大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
背景:CentOS 6.3
持续更新,作为我的速查小词典
文章目录
超棒的文档:https://man.linuxde.net/xinshoumingling
基础必备
- ls -lh:显示的最全,隐藏的,详细的都显示了。
- sudo:sudo+指令 sudo执行的指令,就等价于root亲自执行的指令
- apt-get: ubuntu的。常用
sudo apt-get install安装软件,因为一般需要root权限来操作,所以一般搭配sudo。
apt-get对安装、卸载升级软件提供一条龙服务。 - yum:centos的安装命令是yum install。
- yum安装完后查看已安装的包:
yum list | grep 软件名或者包名
“|”是一个『管道』 - 下载-:wget
wget 某url从指定的url下载文件。稳定。对限定了链接时间的服务器上下载大文件非常有用。 - rpm查看包的安装位置以及安装文件:rpm 如
rpm -qa列出所有安装过的软件包;rpm -q | grep 包名包是否安装;rpm -qa | grep XXX列出包含某字符的包;rpm -ql 包名包安装的文件到哪里去了 - which: which 文件;which 命令;查找文件、显示命令绝对路径。
- whereis:
whereis XXX???????这几个有点混【回去补】。 - 查看进程是否已经启动:
ps -ef | grep xxxps看哪些进程正在运行、运行状态、进程是否结束等… - service启动重启停止服务-:
service mysql status显示Mysql服务当前状态;service mysql start启动mysql;service mysql stop停止mysql服务;service mysql restart重启服务等。 - scp:远程拷贝文件
scp -r root@10.10.10.10:/opt/soft/mongodb /opt/soft/从10.10.10.10机器拷贝monggodb到本地/opt/soft/目录来。 - tar:
- 解压 tar包到当前目录下
tar -xvf *.tar; - 解压 tar.gz包:
tar -zxvf *.tar.gz - 打包成tar.gz格式:
tar -zcvf anaconda3.tar.gz ./anaconda3 - cp:
cp 源目录/xxx 目标目录把xxx拷贝到目标目录下;cp 源 ./拷到当前目录下。cp -r 源 目标源文件下还有很多文件或者子目录,用-r递归处理… - rm:
rm -rf /usr/temp彻底删除temp文件夹;rm -i删之前先询问一下;rm -r递归处理;rm -f强制删除文件或目录。 - mv:1)移动
mv 原文件 目标文件目录,将XX文件移动到当前目录:mv /../XX .;2)给文件改名mv 旧文件名 新文件名。 - tree .:显示目录树。
vim命令
必须在英文输入法下!!!
- 三种模式:命令模式、输入模式、底线命令模式。
- 刚启动vim,便进入到命令模式,此时敲下去的字母被识别为命令。
- i切换到输入模式。
- : 切换到底线命令模式,以在最后一行输入命令。
- 输入模式下常用:
i要编辑了,i切换嘛
esc:退出输入模式,切换到命令模式 - 底线命令:
q:退出
w:保存
esc:随时退出底线 - 显示行号::set nu
- 查找某个字符:命令模式下,/ 然后输目标字符,回车
一般比如要在某个目录下新建一个文档,比如在/usr/test下想建一个hi.py文件,那么就vim /usr/test/hi.py就ok。 - 根据行号查找:esc退出,shift+:行号 回车。
- 翻页 ctrl+f ctrl向下/上翻页
- 乱码
:set encoding=utf8
‘Shift’+’:’进入命令行模式
翻页:
搜索关键字:/关键字 可快速定位 n:可快速查找next 大写N,上一个
gg : 跳转到文件头
Shift+g: 跳转到文件末尾
行数+gg : 跳转到指定行,例跳转到123行:123gg
j:下一行
K:上一行
:n (跳转到文件第n行,需要回车)
w:按单词移动
u:撤销。一直按u一直撤
ctrl+r:取消撤销。一直按一直取消
行号:
设置:set nu
取消:set nonu
Question
Q:添加了新用户bae,sudo一条安装命令后报错xxxis not in the sudoers file. This incident will be reported.
