大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
文章目录
优化目标
引入
我们先从回顾一下Logistic回归,看看Logistic回归是如何演变为支持向量机的。
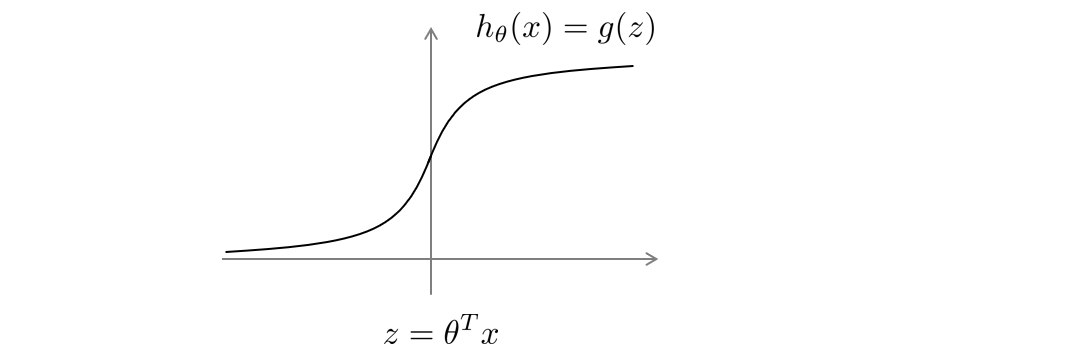

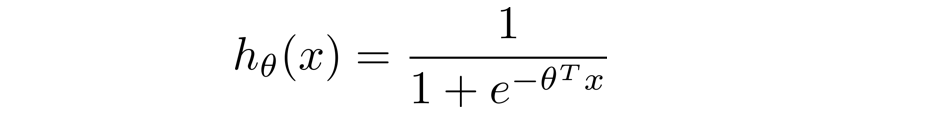
当 y = 1 y=1 y=1时,如果我们希望 h θ ( x ) ≈ 1 h_{\theta}(x)≈1 hθ(x)≈1,则 θ T x \theta^{T}x θTx远大于0.
当 y = 0 y=0 y=0时,如果我们希望 h θ ( x ) ≈ 0 h_{\theta}(x)≈0 hθ(x)≈0,则 θ T x \theta^{T}x θTx远小于0.
下面是每个样本的代价函数,注意没有求和,代表每个单独的训练样本对Logistic回归的总体目标函数的贡献。

然后我们将 h θ ( x ) h_{\theta}(x) hθ(x)的具体公式带入进去,得到的就是每个训练样本对总体函数的具体贡献:
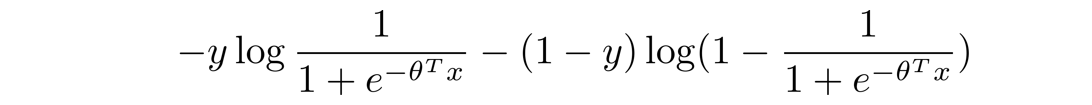
现在我们再来考虑 y = 1 , y = 0 y=1,y=0 y=1,y=0的情况,函数图像如下:
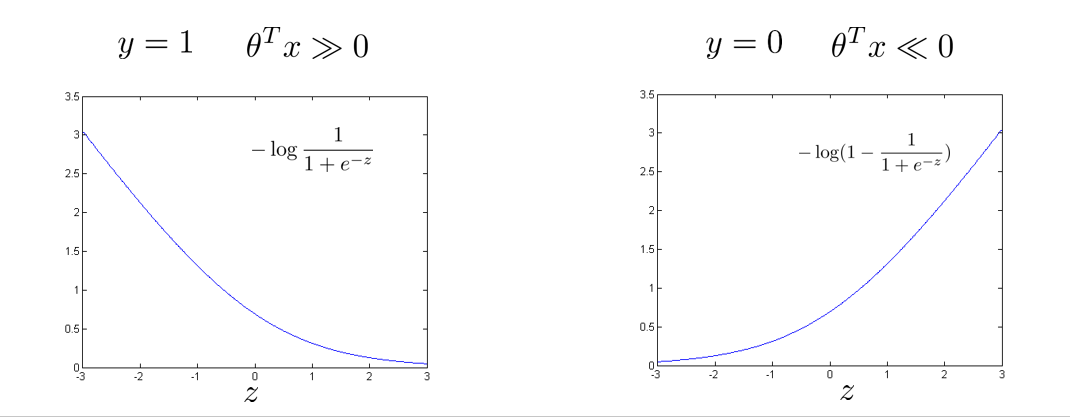
下面我们 y = 1 y=1 y=1为例,用两条直线近似等效曲线,来向支持向量机转换,例如我以 z = 1 z=1 z=1为起点,作两条直线近似取代曲线 − l o g 1 1 + e − z -log\frac{1}{1+e^{-z}} −log1+e−z1,同理 y = 0 y=0 y=0时也一样。
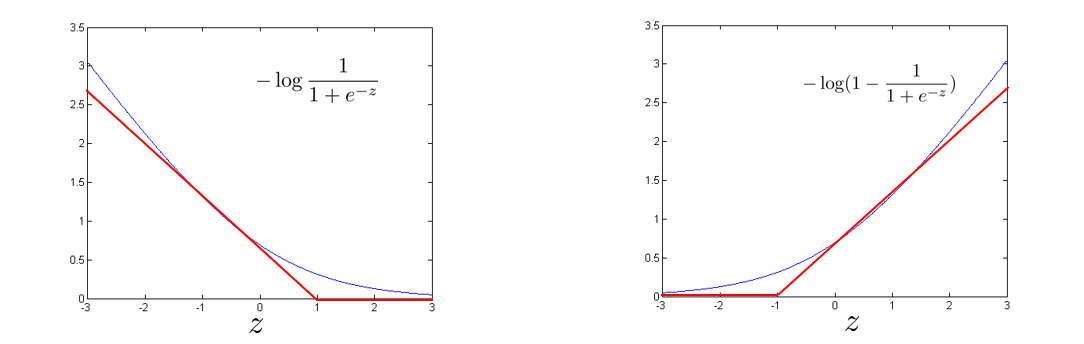
当 y = 1 y=1 y=1时,两条直线记为 C o s t 1 ( z ) Cost_1(z) Cost1(z)。
