大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
Ann Nowe´, Peter Vrancx, and Yann-Michae¨l De Hauwere
Abstract. Reinforcement Learning was originally developed for Markov Decision Processes (MDPs). It allows a single agent to learn a policy that maximizes a pos- sibly delayed reward signal in a stochastic stationary environment. It guarantees convergence to the optimal policy, provided that the agent can sufficiently experi- ment and the environment in which it is operating is Markovian. However, when multiple agents apply reinforcement learning in a shared environment, this might be beyond the MDP model. In such systems, the optimal policy of an agent depends not only on the environment, but on the policies of the other agents as well. These situa- tions arise naturally in a variety of domains, such as: robotics, telecommunications, economics, distributed control, auctions, traffic light control, etc. In these domains multi-agent learning is used, either because of the complexity of the domain or be- cause control is inherently decentralized. In such systems it is important that agents are capable of discovering good solutions to the problem at hand either by coordi- nating with other learners or by competing with them. This chapter focuses on the application reinforcement learning techniques in multi-agent systems. We describe a basic learning framework based on the economic research into game theory, and illustrate the additional complexity that arises in such systems. We also described a representative selection of algorithms for the different areas of multi-agent rein- forcement learning research.
抽象。强化学习最初是为马尔可夫决策过程(MDP)开发的。它允许单个代理人学习在随机静止环境中最大化可能延迟的奖励信号的策略。它保证了最优政策的收敛,只要代理能够进行充分的实验,并且其运作的环境是马尔可夫。但是,当多个代理在共享环境中应用强化学习时,这可能超出了MDP模型。在这样的系统中,代理的最优策略不仅取决于环境,还取决于其他代理的策略。这些情况自然而然地出现在各种领域,例如:机器人技术,电信,经济学,分布式控制,拍卖,交通灯控制等。在这些领域中,使用多智能体学习,要么是因为域的复杂性或者因为控制本质上是分散的。在这样的系统中,代理人能够通过与其他学习者协调或通过与他们竞争来发现问题的良好解决方案是很重要的。本章重点介绍多代理系统中的应用程序强化学习技术。我们描述了一个基于博弈论经济研究的基本学习框架,并说明了这种系统中出现的额外复杂性。我们还描述了针对多智能体强化学习研究的不同领域的代表性算法选择。
Introduction
The reinforcement learning techniques studied throughout this book enable a single agent to learn optimal behavior through trial-and-error interactions with its environ- ment. Various RL techniques have been developed which allow an agent to optimize its behavior in a wide range of circumstances. However, when multiple learners si- multaneously apply reinforcement learning in a shared environment, the traditional approaches often fail.
In the multi-agent setting, the assumptions that are needed to guarantee conver- gence are often violated. Even in the most basic case where agents share a stationary environment and need to learn a strategy for a single state, many new complexities arise. When agent objectives are aligned and all agents try to maximize the same re- ward signal, coordination is still required to reach the global optimum. When agents have opposing goals, a clear optimal solution may no longer exist. In this case, an equilibrium between agent strategies is usually searched for. In such an equilibrium, no agent can improve its payoff when the other agents keep their actions fixed.
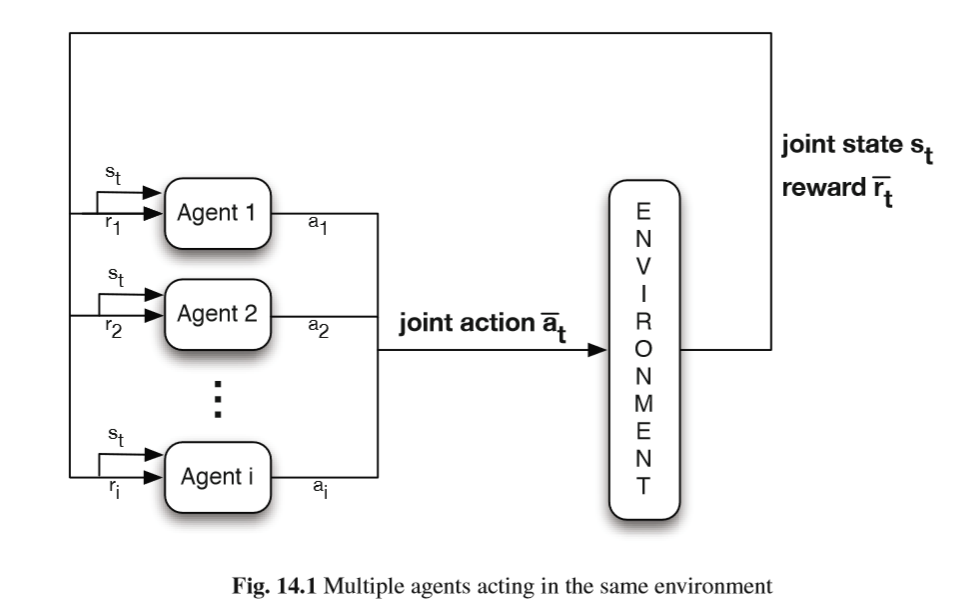
When, in addition to multiple agents, we assume a dynamic environment which requires multiple sequential decisions, the problem becomes even more complex. Now agents do not only have to coordinate, they also have to take into account the current state of their environment. This problem is further complicated by the fact that agents typically have only limited information about the system. In general, they may not be able to observe actions or rewards of other agents, even though these actions have a direct impact on their own rewards and their environment. In the most challenging case, an agent may not even be aware of the presence of other agents, making the environment seem non-stationary. In other cases, the agents have access to all this information, but learning in a fully joint state-action space is in general impractical, both due to the computational complexity and in terms of the coordination required between the agents. In order to develop a successful multi- agent approach, all these issues need to be addressed. Figure 14.1 depicts a standard model of Multi-Agent Reinforcement Learning.
Despite the added learning complexity, a real need for multi-agent systems ex- ists. Often systems are inherently decentralized, and a central, single agent learning approach is not feasible. This situation may arise because data or control is physi- cally distributed, because multiple, possibly conflicting, objectives should be met, or simply because a single centralized controller requires to many resources. Examples of such systems are multi-robot set-ups, decentralized network routing, distributed load-balancing, electronic auctions, traffic control and many others.
The need for adaptive multi-agent systems, combined with the complexities of dealing with interacting learners has led to the development of a multi-agent rein- forcement learning field, which is built on two basic pillars: the reinforcement learn- ing research performed within AI, and the interdisciplinary work on game theory. While early game theory focused on purely competitive games, it has since devel- oped into a general framework for analyzing strategic interactions. It has attracted interest from fields as diverse as psychology, economics and biology. With the ad- vent of multi-agent systems, it has also gained importance within the AI community and computer science in general. In this chapter we discuss how game theory pro- vides both a means to describe the problem setting for multi-agent learning and the tools to analyze the outcome of learning.
本书研究的强化学习技术使单个代理人能够通过与环境的反复试验来学习最佳行为。已经开发了各种RL技术,其允许代理在各种情况下优化其行为。但是,当多个学习者在共享环境中同时应用强化学习时,传统方法通常会失败。
在多智能体环境中,通常会违反保证收敛所需的假设。即使在最基本的情况下,代理人共享一个固定的环境并需要学习单一状态的策略,也会出现许多新的复杂性。当代理目标一致并且所有代理都试图最大化相同的后向信号时,仍然需要协调以达到全局最优。当代理人有相反的目标时,可能不再存在明确的最优解决方案。在这种情况下,通常会搜索代理策略之间的平衡。在这样的均衡中,当其他代理人保持其行动不动时,任何代理人都不能提高其收益。
除了多个代理之外,当我们假设需要多个顺序决策的动态环境时,问题变得更加复杂。现在代理商不仅需要协调,他们还必须考虑到他们环境的当前状态。由于代理通常仅具有关于系统的有限信息,因此该问题进一步复杂化。一般而言,他们可能无法观察其他代理人的行为或奖励,即使这些行为对他们自己的奖励和环境有直接影响。在最具挑战性的情况下,代理商可能甚至不知道其他代理商的存在,使环境看起来不稳定。在其他情况下,代理可以访问所有这些信息,但是由于计算复杂性和代理之间所需的协调,在完全联合的状态 – 动作空间中学习通常是不切实际的。为了开发成功的多代理方法,需要解决所有这些问题。图14.1描绘了多智能体强化学习的标准模型。
尽管增加了学习复杂性,但仍然存在对多代理系统的真正需求。通常,系统本质上是分散的,并且中央的单一代理学习方法是不可行的。出现这种情况可能是因为数据或控制是物理分布的,因为应该满足多个可能相互冲突的目标,或者仅仅因为单个集中控制器需要许多资源。这种系统的示例是多机器人设置,分散式网络路由,分布式负载平衡,电子拍卖,交通控制等等。
对自适应多智能体系统的需求,加上处理相互作用的学习者的复杂性,导致了多智能体强化学习领域的发展,这个领域建立在两个基本支柱上:强化学习研究在AI,以及博弈论的跨学科研究。虽然早期的博弈论主要关注纯粹的竞争性游戏,但它已经发展成为分析战略互动的一般框架。它吸引了心理学,经济学和生物学等多个领域的兴趣。随着多智能体系统的出现,它在人工智能社区和计算机科学中也变得越来越重要。在本章中,我们将讨论博弈论如何提供描述多智能体学习问题设置的方法和分析学习结果的工具。

The multi-agent systems considered in this chapter are characterized by strategic interactions between the agents. By this we mean that the agents are autonomous en- tities, who have individual goals and independent decision making capabilities, but who also are influenced by each other’s decisions. We distinguish this setting from the approaches that can be regarded as distributed or parallel reinforcement learn- ing. In such systems multiple learners collaboratively learn a single objective. This includes systems were multiple agents update the policy in parallel (Mariano and Morales, 2001), swarm based techniques (Dorigo and Stu¨tzle, 2004) and approaches dividing the learning state space among agents (Steenhaut et al, 1997). Many of these systems can be treated as advanced exploration techniques for standard rein- forcement learning and are still covered by the single agent theoretical frameworks, such as the framework described in (Tsitsiklis, 1994). The convergence of the al- gorithms remain valid as long as outdated information is eventually discarded. For example, it allows to use outdated Q-values in the max-operator in the right hand side of standard Q-learning update rule (described in Chapter 1). This is particularly interesting when he Q-values are belonging to to different agents each exploring their own part of the environment and only now and then exchange their Q-values. The systems covered by this chapter, however, go beyond the standard single agent theory, and as such require a different framework.
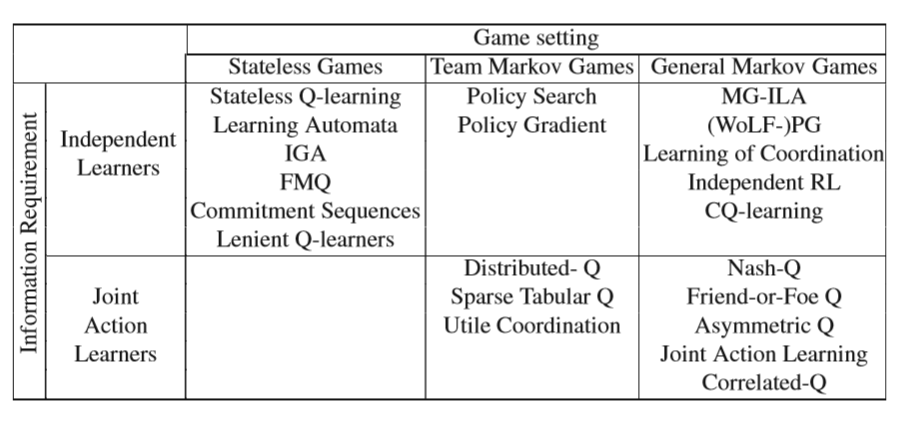
An overview of multi-agent research based on strategic interactions between agents is given in Table 14.1. The techniques listed are categorized based on their
applicability and kind of information they use while learning in a multi-agent sys- tem. We distinguish between techniques for stateless games, which focus on dealing with multi-agent interactions while assuming that the environment is stationary, and Markov game techniques, which deal with both multi-agent interactions and a dy- namic environment. Furthermore, we also show the information used by the agents for learning. Independent learners learn based only on their own reward observation, while joint action learners also use observations of actions and possibly rewards of the other agents.
Table 14.1 Overview of current MARL approaches. Algorithms are classified by their ap- plicability (common interest or general Markov games) and their information requirement (scalar feedback or joint-action information).
本章考虑的多代理系统的特点是代理之间的战略互动。我们的意思是代理人是自治的,他们有个人目标和独立的决策能力,但他们也受到彼此决策的影响。我们将此设置与可被视为分布式或并行强化学习的方法区分开来。在这样的系统中,多个学习者协作地学习单个目标。这包括系统是多个代理并行更新策略(Mariano和Morales,2001),基于群的技术(Dorigo和Stu?tzle,2004)以及在代理之间划分学习状态空间的方法(Steenhaut等,1997)。这些系统中的许多系统可被视为标准加强学习的高级探索技术,并且仍然由单一代理理论框架所涵盖,例如(Tsitsiklis,1994)中描述的框架。只要过时的信息最终被丢弃,算法的收敛仍然有效。例如,它允许在标准Q学习更新规则(在第1章中描述)右侧的max-operator中使用过时的Q值。当他的Q值属于不同的代理人时,这一点特别有趣,每个代理人都在探索他们自己的环境部分,现在只交换他们的Q值。但是,本章涉及的系统超出了标准的单一代理理论,因此需要不同的框架。
表14.1给出了基于代理之间战略相互作用的多智能体研究概述。列出的技术根据它们进行分类
他们在多智能体系统中学习时使用的适用性和信息种类。我们区分无状态游戏的技术,这些技术专注于处理多智能体交互,同时假设环境是静止的,而Markov游戏技术则涉及多智能体交互和动态环境。此外,我们还会显示代理商用于学习的信息。独立学习者仅根据自己的奖励观察进行学习,而联合行动学习者也使用行动观察和其他行动者的奖励。
表14.1当前MARL方法概述。算法根据其适用性(共同兴趣或一般马尔可夫游戏)及其信息要求(标量反馈或联合行动信息)进行分类。
In the following section we will describe the repeated games framework. This setting introduces many of the complexities that arise from interactions between learning agents. However, the repeated game setting only considers static, stateless environments, where the learning challenges stem only from the interactions with other agents. In Section 14.3 we introduce Markov Games. This framework gen- eralizes the Markov Decision Process (MDP) setting usually employed for single agent RL. It considers both interactions between agents and a dynamic environment. We explain both value iteration and policy iteration approaches for solving these Markov games. Section 14.4 describes the current state of the art in multi-agent re- search, which takes the middle ground between independent learning techniques and Markov game techniques operating in the full joint-state joint-action space. Finally in Section 14.5, we shortly describe other interesting background material.
