大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
如果要主线程不等待子线程结束再结束,可以把子线程设置为守护线程, 主线程退出后子线程直接销毁。
如果想让 添加数据的子线程执行完之后再执行读取数据的代码 join()方法,线程等待,
1.多线程执行带有参数的任务
Thread 类执行任务并给任务传参数有两种方式:
- args: 指定将来调用 函数的时候 传递什么数据过去
args参数指定的一定是一个元组类型- kwargs 表示以字典方式给执行任务传参
以元组形式传参
import threading import time g_nums = [1,2] def test1(temp): temp.append(33) print("-----in test1 temp=%s-----"% str(temp)) def test2(temp): print("-----in test2 temp=%s-----"% str(temp)) def main(): t1 = threading.Thread(target=test1,args=(g_nums,)) # 加上要传递的参数,元组类型 t2 = threading.Thread(target=test2, args=(g_nums,)) # args 元组类型 t1.start() time.sleep(1) t2.start() time.sleep(1) print("-----in main temp=%s-----"% str(g_nums)) if __name__ == '__main__': main()结果:
—–in test1 temp=[1, 2, 33]—–
—–in test2 temp=[1, 2, 33]—–
—–in main temp=[1, 2, 33]—–
以字典方式进行传参 (字典的key值和参数名要一致)
import threading def eat(name, number): print("eating :%s number :%d" % (name, number)) def watch(name, type): print("watch : %s type:%s" % (name, type)) if __name__ == '__main__': eat_thread = threading.Thread(target=eat, kwargs={"name": "爆米花", "number": 1}) watch_thread = threading.Thread(target=watch, kwargs={"name": "电影", "type": "科幻"}) eat_thread.start() watch_thread.start()运行结果:
eating :爆米花 number :1
watch : 电影 type:科幻
2.线程的注意点
- 线程之间执行是无序的
- 主线程会等待所有的子线程执行结束再结束
- 线程之间共享全局变量
- 线程之间共享全局变量数据出现错误问题
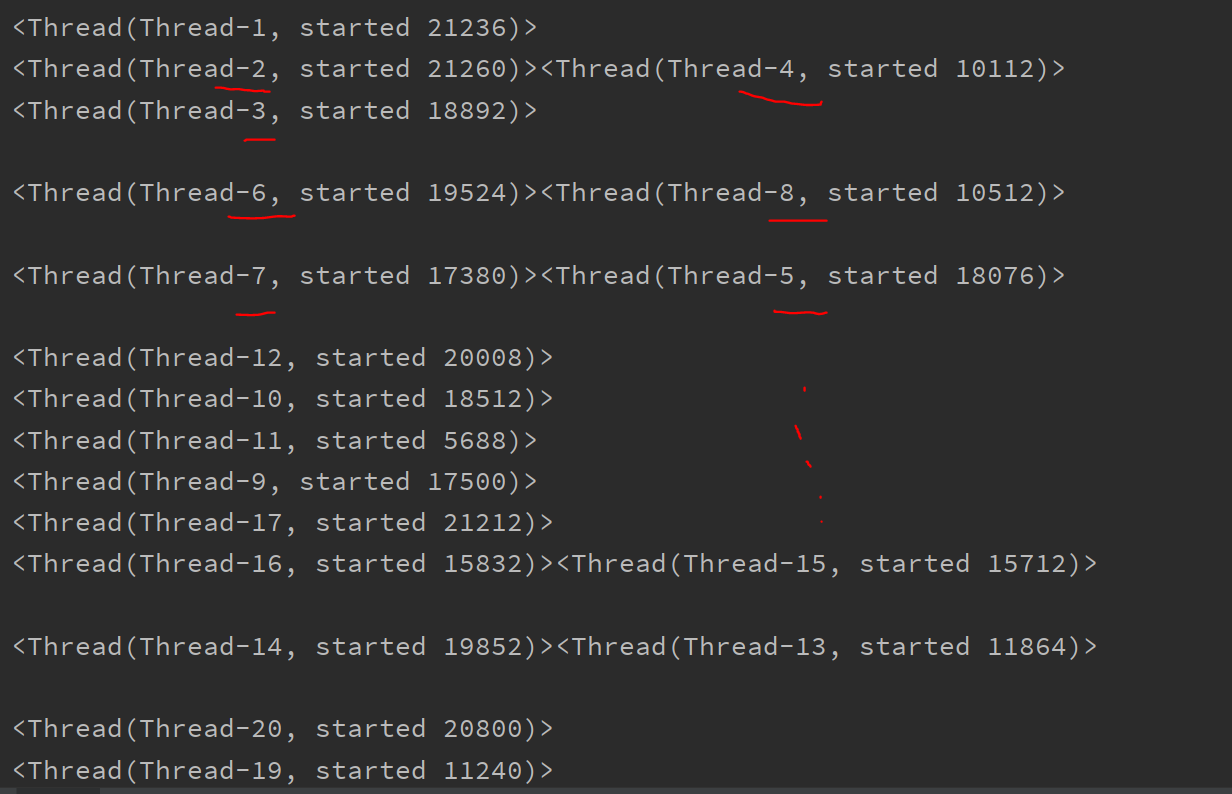
线程之间执行是无序的