当 y = 0 y=0 y=0时,两条直线记为 C o s t 0 ( z ) Cost_0(z) Cost0(z)。
构建支持向量机
这是我们在Logistic回归中使用的正规化代价函数 J ( θ ) J(\theta) J(θ)
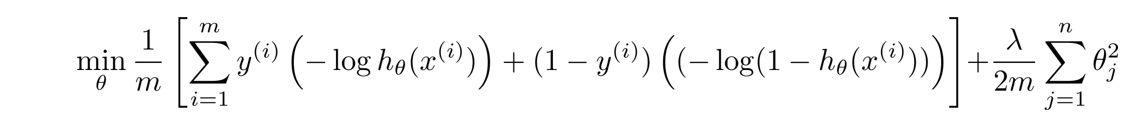
然后我们用 C o s t 1 ( θ T x ( i ) ) Cost_1(\theta^{T}x^{(i)}) Cost1(θTx(i))和 C o s t 0 ( θ T x ( i ) ) Cost_0(\theta^{T}x^{(i)}) Cost0(θTx(i))将 − l o g h θ ( x ( i ) ) -logh_{\theta}(x^{(i)}) −loghθ(x(i))和 − l o g ( 1 − h θ ( x ( i ) ) ) -log(1-h_{\theta}(x^{(i)})) −log(1−hθ(x(i)))代替,去掉 1 m \frac{1}{m} m1,然后对于正规项,我们不再用 λ \lambda λ来控制正规项的权重,而选择用不同的常数C来控制第一项的权重,最后我们得到支持向量机的总体优化目标如下:

与Logistic回归不同的是,sigmoid函数输出的不是概率,而是直接输出0或者1。
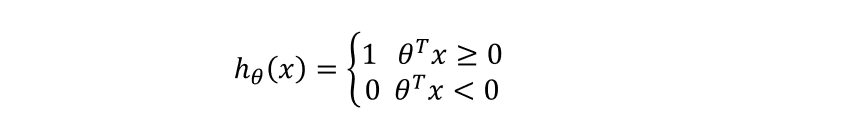
直观理解SVM
这是SVM的代价函数和图像:

下面我们来想一下如何让代价函数最小化。
若 y = 1 y=1 y=1,则当 θ T x ≥ 1 \theta^{T}x≥1 θTx≥1时, C o s t 1 ( z ) = 0 Cost_1(z)=0 Cost1(z)=0.
若 y = 0 y=0 y=0,则当 θ T x ≤ − 1 \theta^{T}x≤-1 θTx≤−1时, C o s t 2 ( z ) = 0 Cost_2(z)=0 Cost2(z)=0.
