大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1.什么是布隆过滤器
布隆过滤器是一个叫“布隆”的人提出的,本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure)。它本身是一个很长的二进制向量,特点是高效地插入和查询,可以用来确定 “某一条数据一定不存在或者可能存在一个集合中”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少(因为是个二进制的向量),但是缺点是其返回的结果是概率性的,而不是确切的。
2.布隆过滤器数据结构
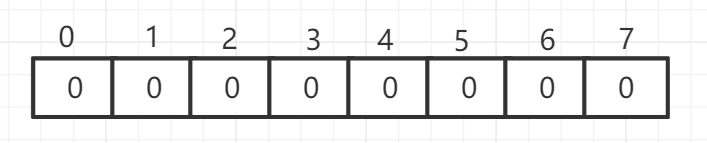
布隆过滤器是一个 bit 向量或者说 bit 数组,长度为8的布隆过滤器,默认值都是0,就像下面这样:

如果我们要映射一个值到布隆过滤器中,需要使用多个不同的哈希函数生成多个哈希值,并将bit向量里位置 等于哈希值的元素设置为1。例如针对值 userId=10的数据 进行三个不同的哈希函数分别生成了哈希值 1、4、7,则布隆过滤器转变为:

我们现在再存一个值 userId=18的数据,如果三次哈希函数返回0、 4、6 的话,布隆过滤器图继续变为:
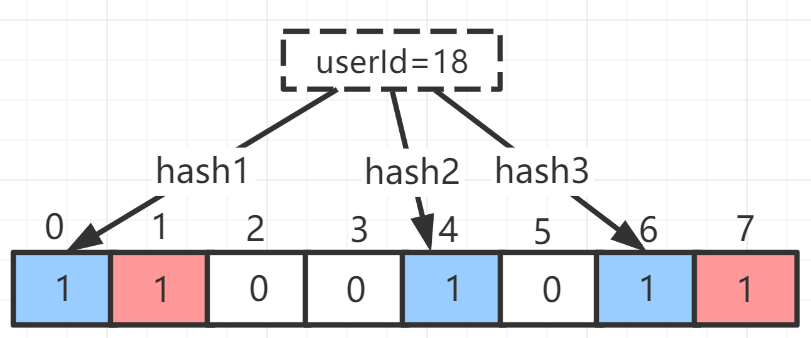
需要注意的是:bit向量index=4位置由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在如果想查询 userId=20 这个数据在布隆过滤器中是否存在,三次哈希函数返回了 1、5、7三个值,结果发现 bit向量index=4位置的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说userId=20 这个数据不存在布隆过滤器中。
而当查询 userId=10 这个数据是否存在的话,那么三次哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么可以说 userId=10 这个数据在布隆过滤器中存在了么?答案是不一定,只能是 userId=10 这个值可能存在。为什么是这样呢?因为随着增加的数据越来越多,被置为 1 的 bit 位也会越来越多,比如某个userId=1的数据即使没有被存储过,但是万一三次哈希后返回的三个 bit 位都被其它值置位了 1 ,那么还是不能判断 userId=1 这个值在布隆过滤器中存在。
所以得出了布隆过滤器的结论:可以用来确定某一条数据一定不存在 或 者可能存在于一个集合中,不能判断一定存在。
3.如何选择哈希个数和长度
知道了Bloom Filter的原理后,那么如何选择哈希函数个数 和 布隆过滤器长度呢?很显然,布隆过滤器长度过小,所有的 bit 位很快就均为 1了,那么查询任何值都会返回“可能存在”,起不到过滤的目的。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 所有 bit 位被置1的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
先来看网上的一张统计的图:k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
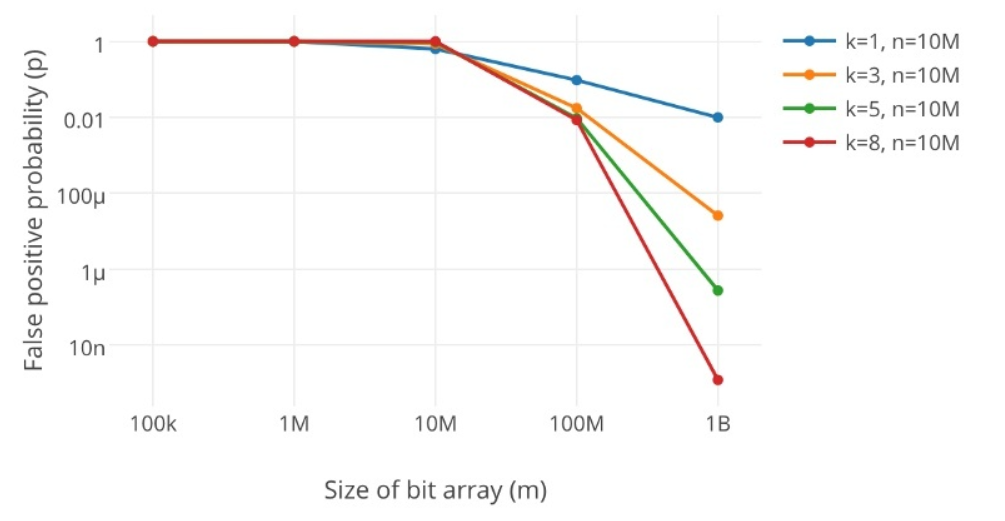
从上图的统计结果,可以得出几个结论:
-
(1)当布隆过滤器长度m 、插入的元素个数n一定时,哈希函数个数k越小,隆过滤器误报率p就越大。
-
(2)当布隆过滤器哈希函数个数k、插入的元素个数n一定时,布隆过滤器长度m越小,隆过滤器误报率p就越大。
那么如何选择适合业务的 k 和 m 值呢,这里有一个公式:
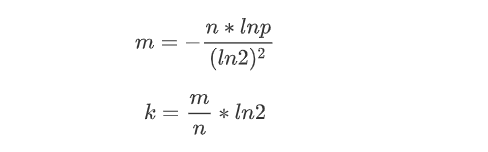
k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。一般可以根据自己的业务场景确认出插入元素个数n 和 误报率p。关于公式是如何推导出来的,网上很多大家自行百度一下。
4.最佳实践
(1)应用场景
-
(1)黑名单:比如邮件黑名单过滤器,判断邮件地址是否在黑名单中、内网系统用IP黑白名单防止网络爬虫等。
-
(2)防止Redis缓存击穿。
(2)布隆过滤器实现
1)guava布隆过滤器
布隆过滤器实现难点的在于如何设计随机映射函数、到底进行几次hash映射,二进制向量的长度设置为多少比较好,这些开发起来都比较困难,好在Google大佬在guava已经为我们封装了布隆过滤器实现。
maven坐标
<!--guava:布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>实现代码
public class BloomFilterObj {
//预计要插入元素个数
private static int size = 1000000;
//期望的误判率
private static double fpp = 0.01;
//布隆过滤器
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
HashMap
//插入数据
for (int i = 0; i < 1000000; i++) {
bloomFilter.put(i);
}
int count = 0;
for (int i = 1000000; i < 3000000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "误判了");
}
}
System.out.println("总共的误判数:" + count);
}
}上面实例执行结果:
//最后几行输出
2999753误判了
2999838误判了
2999923误判了
2999928误判了
总共的误判数:20339guava实现布隆过滤器存在一个问题:数据是存放在本地内存中,分布式系统中无法实现布隆过滤器的共享。那怎么解决这个问题呢?可以redis来实现分布式系统的布隆过滤器。
