大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用

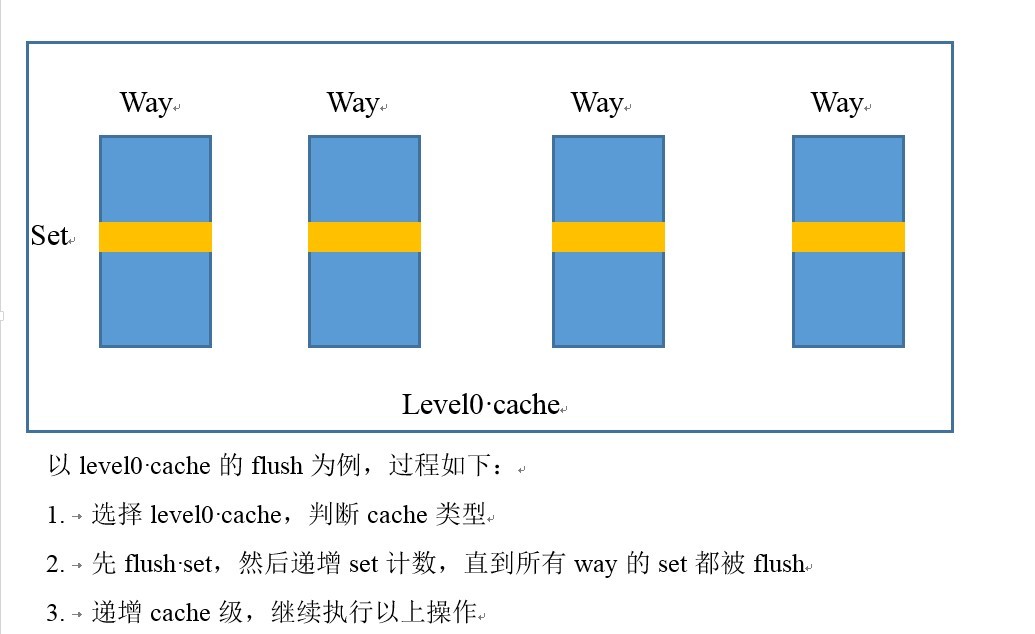
/*
* __flush_dcache_all()
* Flush the wholeD-cache.
* Corrupted registers: x0-x7, x9-x11
*/
ENTRY(__flush_dcache_all)
//保证之前的访存指令的顺序
dsb sy
//读cache level id register
mrs x0, clidr_el1 // read clidr
//取bits[26:24](Level of Coherency for the cache hierarchy.)
//需要遵循cache一致性的cache层级(例如有3级cache,但2级需要做一致性)
and x3, x0, #0x7000000 // extract loc from clidr
//逻辑右移23位,把bits[26:24]放到bits[2:0]
lsr x3, x3, #23 // left align loc bit field
//如果需要做cache一致性的层级为0,则不需要flush,跳转到finished标记处。
cbz x3, finished // if loc is 0, then no need toclean
//x10存放cache级,从level0 cache开始做flush
//以下三个循环loop3是set/way(x9),
//loop2是index(x7),loop1是cache level(x10)
mov x10, #0 // start clean at cache level 0
loop1:
//x10+2后右移一位正好等于1,再加上x10本身正好等于3
//每执行一次loop1,x2+3*执行次数,目的在于把x0(clidr_el1)右移3位,
//取下一个cache的ctype type fields字段,clidr_el1的格式见《ARMv8 ARM》
add x2, x10, x10, lsr #1 /
//x0逻辑右移x2位,给x1,提取cache类型放到x1中,x0中存放:clidr_el1
lsr x1, x0, x2
//掩掉高位,只取当前cache类型
and x1, x1, #7
/* 判断当前cache是什么类型:
* 000 No cache.
* 001 Instruction cache only.
* 010 Data cache only.
* 011 Separate instruction and data caches.
* 100 Unified cache.
*/
//小于2说明data cache不存在或者只有icache,
//跳转skip执行,大于等于2继续执行
cmp x1, #2
b.lt skip
/*
* Save/disableand restore interrupts.
* .macro save_and_disable_irqs, olddaif
* mrs \olddaif,daif
* disable_irq
* .endm
*/
//保存daif到x9寄存器中,关闭中断
save_and_disable_irqs x9 // make CSSELR and CCSIDR access atomic
//选择当前cache级进行操作,csselr_el1寄存器bit[3:1]选择要操作的cache级
//第一次执行时x10=0,选择level 0级cache
msr csselr_el1,x10
//isb用于同步新的cssr和csidr寄存器
isb
//因为执行了“msr csselr_el1,x10”,所以要重新读取ccsidr_el1
mrs x1, ccsidr_el1 // read the new ccsidr
/*
* .macro restore_irqs, olddaif
* msrdaif, \olddaif
. * endm
*/
restore_irqs x9
//x1存储ccsidr_el1内容,低三位是(Log2(Number of bytes in cache line)) – 4
//加4后x2=(Log2(Numberof bytes in cache line))
and x2, x1, #7 // extract the length of the cachelines
add x2, x2, #4 // add 4 (line length offset)
mov x4, #0x3ff
//逻辑右移3位,提取bits[12:3](Associativityof cache) – 1,
//x4存储cache的way数
and x4, x4, x1, lsr #3 // find maximum number on the way size
//计算x4前面0的个数,存到x5
clz x5, x4 // find bit position of way sizeincrement
//提取bits[27:13]位:(Number of sets in cache) – 1
mov x7, #0x7fff
//x7中存储cache中的set数
and x7, x7, x1, lsr #13 // extract max number of the index size
loop2:
//把x4值备份
mov x9, x4 // create working copy of max waysize
loop3:
//把需要操作哪个way存储到x6
lsl x6, x9, x5
//确定操作哪一级的哪个way(x10指定操作哪一级cache)
orr x11, x10, x6 // factor way and cache number intox11
//确定操作哪个set
lsl x6, x7, x2
orr x11, x11, x6 // factor index number into x11
//x11中存储了哪一级cache(10),哪一路cache(x9),哪个set(x7)
dc cisw, x11 // clean & invalidate by set/way
//way数-1
subs x9, x9, #1 // decrementthe way
b.ge loop3
subs x7, x7, #1 // decrementthe index
b.ge loop2
skip:
add x10, x10, #2 // increment cache number,
//为什么加2不是1?见loop1标号处解释
cmp x3, x10
b.gt loop1
finished:
mov x10, #0 // swith back to cache level 0
msr csselr_el1, x10 // select current cache level incsselr
dsb sy
isb
ret
ENDPROC(__flush_dcache_all)
如果你对此有疑问,欢迎留言讨论。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184707.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
