大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
(5)GlobalSession:这个只在portal应用中有用,给每一个 global http session 新建一个Bean实例。
5、Spring事务传播行为
所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
-
TransactionDefinition.PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。这是默认值。
-
TransactionDefinition.PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-
TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-
TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-
TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
-
TransactionDefinition.PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
-
TransactionDefinition.PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
6、Spring的声明式事务管理力度是什么级别?
Struts2是类级别的,Spring是方法级别的
spring事务可以分为编程式事务和声明式事务
7、spring MVC与struts2的区别:
参考: http://blog.csdn.net/chenleixing/article/details/44570681
① Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截
② SpringMVC的方法之间基本上独立的,独享request response数据
③ 由于Struts2需要针对每个request进行封装,把request,session等servlet生命周期的变量封装成一个一个Map,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的
④ 拦截器实现机制上,Struts2有以自己的interceptor机制,SpringMVC用的是独立的AOP方式
⑤ SpringMVC的入口是servlet,而Struts2是filter
⑥ SpringMVC集成了Ajax
⑦ SpringMVC验证支持JSR303,处理起来相对更加灵活方便,而Struts2验证比较繁琐,感觉太烦乱
⑧ Spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高
⑨ Struts2更加符合OOP的编程思想, SpringMVC就比较谨慎,在servlet上扩展
⑩ SpringMVC开发效率和性能高于Struts2
8、Spring框架中的核心思想包括什么?
主要思想是IOC控制反转,DI依赖注入,AOP面向切面
9、ArrayList和LinkedList的大致区别如下:
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
10、ArrayList,Vector主要区别为以下几点:
(1):Vector是线程安全的,源码中有很多的synchronized可以看出,而ArrayList不是。导致Vector效率无法和ArrayList相比;
(2):ArrayList和Vector都采用线性连续存储空间,当存储空间不足的时候,ArrayList默认增加为原来的50%,Vector默认增加为原来的一倍;
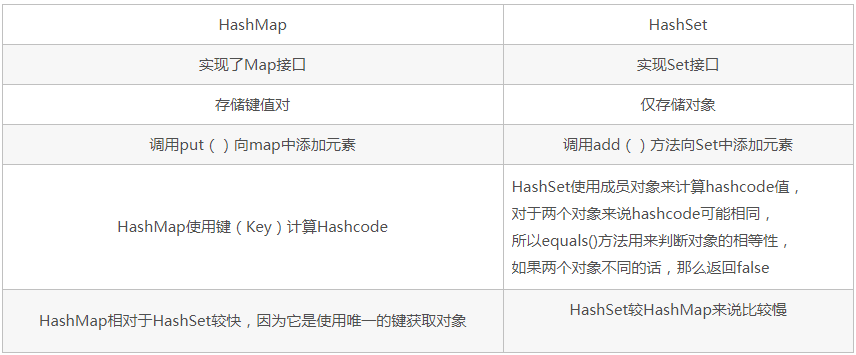
11、HashSet与HashMap的区别:

12、HashMap和Hashtable的区别:
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
-
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
-
HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
-
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
-
由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
-
HashMap不能保证随着时间的推移Map中的元素次序是不变的。
13、线程安全是什么?线程不安全是什么?
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。(Vector,HashTable)
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。(ArrayList,LinkedList,HashMap等)
14、线程和进程的区别?
进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同;
(1)进程是资源的分配和调度的一个独立单元,而线程是CPU调度的基本单元
(2)同一个进程中可以包括多个线程,并且线程共享整个进程的资源(寄存器、堆栈、上下文),一个进行至少包括一个线程。
(3)进程的创建调用fork或者vfork,而线程的创建调用pthread_create,进程结束后它拥有的所有线程都将销毁,而线程的结束不会影响同个进程中的其他线程的结束
(4)线程是轻两级的进程,它的创建和销毁所需要的时间比进程小很多,所有操作系统中的执行功能都是创建线程去完成的
(5)线程中执行时一般都要进行同步和互斥,因为他们共享同一进程的所有资源
(6)线程有自己的私有属性TCB,线程id,寄存器、硬件上下文,而进程也有自己的私有属性进程控制块PCB,这些私有属性是不被共享的,用来标示一个进程或一个线程的标志
15、黑盒测试、灰盒测试、白盒测试、单元测试有什么区别?
