大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
本原创入门教程,涵盖ZooKeeper核心内容,通过实例和大量图表,结合实战,帮助学习者理解和运用,任何问题欢迎留言。
欢迎在我个人网站查看全集《ZooKeeper入门实战教程》
目录:
本章是后续学习的基石,只有充分理解了分布式系统的概念和面临的问题,以及ZooKeeper内部的概念,才能懂得ZooKeeper是如何对分布式系统进行协调,为后续学习打下坚实的基础。
1、ZooKeeper介绍与核心概念
1.1 简介
ZooKeeper最为主要的使用场景,是作为分布式系统的分布式协同服务。在学习zookeeper之前,先要对分布式系统的概念有所了解,否则你将完全不知道zookeeper在分布式系统中起到了什么作用,解决了什么问题。
1.2分布式系统面临的问题
我们将分布式系统定义为:分布式系统是同时跨越多个物理主机,独立运行的多个软件所组成系统。类比一下,分布式系统就是一群人一起干活。人多力量大,每个服务器的算力是有限的,但是通过分布式系统,由n个服务器组成起来的集群,算力是可以无限扩张的。
优点显而易见,人多干活快,并且互为备份。但是缺点也很明显。我们可以想象一下,以一个小研发团队开发软件为例,假设我们有一个5人的项目组,要开始一个系统的开发,项目组将面临如下问题:

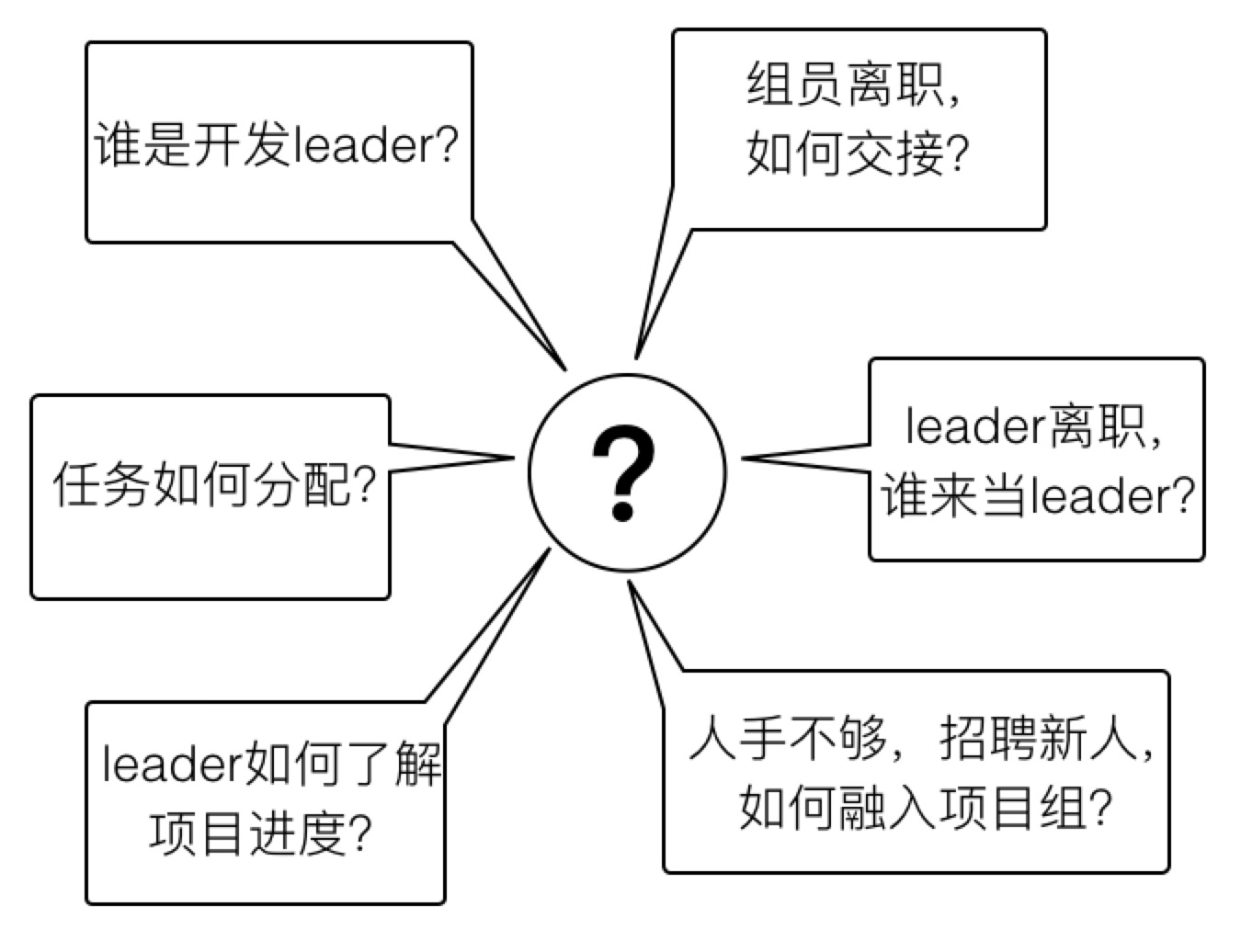
你一定在想,以上这些问题很简单啊,在我的日常工作中天天都在发生,并没感觉有什么复杂。是的,这是因为我们人类的大脑是个超级计算机,能够灵活应对这些问题,而且现实中信息的交换不依赖网络,不会因网络延迟或者中断,出现信息不对等。而且现实中对以上问题的处理其实并不严谨,从而也引发了很多问题。想一想,项目中是不是出现过沟通不畅造成任务分配有歧义?是否由于人员离职造成任务进行不下去,甚至要联系离职人员协助?