import threading import time def task(): time.sleep(0.2) # 获取当前线程 print(threading.current_thread()) if __name__ == '__main__': for i in range(20): # 每循环一次创建一个子线程 sub_thread = threading.Thread(target=task) # 启动子线程 sub_thread.start()通过下方的运行结果可以看出, 线程之间的执行确实是无序的,具体哪个线程执行是由cpu调度决定的
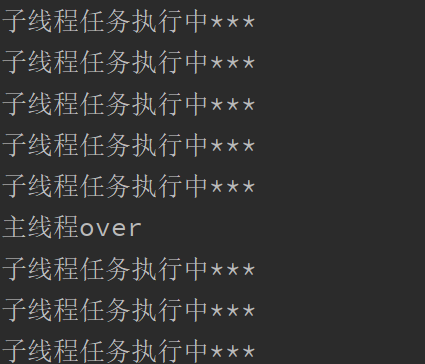
主线程会等待所有的子线程执行结束再结束
import threading import time def task(): while True: print("子线程任务执行中***") time.sleep(0.2) if __name__ == '__main__': # 创建子线程 sub_thread = threading.Thread(target=task) sub_thread.start() # 主线程延迟执行1秒 time.sleep(1) print("主线程over")运行结果: 子线程一直会执行,主线程会等待子线程结束再结束
如果要主线程不等待子线程结束再结束,可以把子线程设置为守护线程, 主线程退出后子线程直接销毁。
第一种方式: daemon=True
# daemon=True 表示创建的子线程守护主线程,主线程退出子线程直接销毁 sub_thread = threading.Thread(target=task, daemon=True)第二种方式:setDaemon(True)
sub_thread = threading.Thread(target=task) sub_thread.setDaemon(True) sub_thread.start()
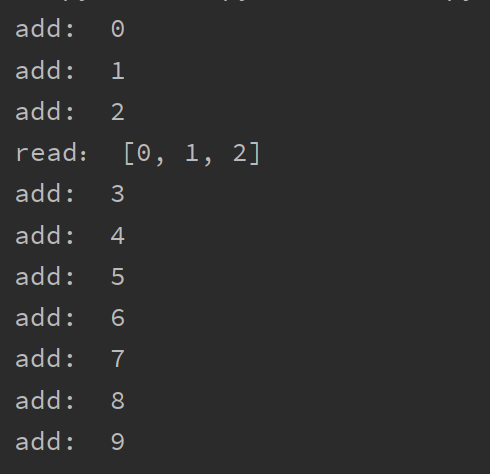
线程之间共享全局变量
import threading # 定义全局变量 g_list = [] # 添加数据 def add_data(): for i in range(10): # 每循环一次就把数据添加到全局变量中 g_list.append(i) print("add: ", i) # 读取数据 def read_data(): print("read:", g_list) if __name__ == '__main__': # 创建子线程 add_thread = threading.Thread(target=add_data) read_thread = threading.Thread(target=read_data) add_thread.start() read_thread.start()运行结果: 可以共同访问一个变量
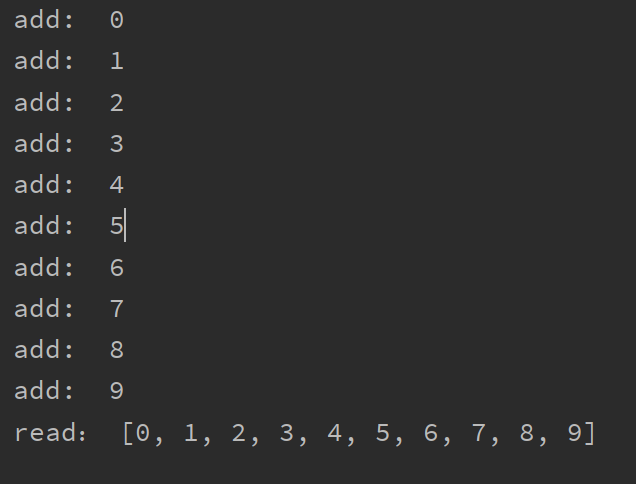
如果想让 添加数据的子线程执行完之后再执行读取数据的代码 join()方法,线程等待,
join()方法,线程等待(线程同步的一种方式,保证同一时刻只能有一个线程去操作全局变量,同步就是按照预先的先后次序进行运行,比如现实生活中的对讲机,你说完,我再说),让第一个线程执行完之后再执行第二个线程,保证数据不会有问题
add_thread.start() add_thread.join() read_thread.start()

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184204.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