下面我们想象一下,如果将常数C设得比较大,例如C=100000,那么当进行最小化时,我们将迫切希望找到一个合适的值,使第一项等于0,那么现在我们试着在这种情况下来理解优化问题。
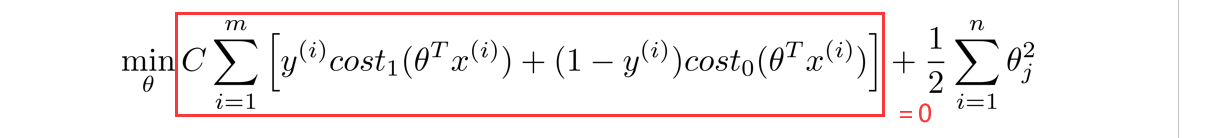
要使第一项为0,则有以下两种情况:
若 y = 1 y=1 y=1,则 θ T x ≥ 1 \theta^{T}x≥1 θTx≥1,即 y = 1 y=1 y=1的样本点在超平面 H 1 : θ T x ≥ 1 H_1:\theta^{T}x≥1 H1:θTx≥1上。
若 y = 0 y=0 y=0,则 θ T x ≤ − 1 \theta^{T}x≤-1 θTx≤−1,即 y = 0 y=0 y=0的样本点在超平面 H 2 : θ T x ≤ − 1 H_2:\theta^{T}x≤-1 H2:θTx≤−1上。
如下图所示,在 H 1 、 H 2 H_1、H_2 H1、H2上的点就是支持向量:
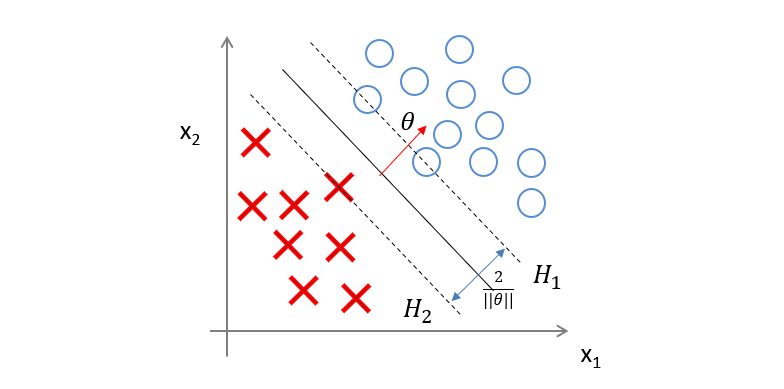
这里两个超平面 H 1 、 H 2 H_1、H_2 H1、H2平行,它们中间没有样本点。 H 1 、 H 2 H_1、H_2 H1、H2之间的距离成为间隔(margin)。
间隔依赖于分离超平面的法向量 θ \theta θ,等于 2 ∣ ∣ θ ∣ ∣ \frac{2}{||\theta||} ∣∣θ∣∣2。 H 1 、 H 2 H_1、H_2 H1、H2是间隔边界。
核函数(kernel)
简单介绍
如下图,我们需要得到一个非线性的决策边界:

按我们之前学的方法,可以通过增加项数来进行拟合,如下:
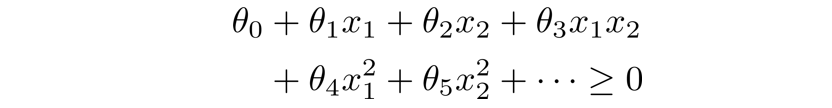
现在我们用一些新的符号 f 1 , f 2 , f 3 . . . f_1,f_2,f_3… f1,f2,f3...来表示新的特征值:
θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 + θ 4 f 4 + θ 5 f 5 + . . . ≥ 0 \theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3+\theta_4f_4+\theta_5f_5+…≥0 θ0+θ1f1+θ2f2+θ3f3+θ4f4+θ5f5+...≥0
f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , f 4 = x 1 2 . . . f_1=x_1,f_2=x_2,f_3=x_1x_2,f_4=x_1^2… f1=x1,f2=x2,f3=x1x2,f4=x12...