是不是出现过任务分配不合理?类似这样的各种问题,肯定会发生于你的项目组中。在现实世界,我们可以人为去协调,即使出错了,人工去补错,加加班搞定就好。但在计算机的世界,这样做是行不通的,一切都要保证严谨,以上问题要做到尽可能不要发生。因此,分布式系统必须采用合理的方式解决掉以上的问题。
实际上要想解决这些问题并没有那么复杂,我们仅需要做一件事就可以万事无忧—让信息在项目组成员中同步。如果能做到信息同步,那么每个人在干什么,大家都是清楚的,干到什么程度也是清晰的,无论谁离职也不会产生问题。分配的工作,能够及时清晰的同步给每个组员,确保每个组员收到的任务分配没有冲突。
分布式系统的协调工作就是通过某种方式,让每个节点的信息能够同步和共享。这依赖于服务进程之间的通信。通信方式有两种:
1、通过网络进行信息共享
这就像现实世界,开发leader在会上把任务传达下去,组员通过听leader命令或者看leader的邮件知道自己要干什么。当任务分配有变化时,leader会单独告诉组员,或者再次召开会议。信息通过人与人之间的直接沟通,完成传递。
2、通过共享存储
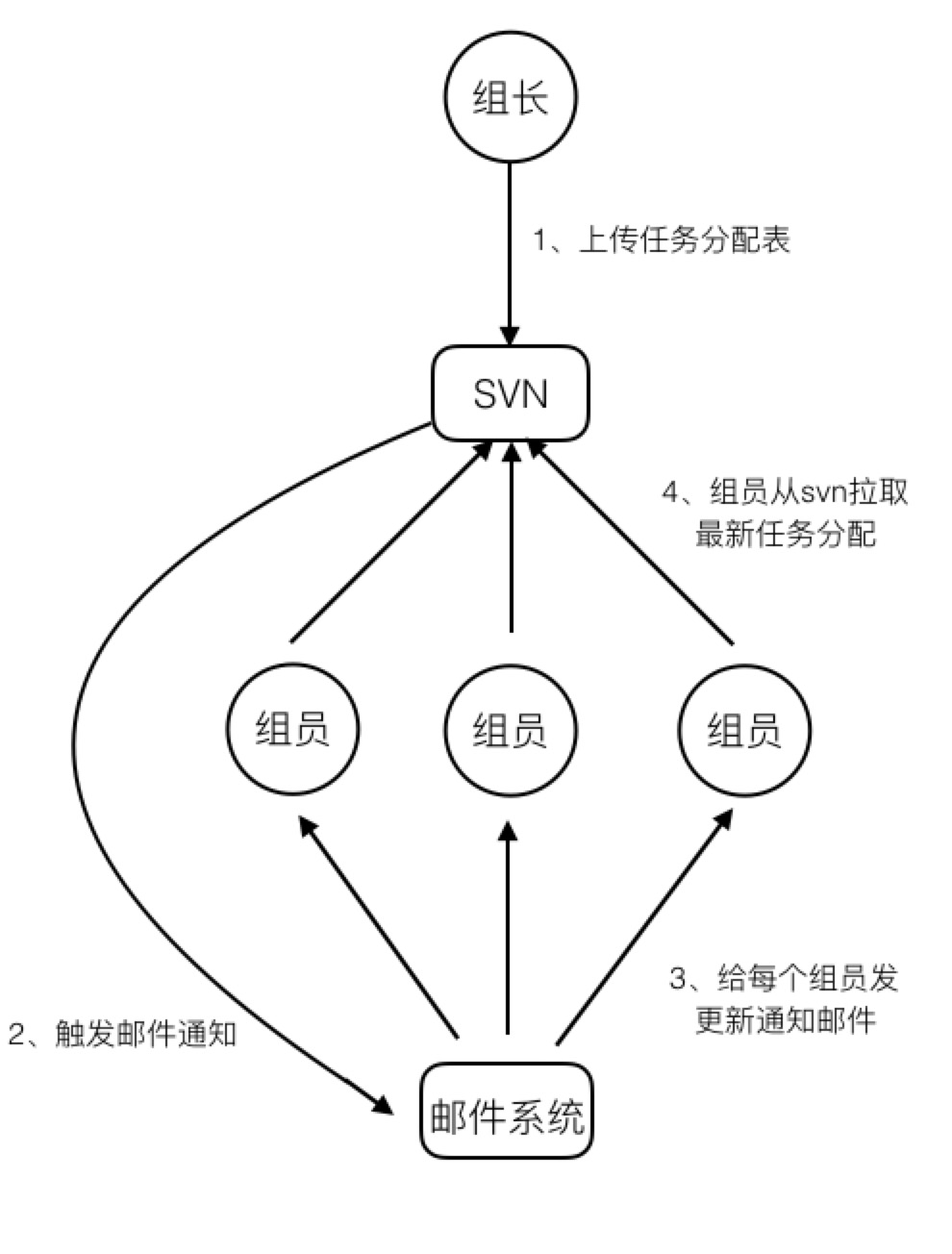
这就好比开发leader按照约定的时间和路径,把任务分配表放到了svn上,组员每天去svn上拉取最新的任务分配表,然后干活。其中svn就是共享存储。更好一点的做法是,当svn文件版本更新时,触发邮件通知,每个组员再去拉取最新的任务分配表。这样做更好,因为每次更新,组员都能第一时间得到消息,从而让自己手中的任务分配表永远是最新的。此种方式依赖于中央存储。整个过程如下图所示:
1.3 ZooKeeper如何解决分布式系统面临的问题
ZooKeeper对分布式系统的协调,使用的是第二种方式,共享存储。其实共享存储,分布式应用也需要和存储进行网络通信。网络通信是分布式系统并发设计的基础。