在下一节中,我们将描述重复的游戏框架。 此设置介绍了学习代理之间交互所产生的许多复杂性。 然而,重复的游戏设置仅考虑静态的无状态环境,其中学习挑战仅源于与其他代理的交互。 在14.3节中,我们介绍马尔可夫游戏。 该框架通常用于单个代理RL的马尔可夫决策过程(MDP)设置。 它考虑了代理和动态环境之间的相互作用。 我们解释了用于解决这些马尔可夫游戏的价值迭代和政策迭代方法。 第14.4节描述了多智能体研究中的当前技术水平,它在独立学习技术和在完整的联合状态联合作用空间中运行的马尔可夫游戏技术之间取得了中间地位。 最后在第14.5节中,我们将简要介绍其他有趣的背景资料。
14.2Repeated Games
14.2.1Game Theory
The central idea of game theory is to model strategic interactions as a game between a set of players. A game is a mathematical object, which describes the consequences of interactions between player strategies in terms of individual payoffs. Different representations for a game are possible. For example,traditional AI research often focusses on the extensive form games, which were used as a representation of situa- tions where players take turns to perform an action. This representation is used, for instance, with the classical minimax algorithm (Russell and Norvig, 2003). In this chapter, however, we will focus on the so called normal form games, in which game players simultaneously select an individual action to perform. This setting is often used as a testbed for multi-agent learning approaches. Below we the review basic game theoretic terminology and define some common solution concepts in games.
博弈论的核心思想是将战略互动模型化为一组参与者之间的博弈。 游戏是一个数学对象,它描述了玩家策略之间在个人收益方面的交互的后果。 可以对游戏进行不同的表示。 例如,传统的人工智能研究通常侧重于广泛的形式游戏,这些游戏被用来表示玩家轮流执行动作的情境。 例如,该表示用于经典的minimax算法(Russell和Norvig,2003)。 然而,在本章中,我们将关注所谓的普通形式游戏,其中游戏玩家同时选择要执行的个人动作。 此设置通常用作多代理学习方法的测试平台。 下面我们回顾一下基本的游戏理论术语,并在游戏中定义一些常见的解决方案概念。
14.2.1.1Normal Form Games
Definition 14.1. A normal form game is a tuple (n,A1,…,n,R1,…,n), where
•1,… , n is a collection of participants in the game, called players;
•Ak is the individual (finite) set of actions available to player k;
•Rk : A1 × …× An → R is the individual reward function of player k, specifying the expected payoff he receives for a play a ∈ A1 × …× An.
A game is played by allowing each player k to independently select an individual action a from its private action set Ak.The combination of actions of all players
constitute a joint action or action profile a from the joint action set A = A1 … An. For each joint action a A, Rk(a) denotes agent k’s expected payoff.
Normal form games are represented by their payoff matrix. Some typical 2-player
games are given in Table 14.2. In this case the action selected by player 1 refers to a row in the matrix, while that of player 2 determines the column. The corresponding entry in the matrix then gives the payoffs player 1 and player 2 receive for the play. Players 1 and 2 are also referred to as the row and the column player, respectively. Using more dimensional matrices n-player games can be represented where each entry in the matrix contains the payoff for each of the agents for the corresponding combination of actions.
通过允许每个玩家k从其私人动作集Ak中独立地选择个体动作a来玩游戏。所有玩家的动作的组合
从联合行动集A = A1 … An构成联合行动或行动概况a。 对于每个联合行动,A,Rk(a)表示代理人k的预期收益。
普通形式的游戏由其支付矩阵表示。 一些典型的2人游戏
表14.2给出了游戏。 在这种情况下,由玩家1选择的动作引用矩阵中的行,而玩家2的动作确定该列。 矩阵中的相应条目然后给予支付玩家1和玩家2接收该游戏。 玩家1和2也分别被称为行和列播放器。 使用更多维度矩阵可以表示n个玩家游戏,其中矩阵中的每个条目包含针对相应的动作组合的每个代理的支付。


14.2.1.2Types of Games
Depending on the reward functions of the players, a classifications of games can be made. When all players share the same reward function, the game is called a identical payoff or common interest game. If the total of all players rewards adds up to 0 the game is called a zero-sum game. In the latter games wins for certain players translate to losses for other players with opposing goals. Therefore these games are also referred to as pure competitive games. When considering games without special restrictions we speak of general sum games.
Table 14.2 Examples of 2-player, 2-action games. From left to right: (a) Matching pennies, a purely competitive (zero-sum) game. (b) The prisoner’s dilemma, a general sum game. © The coordination game, a common interest (identical payoff) game. (d) Battle of the sexes, a coordination game where agents have different preferences) Pure Nash equilibria are indi- cated in bold.
根据玩家的奖励功能,可以进行游戏分类。 当所有玩家共享相同的奖励功能时,该游戏被称为相同的支付或共同兴趣游戏。 如果所有玩家奖励的总和加起来为0,则该游戏称为零和游戏。 在后一场比赛中,某些球员的胜利会转化为其他有相反目标球员的失利。 因此,这些游戏也被称为纯竞争游戏。 在考虑没有特殊限制的游戏时,我们会谈到一般的游戏。
表14.2 2人2动作游戏的示例。 从左到右:(a)匹配便士,纯粹竞争(零和)游戏。 (b)囚犯的困境,一般的游戏。 (c)协调游戏,共同利益(相同的支付)游戏。 (d)性别之战,代理人有不同偏好的协调游戏)纯纳什均衡以粗体表示。
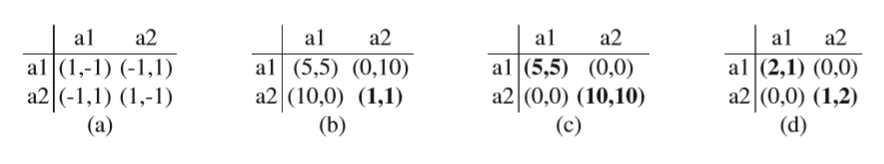
Examples of these game types can be seen in Table 14.2. The first game in this table, named matching pennies, is an example of a strictly competitive game. This game describes a situation where the two players must each, individually, select one side of a coin to show (i.e. Heads or Tails). When both players show the same side, player one wins and is paid 1 unit by player 2. When the coins do not match, player 2 wins and receives 1 unit from player 1. Since both players are betting against each other, one player’s win automatically translates in the other player’s loss, therefore this is a zero-sum game.
The second game in Table 14.2, called the prisoner’s dilemma, is a general sum game. In this game, 2 criminals have been apprehended by the police for commit- ting a crime. They both have 2 possible actions: cooperate with each other and deny the crime (action a1), or defect and betray the other, implicating him in the crime (action a2). If both cooperate and deny the crime, the police have insufficient evi- dence and they get a minimal sentence, which translates to a payoff of 5 for both. If one player cooperates, but the other one defects, the cooperator takes all the blame
(payoff 0), while the defector escapes punishment (payoff 10). Should both play- ers defect, however, they both receive a large sentence (payoff 1). The issue in this game is that the cooperate action is strictly dominated by the defect action: no mat- ter what action the other player chooses, to defect always gives the highest payoff. This automatically leads to the (defect, defect) outcome, despite the fact that both players could simultaneously do better by both playing cooperate.
The third game in Table 14.2 is a common interest game. In this case both players receive the same payoff for each joint action. The challenge in this game is for the players to coordinate on the optimal joint action. Selecting the wrong joint action gives a sub optimal payoff and failing to coordinate results in a 0 payoff.
The fourth game, Battle of the sexes, is another example of a coordination game. Here however, the players get individual rewards and prefer different outcomes. Agent 1 prefers (a1,a1), whereas agent 2 prefers (a2,a2). In addition to the coor- dination problem, the players now also have to agree on which of the preferred outcomes.
Of course games are not restricted to only two actions but can have any number of actions. In Table 14.3 we show some 3-action common interest games. In the first, the climbing game from (Claus and Boutilier, 1998), the Nash equilibria are surrounded by heavy penalties. In the second game, the penalties are left as a param- eter k < 0. The smaller k, the more difficult it becomes to agree through learning on the preferred solution ((a1,a1) and (a3,a3)) (The dynamics of these games us- ing a value-iteration approach are analyzed in (Claus and Boutilier, 1998), see also Section 14.2.2).
这些游戏类型的例子见表14.2。这张表中的第一款游戏名为匹配便士,是一款严格竞争游戏的例子。该游戏描述了这样的情况:两个玩家必须各自单独地选择硬币的一侧来显示(即头或尾)。当两个玩家显示相同的一方时,玩家1获胜并由玩家2支付1个单位。当硬币不匹配时,玩家2获胜并从玩家1获得1个单位。由于两个玩家互相投注,一个玩家的胜利自动翻译其他玩家的损失,因此这是一个零和游戏。
表14.2中的第二场比赛被称为囚徒困境,是一场总和比赛。在这场比赛中,2名罪犯因犯罪而被警方逮捕。他们都有两种可能的行动:相互合作并否认犯罪(行动a1),或叛逃并背叛另一方,将他牵连到犯罪中(行动a2)。如果双方合作并否认犯罪,警方就没有足够的证据,他们会得到最低限度的判决,这意味着两者的回报都是5。如果一个玩家合作,但另一个玩家缺陷,合作者就会承担全部责任
(支付0),而叛逃者逃脱惩罚(收益10)。然而,如果两个玩家都有缺陷,他们都会收到一个大句子(收益1)。这个游戏中的问题是合作行为严格地受到缺陷行为的支配:无论其他玩家选择什么动作,缺陷总是给出最高的回报。这会自动导致(缺陷,缺陷)结果,尽管两个玩家可以同时通过合作来做得更好。
表14.2中的第三个游戏是一个共同的兴趣游戏。在这种情况下,两个玩家都会获得与每个联合行动相同的回报。这场比赛的挑战是让球员协调最佳的联合动作。选择错误的联合动作会给出次优的支付,并且无法协调结果以获得0。
第四场比赛,性别之战,是协调游戏的另一个例子。然而,在这里,球员获得个人奖励并且喜欢不同的结果。代理1优选(a1,a1),而代理2优选(a2,a2)。除了协调问题,球员现在还必须就哪些首选结果达成一致。
当然,游戏不仅限于两个动作,而且可以有任意数量的动作。在表14.3中,我们展示了一些3动作共同兴趣游戏。在第一场比赛(克劳斯和布比里耶,1998年)的攀登比赛中,纳什均衡被重罚所包围。在第二个游戏中,惩罚留给参数k <0。k越小,通过学习首选解((a1,a1)和(a3,a3))就越难达成一致(The使用价值迭代方法对这些游戏的动态进行了分析(Claus and Boutilier,1998),另见第14.2.2节)。
Table 14.3 Examples of 2-player, 3-action games. From left to right: (a) Climbing game (b) The penalty game, where k<=0. Both games are of the common interest type. Pure Nash equilibria are indicated in bold.
表14.3 2人3动作游戏的示例。 从左到右:(a)攀爬游戏(b)惩罚游戏,其中k <= 0。 这两种游戏都是共同感兴趣的类型。 纯纳什均衡以粗体表示。

Solution Concepts in Games
Since players in a game have individual reward functions which are dependent on the actions of other players, defining the desired outcome of a game is often not clearcut.One cannot simply
expect participants to maximize their payoffs,as it may not be possible for all players to achieve this goal at the same time. See for example the Battle of the sexes game in Table 14.2(d).
An important concept for such learning situations, is that of a best response. When playing a best response, a player maximizes his payoff with respect to the current strategies of his opponents in the game. That is, it is not possible for the player to improve his reward if the other participants in the game keep their strategies fixed. Formally,we can define this concept as follows:
由于游戏中的玩家具有依赖于其他玩家行为的个人奖励功能,因此定义游戏的期望结果通常并不明确。一个不能简单
期望参与者最大化他们的回报,因为所有玩家可能无法同时实现这一目标。 参见表14.2(d)中的性别之战。
这种学习情境的一个重要概念是最佳反应。 在播放最佳响应时,玩家可以根据游戏中对手的当前策略最大化他的回报。 也就是说,如果游戏中的其他参与者保持他们的策略固定,则玩家不可能提高他的奖励。 在形式上,我们可以将这个概念定义如下:
Definition 14.2.

A central solution concept in games, is the Nash equilibrium (NE). In a Nash equilibrium,the players all play mutualbes treplies, meaning that each player uses a best response to the current strategies of the other players. Nash(Nash,1950)proved that every normal form game has at least 1 Nash equilibrium, possibly in mixed strategies. Based on the concept of best response we can define a Nash equilibriumas:
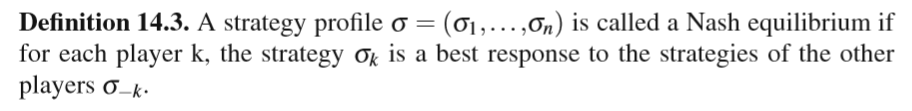
Thus, when playing a Nash equilibrium, no player in the game can improve his payoff by unilaterally deviating from the equilibrium strategy profile. As such no player has an incentive to change his strategy, and multiple players have to change their strategy simultaneously in order to escape the Nash equilibrium.
In common interest games such as the coordination in Table 14.2©, the Nash equilibrium corresponds to a local optimum for all players, but it does not necessar- ily correspond to the global optimum. This can clearly be seen in the coordination game, where we have 2 Nash equilibria: the play (a1,a1) which gives both players
a reward of 5 and the global optimum (a2,a2) which results in a payoff of 10.
