大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
决策树:什么是基尼系数
在我翻译学习这篇Random Forests for Complete Beginners的时候,对基尼系数和它相关的一些中文表达充满了疑问,查了一些资料以后,完成了这篇文章。其中基尼杂质系数的计算和解释参考了A Simple Explanation of Gini Impurity。
如果你查看scikit-learn中DecisionTreeClassifier的文档,你会看到这样的参数:


RandomForestClassifier文档里也谈到了gini。那么两者都提到并作为默认标准的基尼系数是什么?
名词辨析
你在不同的地方往往能看到关于基尼的不同名词,我查询了一大堆文献,发现它们的使用遵循以下规律:
- 基尼杂质系数/基尼不纯系数(Gini Impurity):等效于我们通常说的基尼系数,在上面提到的分类器文档里的就是它,计算方法在后面将提到。
- 基尼增益系数/基尼系数增益(Gini Gain):表征某个划分对基尼系数的增益,使用原基尼杂质系数减去按样本占比加权的各个分支的基尼杂质系数来计算,计算方法在后面将提到。
- 基尼指数(Gini index):这是一个尴尬的问题,因为有人把它等价于gini impurity,但也有人把它用作gini coefficient。需要结合上下文来判断。
- 基尼系数(Gini coefficient):表征在二分类问题中,正负两种标签的分配合理程度。当G=0,说明正负标签的预测概率均匀分配,模型相当于是随机排序。这个名词也在经济学中也有使用,本质是相同的,是用来表征一个地区财富的分配的合理程度。当G=0,说明财富均匀分配。
基尼杂质系数(Gini Impurity)的理解和计算
训练决策树包括将当前数据分成两个分支。假设我们有以下数据点:
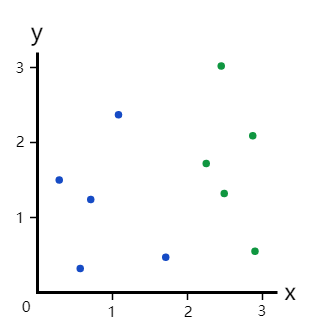
现在,我们的分支里有5个蓝点和5个绿点。
如果我们在x=2处进行划分:
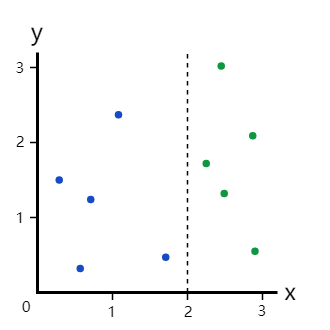
这很明显是个完美划分,因为它把数据集分成了两个分支:
- 左分支全是蓝点
- 右分支全是绿点
但如果我们在x=1.5处进行划分呢?
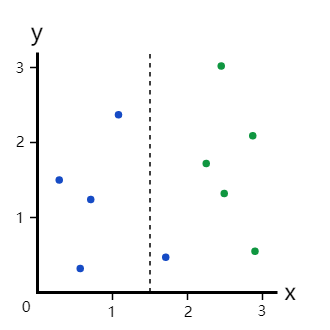
这个划分把数据集分成了两个分支:
- 左分支,4个蓝点
- 右分支,1个蓝点+5个绿点
很明显,这种划分更糟糕,但我们如何量化呢?
解决方法就是基尼杂质系数。
示例1:整个数据集
我们来计算整个数据集的基尼杂质系数。
如果随机选择一个数据点并随机给它分类,我们错误分类数据点的概率是多少?
| 我们的选择 | 实际的分类 | 可能性 | 对错 |
|---|---|---|---|
| 蓝 | 蓝 | 25% | ✓ |
| 红 | 蓝 | 25% | ❌ |
| 蓝 | 红 | 25% | ❌ |
| 红 | 红 | 25% | ✓ |
我们只在上面的两个事件中对其进行了错误的分类。因此,我们的错误概率是25% + 25% = 50%,也即基尼杂质系数是0.5.