现在我们用 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3来举例:
如图,我们在图上选择三个标记 l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)},l^{(2)},l^{(3)} l(1),l(2),l(3)
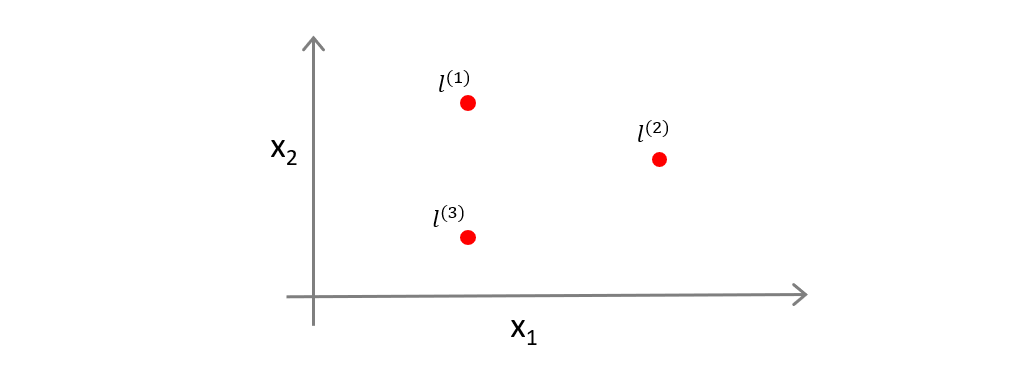
然后来定义新的特征:
给定一个实例x,然后将 f 1 f_1 f1定义为度量实例 x x x与标记点 l ( 1 ) l^{(1)} l(1)的相似度
f 1 = s i m i l a r i t y ( x , l ( 1 ) ) = e x p ( − ∣ ∣ x − l ( 1 ) ∣ ∣ 2 2 σ 2 ) f_1=similarity(x,l^{(1)})=exp(-\frac{
{||x-l^{(1)}||}^2}{2\sigma^2}) f1=similarity(x,l(1))=exp(−2σ2∣∣x−l(1)∣∣2)
类似地,
f 2 = s i m i l a r i t y ( x , l ( 2 ) ) = e x p ( − ∣ ∣ x − l ( 2 ) ∣ ∣ 2 2 σ 2 ) f_2=similarity(x,l^{(2)})=exp(-\frac{
{||x-l^{(2)}||}^2}{2\sigma^2}) f2=similarity(x,l(2))=exp(−2σ2∣∣x−l(2)∣∣2)
f 3 = s i m i l a r i t y ( x , l ( 3 ) ) = e x p ( − ∣ ∣ x − l ( 3 ) ∣ ∣ 2 2 σ 2 ) f_3=similarity(x,l^{(3)})=exp(-\frac{
{||x-l^{(3)}||}^2}{2\sigma^2}) f3=similarity(x,l(3))=exp(−2σ2∣∣x−l(3)∣∣2)
这种函数我们称为高斯核函数,后面我们还会学到其他的核函数。
下面来看看这些核函数的表达式有什么含义。
假设现在有一点非常接近与标记点 l ( 1 ) l^{(1)} l(1),那么欧氏距离 ∣ ∣ x − l ( 1 ) ∣ ∣ 2 {||x-l^{(1)}||}^2 ∣∣x−l(1)∣∣2就会接近于0,此时 f 1 ≈ e x p ( 0 ) = 1 f_1≈exp(0)=1 f1≈exp(0)=1。
相反,如果这点离 l ( 1 ) l^{(1)} l(1)很远,欧式距离 ∣ ∣ x − l ( 1 ) ∣ ∣ 2 {||x-l^{(1)}||}^2 ∣∣x−l(1)∣∣2会变得很大,此时 f 1 ≈ 0 f_1≈0 f1≈0。
讲完了特征值的定义,接下来我们看看核函数是如何应用于决策边界的。
给定一个训练样本,当 θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 ≥ 0 \theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3≥0 θ0+θ1f1+θ2f2+θ3f3≥0时,预测 y = 1 y=1 y=1。