实际上,通过ZooKeeper实现分布式协同的原理,和项目组通过SVN同步工作任务的例子是一样的。ZooKeeper就像是svn,存储了任务的分配、完成情况等共享信息。每个分布式应用的节点就是组员,订阅这些共享信息。当主节点(组leader),对某个从节点的分工信息作出改变时,相关订阅的从节点得到zookeeper的通知,取得自己最新的任务分配。完成工作后,把完成情况存储到zookeeper。主节点订阅了该任务的完成情况信息,所以将得到zookeeper的完工的通知。参考下图,回味一下,是不是和前面项目组通过svn分配工作的例子一模一样?仅仅是把svn和邮件系统合二为一,以ZooKeeper代替。
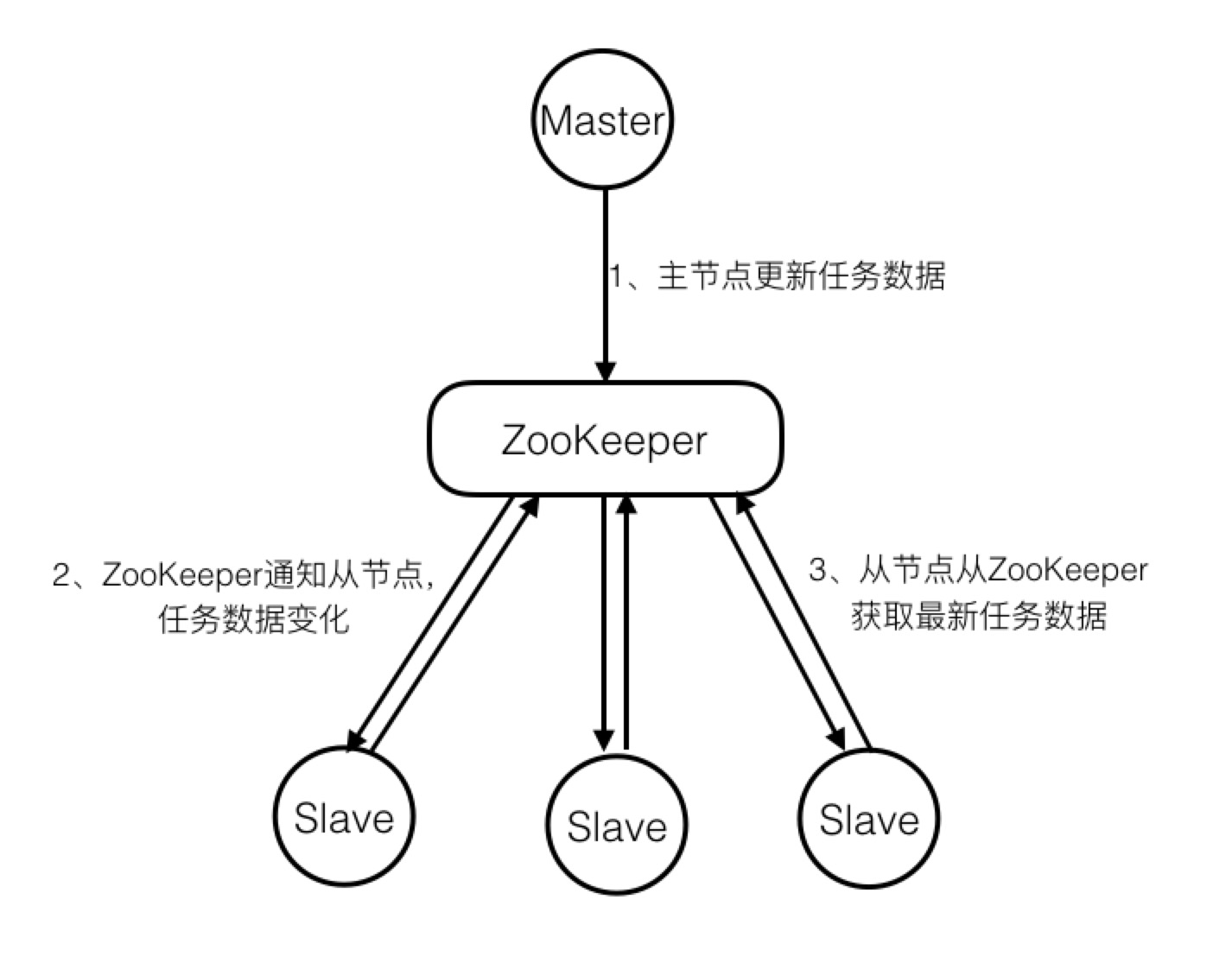
注:Slave节点要想获取ZooKeeper的更新通知,需事先在关心的数据节点上设置观察点。
大多数分布式系统中出现的问题,都源于信息的共享出了问题。如果各个节点间信息不能及时共享和同步,那么就会在协作过程中产生各种问题。ZooKeeper解决协同问题的关键,在于保证分布式系统信息的一致性。
通过以上章节的讲解,我们应该已经理解分布式系统以及其面临的问题。了解了ZooKeeper通过什么样的机制去解决这些问题。从宏观上对ZooKeeper已经有了认知,接下来我们先切入到zookeeper自身,讲解zookeeper的概念,这些概念很重要,所有zookeeper的应用都会围绕这些概念来实现。
1.4、zookeeper概念介绍
ZooKeeper并不直接暴露分布式服务所需要的原语及原语的调用方法。什么是原语?举个例子,比如说分布式锁机制是一个原语,它会暴露出创建、获取、释放三个调用方法。ZooKeeper以类似文件系统的方式存储数据,暴漏出调用这些数据的API。让应用通过ZooKeeper的机制和API,自己来实现分布式相关原语。