The prisoner’s dilemma game in Table 14.2 shows that a Nash equilibrium does
not necessarily correspond to the most desirable outcome for all agents. In the unique Nash equilibrium both players prefer the ’defect’ action, despite the fact that both would receive when both are cooperating. The cooperative outcome is not a Nash equilibrium, however, as in this case both players can improve their payoff by switching to the ’defect’ action.
The first game, matching pennies, does not have a pure strategy Nash equilib- rium, as no pure strategy is a best response to another pure best response. Instead the Nash equilibrium for this game is for both players to choose both sides with equal probability. That is, the Nash strategy profile is ((1/2,1/2),(1/2,1/2)).
因此,当玩纳什均衡时,游戏中的任何玩家都不能通过单方面偏离均衡策略概况来提高他的收益。因此,没有球员有动力改变他的策略,并且多个球员必须同时改变他们的策略以逃避纳什均衡。
在共同感兴趣的游戏中,例如表14.2(c)中的协调,纳什均衡对应于所有参与者的局部最优,但它并不一定对应于全局最优。在协调游戏中可以清楚地看到这一点,我们有2个纳什均衡:游戏(a1,a1)给予两个玩家
奖励5和全局最优(a2,a2),结果为10。
表14.2中的囚徒困境游戏表明纳什均衡确实如此
不一定对应于所有代理人最理想的结果。在独特的纳什均衡中,两位球员都喜欢“缺陷”动作,尽管两者都在合作时会收到。然而,合作结果不是纳什均衡,因为在这种情况下,两个参与者都可以通过切换到“缺陷”行为来改善他们的收益。
第一款匹配便士的游戏并没有纯粹的战略纳什均衡,因为没有纯策略是对另一种纯粹最佳反应的最佳回应。相反,这场比赛的纳什均衡是让两位球员以相同的概率选择双方。也就是说,纳什战略概况是((1 / 2,1 / 2),(1 / 2,1 / 2))。
14.2.2 Reinforcement Learning in Repeated Games
The games described above are often used as test cases for multi-agent reinforce- ment learning techniques. Unlike in the game theoretical setting, agents are not as- sumed to have full access to the payoff matrix. In the reinforcement learning setting, agents are taken to be players in a normal form game, which is played repeatedly, in order to improve their strategy over time.
It should be noted that these repeated games do not yet capture the full multi- agent reinforcement learning problem. In a repeated game all changes in the ex- pected reward are due to changes in strategy by the players. There is no changing environment state or state transition function external to the agents. Therefore, re- peated games are sometimes also referred to as stateless games. Despite this lim- itation, we will see further in this section that these games can already provide a challenging problem for independent learning agents, and are well suited to test coordination approaches. In the next section, we will address the Markov game framework which does include a dynamic environment.
A number of different considerations have to be made when dealing with rein- forcement learning in games. As is common in RL research, but contrary to tradi- tional economic game theory literature, we assume that the game being played is initially unknown to the agents, i.e. agents do not have access to the reward function and do not know the expected reward that will result from playing a certain (joint) action. However, RL techniques can still differ with respect to the observations the agents make. Moreover, we also assume that the game payoffs can be stochastic, meaning that a joint action does not always result in the same deterministic reward for each agent. Therefore, actions have to be sampled repeatedly.
Since expected rewards depend on the strategy of all agents, many multi-agent RL approaches assume that the learner can observe the actions and/or rewards of all participants in the game. This allows the agent to model its opponents and to explicitly learn estimates over joint actions. It could be argued however, that this assumption is unrealistic, as in multi-agent systems which are physically distributed this information may not be readily available. In this case the RL techniques must be able to deal with the non-stationary rewards caused by the influence of the other agents. As such, when developing a multi-agent reinforcement learning application it is important to consider the information available in a particular setting in order to match this setting with an appropriate technique.
上述游戏通常用作多智能体强化学习技术的测试用例。与游戏理论设置不同,代理商不被认为可以完全访问支付矩阵。在强化学习设置中,代理被视为正常形式游戏中的玩家,其被重复播放,以便随着时间改进他们的策略。
应该注意的是,这些重复的游戏尚未捕获完整的多智能体强化学习问题。在重复游戏中,预期奖励的所有变化都是由于玩家的策略变化。代理外部没有变化的环境状态或状态转换功能。因此,重复游戏有时也被称为无国界游戏。尽管有这种限制,我们将在本节中进一步看到,这些游戏已经为独立学习代理提供了一个具有挑战性的问题,并且非常适合测试协调方法。在下一节中,我们将讨论包含动态环境的Markov游戏框架。
在处理游戏中的强制学习时,必须考虑许多不同的因素。正如在RL研究中常见的那样,但与传统的经济博弈论文献相反,我们假设正在玩的游戏最初是代理人所不知道的,即代理人无法获得奖励功能,也不知道预期的奖励。将通过某种(联合)动作产生。然而,RL技术在代理人所做的观察方面仍然可能不同。此外,我们还假设游戏支付可以是随机的,这意味着联合行动并不总是为每个代理产生相同的确定性奖励。因此,必须重复采样动作。
由于预期的奖励取决于所有代理的策略,因此许多多代理RL方法假设学习者可以观察游戏中所有参与者的动作和/或奖励。这允许代理人对其对手进行建模并明确地学习对联合行动的估计。然而,可以说,这种假设是不现实的,因为在物理上分布的多代理系统中,这些信息可能不容易获得。在这种情况下,RL技术必须能够处理由其他代理的影响引起的非固定奖励。因此,在开发多智能体强化学习应用程序时,重要的是要考虑特定设置中可用的信息,以便将此设置与适当的技术相匹配。
14.2.2.1 Goals of Learning
Since it is in general impossible for all players in a game to maximize their pay- off simultaneously, most RL methods attempt to achieve Nash equilibrium play. However, a number of criticisms can be made of the Nash equilibrium as a solu- tion concept for learning methods. The first issue is that Nash equilibria need not be unique, which leads to an equilibrium selection problem. In general, multiple Nash equilibria can exist for a single game. These equilibria can also differ in the
payoff they give to the players. This means that a method learning Nash equilibria, cannot guarantee a unique outcome or even a unique payoff for the players. This can be seen in the coordination game of Table 14.2©, where 2 Nash equilibria ex-
ist, one giving payoff 5 to the agents, and the other giving payoff 10. The game in Table 14.3(b) also has multiple NE, with (a1,a1) and (a3,a3) being the 2 optimal ones. This results in a coordination problem for learning agents, as both these NE have the same quality.
Furthermore, since the players can have different expected payoffs even in an equilibrium play, the different players may also prefer different equilibrium out- comes, which means that care should be taken to make sure the players coordinate on a single equilibrium. This situation can be observed in the Battle of the sexes game in Table 14.2(d), where 2 pure Nash equilibria exist, but each player prefers a different equilibrium outcome.
Another criticism is that a Nash Equilibrium does not guarantee optimality. While playing a Nash equilibrium assures that no single player can improve his payoff by unilaterally changing its strategy, it does not guarantee that the players globally maximize their payoffs, or even that no play exists in which the players si- multaneously do better. It is possible for a game to have non-Nash outcomes, which nonetheless result in a higher payoff to all agents than they would receive for play- ing a Nash equilibrium. This can be seen for example in the prisoner’s dilemma in Table 14.2©.
While often used as the main goal of learning, Nash equilibria are not the only possible solution concept in game theory. In part due to the criticisms mentioned above, a number of alternative solution concepts for games have been developed. These alternatives include a range of other equilibrium concepts, such as the Cor- related Equilibrium(CE))(Aumann, 1974), which generalizes the Nash equilibrium concept, or the Evolutionary Stable Strategy (ESS)(Smith, 1982), which refines the Nash equilibrium. Each of these equilibrium outcomes has its own applications and (dis)advantages. Which solution concept to use depends on the problem at hand, and the objective of the learning algorithm. A complete discussion of possible equilib- rium concepts is beyond the scope of this chapter. We focus on the Nash equilibrium and briefly mention regret minimization as these are the approaches most frequently observed in the multi-agent learning literature. A more complete discussion of so- lution concepts can be found in many textbooks, e.g. (Leyton-Brown and Shoham, 2008).
Before continuing, we mention one more evaluation criterion, which is regularly used in repeated games: the notion of regret. Regret is the difference between the payoff an agent realized and the maximum payoff the agent could have obtained using some fixed strategy. Often the fixed strategies that one compares the agent performance to, are simply the pure strategies of the agent. In this case, the total regret of the agent is the accumulated difference between the obtained reward and the reward the agent would have received for playing some fixed action. For an agent k, given the history of play at time T , this is defined as:
由于游戏中的所有玩家通常不可能同时最大化他们的回报,因此大多数RL方法试图实现纳什均衡游戏。然而,可以对纳什均衡作为学习方法的解决方案概念提出一些批评。第一个问题是纳什均衡不必是唯一的,这导致了均衡选择问题。通常,单个游戏可以存在多个纳什均衡。这些均衡也可能有所不同
他们给予球员的回报。这意味着学习纳什均衡的方法无法保证球员的独特结果甚至是独特的回报。这可以在表14.2(c)的协调博弈中看到,其中2纳什均衡
ist,一个给代理人支付5,另一个给予支付10.表14.3(b)中的游戏也有多个NE,其中(a1,a1)和(a3,a3)是2个最优的NE。这导致学习代理的协调问题,因为这两个NE具有相同的质量。
此外,由于即使在均衡比赛中球员也可以有不同的预期收益,不同的球员也可能更喜欢不同的均衡结果,这意味着应该注意确保球员在单一均衡上协调。这种情况可以在表14.2(d)中的性别比赛中观察到,其中存在2个纯纳什均衡,但每个参与者更喜欢不同的均衡结果。
另一个批评是纳什均衡并不能保证最优性。虽然玩纳什均衡确保没有一个玩家可以通过单方面改变策略来提高他的回报,但并不能保证球员在全球范围内最大化他们的回报,甚至不能保证球员同时做得更好。游戏有可能具有非纳什结果,但这会导致所有代理人获得比获得纳什均衡所获得的更高的回报。例如,可以在表14.2(c)中的囚徒困境中看到这一点。
虽然经常被用作学习的主要目标,但纳什均衡并不是博弈论中唯一可行的解决方案概念。部分由于上面提到的批评,已经开发了许多用于游戏的替代解决方案概念。这些替代方案包括一系列其他均衡概念,例如Cor-相关均衡(CE)(Aumann,1974),它概括了纳什均衡概念,或进化稳定策略(ESS)(Smith,1982),它提炼出来。纳什均衡。这些均衡结果中的每一个都有其自身的应用和(不)优势。使用哪种解决方案概念取决于手头的问题以及学习算法的目标。关于可能的平衡概念的完整讨论超出了本章的范围。我们关注纳什均衡并简要提及后悔最小化,因为这些是多智能体学习文献中最常见的方法。关于解决方案概念的更完整的讨论可以在许多教科书中找到,例如(Leyton-Brown和Shoham,2008)。
在继续之前,我们再提一个评估标准,这个标准经常用于重复游戏:遗憾的概念。后悔是代理人实现的回报与代理人使用某种固定策略可以获得的最大回报之间的差异。通常,将代理性能与之比较的固定策略只是代理的纯策略。在这种情况下,代理人的总后悔是获得的奖励与代理人为播放某些固定动作而获得的奖励之间的累积差异。对于代理k,给定时间T的游戏历史,这被定义为:
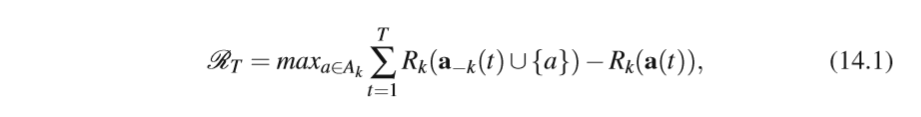
where a(t) denotes the joint action played at time t and a k(t) a denotes the same joint action but with player k playing action a. Most regret based learning approaches attempt to minimize the average regret RT /T of the learner. Exact cal- culation of this regret requires knowledge of the reward function and observation of the actions of other agents in order to determine the Rk(a k(t) a ) term. If this information is not available, regret has to be estimated from previous observations. Under some assumptions regret based learning can been shown to converge to some
form of equilibrium play (Foster and Young, 2003; Hart and Mas-Colell, 2001).
其中a(t)表示在时间t播放的联合动作,而k(t)a表示相同的联合动作,但是玩家k表演动作a。 大多数基于后悔的学习方法试图最小化学习者的平均后悔RT / T. 对这种遗憾的精确计算需要了解奖励函数和观察其他代理人的行为以确定Rk(a k(t)a)项。 如果没有这方面的信息,则必须根据先前的意见估计遗憾。 根据一些假设,基于遗憾的学习可以显示出与某些人相关
平衡游戏的形式(Foster和Young,2003; Hart和Mas-Colell,2001)。
14.2.2.2 Q-Learning in Games
A natural question to ask is what happens when agents use a standard, single-agent RL technique to interact in a game environment. Early research into multi-agent RL focussed largely on the application of Q-learning to repeated games. In this so called independent or uninformed setting, each player k keeps an individual vector
of estimated Q-values Qk(a), a Ak. The players learn Q-values over their own action set and do not use any information on other players in the game. Since there
is no concept of environment state in repeated games, a single vector of estimates is sufficient, rather than a full table of state-action pairs, and the standard Q-learning update is typically simplified to its stateless version:
一个自然要问的问题是当代理使用标准的单代理RL技术在游戏环境中进行交互时会发生什么。 早期对多智能体RL的研究主要集中在Q学习在重复游戏中的应用。 在这种所谓的独立或不知情的设置中,每个玩家k保持单独的向量
估计的Q值Qk(a),Ak。 玩家通过他们自己的动作集学习Q值,并且不使用游戏中其他玩家的任何信息。 从那里
在重复博弈中没有环境状态的概念,单个估计向量就足够了,而不是完整的状态 – 动作对表格,标准的Q学习更新通常简化为无状态版本:
Q(a)←Q(a)+ α [r(t)−Q(a)]
In (Claus and Boutilier, 1998) the dynamics of stateless Q-learning in repeated nor- mal form common interest games are empirically studied.The key questions here are: is simple Q-learning still guaranteed to converge in a multi-agent setting, and if so, does it converge to (the optimal) equilibrium. It also relates independent Q- learners to joint action learners (see below) and investigates how the rates of con- vergence and limit points are influenced by the game structures and action selection strategies. In a related branch of research (Tuyls and Nowe´, 2005; Wunder et al, 2010) the dynamics of independent Q-learning are studied using techniques from evolutionary game theory (Smith, 1982).