黑盒测试关注程序的功能是否正确,面向实际用户;
白盒测试关注程序源代码的内部逻辑结构是否正确,面向编程人员;
灰盒测试是介于白盒测试与黑盒测试之间的一种测试。
单元测试(Unit Testing)是对软件基本组成单元进行的测试,如函数或是一个类的方法。这里的单元,就是软件设计的最小单位。
16、怎么对数据库百万级数据进行优化?
使用读写分离技术(
让主数据库(master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库(slave)处理SELECT查询操作
)
17、Spring Bean的生命周期:
-
Bean的建立, 由BeanFactory读取Bean定义文件,并生成各个实例
-
Setter注入,执行Bean的属性依赖注入
-
BeanNameAware的setBeanName(), 如果实现该接口,则执行其setBeanName方法
-
BeanFactoryAware的setBeanFactory(),如果实现该接口,则执行其setBeanFactory方法
-
BeanPostProcessor的processBeforeInitialization(),如果有关联的processor,则在Bean初始化之前都会执行这个实例的processBeforeInitialization()方法
-
InitializingBean的afterPropertiesSet(),如果实现了该接口,则执行其afterPropertiesSet()方法
-
Bean定义文件中定义init-method
-
BeanPostProcessors的processAfterInitialization(),如果有关联的processor,则在Bean初始化之前都会执行这个实例的processAfterInitialization()方法
-
DisposableBean的destroy(),在容器关闭时,如果Bean类实现了该接口,则执行它的destroy()方法
-
Bean定义文件中定义destroy-method,在容器关闭时,可以在Bean定义文件中使用“destory-method”定义的方法
简单回答springbean生命周期:
(1)实例化(必须的)构造函数构造对象
(2)装配(可选的)为属性赋值
(3)回调(可选的)(容器-控制类和组件-回调类)
(4)初始化(init-method=” “)
(5)就绪
(6)销毁(destroy-method=” “)
18、springmvc生命周期:
1A)客户端发出http请求,只要请求形式符合web.xml
文件中配置的*.action的话,就由DispatcherServlet
来处理。
1B)DispatcherServlet再将http请求委托给映射器
的对象来将http请求交给对应的Action来处理
2)映射器根据客户的http请求,再对比<bean name=”/hello.action
如果匹配正确,再将http请求交给程序员写的Action
3)执行Action中的业务方法,最终返回一个名叫ModelAndView
的对象,其中封装了向视图发送的数据和视图的逻辑名
4)ModelAndView对象随着响应到到DispatcherServlet中了
5)这时DispatcherServlet收到了ModelAndView对象,
它也不知道视图逻辑名是何意,又得委托一个名叫
视图解析器的对象去具体解析ModelAndView对象
中的内容
6)将视图解析器解析后的内容,再次交由DispatcherServlet
核心控制器,这时核心控制器再将请求转发到具体的
视图页面,取出数据,再显示给用户
19、servlet生命周期?
总结
至此,文章终于到了尾声。总结一下,我们谈论了简历制作过程中需要注意的以下三个部分,并分别给出了一些建议:
- 技术能力:先写岗位所需能力,再写加分能力,不要写无关能力;
- 项目经历:只写明星项目,描述遵循 STAR 法则;
- 简历印象:简历遵循三大原则:清晰,简短,必要,要有的放矢,不要海投;
以及最后为大家准备的福利时间:简历模板+Java面试题+热门技术系列教程视频
戳这里免费领取文中资料
过程中需要注意的以下三个部分,并分别给出了一些建议:
- 技术能力:先写岗位所需能力,再写加分能力,不要写无关能力;
- 项目经历:只写明星项目,描述遵循 STAR 法则;
- 简历印象:简历遵循三大原则:清晰,简短,必要,要有的放矢,不要海投;
以及最后为大家准备的福利时间:简历模板+Java面试题+热门技术系列教程视频
戳这里免费领取文中资料
[外链图片转存中…(img-DGQ6IXv7-1628077328596)]
[外链图片转存中…(img-cIKj9t9X-1628077328597)]
[外链图片转存中…(img-rFeHbZY0-1628077328599)]
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184413.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