假设我们已经得到了参数 θ \theta θ的值:
θ 0 = − 0.5 , θ 1 = 1 , θ 2 = 1 , θ 3 = 0 \theta_0=-0.5,\theta_1=1,\theta_2=1,\theta_3=0 θ0=−0.5,θ1=1,θ2=1,θ3=0
现在我们有一个实例 x x x(蓝点),落在如图所示位置,显然,该实例与标记点 l ( 1 ) l^{(1)} l(1)间距离很近,故 f 1 = 1 f_1=1 f1=1,与标记点 l ( 2 ) , l ( 3 ) l^{(2)},l^{(3)} l(2),l(3)相距较远,故 f 2 , f 3 = 0 f_2,f_3=0 f2,f3=0,然后我们代入 θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 \theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3 θ0+θ1f1+θ2f2+θ3f3得 θ 0 + θ 1 = 0.5 > 0 \theta_0+\theta_1=0.5>0 θ0+θ1=0.5>0,所以预测 y = 1 y=1 y=1。

若一个实例如绿点所示,与 l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)},l^{(2)},l^{(3)} l(1),l(2),l(3)的距离都很远,此时 f 1 , f 2 , f 3 = 0 f_1,f_2,f_3=0 f1,f2,f3=0
代入 θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 \theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3 θ0+θ1f1+θ2f2+θ3f3得 θ 0 = − 0.5 < 0 \theta_0=-0.5<0 θ0=−0.5<0,所以预测 y = 0 y= 0 y=0。
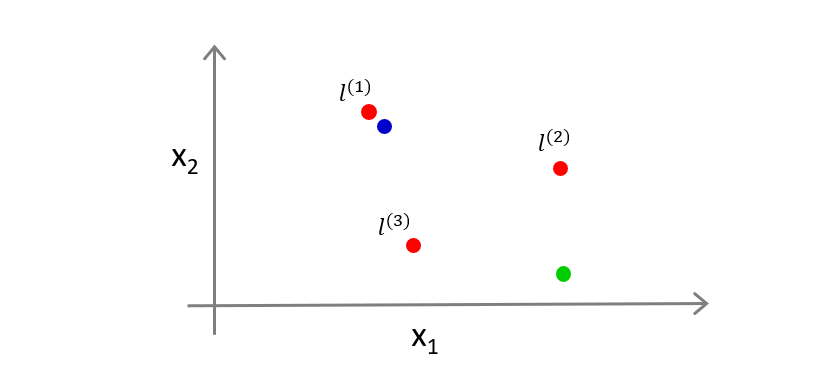
如此,便会得到一个可以区分正负样本的非线性的决策边界。
那么现在大家可能会想如何去得到我们的标记点 l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)},l^{(2)},l^{(3)} l(1),l(2),l(3),并且在一些复杂的分类问题中,也许我们需要更多的标记点。
一般情况下,我们会直接选择训练样本作为标记点。
如下给定 m m m个训练样本,然后选定与 m m m个训练样本完全一样的位置作为标记点。
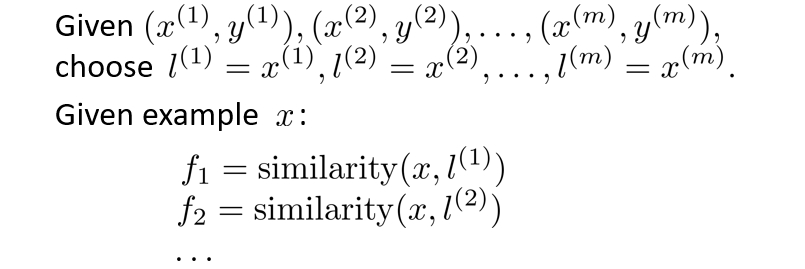
转化为向量:
f = [ f 0 f 1 f 2 f 3 . . . ] ∈ R m + 1 f=\left[ \begin{matrix} f_0 \\ f_1 \\ f_2 \\ f_3\\… \end{matrix} \right]∈R^{m+1} f=⎣⎢⎢⎢⎢⎡f0f1f2f3...⎦⎥⎥⎥⎥⎤∈Rm+1
则当 θ T f ≥ 0 \theta^Tf≥0 θTf≥0时,预测 y = 1 y= 1 y=1.