While independent Q-learners were shown to reach equilibrium play under some circumstances, they also demonstrated a failure to coordinate in some games, and even failed to converge altogether in others.
They compared joint action learners to independent learners. In the former the agents learn Q-values for all joint actions, with other words each agent j leans a Q- value for all a in A. The action selection is done by each agent individually based on the believe the agents has about the other agents strategy. Equation 14.3 expresses that the Q-value of the joint action is weighted according to the probability the other agents will select some particular value. The Expected Values (EV) can then be used in combination with any action selection technique. Claus and Boutilier showed
experimentally using the games of table 2, that joint action learners and independent learners using a Boltzmann exploration strategy with decreasing temperature behave very similar. These learners have been studied from an evolutionary game theory point of view in (Tuyls and Nowe´, 2005) and is has been shown that these learners will converge to evolutionary stable NE which are not necessarily pareto optimal.
在(Claus和Boutilier,1998)中,重复正态形式共同兴趣博弈的无状态Q学习的动态是经验研究。这里的关键问题是:简单的Q学习仍然保证在多智能体环境中收敛,如果是这样,它会收敛到(最佳)均衡。它还将独立的Q-学习者与联合行动学习者(见下文)联系起来,并研究如何通过游戏结构和行动选择策略来影响收敛率和限制点。在相关的研究分支(Tuyls和Nowe,2005; Wunder等,2010)中,使用进化博弈论(Smith,1982)的技术研究了独立Q学习的动态。
虽然独立的Q-学习者在某些情况下表现出达到平衡,但他们也表现出在某些游戏中未能协调,甚至未能在其他游戏中完全融合。
他们将联合行动学习者与独立学习者进行了比较。在前者中,代理人学习所有联合行动的Q值,换句话说,每个代理j都倾向于A中所有a的Q值。行动选择由每个代理根据代理人对另一个的相信来单独完成。代理人战略。公式14.3表示联合行动的Q值是根据其他代理人选择某个特定值的概率加权的。然后可以将预期值(EV)与任何动作选择技术结合使用。 Claus和Boutilier表示
通过实验使用表2的游戏,使用玻璃体温度降低的玻尔兹曼探索策略的联合行动学习者和独立学习者表现得非常相似。这些学习者已经从进化博弈理论的角度进行了研究(Tuyls和Nowe,2005),并且已经证明这些学习者将会聚到进化稳定的NE,这不一定是帕累托最优的。
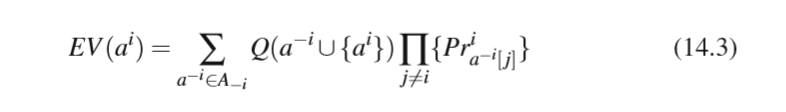
However the learners have difficulties to reach the optimal NE, and more sophis- ticated exploration strategies are needed to increase the probability of converging to the optimal NE. The reason that simple exploration strategies are not sufficient is mainly due to the fact that the actions involved in the optimal NE often lead to much lower payoff when combined with other actions, the potential quality of the action is therefore underestimated. For example in game 2a the action a1 of the row player, will only lead to the highest reward 11 when combined with action a1 of the column player. During the learning phase, agents are still exploring and action a1 will also be combined with actions a2 and a3. As a results the agents will often settle for the more “safe” NE (a2,a2). A similar behavior is observed in game 2b, since miscoordination on the 2 NE is punished, the bigger the penalty (k¡0) the more dif- ficult it become for the agents to reach either of the optimal NE. This also explains why independent learners are generally not able to converge to a NE when they are allowed to use any, including a random exploration strategy. Whereas in sin- gle agent Q-learning, the particular exploration strategy does not affect the eventual convergence (Tsitsiklis, 1994) this no longer holds in a MAS setting.
The limitations of single-agent Q-learning have lead to a number of extensions of the Q-learning algorithm for use in repeated games. Most of these approaches fo- cus on coordination mechanisms allowing Q-learners to reach the optimal outcome in common interest games. The frequency maximum Q-learning (FMQ) algorithm
(Kapetanakis and Kudenko, 2002), for example, keeps a frequency value f req(R∗,a)
indicating how often the maximum reward so far (R∗) has been observed for a cer- tain action a. This value is then used as a sort of heuristic which is added to the
Q-values. Instead of using Q-values directly, the FMQ algorithm relies on following heuristic evaluation of the actions:
然而,学习者难以达到最佳NE,并且需要更复杂的探索策略来增加收敛到最佳NE的概率。简单的探索策略不充分的原因主要是由于最佳NE中涉及的动作与其他动作相结合时往往导致低得多的回报,因此低估了动作的潜在质量。例如,在游戏2a中,行播放器的动作a1仅在与列播放器的动作a1组合时才导致最高奖励11。在学习阶段,代理人仍在探索,行动a1也将与行动a2和a3结合起来。结果,代理人通常会选择更“安全”的NE(a2,a2)。在游戏2b中观察到类似的行为,因为对2 NE的不协调受到惩罚,惩罚越大(k≤0),代理人越难以到达最佳NE中的任何一个。这也解释了为什么独立学习者在被允许使用任何NE时通常无法收敛到NE,包括随机探索策略。在单一代理Q学习中,特定的探索策略不会影响最终的收敛(Tsitsiklis,1994),这不再适用于MAS设置。
单代理Q学习的局限性导致Q学习算法的许多扩展用于重复游戏。这些方法中的大多数都集中在协调机制上,使得Q-学习者能够在共同兴趣游戏中达到最佳结果。频率最大Q学习(FMQ)算法
(Kapetanakis和Kudenko,2002),例如,保持频率值f req(R *,a)
表示对某一特定行动a迄今为止观察到的最大奖励(R *)的频率a。然后将此值用作添加到的一种启发式
Q值。 FMQ算法不依赖于直接使用Q值,而是依赖于对动作的启发式评估:
EV(a)=Q(a)+w.freq(R∗,a).R∗,
where w is a weight that controls the importance of the heuristic value f req(R∗,a)R∗. The algorithm was empirically shown to be able to drive learners to the optimal joint action in common interest games with deterministic payoffs.
In (Kapetanakis et al, 2003) the idea of commitment sequences has been intro- duced to allow independent learning in games with stochastic payoffs. A commit- ment sequence is a list of time slots for which an agent is committed to selecting al- ways the same action. These sequences of time slots is generated according to some protocol the agents are aware off. Using this guarantee that at time slots belonging
to the same sequence the agents are committed to always select the same individual action, the agents are able to distinguish between the two sources of uncertainty: the noise on the reward signal and the influence on the reward by the actions taken by the other agents. This allows the agents to deal with games with stochastic payoffs. A recent overview of multi-agent Q-learning approaches can be found in (Wun-
der et al, 2010).
其中w是控制启发式值f req(R *,a)R *的重要性的权重。根据经验,该算法能够使学习者在具有确定性收益的共同兴趣游戏中获得最佳联合行动。
在(Kapetanakis等,2003)中,引入了承诺序列的概念,允许在具有随机收益的游戏中进行独立学习。提交序列是代理致力于选择相同操作的时隙列表。这些时隙序列是根据代理知道的某些协议生成的。使用此保证在时隙属于
在同一序列中,代理人承诺始终选择相同的个人行为,代理人能够区分两个不确定性来源:奖励信号上的噪声以及其他代理人采取的行动对奖励的影响。这允许代理商处理具有随机收益的游戏。最近对多智能体Q学习方法的概述可以在(Wun-
der et al,2010)。
14.2.2.3Gradient Ascent Approaches
As an alternative to the well known Q-learning algorithm, we now list some ap- proaches based on gradient following updates. We will focus on players that employ learning automata (LA) reinforcement schemes. Learning automata are relatively simple policy iterators, that keep a vector action probabilities p over the action set
A. As is common in RL, these probabilities are updated based on a feedback received from the environment. While initial studies focussed mainly on a single automaton in n-armed bandit settings, RL algorithms using multiple automata were developed to learn policies in MDPs (Wheeler Jr and Narendra, 1986). The most commonly used LA update scheme is called Linear Reward-Penalty and updates the action probabilities as follows:
作为众所周知的Q学习算法的替代方案,我们现在列出一些基于梯度跟踪更新的方法。 我们将专注于采用学习自动机(LA)强化方案的球员。 学习自动机是相对简单的策略迭代器,它在操作集上保持向量动作概率p
A.如在RL中常见的,基于从环境接收的反馈来更新这些概率。 虽然最初的研究主要集中在n臂强盗设置中的单个自动机,但是使用多个自动机的RL算法被开发用于学习MDP中的策略(Wheeler Jr和Narendra,1986)。 最常用的LA更新方案称为线性奖励 – 惩罚,并按如下方式更新动作概率:
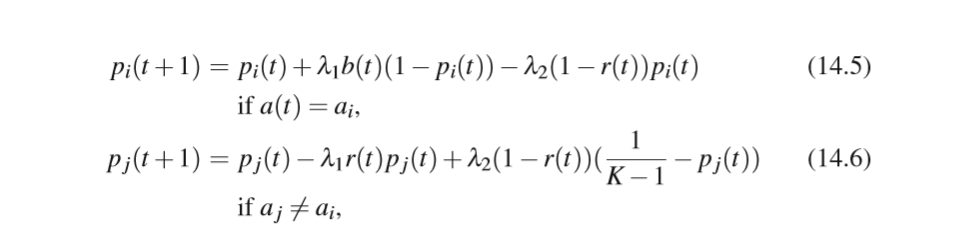

This algorithm has also been shown to be a special case of the REINFORCE (Williams, 1992) update rules. Despite the fact that all these update rules are derived
from the same general scheme, they exhibit very different learning behaviors. Inter- estingly, these learning schemes perform well in game contexts, even though they do not require any information (actions, rewards, strategies) on the other players in the game. Each agent independently applies a LA update rule to change the prob-
abilities over its actions. Below we list some interesting properties of LA in game settings. In two-person zero-sum games, the LR−I scheme converges to the Nash
equilibrium when this exists in pure strategies, while the LR−P scheme is able to
approximate mixed equilibria. In n-player common interest games reward-inaction
also converges to a pure Nash equilibrium. In (Sastry et al, 1994), the dynamics of reward-inaction in general sum games are studied. The authors proceed by ap-
proximating the update in the automata game by a system of ordinary differential equations. Following properties are found to hold for the LR−I dynamics:
•All Nash equilibria are stationary points.
•All strict Nash equilibria are asymptotically stable.
•All stationary points that are not Nash equilibria are unstable.
Furthermore, in (Verbeeck, 2004) it is shown that an automata team using the reward-inaction scheme will convergence to a pure joint strategy with probability 1 in common as well as conflicting interest games with stochastic payoffs. These results together imply local convergence towards pure Nash equilibria in n-player general-sum games(Verbeeck, 2004). Since NE with higher payoffs are stronger at- tractors for the LA, the agents are more likely to reach the better NE. Equipped with an exploration strategy with only requires very limited communications, the agents are able to explore the interesting NE without the need for exhaustive exploration and once these are found, different solution concepts can be considered, for example fair solutions alternating between different Pareto optimal solutions.
In (Verbeeck et al, 2005) it has also been shown that these LA based approach is able to converge in a setting where agents take actions asynchronously and the rewards are delayed as is common in load balancing settings or congestion games.
Another gradient technique frequently studied in games is the Infinitesimal Gra- dient Ascent (IGA) family of algorithms (Singh et al, 2000; Bowling and Veloso, 2001; Zinkevich, 2003; Bowling, 2005). In addition to demonstrating Nash equilib- rium convergence in a number of repeated game settings, several of these papers also evaluate the algorithms with respect to their regret.
该算法也被证明是REINFORCE(Williams,1992)更新规则的一个特例。尽管所有这些更新规则都是派生的
从相同的一般方案,他们表现出非常不同的学习行为。有趣的是,这些学习方案在游戏环境中表现良好,即使他们不需要游戏中其他玩家的任何信息(行动,奖励,策略)。每个代理独立应用LA更新规则来改变问题
对其行为的能力。下面我们列出了游戏设置中LA的一些有趣属性。在双人零和游戏中,LR-I计划融合到纳什
当纯粹策略中存在这种均衡时,LR-P方案能够达到平衡
近似混合均衡。在n玩家共同兴趣游戏奖励无为
也收敛于纯粹的纳什均衡。在(Sastry等,1994)中,研究了一般和博弈中奖励 – 不作为的动态。作者继续
通过常微分方程系统逼近自动机游戏中的更新。发现以下属性适用于LR-I动态:
•所有纳什均衡都是静止点。
•所有严格的纳什均衡都是渐近稳定的。
•所有非纳什均衡的静止点都不稳定。
此外,在(Verbeeck,2004)中,显示使用奖励 – 不作为方案的自动机团队将收敛到具有概率1的纯联合策略以及具有随机收益的冲突兴趣博弈。这些结果共同意味着在n玩家一般和游戏中对纯纳什均衡的局部趋同(Verbeeck,2004)。由于收益较高的NE是洛杉矶较强的吸引子,因此代理商更有可能获得更好的NE。配备只需要非常有限的通信的探索策略,代理能够探索有趣的NE而无需进行详尽的探索,一旦找到这些,就可以考虑不同的解决方案概念,例如在不同的Pareto最优解决方案之间交替的公平解决方案。
在(Verbeeck等人,2005)中,已经表明这些基于LA的方法能够在代理采取异步动作并且奖励被延迟的设置中收敛,这在负载平衡设置或拥塞游戏中是常见的。
在游戏中经常研究的另一种梯度技术是无穷小梯度上升(IGA)算法族(Singh等,2000; Bowling和Veloso,2001; Zinkevich,2003; Bowling,2005)。除了在许多重复的游戏设置中展示纳什均衡收敛之外,这些论文中的一些还评估算法的遗憾。
14.3Sequential Games
While highlighting some of the important issues introduced by learning in a multi- agent environment, the traditional game theory framework does not capture the full complexity of multi-agent reinforcement learning. An important part of the rein- forcement learning problem is that of making sequential decisions in an environment with state transitions and cannot be described by standard normal form games, as they allow only stationary, possibly stochastic, reward functions that depend solely
on the actions of the players. In a normal form game there is no concept of a system with state transitions, a central issue of the Markov decision process concept. There- fore, we now consider a richer framework which generalizes both repeated games and MDPs. Introducing multiple agents to the MDP model significantly compli- cates the problem that the learning agents face. Both rewards and transitions in the environment now depend on the actions of all agents present in the system. Agents are therefore required to learn in a joint action space. Moreover, since agents can have different goals, an optimal solution which maximizes rewards for all agents simultaneously may fail to exist.
