的二进制全部设置为一。当我们对这一亿个 email 地址都进行这样的处理后。一个针对这些 email 地址的布隆过滤器就建成了。
3.Google chrome 浏览器使用bloom filter识别恶意链接(能够用较少的存储空间表示较大的数据集合,简单的想就是把每一个URL都可以映射成为一个bit)
4.文档存储检索系统也采用布隆过滤器来检测先前存储的数据
5.爬虫URL地址去重
A,B 两个文件,各存放 50 亿条 URL,每条 URL 占用 64 字节,内存限制是 4G,让你找出 A,B 文件共同的 URL。如果是三个乃至 n 个文件呢?
分析 :如果允许有一定的错误率,可以使用 Bloom filter,4G 内存大概可以表示 340 亿 bit。将其中一个文件中的 url 使用 Bloom filter 映射为这 340 亿 bit,然后挨个读取另外一个文件的 url,检查是否与 Bloom filter,如果是,那么该 url 应该是共同的 url(注意会有一定的错误率)。
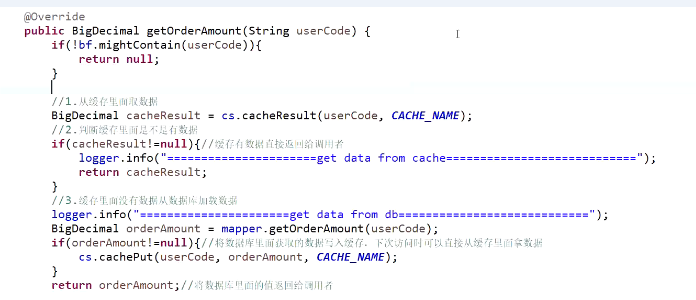
6.解决缓存穿透问题
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
伪代码如下:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185220.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