我们若想让应用能够通过ZooKeeper实现分布式协同,那么第一件事就是了解ZooKeeper的特性及相关概念,另外熟悉它给我们提供了哪些API。
1.4.1 znode
第一章讲过Zookeeper会保存任务的分配、完成情况,等共享信息,那么ZooKeeper是如何保存的呢?在ZooKeeper中,这些信息被保存在一个个数据节点上,这些节点被称为znode。它采用了类似文件系统的层级树状结构进行管理。见下图示例:
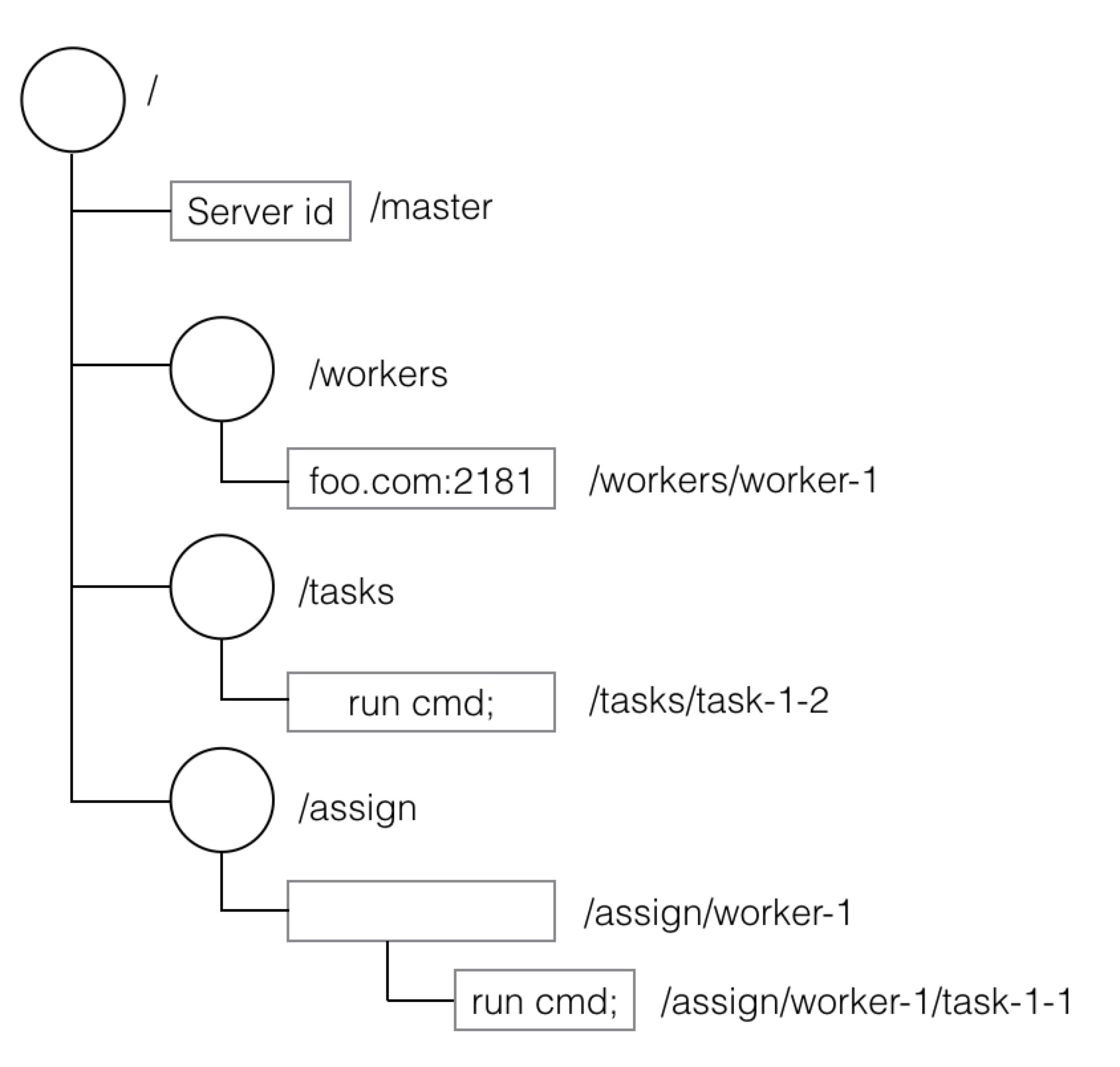
根节点/包含4个子节点,其中三个拥有下一级节点。有的叶子节点存储了信息。
节点上没有存储数据,也有着重要的含义。比如在主从模式中,当/master节点没有数据时,代表分布式应用的主节点还没有选举出来。
znode节点存储的数据为字节数组。存储数据的格式zookeeper不做限制,也不提供解析,需要应用自己实现。
实际上图就是主从模式存储数据的示例,这里先简单讲解:
- /master,存储了当前主节点的信息
- /workers,下面的每个子znode代表一个从节点,子znode上存储的数据,如“foo.com:2181”,代表从节点的信息。
- /tasks,下面的每个子znode代表一个任务,子znode上存储的信息如“run cmd”,代表该内务内容
- /assign,下面每个子znode代表一个从节点的任务集合。如/assign/worker-1,代表worker-1这个从节点的任务集合。/assign/worker-1下的每个子znode代表分配给worker-1的一个任务。
持久节点(persistent)和临时节点(ephemeral)
持久节点只能通过delete删除。临时节点在创建该节点的客户端崩溃或关闭时,自动被删除。
