大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
https://www.cnblogs.com/qdhxhz/p/11237246.html
开发一个电商项目,因为数据量一直在增加(已达亿级),所以需要重构之前开发好的秒杀功能,为了更好的支持高并发,在验证用户是否重复购买的环节,就考虑用布隆过滤器。
也顺便更加深入的去了解下布隆过滤器的原理,感觉还是蛮有意思的,这一连串的公式不静下心来思考,很容易被绕晕。
一、概述
1、什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构,特点是高效地插入和查询。根据查询结果可以用来告诉你 某样东西一定不存在或者可能存在 这句话是该算法的核心。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的,同时布隆过滤器还有一个缺陷就是
数据只能插入不能删除。
2、数据如何存入布隆过滤器
布隆过滤器是由一个很长的bit数组和一系列哈希函数组成的。
数组的每个元素都只占1bit空间,并且每个元素只能为0或1。
布隆过滤器还拥有k个哈希函数,当一个元素加入布隆过滤器时,会使用k个哈希函数对其进行k次计算,得到k个哈希值,并且根据得到的哈希值,在维数组中把对应下标的值置位1。
判断某个数是否在布隆过滤器中,就对该元素进行k次哈希计算,得到的值在位数组中判断每个元素是否都为1,如果每个元素都为1,就说明这个值在布隆过滤器中。
3、布隆过滤器为什么会有误判
当插入的元素越来越多时,当一个不在布隆过滤器中的元素,经过同样规则的哈希计算之后,得到的值在位数组中查询,有可能这些位置因为其他的元素先被置1了。
所以布隆过滤器存在误判的情况,但是如果布隆过滤器判断某个元素不在布隆过滤器中,那么这个值就一定不在。
如果对布隆过滤器的概念还不是很理解的话,推荐一篇博客,图文并茂好理解很多。详解布隆过滤器的原理、使用场景和注意事项
4、使用场景
- 网页爬虫对URL的去重,避免爬去相同的URL地址。
- 垃圾邮件过滤,从数十亿个垃圾邮件列表中判断某邮箱是否是杀垃圾邮箱。
- 解决数据库缓存击穿,黑客攻击服务器时,会构建大量不存在于缓存中的key向服务器发起请求,在数据量足够大的时候,频繁的数据库查询会导致挂机。
- 秒杀系统,查看用户是否重复购买。
二、实际应用场景
背景 现在有个100亿个黑名单网页数据,每个网页的URL占用64字节。现在想要实现一种网页过滤系统,可以根据网页的URL判断该网站是否在黑名单上,请设计该系统。
需求可以允许有0.01%以下的判断失误率,并且使用的总空间不要超过200G。
这里一共有4个常量:
100亿条黑名单数据,每条数据占64个字节,万分之一的失误率,总空间不要超过200G。
如果不考虑不拢过滤器,那么这里存储100亿条数据就需要 100亿 * 64字节 = 596G 显然超过300G
解题 在满足有 100亿条数据 并且允许 万分之一的失误率 的布隆过滤器需要多大的bit数组呢?
- 设bit数组大小为m,样本数量为n,失误率为p。
- 由题可知 n = 100亿,p = 0.01%
布隆过滤器的大小m公式


求得 m = 19.19n,向上取整为 20n。所以2000亿bit,约为186G。
算完m,我们顺便来算下m,n已知,这时满足最小误差的k是几个。
哈希函数的个数k公式

求得 k = 14,即需要14个哈希函数。
通过通过 m = 20n, k = 14我们再来算下真实的失误率。
布隆过滤器真实失误率p公式

求得 p = 0.006%,即布隆过滤器的真实失误率为0.006%。
通过布隆过滤器公式也可以看出:
单个数据的大小不影响布隆过滤器大小,因为样本会通过哈希函数得到输出值。
就好比上面的 每个网页的URL占用64字节 这个数据大小 跟布隆过滤器大小没啥关系。
这三个公式就是有关布隆过滤器已经推倒出的公式,下面我们来推下这个公式是如何推导出来的。
三、公式推导
讲公式,应该先知道几个关键的常量。
误判率p、布隆过滤器长度m、元素个数n、哈希函数个数k
我们再来一步一步由简单到难推导公式。
1、误差率公式推导
前提条件:就是假设每个元素哈希得到的值分布到m数组上的每一个数组节点的概率是相等的。
1) 假设布隆过滤器长度为m,元素个数n为1,哈希函数个数k也为1。那么在插入时某一数组节点没有被置为1的概率。

这个应该很好理解。
2)如果上面其它不变,而哈希函数个数变成k个,那么在插入时某一数组节点没有被置为1的概率。

好理解!
3)如果元素个数变成n个,而哈希函数个数变成k个,那么在插入时某一数组节点没有被置为1的概率。

4)从上面推导出的是: 当布隆过滤器长度为m,元素个数变成n个,哈希函数个数变成k个的时候,某一节点被置为1的概率为

到这里应该也好理解,第三步是该位置从未被置为1,那么1去减去它就是至少有一次被置为1,那么只要存在一次被置1,那么该位置的bit标示就是1,因为布隆过滤器是不能删除的。
5)这个还需要考虑到,一个元素通过hash会生成多个k,放入m数组中,所以需要这k个值都为1才会认为该该元素已经存在。所以是这样的。

上面这个公式推导在转换下就成了
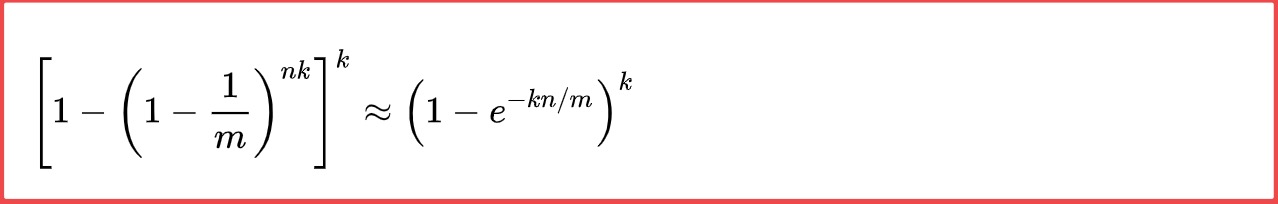
思考 为什么上面这个公式的值就是最终的误差率?
因为当一个布隆过滤器中不存在的元素进来的是的时候,首先通过hash算法产生k个哈希值,分布在m数组上都为1的的概率不就是上面推导出的这个公式吗,那不就是误差吗?
因为明明是不存在的值,却有这个概率表明已经存在。
思考 给定的m和n,思考k值为多少误差会最小。
为什么k值的大小不合理会影响误差呢?
我们来思考下,一个元素最终生成k个hash值,那么会在数组m上的k个位置标记为1。
假设k为1,那么每次进来只在m上的某一个位置标记为1,这样的话如果一个新元素进来刚好hash值也在这里,而不用其它位置来判断是否为1,这个误差就会比较大。
假设k为m,那么第一个元素进来,在m上所有位置上都表为1了 ,以后只要进来一个元素就会标记为已存在。这个误差也太大了。
上面只是举了两个极端的例子,但也说明k值太大、太小都不好,它的最优值一定跟m、n存在某种关系。
至于完整公式的推导,我这里就不在写了,后面会贴一个人家怎么推导的博客。
它们之间的关系只要记住下面这个公式就可以了。

这篇博客就到这里了,后面有整理通过谷歌的guava工具 和 redis 实现布隆过滤器的示例。通过Lua脚本批量插入数据到Redis布隆过滤器
参考
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/185122.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