需要允许用户youuser执行sudo命令(需要输入密码),怎么做:
1、切换到root用户下
2、/etc/sudoers文件默认是只读的,对root来说也是,因此需先添加sudoers文件的写权限,命令是: 即执行操作:chmod u+w /etc/sudoers
3. 编辑sudoers文件 即执行:vi /etc/sudoers 找到这行 root ALL=(ALL) ALL,在他下面添加xxx
ALL=(ALL) ALL (这里的xxx是你的用户名)
ps:这里说下你可以sudoers添加下面四行中任意一条
youuser ALL=(ALL) ALL
%youuser ALL=(ALL) ALL
youuser ALL=(ALL) NOPASSWD: ALL
%youuser ALL=(ALL) NOPASSWD: ALL
第一行:允许用户youuser执行sudo命令(需要输入密码).
第二行:允许用户组youuser里面的用户执行sudo命令(需要输入密码).
第三行:允许用户youuser执行sudo命令,并且在执行的时候不输入密码.
第四行:允许用户组youuser里面的用户执行sudo命令,并且在执行的时候不输入密码.
4、撤销sudoers文件写权限,命令: chmod u-w /etc/sudoers
查磁盘、文件大小、查大文件
我最常用的两个:
- 查磁盘大小及使用df -h
- 查当前目录下文件的大小 du -sh *
其他:
df:磁盘使用情况查看 df -ah
du:查文件或目录大小。du -sh * | sort -n查当前目录下的大文件或目录;查看上GB的目录并且排序,可以用这个命令du -h --max-depth=1 |grep 'G' |sort;-h以K,M,G为单位,提高可读性;-s仅显示统计;
常用:du -h –max-depth=1
**查找大文件:**find /home/bae -name *log -size +100M -print0 | xargs -0 du -h | sort -r
统计文件行数、字数、字节数
wc 文件名
返回:行数 字数 字节数 文件名
还可以一次查多个文件
wc 文件名1 文件名2 文件名3
cat 20210620 | grep ‘uniqid’ | wc -l grep时候注意,不要把机器拉宕机
cat 20210620 | grep ‘uniqid’ | more
重命名
mv 旧文件名 新文件名
环境变量添加
https://www.cnblogs.com/youyoui/p/10680329.html 有好几种方式
我一般用:
vim ~/.bashrc
加export …
source ~/.bashrc
对当前用户生效
让代码在后台运行 nohup
注意!!!用nohup的时候要用命令的绝对路径
type python获取python的绝对路径
type hadoop获取hadoop的绝对路径
后台运行:nohup /xx/xx/python **.py &
终端退出后命令仍然执行。
注意把解释器路径打全
可以用type python获得绝对路径
启动成功了能看到返回一个编号和进程id,如,[1] 22772
还会返回: appending output to `nohup.out’
查看当前终端后台运行的任务: jobs jobs -l能查看到pid
查看当前的所有进程:ps -ef|grep codeFilename
或者ps -ef|grep 进程Id
终止后台运行的进程:kill -9 进程id
查进程
我最常用:
- ps aux | grep “test.py” 看test.py是否在运行着,查test.py的pid等
- 对于nohup后台启动的进程,我常用jobs -l
获取占用CPU资源最多的10个进程
linux下获取占用CPU资源最多的10个进程,可以使用如下命令组合:
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +3|head
杀掉进程
Mac下
比方想杀掉Outlook:
1、查出Outlook的pid: ps aux | grep Outlook
ps axu | grep "Outlook" | grep -v grep | awk -F " " '{print $2}'直接会得到4238
2、杀掉进程:sudo kill -9 4238 4238是进程号pid。