前面例子中的/master应该使用临时节点,这样当主节点失效或者退出时,该znode被删除,其他节点知道主节点崩溃了,开始进行选举的逻辑。另外/works/worker-1也应该是临时节点,在此从节点失效的时候,该临时节点自动删除。
在目前的版本,由于临时znode会因为创建者会话过期被删除,所以不允许临时节点拥有子节点。
有序节点
znode可以被设置为有序(sequential)节点。有序znode节点被分配唯一一个单调递增的证书。如果创建了个一有序节点为/workers/worker-,zookeeper会自动分配一个序号1,追加在名字后面,znode名称为/workers/worker-1。通过这种方式,可以创建唯一名称znode,并且可以直观的看到创建的顺序。
znode支持的操作及暴露的API:
create /path data
创建一个名为/path的znode,数据为data。
delete /path
删除名为/path的znode。
exists /path
检查是否存在名为/path的znode
setData /path data
设置名为/path的znode的数据为data
getData /path
返回名为/path的znode的数据
getChildren /path
返回所有/path节点的所有子节点列表
1.4.2 观察与通知
分布式应用需要及时知道zookeeper中znode的变化,从而了解到分布式应用整体的状况,如果采用轮询方式,代价太大,绝大多数查询都是无效的。因此,zookeeper采用了通知的机制。客户端向zookeeper请求,在特定的znode设置观察点(watch)。当该znode发生变化时,会触发zookeeper的通知,客户端收到通知后进行业务处理。观察点触发后立即失效。所以一旦观察点触发,需要再次设置新的观察点。
我们使用Zookeeper不能期望能够监控到节点每次的变化。思考如下场景:
1、客户端C1设置观察点在/tasks
2、观察点触发,C1处理自己的逻辑