To accommodate the increased complexity of this problem we use the represen- tation of Stochastic of Markov games (Shapley, 1953). While they were originally introduced in game theory as an extension of normal form games, Markov games also generalize the Markov Decision process and were more recently proposed as the standard framework for multi-agent reinforcement learning (Littman, 1994). As the name implies, Markov games still assume that state transitions are Markovian, however, both transition probabilities and expected rewards now depend on the joint action of all agents. Markov games can be seen as an extension of MDPs to the multi-agent case, and of repeated games to multiple state case. If we assume only 1 agent, or the case where other agents play a fixed policy, the Markov game reduces to an MDP. When the Markov game has only 1 state, it reduces to a repeated normal form game.
虽然突出了在多智能体环境中学习引入的一些重要问题,但传统的博弈论框架并没有捕捉到多智能体强化学习的全部复杂性。加强学习问题的一个重要部分是在具有状态转换的环境中进行顺序决策,而不能通过标准的正规形式游戏来描述,因为它们只允许仅依赖于固定的,可能是随机的奖励函数。
关于球员的行动。在正常形式的游戏中,没有具有状态转换的系统的概念,这是马尔可夫决策过程概念的核心问题。因此,我们现在考虑一个更丰富的框架,它概括了重复游戏和MDP。将多个代理引入MDP模型显着地复杂了学习代理所面临的问题。现在,环境中的奖励和转换都取决于系统中存在的所有代理的操作。因此,代理人需要在联合行动空间中学习。此外,由于代理商可以有不同的目标,因此可能无法同时最大化所有代理商的奖励的最佳解决方案。
为了适应这个问题日益复杂的问题,我们使用马尔可夫随机游戏的代表(Shapley,1953)。虽然它们最初是作为正常形式游戏的延伸而在游戏理论中引入的,但马尔可夫游戏也推广了马尔可夫决策过程,并且最近被提议作为多智能体强化学习的标准框架(Littman,1994)。顾名思义,马尔可夫游戏仍然假设状态转换是马尔可夫,但是,转换概率和预期奖励现在都取决于所有代理的联合行动。马尔可夫游戏可以被视为MDP对多智能体案例的扩展,以及对多个州案例的重复游戏。如果我们只假设一个代理,或其他代理发挥固定政策的情况,马尔可夫游戏会减少为MDP。当马尔可夫游戏只有1个状态时,它会减少为重复的正常形式游戏。
14.3.1Markov Games
An extension of the single agent Markov decision process (MDP) to the multi-agent case can be defined by Markov Games. In a Markov Game, joint actions are the result of multiple agents choosing an action independently.
可以通过马尔可夫游戏来定义单个代理马尔可夫决策过程(MDP)到多智能体案例的扩展。 在马尔可夫游戏中,联合行动是多个代理独立选择行动的结果。

to each agent k. Different agents can receive different rewards for the same state transition. Transitions in the game are again assumed to obey the Markov property. As was the case in MDPs, agents try to optimize some measure of their future expected rewards. Typically they try to maximize either their future discounted re- ward or their average reward over time. The main difference with respect to single agent RL, is that now these criteria also depend on the policies of other agents. This results in the following definition for the expected discounted reward for agent i:
每个代理人k。 不同的代理可以为相同的状态转换接收不同的奖励。 再次假设游戏中的过渡服从马尔可夫属性。 与MDP中的情况一样,代理商尝试优化其未来预期奖励的某些衡量标准。 通常情况下,他们会尝试最大限度地提高未来的折扣价格或平均奖励。 与单一代理RL的主要区别在于,现在这些标准还取决于其他代理的策略。 这导致代理i的预期折扣奖励的以下定义:
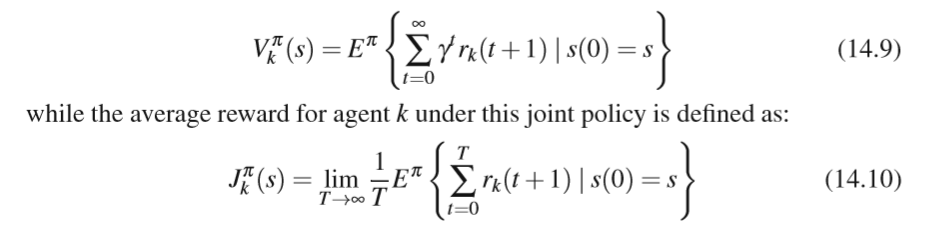
Since it is in general impossible to maximize this criterion for all agents simultaneously, as agents can have conflicting goals, agents playing a Markov game face the same coordination problems as in repeated games.Therefore,typically one relies again one quilibriaas the solution concept for these problems. The best response and Nash equilibrium concepts can be extended to Markov games, by defining a policy π k as a best response, when no other policy for agent k exists which gives a higher expected future reward, provided that the other agents keep their policies fixed.
It should be noted that learning in a Markov game introduces several new issues over learning in MDPs with regard to the policy being learned. In an MDP, it is possible to prove that, given some basic assumptions, an optimal deterministic pol- icy always exists. This means it is sufficient to consider only those policies which deterministically map each state to an action. In Markov games, however, where we must consider equilibria between agent policies, this no longer holds. Similarly to the situation in repeated games, it is possible that a discounted Markov game, only has Nash equilibria in which stochastic policies are involved. As such, it is not suffi- cient to let agents map a fixed action to each state: they must be able to learn a mixed strategy. The situation becomes even harder when considering other reward criteria, such as the average reward, since then it is possible that no equilibria in stationary strategies exist (Gillette, 1957). This means that in order to achieve an equilibrium outcome, the agents must be able to express policies which condition the action se- lection in a state on the entire history of the learning process. Fortunately, one can introduce some additional assumptions on the structure of the problem to ensure the existence of stationary equilibria (Sobel, 1971).
由于通常不可能同时为所有代理商最大化这个标准,因为代理商可以有冲突目标,玩马尔可夫游戏的代理商面临与重复游戏中相同的协调问题。因此,通常一个人再次依赖于这些解决方案的概念。问题。最好的反应和纳什均衡概念可以扩展到马尔可夫游戏,通过将政策πk定义为最佳响应,当没有其他代理商k的政策可以提供更高的预期未来回报时,前提是其他代理人保持其政策固定。
应该注意的是,马尔可夫游戏中的学习引入了几个关于正在学习的策略的MDP学习的新问题。在MDP中,有可能证明,在给定一些基本假设的情况下,始终存在最优确定性策略。这意味着仅考虑那些确定性地将每个状态映射到一个动作的策略就足够了。然而,在马尔可夫游戏中,我们必须考虑代理政策之间的均衡,这已不再成立。与重复博弈中的情况类似,有折扣的马尔可夫游戏可能只有纳什均衡,其中涉及随机政策。因此,让代理人将固定行动映射到每个州是不够的:他们必须能够学习混合策略。在考虑其他奖励标准时,情况变得更加困难,例如平均奖励,从那时起,有可能在平稳策略中不存在均衡(吉列,1957)。这意味着,为了实现均衡结果,代理人必须能够表达政策,这些政策决定了学习过程的整个历史状态中的行动选择。幸运的是,人们可以对问题的结构引入一些额外的假设,以确保固定均衡的存在(Sobel,1971)。
14.3.2Reinforcement Learning in Markov Games
While in normal form games the challenges for reinforcement learners originate mainly from the interactions between the agents, in Markov games they face the
additional challenge of an environment with state transitions. This means that the agents typically need to combine coordination methods or equilibrium solvers used in repeated games with MDP approaches from single-agent RL.
在正常形式的游戏中,强化学习者面临的挑战主要来自于代理人之间的互动,在他们面对的马尔可夫游戏中
状态转换环境的额外挑战。 这意味着代理通常需要将重复游戏中使用的协调方法或平衡求解器与来自单代理RL的MDP方法相结合。
14.3.2.1Value Iteration
A number of approaches have been developed, aiming at extending the successful Q-learning algorithm to multi-agent systems. In order to be successful in a multi- agent context, these algorithms must first deal with a number of key issues.
Firstly, immediate rewards as well as the transition probabilities depend on the actions of all agents. Therefore, in a multi-agent Q-learning approach, the agent does not simply learns to estimate Q(s,a) for each state action pair, but rather estimates
Q(s,a) giving the expected future reward for taking the joint action a = a1,… ,an in
state s. As such, contrary to the single agent case, the agent does not have a single
estimate for the future reward it will receive for taking an action ak in state s. Instead, it keeps a vector of estimates, which give the future reward of action ak, depending on the joint action a k played by the other agents. During learning, the agent selects
an action and then needs to observe the actions taken by other agents, in order to update the appropriate Q(s,a) value.
This brings us to the second issue that a multi-agent Q-learner needs to deal with:
the state values used in the bootstrapping update. In the update rule of single agent Q-learning the agent uses a maximum over its actions in the next state sj. This gives
the current estimate of the value of state sj under the greedy policy. But as was mentioned above, the agent cannot predict the value of taking an action in the next
state, since this value also depends on the actions of the other agents. To deal with
this problem, a number of different approaches have been developed which calculate a value of state sj by also taking into account the other agents. All these algorithms,
of which we describe a few examples below, correspond to the general multi-agent Q-learning template given in Algorithm 23, though each algorithm differs in the method used to calculate the Vk(sj ) term in the Q-learning update.
已经开发了许多方法,旨在将成功的Q学习算法扩展到多代理系统。为了在多代理上下文中取得成功,这些算法必须首先处理许多关键问题。
首先,即时奖励以及转换概率取决于所有代理人的行为。因此,在多智能体Q学习方法中,代理不是简单地学习估计每个状态动作对的Q(s,a),而是估计
Q(s,a)给出联合行动的预期未来奖励a = a1,…,a in
状态。因此,与单一代理案例相反,代理人没有单一案件
估计在州政府采取行动时将获得的未来奖励。相反,它保留了估计的向量,这给出了行动的未来奖励,取决于其他代理人所扮演的联合行动。在学习期间,代理选择
然后需要观察其他代理所采取的操作,以便更新相应的Q(s,a)值。
这将我们带到第二个问题,即多代理Q-learning需要处理的问题:
引导更新中使用的状态值。在单代理Q-learning的更新规则中,代理在下一个状态sj中使用最大值。这给了
目前对贪婪政策下国家sj价值的估计。但如上所述,代理人无法预测下一次采取行动的价值
state,因为此值还取决于其他代理的操作。要处理
在这个问题上,已经开发了许多不同的方法,它们还通过考虑其他代理来计算状态sj的值。所有这些算法,
我们在下面描述了几个例子,它们对应于算法23中给出的一般多智能体Q学习模板,尽管每种算法在用于计算Q学习更新中的Vk(sj)项的方法上不同。


Another method used in multi-agent Q-learning is to assume that the other agents will play according to some strategy. For example, in the minimax Q-learning algo- rithm (Littman, 1994), which was developed for 2-agent zero-sum problems, the learning agent assumes that its opponent will play the action which minimizes the learner’s payoff. This means that the max operator of single agent Q-learning is replaced by the minimax value:
在多智能体Q学习中使用的另一种方法是假设其他代理将根据某种策略进行游戏。 例如,在为2-agent零和问题开发的极小极大Q学习算法(Littman,1994)中,学习代理假设其对手将发挥最小化学习者收益的作用。 这意味着单个代理Q学习的最大运算符被minimax值替换:
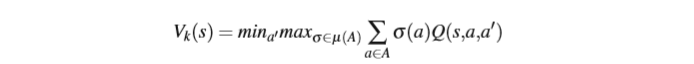
The Q-learning agent maximizes over its strategies for state s, while assuming that the opponent will pick the action which minimizes the learner’s future rewards. Note that the agent does not just maximizes over the deterministic strategies, as it is possible that the maximum will require a mixed strategy. This system was later generalized to friend-or-foe Q-learning (Littman, 2001a), where the learning agent deals with multiple agents by marking them either as friends, who assist to maximize its payoff or foes, who try to minimize the payoff.
Alternative approaches assume that the agents will play an equilibrium strategy. For example, Nash-Q (Hu and Wellman, 2003) observes the rewards for all agents and keeps estimates of Q-values not only for the learning agent, but also for all other agents. This allows the learner to represent the joint action selection in each state as a game, where the entries in the payoff matrix are defined by the Q-values of the agents for the joint action. This representation is also called the stage game.
A Nash-Q agent then assumes that all agents will play according to a Nash equilib- rium of this stage game in each state:
Vk(s)= Nashk(s,Q1,…,Qn),
where Nashk(s,Q1,…,Qn) denotes the expected payoff for agent k when the agents play a Nash equilibrium in the stage game for state s with Q-values Q1,…,Qn. Under
some rather strict assumptions on the structure of the stage games, Nash-Q can be shown to converge in self-play to a Nash equilibrium between agent policies.
The approach used in Nash-Q can also be combined with other equilibrium con- cepts, for example correlated equilibria (Greenwald et al, 2003) or the Stackelberg equilibrium (Kononen, 2003). The main difficulty with these approaches is that the value is not uniquely defined when multiple equilibria exist, and coordination is needed to agree on the same equilibrium. In these cases, additional mechanisms are typically required to select some equilibrium.
While the intensive research into value iteration based multi-agent RL has yielded some theoretical guarantees (Littman, 2001b), convergence results in the general Markov game case remain elusive. Moreover, recent research indicates that a reliance on Q-values alone may not be sufficient to learn an equilibrium policy in arbitrary general sum games (Zinkevich et al, 2006) and new approaches are needed.