3、根据进程名字杀进程:killall name
4、杀掉多进程进程:ps aux | grep "test.sh" | awk -F ' ' '{print $2}' | xargs kill 杀掉所有为test.sh的进程
远程拷贝
把远程机器上的文件夹拷贝到本机:
例如:把机器x上的/home/chen/life文件夹拷贝到当前机器的当前目录下:
scp -r 用户名@ip地址:机器x上的文件路径/文件夹 本机上的路径
scp -r root@10.138.37.187:/home/tem ./
把当前机器上的文件拷贝到远程机器:
scp 本机上的路径/文件 用户名@ip地址:机器x上的文件路径/目标文件夹/
scp -r 本机上的路径/文件夹 用户名@ip地址:机器x上的文件路径/目标文件夹/
eg:
scp -r XXX/NA.2020-09-27 root@10.138.37.137:/home/bae/
一个机器两个账户之间拷贝
如果相互有权限,就直接cp。
如果是隔离的,就先放到系统的/tmp/下,再从/tmp/搬运。
命令快捷技巧
快速光标定位到命令头:ctrl + a
快速光标定位到命令头:ctrl + e
删除本条命令:ctrl + e 再ctrl + u
查目录下有哪些文件
ll -a
查本机ip,只显示本机ip
hostname -i
grep
1.在文件中查找
a. 在rp.log文件查找sql result number,输出的是所在行的整行内容:grep "sql result number" rp.log
b. 查找出来后写到另一个文件grep "process sql result number" rp.log >a
c.想查多个:grep -e 。 比如既查sql number又查time: grep -e “sql number” -e “time” rp.log
2.在文件夹下查找
一般我用在项目里查找代码变量什么的
在当前文件夹下查找XXX出现的所有地方grep -ri XXX ./
3.反选匹配grep -v
匹配除XXX在的行以外的所有行
查看文件前几行,后几行
head -n 10 file
tail -n 10 file
tail file
sh启动脚本
sh XXX.sh
sh xxx.sh >>tmp 追加
sh -x XXX.sh
Sh *.sh >res 2>&1
Sh *.sh >res 2>&1 &
Nohuo *.sh
sh *.sh 1>>log.txt 2>&1
修改目录以及目录下所有文件所属用户和用户组
修改目录下文件的所属用户:sudo chown -R bae /home
-R为递归
修改目录下的文件的所属用户组:sudo chgrp -R bae /home
查找文件find
查找某个目录下的该文件
eg.查找.jumbo文件夹下是否有github.com文件夹find .jumbo -name github.com
查找.jumbo文件夹下是否有github相关的文件夹find .jumbo -name *github*
查找/home/test路径下是否有*.go文件find /home/test -name *.go
-iname不区分大小写
! -name非…
sed编辑文件
增删查改。
- 增:a(append)
- 删:d(delete)
- 查:-n p(print)
- 改:前面插入 i ,数据行替换 c,字符串的替换 s ,替换并写入文件 -i
1. sed -n
sed -n '/name/p' 1.txt#逐行读取文件,找出匹配文件中name的行,结果:
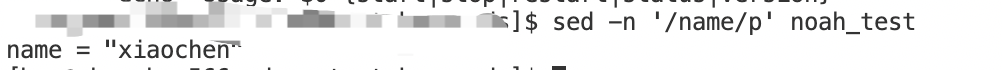

常用,获取name的值:sed -n '/name/p' noah_test | grep name | awk -F "=" '{print $2}' ,输出”xiaochen”,写在代码里可以这样用变量保存来用:namePerson=$(sed -n '/name/p' noah_test | grep name | awk -F "=" '{print $2}')
关于awk的理解写在awk部分。
2.sed -i 直接修改文件
sed -i 's/原字符串/新字符串/' /home/1.txt
sed -i 's/原字符串/新字符串/g' /home/1.txt