最小化函数
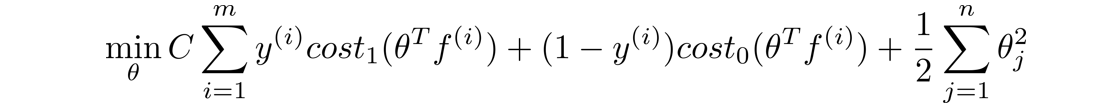
参数选择
-
首先我们看看参数 C C C,前面我们知道 C C C和 1 λ \frac{1}{\lambda} λ1作用一样,如果选择了较大的 C C C,则意味着选择了较大的 λ \lambda λ,则是一个高偏差,低方差的模型(欠拟合)。
如果选择了较小的 C C C,则意味着选择了较小的 λ \lambda λ,则是一个高方差,低偏差的模型(过拟合)。
-
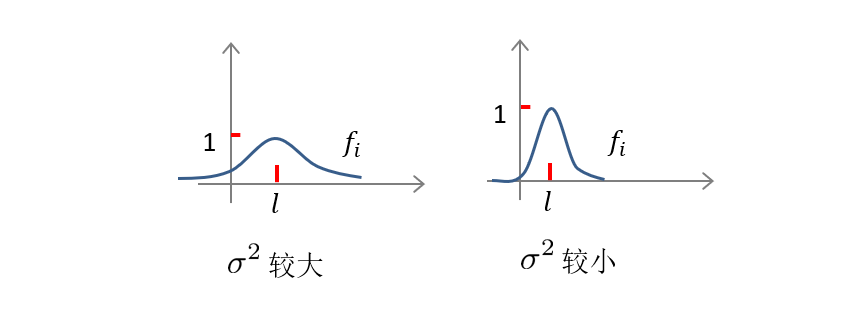
还有一个参数 σ 2 \sigma^2 σ2,如果 σ 2 \sigma^2 σ2比较大,则高斯核函数 e x p ( − ∣ ∣ x − l ( i ) ∣ ∣ 2 2 σ 2 ) exp(-\frac{
{||x-l^{(i)}||}^2}{2\sigma^2}) exp(−2σ2∣∣x−l(i)∣∣2)相对平滑,模型高偏差低方差。反之则相对陡峭,模型低偏差高方差。
例题
在本次代码练习中,我们先从基础的线性分类出发,再到非线性分类来熟悉SVM的工作原理,最后再构建区分垃圾邮件的分类器。
import numpy as np
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
import scipy.io as sio
线性SVM
df = sio.loadmat('E:\\happy\\ML&DL\\My_exercise\\ex5-SVM\\data\\ex6data1.mat')
data = pd.DataFrame(df['X'], columns=['X1', 'X2'])
data['y'] = df['y']
data.head()

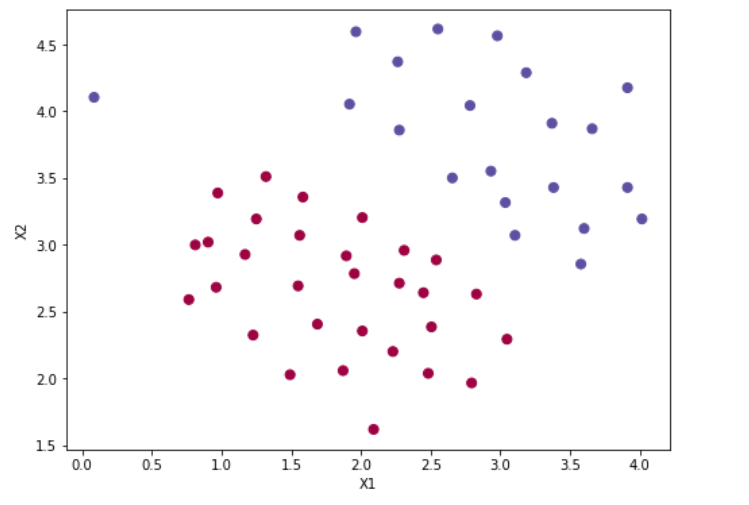
fig = plt.subplots(figsize=(8,6))
plt.scatter(data['X1'], data['X2'], s=50, c=data['y'], cmap='Spectral')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
from sklearn import svm
C=1
#C=1
svc_1 = svm.LinearSVC(C=1, loss='hinge', max_iter=10000)
svc_1.fit(data[['X1', 'X2']], data['y'])
svc_1.score(data[['X1', 'X2']], data['y'])
0.9803921568627451
#C=1时,画图看看每个类别预测的置信度
data['SVM1 Confidence'] = svc_1.decision_function(data[['X1', 'X2']])
data.head()
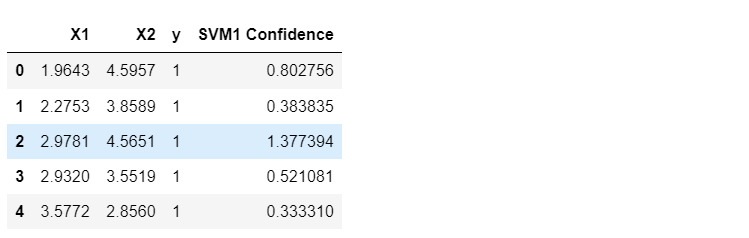
fig = plt.subplots(figsize=(8,6))