3、C1设置新的观察点前,C2更新了/tasks
4、C1处理完逻辑,再次设置了观察点。
此时C1不会得到第三步的通知,因此错过了C2更新/tasks这次操作。要想不错过这次更新,C1需要在设置监视点前读取/tasks的数据,进行对比,发现更新。
再如下面的场景:
1、客户端C1设置观察点在/tasks
2、/tasks上发生了连续两次更新
3、C1在得到第一次更新的通知后就读取了/tasks的数据
4、此时第二次更新也已经发生,C1用第一次的通知,读取到两次更新后的数据
此时C1虽然错过了第二次通知,但是C1最终还是读取到了最新的数据。
因此Zookeeper只能保证最终的一致性,而无法保证强一致性。
zookeeper可以定义不同的观察类型。例如观察znode数据变化,观察znode子节点变化,观察znode创建或者删除。
1.4.3 版本
每个znode都有版本号,随着每次数据变化自增。setData和delete,以版本号作为参数,当传入的版本号和服务器上不一致时,调用失败。当多个zookeeper客户端同时对一个znode操作时,版本将会起到作用,假设c1,c2同时往一个znode写数据,c1先写完后版本从1升为2,但是c2写的时候携带版本号1,c2会写入失败。
1.4.4 法定人数
zookeeper服务器运行于两种模式:独立模式和仲裁模式(集群)。仲裁模式下,会复制所有服务器的数据树。但如果让客户端等待所有复制完成,延迟太高。这里引入法定人数概念,指为了使zookeeper集群正常工作,必须有效运行的服务器数量。同时也是服务器通知客户端保存成功前,必须保存数据的服务器最小数。例如我们有一个5台服务器的zookeeper集群,法定人数为3,只要任何3个服务器保存了数据,客户端就会收到确认。只要有3台服务器存活,整个zookeeper集群就是可用的。
下图展示了客户端提交请求到收到回复的过程:
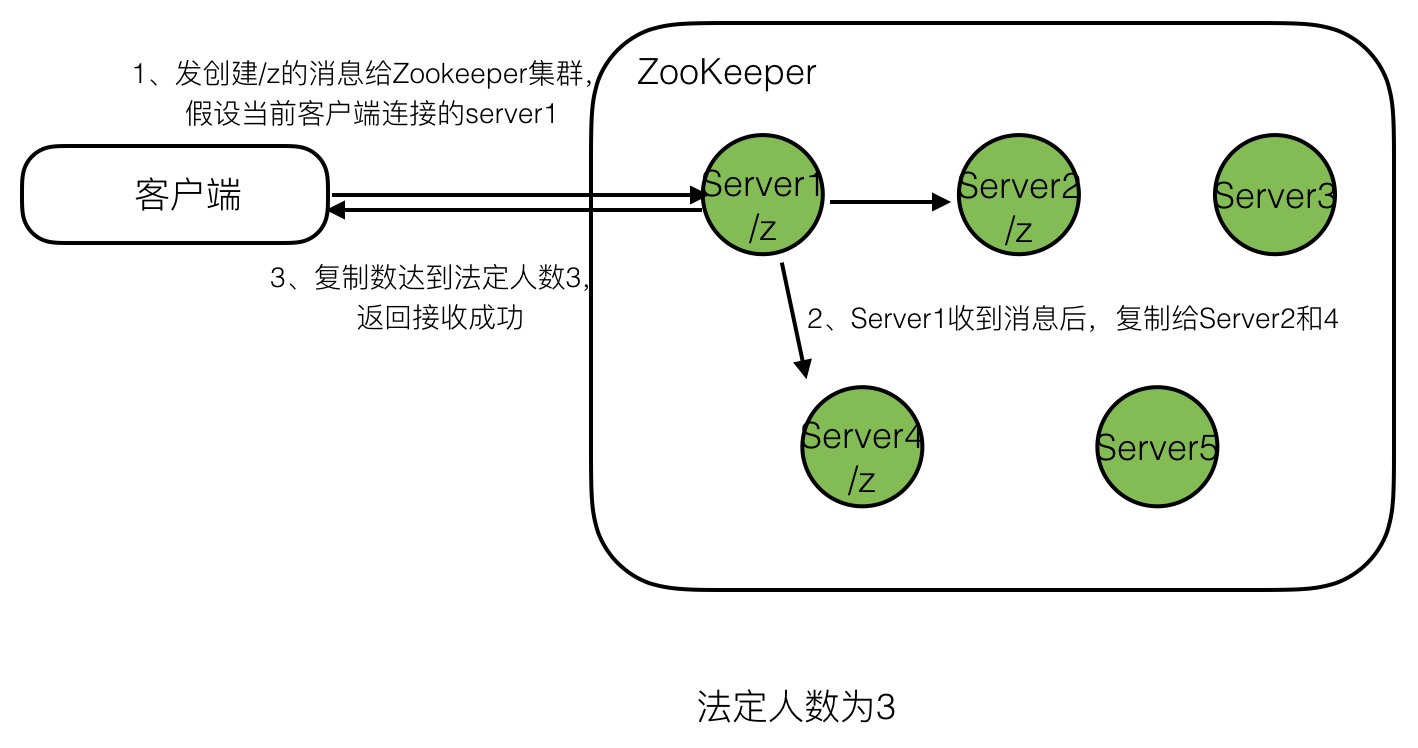
法定人数需要大于服务器数量的一半。也称为多数原则。举个例子说明,假如集群有5台服务器,法定人数为2,那么有2台服务器参与复制即可,若这2台server刚刚复制完/z这个znode,就挂掉了。此时剩下了3台server,大于法定人数2,所以zookeeper认为集群正常,但这三台服务器是无法发现/z这个znode的。如果法定人数大于服务器数量一半,那么法定人数复制完成,就可以确保集群存活时,至少有一台服务器有最新的znode,否则集群认为自己已经崩溃。
下面两个例子阐明了,为何要遵循多数原则。
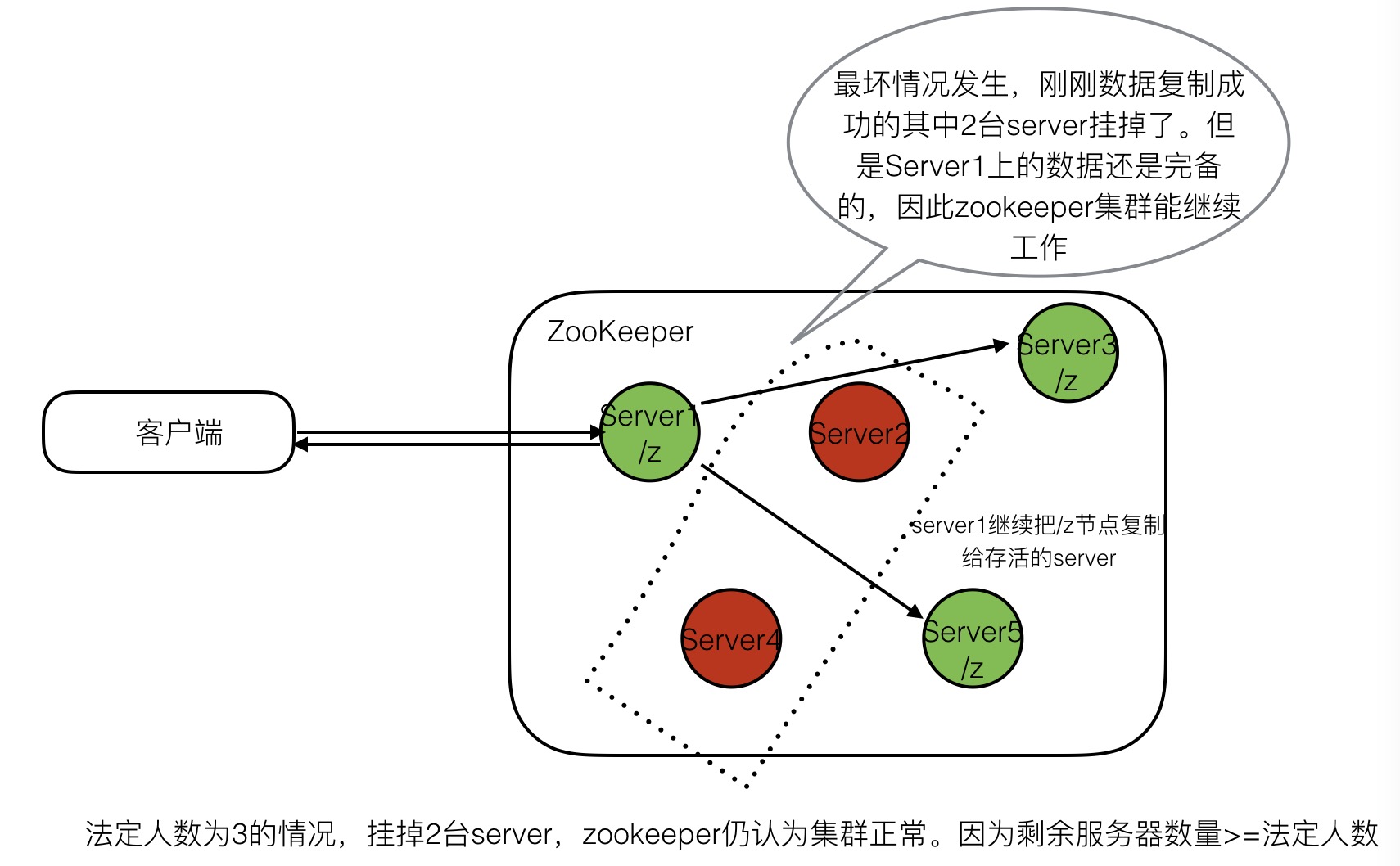
下图展示了5台server,法定人数为3,在确保zookeeper集群存活的前提下,最坏的情况挂了2台server(剩余及器数量3>=法定人数3),zookeeper是如何能确保数据完备,集群继续工作的。
接下来两张图展示了5台server,未遵循多数原则,法定人数设为2。同样挂了两台server时,为什么zookeeper集群会出问题。
首先,客户端发起请求,2个server复制数据后即返回客户端接收成功。
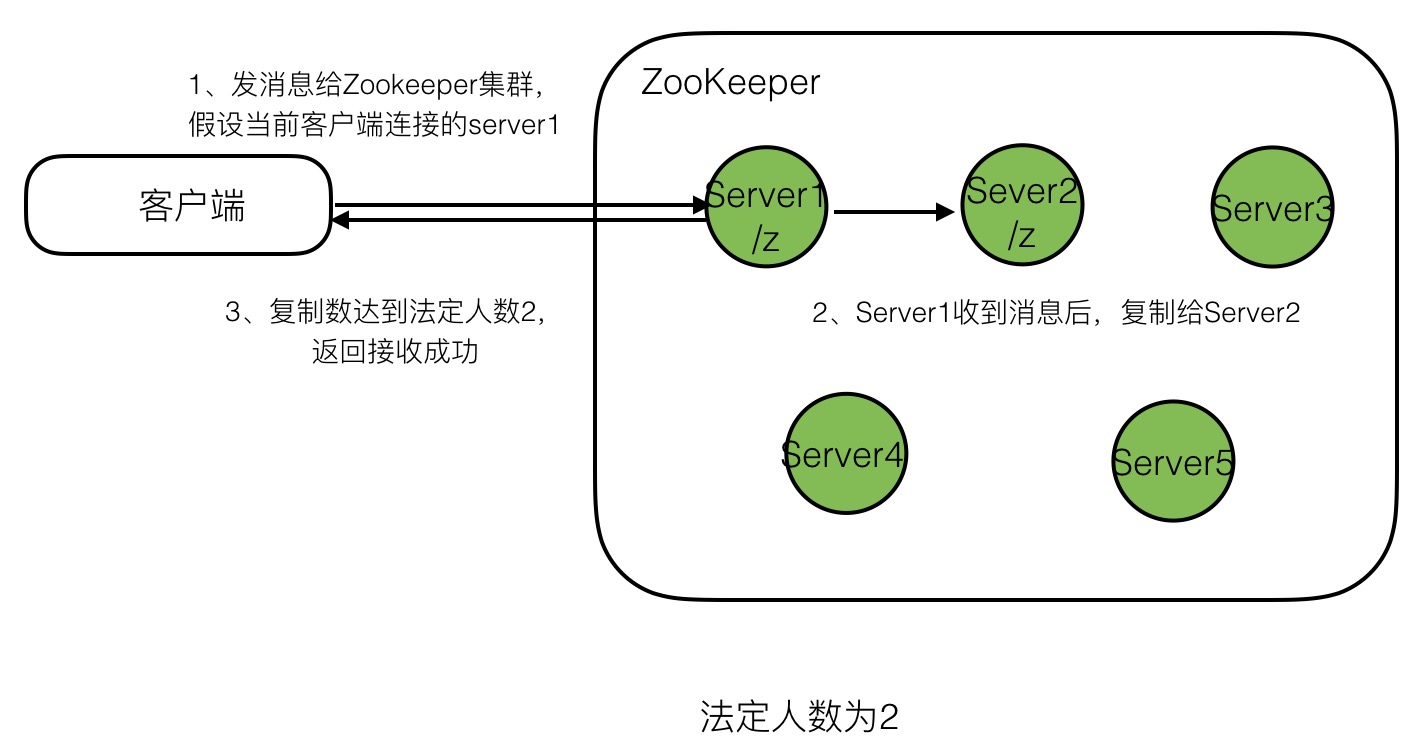
就在此刻,很不幸,在继续同步更新给其他节点前,刚刚两个复制了数据的节点挂了。此时会怎样呢?如下图:
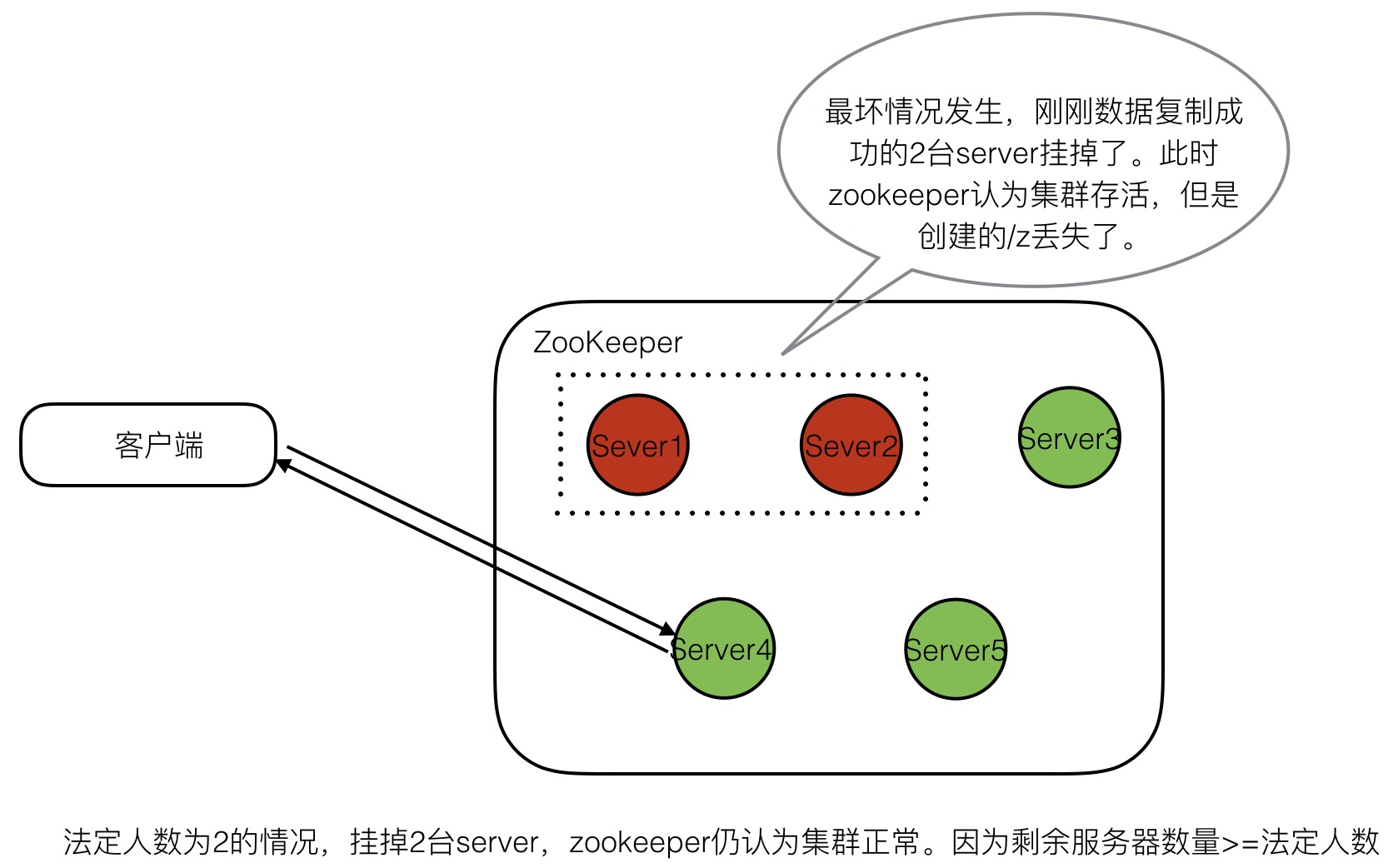
可以看到创建/z的操作在zookeeper集群中丢失了。
相信通过以上讲解,你已经能够理解为什么法定人数一定要多于一半服务器的数量。
此外,我们要尽量选用奇数个服务器,这样集群能容忍崩溃服务器占比更大,性价比更高。例如4台服务器的集群,法定人数最少为3,那么只能允许1台服务器崩溃,也就是仅允许25%的机器崩溃。而5台服务器的集群,法定人数最少也是3,但是此时允许2台服务器崩溃。换句话讲,40%的机器崩溃后还能工作。