Q学习代理最大化其状态策略,同时假设对手将选择最小化学习者未来奖励的动作。请注意,代理不仅仅是最大化确定性策略,因为最大值可能需要混合策略。这个系统后来被推广到朋友或敌人的Q学习(Littman,2001a),其中学习代理通过将他们标记为朋友,帮助最大化其收益或敌人,试图最小化收益来处理多个代理。
替代方法假设代理将发挥均衡策略。例如,Nash-Q(Hu和Wellman,2003)观察所有代理人的奖励,并且不仅对学习代理人而且对所有其他代理人保持Q值的估计。这允许学习者将每个状态中的联合动作选择表示为游戏,其中支付矩阵中的条目由联合动作的代理的Q值定义。这种表示也称为舞台游戏。
然后,Nash-Q代理假定所有代理将根据每个状态下此阶段游戏的Nash均衡进行游戏:
Vk(s)= Nashk(s,Q1,…,Qn),
其中Nashk(s,Q1,…,Qn)表示当代理人在Q值Q1,…,Qn的状态s的阶段游戏中发挥纳什均衡时代理人k的预期收益。下
对阶段博弈结构有一些相当严格的假设,Nash-Q可以表现为在自我发挥中融合到代理政策之间的纳什均衡。
Nash-Q中使用的方法也可以与其他均衡概念相结合,例如相关均衡(Greenwald等,2003)或Stackelberg均衡(Kononen,2003)。这些方法的主要困难在于,当存在多个均衡时,该值不是唯一定义的,并且需要协调以在同一均衡上达成一致。在这些情况下,通常需要额外的机制来选择一些平衡。
虽然对基于价值迭代的多智能体RL的深入研究已经产生了一些理论上的保证(Littman,2001b),但在一般马尔可夫游戏案例中的收敛结果仍然是难以捉摸的。此外,最近的研究表明仅仅依靠Q值可能不足以在任意一般和博弈中学习均衡政策(Zinkevich等,2006),需要新的方法。
14.3.2.2Policy Iteration
In this section we describe policy iteration for multi-agent reinforcement learning. We focus on an algorithm called Interconnected Learning Automata for Markov Games (MG-ILA)(Vrancx et al, 2008b), based on the learning automata from Sec- tion 14.2.2.3 and which can be applied to average reward Markov games. The al- gorithm can be seen as an implementation of the actor-critic framework, where the
policy is stored using learning automata. The main idea is straightforward: each agent k puts a single learning automaton LA (k,i) in each system state si. At each time step only the automata of the current state are active. Each automaton then individually selects an action for its corresponding agent. The resulting joint action triggers the next state transition and immediate rewards. Automata are not updated
using immediate rewards but rather using a response estimating the average reward. The complete algorithm is listed in Algorithm 24.
An interesting aspect of this algorithm is that its limiting behavior can be approx- imated by considering a normal form game in which all the automata are players. A play in this game selects an action for each agent in each state, and as such corre- sponds to a pure, joint policy for all agents. Rewards in the game are the expected average rewards for the corresponding joint policies. In (Vrancx et al, 2008b),it is shown that the algorithm will converge to a pure Nash equilibrium in this result- ing game (if it exists), and that this equilibrium corresponds to a pure equilibrium between the agent policies. The game approximation also enables an evolutionary game theoretic analysis of the learning dynamics (Vrancx et al, 2008a), similar to that applied to repeated games.
在本节中,我们将描述多智能体强化学习的策略迭代。我们专注于一种称为Markov Games的互连学习自动机(MG-ILA)的算法(Vrancx等,2008b),该算法基于第14.2.2.3节中的学习自动机,可应用于平均奖励马尔可夫游戏。该算法可以看作是演员 – 评论家框架的实现,其中
使用学习自动机存储策略。主要思想很简单:每个代理k在每个系统状态si中放置一个学习自动机LA(k,i)。在每个时间步,只有当前状态的自动机是活动的。然后,每个自动机单独为其相应的代理选择一个动作。由此产生的联合动作触发下一个状态转换和即时奖励。自动机不会更新
使用即时奖励,而是使用估算平均奖励的回复。算法24中列出了完整的算法。
该算法的一个有趣的方面是它的限制行为可以通过考虑所有自动机都是玩家的普通形式游戏来估算。这个游戏中的游戏为每个州的每个代理选择一个动作,因此对所有代理的纯粹联合政策都是相应的。游戏中的奖励是相应联合政策的预期平均奖励。在(Vrancx等,2008b)中,表明该算法将在该结果游戏中收敛到纯纳什均衡(如果存在),并且该均衡对应于代理策略之间的纯粹均衡。游戏近似还使得学习动力学的进化博弈理论分析(Vrancx等,2008a),类似于应用于重复博弈的。

While not as prevalent as value iteration based methods, a number of interesting approaches based on policy iteration have been proposed. Like the algorithm de- scribed above, these methods typically rely on a gradient based search of the policy space. (Bowling and Veloso, 2002), for example, proposes an actor-critic frame- work which combines tile coding generalization with policy gradient ascent and uses the Win or Learn Fast (WoLF) principle. The resulting algorithm is empirically shown to learn in otherwise intractably large problems. (Kononen, 2004) introduces a policy gradient method for common-interest Markov games which extends the single agent methods proposed by (Sutton et al, 2000). Finally, (Peshkin et al, 2000)
develop a gradient based policy search method for partially observable, identical payoff stochastic games. The method is shown to converge to local optima which are, however, not necessarily Nash equilibria between agent policies.
虽然不像基于值迭代的方法那样普遍,但已经提出了许多基于策略迭代的有趣方法。 与上面描述的算法一样,这些方法通常依赖于基于梯度的策略空间搜索。 (例如,Bowling和Veloso,2002)提出了一种行为者 – 评论家框架,它将瓦片编码概括与政策梯度上升相结合,并使用Win或Learn Fast(WoLF)原理。 根据经验证明,所得算法可以在其他难以处理的大问题中学习。 (Kononen,2004)介绍了一种用于共同兴趣马尔可夫游戏的策略梯度方法,该方法扩展了(Sutton等,2000)提出的单一代理方法。 最后,(Peshkin等,2000)
为部分可观察,相同的支付随机游戏开发基于梯度的策略搜索方法。 该方法显示为收敛于局部最优,然而,这不一定是代理政策之间的纳什均衡。
14.4Sparse Interactions in Multi-agent System
A big drawback of reinforcement learning in Markov games is the size of the state- action-space in which the agents are learning. All agents learn in the entire joint state-action space and as such these approaches become quickly infeasible for all but the smallest environments and with a limited number of agents. Recently, a lot of attention has gone into mitigating this problem. The main intuition for these approaches is to only explicitly consider the other agents if a better payoff can be obtained by doing so. In all other situations the other agents can safely be ignored and as such have the advantages of learning in a small state-action space, while also having access to the necessary information to deal with the presence of other agents, if this is beneficial. An example of such systems is an automated warehouse, where the automated guided vehicles only have to consider each other when they are close by to each other. We can distinguish two different lines of research: agents can base their decision for coordination on the actions that are selected, or agents can focus on the state information at their disposal, and learn when it is beneficial to observe the state information of other agents. We will describe both these approaches separately in Sections 14.4.2.1 and 14.4.2.2
马尔可夫游戏中强化学习的一大缺点是代理人正在学习的状态 – 动作空间的大小。所有代理人都在整个联合国家行动空间中学习,因此这些方法对于除了最小的环境以及有限数量的代理之外的所有人来说都很快变得不可行。最近,很多人都在关注这个问题。这些方法的主要直觉是,只有通过这样做才能获得更好的收益,才能明确地考虑其他代理。在所有其他情况下,其他代理可以安全地被忽略,因此具有在小的状态 – 动作空间中学习的优点,同时还可以访问必要的信息来处理其他代理的存在,如果这是有益的。这种系统的一个例子是自动仓库,其中自动引导车辆仅在它们彼此靠近时才必须相互考虑。我们可以区分两种不同的研究方向:代理人可以根据所选择的行动作出协调决策,或者代理人可以专注于他们可以使用的状态信息,并了解何时观察其他代理人的状态信息是有益的。我们将在第14.4.2.1节和第14.4.2.2节中分别描述这两种方法
14.4.1Learning on Multiple Levels
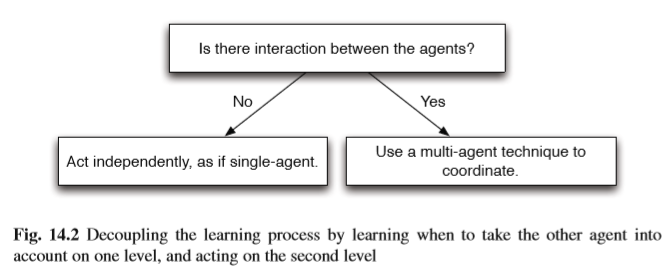
Learning with sparse interactions provides an easy way of dealing with the expo- nential growth of the state space in terms of the number of agents involved in the learning process. Agents should only rely on more global information, in those situ- ations where the transition of the state of the agent to the next state and the rewards the agents experience are not only dependent on the local state information of the agent performing the action, but also on the state information or actions of other agents. The idea of sparse interactions is ’When is an agent experiencing influence from another agent?’. Answering this questing, allows an agent to know when it can select its actions independently (i.e. the state transition function and reward function are only dependent on its own action) or when it must coordinate with other agents (i.e. the state transition function and the reward function is the effect of the joint ac- tion of multiple agents). This leads naturally to a decomposition of the multi-agent learning process into two separate layers. The top layer should learn when it is nec- essary to observe the state information about other agents and select whether pure independent learning is sufficient, or whether some form of coordination between the agents is required. The bottom layer contains a single agent learning technique, to be used when there is no risk of influence by other agents, and a multi-agent tech- nique, to be used when the state transition and reward the agent receives is depen- dent of the current state and actions of other agents. Figure 14.2 shows a graphical
representation of this framework. In the following subsection we begin with an overview of algorithms that approach this problem from the action space point of view, and focus on the coordination of actions.
使用稀疏交互进行学习提供了一种简单的方法,可以根据学习过程中涉及的代理数量来处理状态空间的指数增长。代理应该只依赖于更多的全局信息,在那些将代理状态转换到下一个状态的情况和代理所经历的奖励不仅取决于执行该操作的代理的本地状态信息,而且还有关于其他代理人的国家信息或行动。稀疏交互的概念是“代理何时受到另一个代理的影响?”。回答此任务,允许代理知道何时可以独立选择其动作(即状态转换功能和奖励功能仅取决于其自身的动作)或何时必须与其他代理协调(即状态转换功能和奖励)功能是多种药剂联合作用的结果)。这自然导致多代理学习过程分解成两个单独的层。最上层应该学习何时需要观察其他代理的状态信息,并选择纯粹的独立学习是否足够,或者是否需要代理之间的某种形式的协调。底层包含单个代理学习技术,当不存在其他代理影响的风险时使用,以及多代理技术,当状态转换和奖励代理接收时依赖于其他代理人的当前状态和行为。图14.2显示了一个图形
代表这个框架。在下面的小节中,我们首先概述从行动空间角度处理此问题的算法,并重点关注行动的协调。
14.4.2Learning to Coordinate with Sparse Interactions
14.4.2.1Learning Interdependencies among Agents
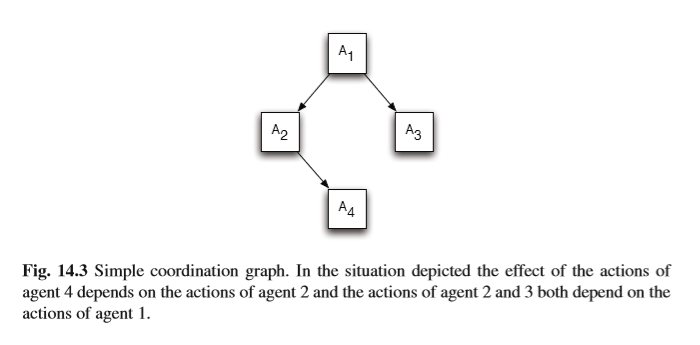
Kok & Vlassis proposed an approach based on a sparse representation for the joint action space of the agents while observing the entire joint state space. More specif- ically they are interested in learning joint-action values for those states where the agents explicitly need to coordinate. In many problems, this need only occurs in very specific situations (Guestrin et al, 2002b). Sparse Tabular Multiagent Q-learning maintains a list of states in which coordination is necessary. In these states, agents select a joint action, whereas in all the uncoordinated states they all select an action individually (Kok and Vlassis, 2004b). By replacing this list of states by coordi- nation graphs (CG) it is possible to represent dependencies that are limited to a few agents (Guestrin et al, 2002a; Kok and Vlassis, 2004a, 2006). This technique is known as Sparse Cooperative Q-learning (SCQ). Figure 14.3 shows a graphical representation of a simple CG for a situation where the effect of the actions of agent 4 depend on the actions of agent 2 and the actions of agent 2 and 3 both depend on the actions of agent 1, so the nodes represent the agents, while an edge defines a dependency between two agents. If agents transitioned into a coordinated state, they applied a variable elimination algorithm to compute the optimal joint action for the current state. In all other states, the agents select their actions independently.
In later work, the authors introduced Utile Coordination (Kok et al, 2005). This is a more advanced algorithm that uses the same idea as SCQ, but instead of hav- ing to define the CGs beforehand, they are being learned online. This is done by maintaining statistical information about the obtained rewards conditioned on the states and actions of the other agents. As such, it is possible to learn the context spe- cific dependencies that exist between the agents and represent them in a CG. This technique is however limited to fully cooperative MAS.