plt.scatter(data['X1'], data['X2'], s=50, c=data['SVM1 Confidence'], cmap='RdBu')
plt.title('SVM (C=1) Decision Confidence')
plt.show()
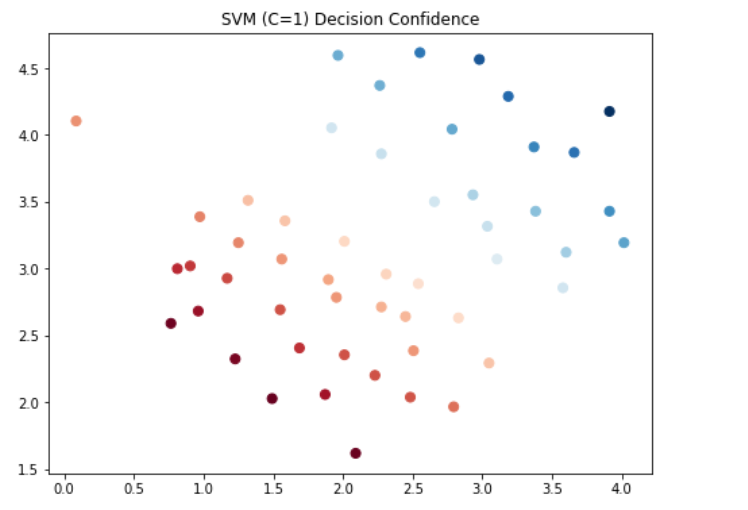
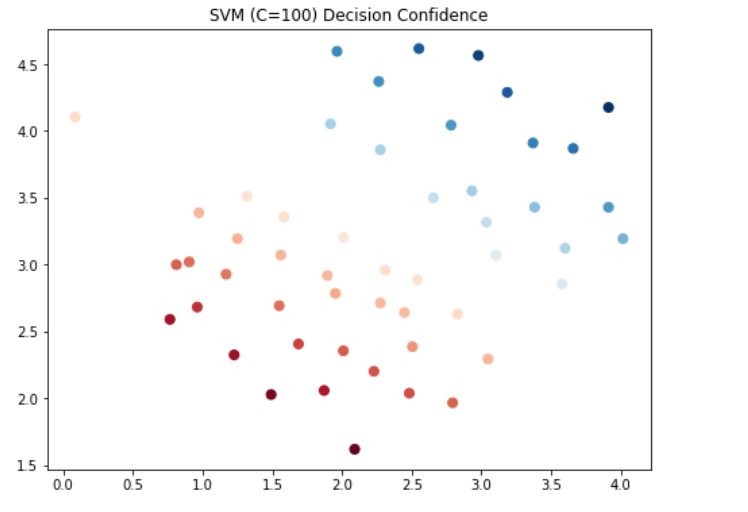
C=100
#C=100时,画图看看每个类别预测的置信度
data['SVM100 Confidence'] = svc_100.decision_function(data[['X1', 'X2']])
fig = plt.subplots(figsize=(8,6))
plt.scatter(data['X1'], data['X2'], s=50, c=data['SVM100 Confidence'], cmap='RdBu')
plt.title('SVM (C=100) Decision Confidence')
plt.show()
非线性SVM
#高斯核函数
def gaussian_kernel(x1, x2, sigma):
return np.exp(-np.power(x1 - x2, 2).sum() / (2 * (sigma ** 2)))
#测试一下
x1 = np.array([1, 2, 3])
x2 = np.array([2, 0, 1])
sigma = 2
gaussian_kernel(x1, x2, sigma)
0.32465246735834974
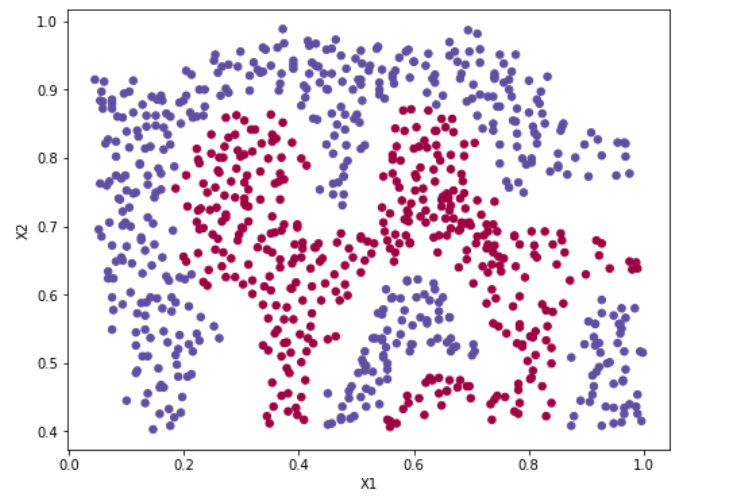
df = sio.loadmat('E:\\happy\\ML&DL\\My_exercise\\ex5-SVM\\data\\ex6data2.mat')
data = pd.DataFrame(df['X'], columns=['X1', 'X2'])
data['y'] = df['y']
data
fig = plt.subplots(figsize=(8,6))
plt.scatter(data['X1'], data['X2'], s=30, c=data['y'], cmap='Spectral')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
#用内置的高斯核函数求解
svc = svm.SVC(C=100, gamma=10, probability=True)
svc.fit(data[['X1', 'X2']], data['y'])
svc.score(data[['X1', 'X2']], data['y'])
0.9698725376593279
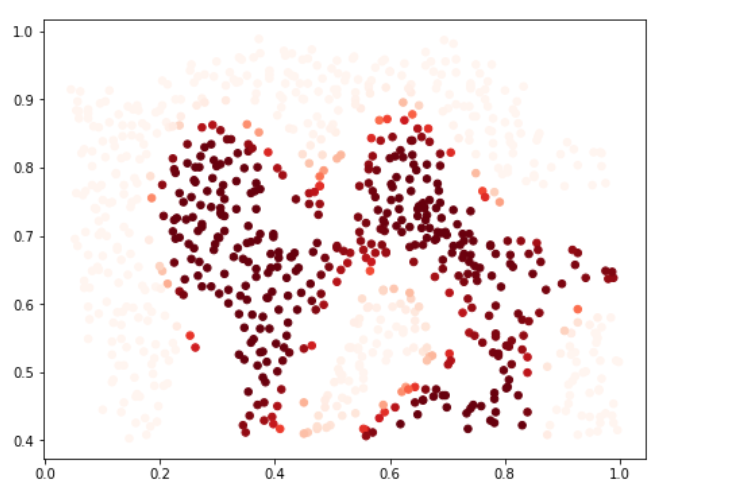
#选一类按照概率画出来
prob = svc.predict_proba(data[['X1', 'X2']])[:, 0]
fig = plt.subplots(figsize=(8,6))
plt.scatter(data['X1'], data['X2'], s=30, c=prob, cmap='Reds')