仲裁模式下,负载均衡通过客户端随机选择连接串中的某个服务器来实现。
1.4.5 会话
客户端对zookeeper集群发送任何请求前,需要和zookeeper集群建立会话。客户端提交给zookeeper的所有操作均关联在一个会话上。当一个会话因某种原因终止时,会话期间创建的临时节点将会消失。而当当前服务器的问题,无法继续通信时,会话将被透明的转移到另外一台zookeeper集群的服务器上。
会话提供了顺序保障。同一个会话中的请求以FIFO顺序执行。并发会话的FIFO顺序无法保证。
1.4.6 会话状态和生命周期
会话状态有:
connecting、connected、closed、not_connected
创建会话时,需要设置会话超时这个重要的参数。如果经过时间t后服务接受不到这个会话的任何消息,服务就会声明会话过期。客户端侧,t/3时间未收到任何消息,客户端向服务器发送心跳消息,2t/3时间后,客户端开始寻找其他服务器。此时他有t/3的时间去寻找,找不到的话,会话失效。
重连服务器时,只有更新大于客户端的服务器才能被连接,以免连接到落后的服务器。zookeeper中通过更新建立的顺序,分配事务标识符。只有服务器的事物标识符大于客户端携带的标识符时,才可连接。
回顾
本章首先介绍了分布式系统及分布式系统面临的问题,随后介绍了zookeeper是以何机制来解决这些问题的。最后介绍了zookeeper中的重要概念,在开始后续学习前,一定要确保自己理解了这些重要的概念,本章知识是后面章节学习的重要基石。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184786.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
