大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Up主作为CV穷人代表,这一次想要触碰一下 papers 里最为活跃却又以 “Huge” 令穷人望而生畏的超级数据集: ImageNet 中的 ILSVRC2012.
还记得依靠氪金 “霸道总裁式” 碾压一切 “noise 2 image” 的 BigGAN 吗?
来不及时间解释了,快上车!
## 下载可怜穷人的 BigGAN-4~8 gpus version
>> git clone https://github.com/ajbrock/BigGAN-PyTorch.git
准备数据集及其预处理
http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_test.tar http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_val.tar http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_img_train.tar http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_devkit_t12.tar http://www.image-net.org/challenges/LSVRC/2012/nnoupb/ILSVRC2012_bbox_train_v2.tar这一步是重点,讲述了UP主如何下载整个数据集。
- 首先是通过迅雷下载一些辅助信息(BBox等)和较小的测试集与验证集数据(建议租一个一天会员)(直接复制上面的几个链接);
- 但是到了训练集的 137 个 GB 的时候就不行了,因为用的是内网,强行被限制了网速,所以只好找到一个热心网友的网盘上分享的资源,每个类别对应一个压缩包,共1000个,
## 原来的资源找不到了,这里有个也是一样的 https://pan.baidu.com/s/1hsDmdNI下载完后就是解压了,花了几个小时,写了个脚本(对1000个 .tar 压缩包进行解压缩),
import tarfile import os from tqdm import tqdm if __name__ == '__main__': src_pth = 'xxxxxx/ILSVRC2012_img_train' des_pth = 'xxxxxx/SuperDatasets/Image-Net/ILSVRC2012_img_train' for i in tqdm(range(1000)): dir_name = '%04d' % (i+1) if os.path.exists(os.path.join(des_pth, dir_name)) is not True: os.mkdir(os.path.join(des_pth, dir_name)) tar_file = os.path.join(src_pth, dir_name+'.tar') dir_file = os.path.join(des_pth, dir_name) tar_fh = tarfile.open(tar_file) for f_name in tar_fh.getnames(): tar_fh.extract(f_name, path=dir_file) # 解压到指定文件夹最后得到
好吧确实有点感动♪(^∀^●)ノ
这里的每个子文件夹下都是同一个类别的图像,1000个类别的中英文信息参照这位老哥的博客:imagenet数据集类别标签和对应的英文中文对照表
但实际上我们并不在意具体每一类别指的是什么,只要用0,1,2,…去指代即可。
训练阶段我们只需要在工程目录下新建
data目录,里边再新建ImageNet目录,里边再新建I128目录,即data/ImageNet/I128。这之后将 train 的1000个子目录移动过去。

Anyway,收集完数据后,下面就是预处理了。
- 执行
python make_hdf5.py --dataset I128 --batch_size 128 --data_root data
hdf5 是为了将数据处理成更利于快速 I /O 的格式,类似于在上一篇博客 EDVR-lmdb ;但与 lmdb 不同的是,lmdb 纯碎是存储一个巨大的 dict,而 hdf5 还附带了控制 batch 的功能,简直就是专门为 dataset 而设计的Σ( ° △ °|||)︴- 其中, b a t c h _ s i z e _ o v e r a l l = n u m _ g p u × b a t c h _ s i z e _ p e r _ g p u batch\_size\_overall = num\_gpu \times batch\_size\_per\_gpu batch_size_overall=num_gpu×batch_size_per_gpu
这里的 batch_size 就是 overall 的;作者说,16GB 的单个 VRAM 支持 batch_size_per_gpu 可以是256,所以作者说原始的 BigGAN设置是:
2048 = 256 × 8 2048=256\times 8 2048=256×8- 本穷UP好不容易借到 4 张 1080ti,那就是假设是 8GB ✖ 4, 所以
128 × 4 = 512 128\times 4=512 128×4=512,想想还是算了,就按他给的 256 的一半 128 来吧。
下面我们来看看这样的设置下发生了什么?
经由代码文件
make_hdf5.py, utils.py, datasets.py
我们可以推断出数据集应该这样准备:
'''
/data/ImageNet
├I128 # ImageNet 128x128
│ ├dog
│ │ ├xxx.jpg
│ │ ├xxy.jpg
│ │ ...
│ │ └zzz.jpg
│ ├cat
│ │ ├xxx.jpg
│ │ ...
│ │ ├xxy.jpg
│ │ ...
│ │ └zzz.jpg
│ ...
│ └class_n
│ ├xxx.jpg
│ ...
│ ├xxy.jpg
│ ...
│ └zzz.jpg
├I256 # ImageNet 256x256
...
└XXXX
'''
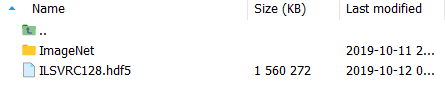
完了后我们应该会得到一个:
data/ImageNet/ILSVRC128.hdf5TIP
我们发现代码里并没有一定要求1000个类别的图像都参与训练,所以我们可以只取其中的一部分类别。那就前 25 类吧,刚好到猫头鹰先生那里,一共也有 32500 张图像。处理就很快了,一分钟不到,生成文件大小是 1.4 GB。
- 执行
python calculate_inception_moments.py --dataset I128_hdf5 --data_root data
这里是为了使用torchvision.models.inception的预训练模型去计算 IS 分数( μ \mu μ 和 σ \sigma σ)

开始训练
python train.py \ --dataset I128_hdf5 \ # which Dataset to train on, out of I128, I256, C10, C100; --parallel --shuffle --num_workers 8 --batch_size 128 \ # for data loader settings --num_G_accumulations 2 --num_D_accumulations 2 \ --num_D_steps 1 --G_lr 1e-4 --D_lr 4e-4 --D_B2 0.999 --G_B2 0.999 \ --G_attn 64 --D_attn 64 \ --G_nl relu --D_nl relu \ --SN_eps 1e-8 --BN_eps 1e-5 --adam_eps 1e-8 \ --G_ortho 0.0 \ --G_init xavier --D_init xavier \ --ema --use_ema --ema_start 2000 --G_eval_mode \ --test_every 2000 --save_every 1000 --num_best_copies 5 --num_save_copies 2 --seed 0 \ --name_suffix SAGAN_ema \UP主的成功设置
UP主后来变成只有两张卡,那就再试试咯,把 b a t c h _ s i z e _ o v e r a l l batch\_size\_overall batch_size_overall 设置成32,最终暂且在两张卡上跑了起来。
CUDA_VISIBLE_DEVICES=0,1 python train.py --dataset I128_hdf5 --parallel --shuffle --num_workers 8 --batch_size 32 --num_G_accumulations 1 --num_D_accumulations 1 --num_D_steps 1 --G_lr 1e-4 --D_lr 4e-4 --D_B2 0.999 --G_B2 0.999 --G_attn 64 --D_attn 64 --G_nl relu --D_nl relu --SN_eps 1e-8 --BN_eps 1e-5 --adam_eps 1e-8 --G_ortho 0.0 --G_init xavier --D_init xavier --ema --use_ema --ema_start 2000 --G_eval_mode --test_every 2000 --save_every 1000 --num_best_copies 5 --num_save_copies 2 --seed 0 --name_suffix SAGAN_ema
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184225.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