公式
G = ∑ i = 1 C p ( i ) ∗ [ 1 − p ( i ) ] G = \sum_{i=1}^C {p(i)*[1-p(i)]} G=i=1∑Cp(i)∗[1−p(i)]
- C: 类别数
- p(i):一个样本被归类进第i类的概率
上面这个例子计算式即为:
G = p ( 1 ) ∗ [ 1 − p ( 1 ) ] + p ( 2 ) ∗ [ 1 − p ( 2 ) ] = 0.5 ∗ [ 1 − 0.5 ] + 0.5 ∗ [ 1 − 0.5 ] = 0.5 \begin{aligned} G&=p(1)*[1-p(1)]+p(2)*[1-p(2)]\\ &=0.5*[1-0.5]+0.5*[1-0.5]\\ &=0.5 \end{aligned} G=p(1)∗[1−p(1)]+p(2)∗[1−p(2)]=0.5∗[1−0.5]+0.5∗[1−0.5]=0.5
示例2:完美划分
完美划分后数据集的基尼杂质系数是多少?
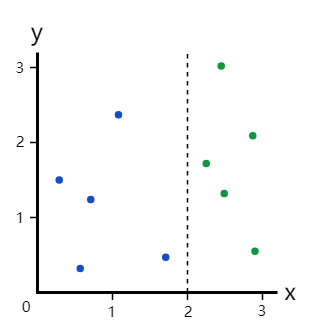
左分支的基尼杂质系数:
G l e f t = 1 ∗ ( 1 − 1 ) + 0 ∗ ( 1 − 0 ) = 0 G_{left}=1∗(1−1)+0∗(1−0)=0 Gleft=1∗(1−1)+0∗(1−0)=0
右分支的基尼杂质系数:
G r i g h t = 0 ∗ ( 1 − 0 ) + 1 ∗ ( 1 − 1 ) = 0 G_{right}=0∗(1−0)+1∗(1−1)=0 Gright=0∗(1−0)+1∗(1−1)=0
它们没有杂质,所以基尼杂质系数自然为0!此时就是最优情况。
示例3:不完美划分
那不完美划分呢?
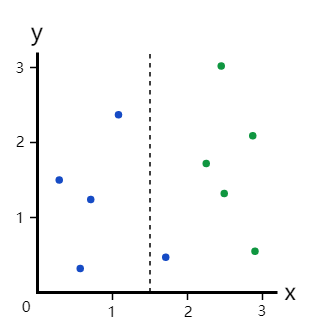
易知左分支:
G l e f t = 0 G_{left}=0 Gleft=0
右分支:
G r i g h t = 1 6 ∗ ( 1 − 1 6 ) + 5 6 ∗ ( 1 − 5 6 ) = 5 18 = 0.278 \begin{aligned} G_{right}&=\frac{1}{6}*(1-\frac{1}{6})+\frac{5}{6}*(1-\frac{5}{6})\\ &=\frac{5}{18}\\ &=0.278 \end{aligned} Gright=61∗(1−61)+65∗(1−65)=185=0.278
划分的选择
终于到了回答之前提出问题的时候了:我们如何量化划分的效果?
对这个划分:
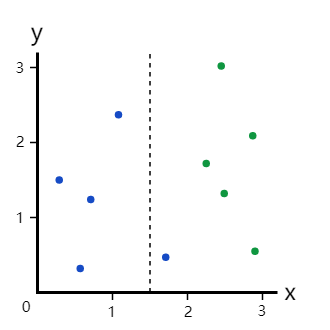
我们已经计算了基尼系数杂质:
- 划分前(整个数据集):0.5
- 左分支:0
- 右分支:0.278
我们将基于每个分支中的样本占比来进行加权来以确定划分的基尼增益。由于左分支有4个样本,右分支有6个样本,我们得到:
( 0.4 ∗ 0 ) + ( 0.6 ∗ 0.278 ) = 0.167 (0.4∗0)+(0.6∗0.278)=0.167 (0.4∗0)+(0.6∗0.278)=0.167
因此,我们用这个划分“降低”的杂质量是
0.5 − 0.167 = 0.333 0.5−0.167=0.333 0.5−0.167=0.333
这就被称为基尼增益系数。越好的划分基尼增益系数越大,比如此处0.5>0.333.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/184168.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