网络搜索寻找最优参数
#读取训练集和验证集
df = sio.loadmat('E:\\happy\\ML&DL\\My_exercise\\ex5-SVM\\data\\ex6data3.mat')
df.keys()
gamma = 1 2 σ 2 \frac{1}{2\sigma^2} 2σ21
X = df['X']
Xval = df['Xval']
y = df['y']
yval = df['yval']
candidate = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
gamma_values = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30, 100]
best_score = 0
best_params = {
'C': None, 'gamma': None}
for C in candidate:
for gamma in gamma_values:
svc = svm.SVC(C=C, gamma=gamma)
svc.fit(X, y)
score = svc.score(Xval, yval)
if score > best_score:
best_score = score
best_params['C'] = C
best_params['gamma'] = gamma
best_score, best_params
(0.965, {'C': 0.3, 'gamma': 100})
实现垃圾邮件过滤器
train = sio.loadmat('E:\\happy\\ML&DL\\My_exercise\\ex5-SVM\\data\\spamTrain.mat')
test = sio.loadmat('E:\\happy\\ML&DL\\My_exercise\\ex5-SVM\\data\\spamTest.mat')
train.keys(),test.keys()
#X是一个二进制向量,1表示邮件中存在该单词,0表示不存在
X = train['X']
y = train['y'].ravel()
Xtest = test['Xtest']
ytest = test['ytest'].ravel()
svc = svm.SVC()
svc.fit(X, y)
svc.score(Xtest, ytest)
0.987
例题数据和jupyter获取
关注公众号“大拨鼠Code”,回复“机器学习”可领取上面例题的源文件,jupyter版本的,例题和数据也一起打包了,之前的练习也在里面,感谢支持。
参考资料:
[1] https://www.bilibili.com/video/BV164411b7dx
[2] https://github.com/fengdu78/Coursera-ML-AndrewNg-Notes
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184334.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