加g与不加g的区别:
#cat 1.txt
d
ddd
#ff
sed -i 's/d/7523/' /home/1.txt
执行结果
7523
7523dd
#ff
sed -i 's/d/7523/g' /home/1.txt
执行结果
7523
752375237523
#ff
其它:

awk
见上面的sed,namePerson=$(sed -n '/name/p' noah_test | grep name | awk -F "=" '{print $2}'),awk -F “=” ‘{print $2} 以等号分隔,取等号后的部分。
awk 过滤某一列的数字大于10的行
cat frequency.log | awk -F ':' '$2>100{print $0}'
-F 以什么作为分隔列
$2>100 第二列大于100
{print $0}打印一整行
边启动边看日志
搞两个面板:
面板1输入:tail -f *.log.wf *.log观察着
面板2启动程序,看日志输出
根据端口查进程
netstat -tnlp 查看有哪些监听
/usr/sbin/lsof -i:8800 比如看8800
传文件 通过HTTP
传开发机的文件到本地。
1、python -m SimpleHTTPServer 8030 8030为指定的端口号
2、开发机ip:port 在本地浏览器访问,即可
split大文件分割为小文件
按行数分隔:
split -l 50000 大文件名 5W行一个小文件
split -l 50000 大文件名 filen_ -d -a 2 5W行一个小文件
- -l:按行数分割
- file_:定义分割后的小文件的命名前缀为file
- -d:定义小文件命名后缀为数字
- -a 2: 表示用两位数来顺序命名
eg.
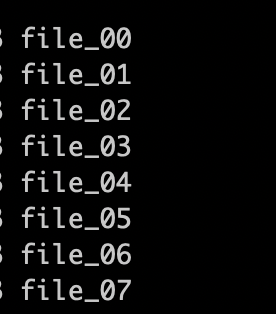
split -l 2000000 …/bigfile.txt file_ -d -a 2
结果如下:
排序 sort
这篇sort写的很好。
使用方法:sort [选项]… [文件]…
sort默认是把结果输出到标准输出
选项总结
-r 降序, sort默认升序
-n 要以数值来排序 sort只认字符
-t 设定间隔符
-t $'间隔符' -k 第几列 定了间隔符之后,就可以用-k来指定列数了。
-u 在输出行中去除重复行
-o 结果输出到原文件 写法不太一样:sort oldfile -o oldfile sort默认是把结果输出到标准输出,所以需要用重定向才能将结果写入文件,形如sort oldfile > newfile。如果你想把排序结果输出到原文件中,用-o。
a.按每行的首字符排序
1、原文内容 每行以tab间隔
黄皮书 50 0.5
龙虾 30 0.4
龙族 40 0.6
黄金 60 0.8
2、升序:cat 文件名 | sort > 新文件名
效果:
黄皮书 50 0.5
黄金 60 0.8
龙族 40 0.6
龙虾 30 0.4
3、降序:cat 文件名 | sort -r > 新文件名
效果:
龙虾 30 0.4
龙族 40 0.6
黄金 60 0.8
黄皮书 50 0.5
要是需要写到新文件的话,就>重定向到新文件
b.按某列排序
筛选出某一列的词频小于50的
cat testcn.txt | awk -F $'\t' '$2<40{print $0}' >result.txt
-F 指以什么做分隔符
符号前面最好加上$,有的不加也能行。
上面awk有解释命令意思。
效果:
龙虾 30 0.4
龙族 40 0.6
按第二列数字升序排序
sort -n -t $'\t' -k 2 testcn.txt
效果:
龙虾 30 0.4
龙族 40 0.6
黄皮书 50 0.5
黄金 60 0.8
按第二列数字降序排序
sort -r -n -t $'\t' -k 2 testcn.txt
效果:
黄金 60 0.8
黄皮书 50 0.5
龙族 40 0.6
龙虾 30 0.4
删除文件的第一行
sed -i '1d' 文件名
删第n行:
sed -i 'nd' 文件名
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184493.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