2)分布式布隆过滤器实现
用redis来实现布隆过滤器,需要我们自己根据插入元素个数n 和 误判率p来计算出bloom filter的长度m、哈希函数个数k,无疑是一个艰辛的任务,但是我们可以参考guava中的实现。guava中布隆过滤器取hash运算运算时,为了达到更离散目的,实现原理 和 HashMap的取hash运算有点类似,都是用到高位和低位运算。
/**
* @author: feiwang_6
* @create: 2020/6/4 22:14
* @description: Redis实现布隆过滤器
*/
public class RedisBloomFilter {
//预计插入的元素个数
static final int expectedInsertions = 1000;
//期望的误判率
static final double fpp = 0.01;
//bit数组长度
private static long bitSize;
//hash函数数量
private static int numHashFunctions;
static {
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public static void main(String[] args) {
//初始化Redis布隆过滤器
Jedis jedis = new Jedis("localhost", 6379);
for (int i = 0; i < 1000; i++) {
long[] indexArray = getIndexArray(String.valueOf(i));
for (long index : indexArray) {
jedis.setbit("bloom_key_name", index, true);
}
}
//测试布隆过滤器的误报率
int num = 0;
for (int i = 1000; i <= 2000; i++) {
long[] indexArray = getIndexArray(String.valueOf(i));
for (long index : indexArray) {
if (!jedis.getbit("bloom_key_name", index)) {
System.out.println(i + " 一定不存在");
num++;
break;
}
}
}
System.out.println("一定不存在的有 " + num + " 个");
}
/**
* 根据key获取布隆过滤器bitmap下标
* (guava的布隆过滤器实现源码)
*/
private static long[] getIndexArray(String key) {
//低32位
long hash1 = (int)hash(key);
//高32位
long hash2 = (int)(hash1 >>> 32);
long[] result = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
long combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = ~combinedHash;
}
result[i] = combinedHash % bitSize;
}
return result;
}
/**
* hash计算
* @param key
* @return
*/
private static long hash(String key) {
return Hashing.murmur3_128().hashBytes(key.getBytes()).asLong();
}
/**
* 计算hash函数个数
* 根据上面公式hash函数个数k = (m / n) * log(2),需要考虑到避免因除法而截断小数部分
* (guava的布隆过滤器实现源码)
* @param n
* @param m
* @return
*/
private static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
/**
* 根据上面公式计算布隆过滤器bit数组长度m
* (guava的布隆过滤器实现源码)
* @param n
* @param p
* @return
*/
private static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}上面实例执行结果:
//最后几行运行结果:
1997 一定不存在
1998 一定不存在
1999 一定不存在
2000 一定不存在
一定不存在的有988个说明:在分布式系统中使用redis,一般都是和spring集成使用,由于本地没有redis集群环境,就写了一个单机手动连接测试用例,没有真正实现分布式,但这里主要讲解的是实现思路,大同小异。
最后抛一个问题:在分布式系统中,使用redis的bit来实现bloom filter时,每次请求都会去读redis,当并发量大时每次都去读严重影响性能,那么怎么进行优化?
总结:
- (1)不同的数据结构有不同的适用场景和优缺点,需要自己仔细权衡业务需求之后妥善适用它们,布隆过滤器就是这样。
- (2)使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,大神们推荐 MurmurHash、KetamaHash、Fnv 。
- (3)分布式服务中使用布隆过滤器时,一定要给自己预留一个初始化的接口,比如swagger接口等,在后端系统上线后先初始化布隆过滤器。
2020年06月04日 晚 于北京记
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185190.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