Kok&Vlassis提出了一种基于代理人联合行动空间稀疏表示的方法,同时观察整个联合状态空间。更具体地说,他们有兴趣学习代理人明确需要协调的那些州的联合行动价值。在许多问题中,这种需要只发生在非常特殊的情况下(Guestrin等,2002b)。稀疏表格多智能体Q-learning维护一个需要协调的状态列表。在这些状态中,代理选择联合动作,而在所有未协调状态中,他们都单独选择动作(Kok和Vlassis,2004b)。通过协调图(CG)替换该状态列表,可以表示仅限于少数代理的依赖性(Guestrin等,2002a; Kok和Vlassis,2004a,2006)。该技术称为稀疏合作Q学习(SCQ)。图14.3显示了一个简单CG的图形表示,其中代理4的操作的影响取决于代理2的操作,代理2和3的操作都取决于代理1的操作,因此节点代表代理,而边缘定义了两个代理之间的依赖关系。如果代理转换为协调状态,则他们应用变量消除算法来计算当前状态的最佳联合动作。在所有其他状态中,代理会独立选择其操作。
在后来的工作中,作者介绍了Utile Coordination(Kok等,2005)。这是一种更高级的算法,它使用与SCQ相同的思想,但不是事先定义CG,而是在线学习。这是通过维护关于所获得的奖励的统计信息来完成的,所述奖励以其他代理的状态和动作为条件。因此,可以了解代理之间存在的上下文特定依赖关系并在CG中表示它们。然而,该技术仅限于完全协作的MAS。
The primary goal of these approaches is to reduce the joint-action space. How- ever, the computation or learning in the algorithms described above, always employ a complete multi-agent view of the entire joint-state space to select their actions, even in states where only using local state information would be sufficient. As such, the state space in which they are learning is still exponential in the number of agents, and its use is limited to situations in which it is possible to observe the entire joint state.
这些方法的主要目标是减少联合行动空间。 但是,上述算法中的计算或学习总是采用整个联合状态空间的完整多代理视图来选择其动作,即使在仅使用本地状态信息就足够的状态下也是如此。 因此,他们所学习的状态空间仍然是代理人数量的指数,并且其使用仅限于可以观察整个联合状态的情况。
14.4.2.2Learning a Richer State Space Representation
Instead of explicitly learning the optimal coordinated action, a different approach consists in learning in which states of the environment it is beneficial to include the state information about other agents. We will describe two different methods. The first method learns in which states coordination is beneficial using an RL approach. The second method learns the set of states in which coordination is necessary based on the observed rewards. Unlike the approaches mentioned in Section 14.4.2.1, these approaches can also be applied to conflicting interest games and allow independent action selection.
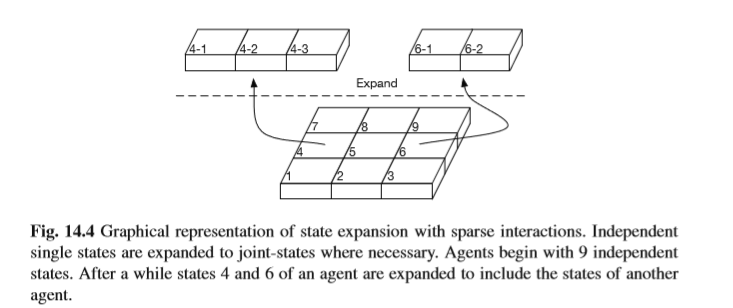
The general idea of the approaches described in this section are given by Figure
14.4.These algorithms will expand the local state information of an agent to in- corporate the information of another agent if this information is necessary to avoid suboptimal rewards.
不同于明确地学习最佳协调动作,不同的方法在于学习在哪些环境状态中包括关于其他代理的状态信息是有益的。 我们将描述两种不同的方法。 第一种方法使用RL方法了解哪种状态协调是有益的。 第二种方法根据观察到的奖励来学习需要协调的状态集。 与第14.4.2.1节中提到的方法不同,这些方法也可以应用于冲突的兴趣游戏,并允许独立的行动选择。
本节中描述的方法的一般概念由图给出
14.4。如果需要这些信息以避免次优奖励,这些算法将扩展代理的本地状态信息以包含另一个代理的信息。
Learning of Coordination
Spaan and Melo approached the problem of coordination from a different angle than Kok & Vlassis (Spaan and Melo, 2008). They introduced a new model for multi- agent decision making under uncertainty called interaction-driven Markov games (IDMG). This model contains a set of interaction states which lists all the states in which coordination is beneficial.
Spaan和Melo从与Kok&Vlassis不同的角度解决了协调问题(Spaan和Melo,2008)。 他们在不确定性下引入了一种新的多智能体决策模型,称为交互驱动的马尔可夫游戏(IDMG)。 该模型包含一组交互状态,列出了协调有益的所有状态。
In later work, Melo and Veloso introduced an algorithm where agents learn in which states they need to condition their actions on the local state information of other agents (Melo and Veloso, 2009). As such, their approach can be seen as a way of solving an IDMG where the states in which coordination is necessary is not specified beforehand. To achieve this, they augment the action space of each agent with a pseudo-coordination action (COORDINATE). This action will perform an active perception step. This could for instance be a broadcast to the agents to divulge their location or using a camera or sensors to detect the location of the other agents. This active perception step will decide whether coordination is necessary or if it is safe to ignore the other agents. Since the penalty of miscoordination is bigger than the cost of using the active perception, the agents learn to take this action in the interaction states of the underlying IDMG. This approach solves the coordination problem by deferring it to the active perception mechanism.
The active perception step of LoC can consist of the use of a camera, sensory data, or communication to reveal the local state information of another agent. As such the outcome of the algorithm depends on the outcome of this function. Given an adequate active perception function, LoC is capable of learning a sparse set of states in which coordination should occur. Note that depending on the active perception function, this algorithm can be used for both cooperative as conflicting interest systems.
The authors use a variation on the standard Q-learning update rule:
在后来的工作中,Melo和Veloso引入了一种算法,在这种算法中,代理人可以了解他们需要在哪些状态下根据其他代理人的本地状态信息来调整他们的行为(Melo和Veloso,2009)。因此,他们的方法可被视为解决IDMG的一种方式,其中未预先指定需要协调的状态。为实现这一目标,他们通过伪协调动作(COORDINATE)增加每个代理的动作空间。此操作将执行主动感知步骤。例如,这可以是向代理广播以泄露其位置或使用相机或传感器来检测其他代理的位置。这种主动感知步骤将决定是否需要协调或忽略其他代理是否安全。由于协调的惩罚大于使用主动感知的成本,因此代理学习在基础IDMG的交互状态中采取此动作。该方法通过将协调问题推迟到主动感知机制来解决协调问题。
LoC的主动感知步骤可以包括使用相机,传感数据或通信来揭示另一个代理的本地状态信息。因此,算法的结果取决于该函数的结果。给定足够的主动感知功能,LoC能够学习应该发生协调的稀疏状态集。注意,根据主动感知功能,该算法可以用于合作的冲突兴趣系统。
作者使用标准Q学习更新规则的变体:

Coordinating Q-Learning
Coordinating Q-Learning, or CQ-learning, learns in which states an agent should take the other agents into consideration (De Hauwere et al, 2010) and in which states is cant act using primarily only its own state information. More precisely, the algorithm will identify states in which an agent should take other agents into account when choosing its preferred action.
The algorithm can be decomposed into three sections: detecting conflict situa- tions, selecting actions and updating the Q-values which will now be explained in more detail:
协调Q学习或CQ学习,了解代理人应该考虑其他代理人的状态(De Hauwere等人,2010),以及哪些州不能仅主要使用其自己的州信息。 更确切地说,该算法将识别代理在选择其优选动作时应考虑其他代理的状态。
该算法可以分解为三个部分:检测冲突情况,选择动作和更新Q值,现在将更详细地解释:
1.Detecting conflict situations
Agents must identify in which states they experience the influence of at least one other agent. CQ-Learning needs a baseline for this, so agents are assumed to have learned a model about the expected payoffs for selecting an action in a particular state applying an individual policy. For example, in a gridworld this would mean that the agents have learned a policy to reach some goal, while being the only agent present in the environment. If agents are influencing each other, this will be reflected in the payoff the agents receive when they are acting together. CQ-learning uses a statistical test to detect if there are changes in the observed rewards for the selected state-action pair compared to the case where they were acting alone in the environment. Two situations can occur:
- a.The statistics allow to detect a change in the received immediate rewards. In this situation, the algorithm will mark this state, and search for the cause of this change by collecting new samples from the joint state space in order to identify the joint state-action pairs in which collisions occur. These state- action pairs are then marked as being dangerous, and the state space of the agent is augmented by adding this joint state information. State-action pairs that did not cause interactions are marked as being safe, i.e. the agent’s actions in this state are independent from the states of other agents. So the algorithm will first attempt to detect changes in the rewards an agent receives, solely based on its own state, before trying to identify due to which other agents these changes occur.
- b.The statistics indicate that the rewards the agent receives are from the same distribution as if the agent was acting alone. Therefore, no special action is taken in this situation and the agent continues to act as if it was alone.
代理商必须确定他们在哪些州经历至少一个其他代理商的影响。 CQ-Learning需要一个基线,因此假定代理已经学习了关于在应用单个策略的特定状态中选择动作的预期收益的模型。例如,在gridworld中,这意味着代理已经学会了达到某个目标的策略,同时成为环境中存在的唯一代理。如果代理人相互影响,这将反映在代理人一起行动时所得到的回报。 CQ学习使用统计测试来检测所选择的状态 – 动作对的观察到的奖励是否与他们在环境中单独行动的情况相比有所变化。可能出现两种情况: - a。统计数据允许检测收到的即时奖励的变化。在这种情况下,算法将标记该状态,并通过从联合状态空间收集新样本来搜索该变化的原因,以便识别发生冲突的联合状态 – 动作对。然后将这些状态 – 动作对标记为危险的,并且通过添加该联合状态信息来增强代理的状态空间。不引起交互的状态 – 动作对被标记为安全,即代理在此状态下的动作独立于其他代理的状态。因此,在尝试识别由于哪些其他代理发生这些变化之前,该算法将首先尝试检测代理接收的奖励的变化,仅基于其自身的状态。
- b。统计数据表明,代理人收到的奖励来自同一个分配,就像代理人单独行动一样。因此,在这种情况下不采取任何特殊行动,并且代理人继续表现得像是独自一人。
2.Selecting actions
If an agent selects an action, it will check if its current local state is a state in which a discrepancy has been detected previously (case 1.a, described above). If so, it will observe the global state information to determine if the state informa- tion of the other agents is the same as when the conflict was detected. If this is the case, it will condition its actions on this global state information, otherwise it can act independently, using only its own local state information. If its local state information has never caused a discrepancy (case 1.b, described above), it can act without taking the other agents into consideration.
如果代理选择动作,则它将检查其当前本地状态是否是先前已检测到差异的状态(情况1.a,如上所述)。 如果是这样,它将观察全局状态信息以确定其他代理的状态信息是否与检测到冲突时的状态信息相同。 如果是这种情况,它将调整其对此全局状态信息的操作,否则它可以仅使用其自己的本地状态信息独立操作。 如果其本地状态信息从未引起差异(情况1.b,如上所述),则可以在不考虑其他代理的情况下采取行动。
3.Updating the Q-values
The updating the Q-values follows the same idea as the Learning of Coordi- nation algorithm, described above. The Q-values for local states are used to bootstrap the Q-values of the states that were augmented.
The statistical test used in the algorithm is the Student t-test (Stevens, J.P., 1990). This test can determine whether the null hypothesis that the mean of two populations of samples are equal holds, against the alternative that they are not equal. In CQ- learning this test is first used to identify in which states the observed rewards are significantly different from the expected rewards based on single agent learning, and also to determine on which other agents’ states these changes depend.
A formal description of this algorithm is given in Algorithm 25.
CQ-learning can also be used to generalise information from states in which coordination is necessary to obtain a state-independent representation of the co- ordination dependencies that exist between the agents (De Hauwere et al, 2010). This information can then be transferred to other, more complex, task environments (Vrancx et al, 2011). This principle of transfer learning improves the learning speed, since agents can purely focus on the core task of the problem at hand and use trans- ferred experience for the coordination issues.
更新Q值遵循与上述的协调学习算法相同的思想。本地状态的Q值用于引导增强状态的Q值。
算法中使用的统计检验是Student t检验(Stevens,J.P.,1990)。该测试可以确定两个样本群的平均值是否相等的零假设,而不是它们不相等的替代方案。在CQ-学习中,该测试首先用于识别在哪些状态下观察到的奖励与基于单一代理学习的预期奖励显着不同,并且还确定这些改变所依赖的哪些其他代理的状态。
算法25中给出了该算法的形式描述。
CQ学习还可用于概括来自状态的信息,其中需要协调以获得代理之间存在的协调依赖性的状态无关表示(De Hauwere等,2010)。然后,可以将此信息传输到其他更复杂的任务环境(Vrancx等,2011)。这种转移学习原则提高了学习速度,因为代理人可以完全专注于手头问题的核心任务,并使用转移经验来解决协调问题。

This approach was later extended to detect sparse interactions that are only re- flected in the reward signal, several timesteps in the future (De Hauwere et al, 2011). Examples of such situations are for instance if the order in which goods arrive in a warehouse are important.
这种方法后来被扩展到检测稀疏的相互作用,这些相互作用仅在奖励信号中反映出来,未来几个时间步(De Hauwere等,2011)。 例如,如果货物到达仓库的顺序很重要,则会出现这种情况。
14.5Further Reading
Multi-agent reinforcement learning is a growing field of research, but quite some challenging research questions are still open. A lot of the work done in single-agent reinforcement learning, such as the work done in Bayesian RL, batch learning or transfer learning, has yet to find its way to the multi-agent learning community. General overviews of multi-agent systems are given by Weiss (Weiss, G., 1999), Wooldridge (Wooldridge, M., 2002) and more recently Shoham (Shoham, Y. and Leyton-Brown, K., 2009). For a thorough overview of the field of Game Theory the book by Gintis will be very useful (Gintis, H., 2000).
More focused on the domain of multi-agent reinforcement learning we recom- mend the paper by Bus¸oniu which gives an extensive overview of recent research and describes a representative selection of MARL algorithms in detail together with their strengths and weaknesses (Busoniu et al, 2008). Another track of multi-agent research considers systems where agents are not aware of the type or capabilities of the other agents in the system (Chalkiadakis and Boutilier, 2008).
An important issue in multi-agent reinforcement learning as well as in single agent reinforcement learning, is the fact that the reward signal can be delayed in time. This typically happens in systems which include queues, like for instance in network routing and job scheduling. The immediate feedback of taking an action can only be provided to the agent after the effect of the action becomes apparent,
e.g. after the job is processed. In (Verbeeck et al, 2005) a policy iteration approach based on learning automata is given, which is robust with respect to this type of delayed reward. In (Littman and Boyan, 1993) a value iteration based algorithm is described for routing in networks. An improved version of the algorithm is presented in (Steenhaut et al, 1997; Fakir, 2004). The improved version allows on one hand to use the feedback information in a more efficient way, and on the other hand it avoids instabilities that might occur due to careless exploration.
多智能体强化学习是一个不断发展的研究领域,但相当一些具有挑战性的研究问题仍然存在。在单一代理强化学习中所做的大量工作,例如在贝叶斯RL中完成的工作,批量学习或转移学习,尚未找到通向多智能体学习社区的方法。 Weiss(Weiss,G.,1999),Wooldridge(Wooldridge,M.,2002)以及最近的Shoham(Shoham,Y。和Leyton-Brown,K.,2009)给出了多智能体系统的一般概述。为了全面了解博弈论领域,Gintis的这本书将非常有用(Gintis,H.,2000)。
我们更多地关注多智能体强化学习的领域,我们推荐Bus¸oniu的论文,该论文对最近的研究进行了全面的概述,并详细描述了MARL算法的代表性选择及其优缺点(Busoniu等, 2008)。另一个多智能体研究的轨道考虑了代理人不了解系统中其他代理人的类型或能力的系统(Chalkiadakis和Boutilier,2008)。
多智能体强化学习以及单一代理强化学习中的一个重要问题是奖励信号可以及时延迟。这通常发生在包括队列的系统中,例如在网络路由和作业调度中。采取行动的即时反馈只能在行动效果明显后提供给代理人,
例如工作完成后。在(Verbeeck等,2005)中,给出了基于学习自动机的策略迭代方法,其对于这种类型的延迟奖励是稳健的。在(Littman和Boyan,1993)中,描述了基于值迭代的算法用于网络中的路由。该算法的改进版本在(Steenhaut等,1997; Fakir,2004)中提出。改进版本一方面允许以更有效的方式使用反馈信息,另一方面它避免了由于粗心探索而可能发生的不稳定性。
References
Aumann, R.: Subjectivity and Correlation in Randomized Strategies. Journal of Mathematical Economics 1(1), 67–96 (1974)
Bowling, M.: Convergence and No-Regret in Multiagent Learning. In: Advances in Neural Information Processing Systems 17 (NIPS), pp. 209–216 (2005)
Bowling, M., Veloso, M.: Convergence of Gradient Dynamics with a Variable Learning Rate. In: Proceedings of the Eighteenth International Conference on Machine Learning (ICML), pp. 27–34 (2001)
Bowling, M., Veloso, M.: Scalable Learning in Stochastic Games. In: AAAI Workshop on Game Theoretic and Decision Theoretic Agents (2002)
Busoniu, L., Babuska, R., De Schutter, B.: A comprehensive survey of multiagent reinforce- ment learning. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews 38(2), 156–172 (2008)
Chalkiadakis, G., Boutilier, C.: Sequential Decision Making in Repeated Coalition Forma- tion under Uncertainty. In: Parkes, P.M., Parsons (eds.) Proceedings of 7th Int. Conf. on Autonomous Agents and Multiagent Systems (AAMAS 2008), pp. 347–354 (2008)
Claus, C., Boutilier, C.: The Dynamics of Reinforcement Learning in Cooperative Multiagent Systems. In: Proceedings of the National Conference on Artificial Intelligence, pp. 746– 752. John Wiley & Sons Ltd. (1998)
De Hauwere, Y.M., Vrancx, P., Nowe´, A.: Learning Multi-Agent State Space Representations. In: Proceedings of the 9th International Conference on Autonomous Agents and Multi- Agent Systems, Toronto, Canada, pp. 715–722 (2010)
De Hauwere, Y.M., Vrancx, P., Nowe´, A.: Detecting and Solving Future Multi-Agent Inter- actions. In: Proceedings of the AAMAS Workshop on Adaptive and Learning Agents, Taipei, Taiwan, pp. 45–52 (2011)
Dorigo, M., Stu¨tzle, T.: Ant Colony Optimization. Bradford Company, MA (2004)
Fakir, M.: Resource Optimization Methods for Telecommunication Networks. PhD thesis, Department of Electronics and Informatics, Vrije Universiteit Brussel, Belgium (2004) Foster, D., Young, H.: Regret Testing: A Simple Payoff-based Procedure for Learning Nash Equilibrium. University of Pennsylvania and Johns Hopkins University, Mimeo (2003)
Gillette, D.: Stochastic Games with Zero Stop Probabilities. Ann. Math. Stud. 39, 178–187 (1957)
Gintis, H.: Game Theory Evolving. Princeton University Press (2000)
Greenwald, A., Hall, K., Serrano, R.: Correlated Q-learning. In: Proceedings of the Twentieth International Conference on Machine Learning, pp. 242–249 (2003)
Guestrin, C., Lagoudakis, M., Parr, R.: Coordinated Reinforcement Learning. In: Proceedings of the 19th International Conference on Machine Learning, pp. 227–234 (2002a)
Guestrin, C., Venkataraman, S., Koller, D.: Context-Specific Multiagent Coordination and Planning with Factored MDPs. In: 18th National Conference on Artificial Intelligence, pp. 253–259. American Association for Artificial Intelligence, Menlo Park (2002b)
Hart, S., Mas-Colell, A.: A Reinforcement Procedure Leading to Correlated Equilibrium.
Economic Essays: A Festschrift for Werner Hildenbrand, 181–200 (2001)
Hu, J., Wellman, M.: Nash Q-learning for General-Sum Stochastic Games. The Journal of Machine Learning Research 4, 1039–1069 (2003)
Kapetanakis, S., Kudenko, D.: Reinforcement Learning of Coordination in Cooperative Multi-Agent Systems. In: Proceedings of the National Conference on Artificial Intelli- gence, pp. 326–331. AAAI Press, MIT Press, Menlo Park, Cambridge (2002)
Kapetanakis, S., Kudenko, D., Strens, M.: Learning to Coordinate Using Commitment Se- quences in Cooperative Multiagent-Systems. In: Proceedings of the Third Symposium on Adaptive Agents and Multi-agent Systems (AAMAS-2003), p. 2004 (2003)
Kok, J., Vlassis, N.: Sparse Cooperative Q-learning. In: Proceedings of the 21st International Conference on Machine Learning. ACM, New York (2004a)
Kok, J., Vlassis, N.: Sparse Tabular Multiagent Q-learning. In: Proceedings of the 13th Benelux Conference on Machine Learning, Benelearn (2004b)
Kok, J., Vlassis, N.: Collaborative Multiagent Reinforcement Learning by Payoff Propaga- tion. Journal of Machine Learning Research 7, 1789–1828 (2006)
Kok, J., ’t Hoen, P., Bakker, B., Vlassis, N.: Utile Coordination: Learning Interdependencies among Cooperative Agents. In: Proceedings of the IEEE Symposium on Computational Intelligence and Games (CIG 2005), pp. 29–36 (2005)
Kononen, V.: Asymmetric Multiagent Reinforcement Learning. In: IEEE/WIC International Conference on Intelligent Agent Technology (IAT 2003), pp. 336–342 (2003)
Ko¨no¨nen, V.: Policy Gradient Method for Team Markov Games. In: Yang, Z.R., Yin, H., Everson, R.M. (eds.) IDEAL 2004. LNCS, vol. 3177, pp. 733–739. Springer, Heidelberg (2004)
Leyton-Brown, K., Shoham, Y.: Essentials of Game Theory: A Concise Multidisciplinary Introduction. Synthesis Lectures on Artificial Intelligence and Machine Learning 2(1), 1–88 (2008)
Littman, M.: Markov Games as a Framework for Multi-Agent Reinforcement Learning. In: Proceedings of the Eleventh International Conference on Machine Learning, pp. 157–163. Morgan Kaufmann (1994)
Littman, M.: Friend-or-Foe Q-learning in General-Sum Games. In: Proceedings of the Eigh- teenth International Conference on Machine Learning, pp. 322–328. Morgan Kaufmann (2001a)
Littman, M.: Value-function Reinforcement Learning in Markov Games. Cognitive Systems Research 2(1), 55–66 (2001b), http://www.sciencedirect.com/science/ article/B6W6C-430G1TK-4/2/822caf1574be32ae91adf15de90becc4, doi:10.1016/S1389-0417(01)00015-8
Littman, M., Boyan, J.: A Distributed Reinforcement Learning Scheme for Network Routing. In: Proceedings of the 1993 International Workshop on Applications of Neural Networks to Telecommunications, pp. 45–51. Erlbaum (1993)
Mariano, C., Morales, E.: DQL: A New Updating Strategy for Reinforcement Learning Based on Q-Learning. In: Flach, P.A., De Raedt, L. (eds.) ECML 2001. LNCS (LNAI), vol. 2167, pp. 324–335. Springer, Heidelberg (2001)
Melo, F., Veloso, M.: Learning of Coordination: Exploiting Sparse Interactions in Multiagent Systems. In: Proceedings of the 8th International Conference on Autonomous Agents and Multi-Agent Systems, pp. 773–780 (2009)
Nash, J.: Equilibrium Points in n-Person Games. Proceedings of the National Academy of Sciences of the United States of America, 48–49 (1950)
Peshkin, L., Kim, K., Meuleau, N., Kaelbling, L.: Learning to Cooperate via Policy Search. In: Proceedings of the 16th Conference on Uncertainty in Artificial Intelli- gence, UAI 2000, pp. 489–496. Morgan Kaufmann Publishers Inc., San Francisco (2000), http://portal.acm.org/citation.cfm?id=647234.719893
Russell, S., Norvig, P.: Artificial Intelligence: A Modern Approach, 2nd edn. Prentice-Hall,
Englewood Cliffs (2003)
Sastry, P., Phansalkar, V., Thathachar, M.: Decentralized Learning of Nash Equilibria in Multi-Person Stochastic Games with Incomplete Information. IEEE Transactions on Sys- tems, Man and Cybernetics 24(5), 769–777 (1994)
Shapley, L.: Stochastic Games. Proceedings of the National Academy of Sciences 39(10), 1095–1100 (1953)
Shoham, Y., Leyton-Brown, K.: Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations. Cambridge University Press (2009)
Singh, S., Kearns, M., Mansour, Y.: Nash Convergence of Gradient Dynamics in General- Sum Games. In: Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence, pp. 541–548 (2000)
Smith, J.: Evolution and the Theory of Games. Cambridge Univ. Press (1982)
Sobel, M.: Noncooperative Stochastic Games. The Annals of Mathematical Statistics 42(6), 1930–1935 (1971)
Spaan, M., Melo, F.: Interaction-Driven Markov Games for Decentralized Multiagent Plan- ning under Uncertainty. In: Proceedings of the 7th International Conference on Au- tonomous Agents and Multi-Agent Systems (AAMAS), pp. 525–532. International Foun- dation for Autonomous Agents and Multiagent Systems (2008)
Steenhaut, K., Nowe, A., Fakir, M., Dirkx, E.: Towards a Hardware Implementation of Re- inforcement Learning for Call Admission Control in Networks for Integrated Services. In: Proceedings of the International Workshop on Applications of Neural Networks to Telecommunications, vol. 3, p. 63. Lawrence Erlbaum (1997)
Stevens, J.P.: Intermediate Statistics: A Modern Approach. Lawrence Erlbaum (1990) Sutton, R., McAllester, D., Singh, S., Mansour, Y.: Policy Gradient Methods for Reinforce-
ment Learning with Function Approximation. In: Advances in Neural Information Pro- cessing Systems, vol. 12(22) (2000)
Tsitsiklis, J.: Asynchronous stochastic approximation and Q-learning. Machine Learn- ing 16(3), 185–202 (1994)
Tuyls, K., Nowe´, A.: Evolutionary Game Theory and Multi-Agent Reinforcement Learning.
The Knowledge Engineering Review 20(01), 63–90 (2005)
Verbeeck, K.: Coordinated Exploration in Multi-Agent Reinforcement Learning. PhD thesis, Computational Modeling Lab, Vrije Universiteit Brussel, Belgium (2004)
Verbeeck, K., Nowe, A., Tuyls, K.: Coordinated Exploration in Multi-Agent Reinforcement Learning: An Application to Loadbalancing. In: Proceedings of the 4th International Con- ference on Autonomous Agents and Multi-Agent Systems (2005)
Vrancx, P., Tuyls, K., Westra, R.: Switching Dynamics of Multi-Agent Learning. In: Pro- ceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems (AAMAS 2008), vol. 1, pp. 307–313. International Foundation for Autonomous Agents and Multiagent Systems, Richland (2008a), http://portal.acm.org/citation.cfm?id=1402383.1402430
Vrancx, P., Verbeeck, K., Nowe, A.: Decentralized Learning in Markov Games. IEEE Trans-
actions on Systems, Man, and Cybernetics, Part B 38(4), 976–981 (2008b)
Vrancx, P., De Hauwere, Y.M., Nowe´, A.: Transfer learning for Multi-Agent Coordination. In: Proceedings of the 3th International Conference on Agents and Artificial Intelligence, Rome, Italy, pp. 263–272 (2011)
Weiss, G.: Multiagent Systems, A Modern Approach to Distributed Artificial Intelligence.
The MIT Press (1999)
Wheeler Jr., R., Narendra, K.: Decentralized Learning in Finite Markov Chains. IEEE Trans- actions on Automatic Control 31(6), 519–526 (1986)
Williams, R.: Simple Statistical Gradient-Following Algorithms for Connectionist Reinforce- ment Learning. Machine Learning 8(3), 229–256 (1992)
Wooldridge, M.: An Introduction to Multi Agent Systems. John Wiley and Sons Ltd. (2002) Wunder, M., Littman, M., Babes, M.: Classes of Multiagent Q-learning Dynamics with epsilon-greedy Exploration. In: Proceedings of the 27th International Conference on Ma-
chine Learning, Haifa, Israel, pp. 1167–1174 (2010)
Zinkevich, M.: Online Convex Programming and Generalized Infinitesimal Gradient Ascent.
In: Machine Learning International Conference, vol. 20(2), p. 928 (2003)
Zinkevich, M., Greenwald, A., Littman, M.: Cyclic equilibria in Markov games. In: Advances in Neural Information Processing Systems, vol. 18, p. 1641 (2006)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184218.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
