大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
在如今这个电子产品泛滥的年代,仅仅靠品牌或是外观已经不足以辨别产品的优劣,其内置的处理器自然也就成为了分辨产品是否高端的标准之一。那么我们今天就不妨好好了解一下近几年来电子产品中较为主流的RAM处理器。


在这之前让我们先简单认识一下处理器的架构。所谓处理器架构是CPU厂商给属于同一系列的CPU产品定的一个规范,主要目的是为了区分不同类型CPU的重要标示。目前市面上的CPU指令集分类主要分有两大阵营,一个是intel、AMD为首的复杂指令集CPU,另一个是以IBM、ARM为首的精简指令集CPU。不同品牌的CPU,其产品的架构也不相同,例如,Intel、AMD的CPU是X86架构的,而IBM公司的CPU是PowerPC架构,ARM公司是ARM架构。
下面我们将详细了解近年来ARM公司发布的数款A系列处理器。ARM公司的Cortex-A系列处理器适用于具有高计算要求、运行丰富操作系统以及提供交互媒体和图形体验的应用领域。
Cortex-A73
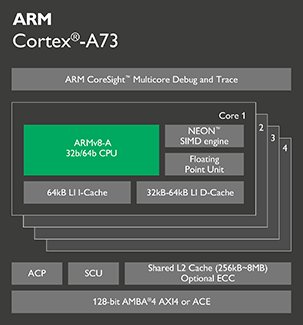
这是ARM 2016年发布的最新A系列处理器,Cortex-A73支持全尺寸ARMv8-A构架,ARMv8-A是ARM公司的首款支持64位指令集的处理器架构,包括ARM TrustZone技术、NEON、虚拟化和加密技术。所以无论是32位还是64位,Cortex-A73都可以提供适应性最强的移动应用生态开发环境。Cortex-A73包括128位 AMBR 4 ACE接口和ARM的big.LITTLE系统一体化接口,采用了目前最先进的10nm技术制造,可以提供比Cortex-A72高出30%的持续处理能力,非常适合移动设备和消费级设备使用。预计今年晚些时候到2017年,Cortex-A73处理器将会逐渐覆盖到我们合作伙伴的高端智能手机、平板电脑、翻盖式移动设备、数字电视等一系列消费电子设备。
Cortex-A72

Cortex-A72最早发布于2015年年初,也是基于ARMv8-A架构,采用台积电16nm FinFET制造工艺,Cortex-A72可在芯片上单独实现性能,也可以搭配Cortex-A53处理器与ARMCoreLinkTMCCI高速缓存一致性互连(CacheCoherentInterconnect)构成ARMbig.LITTLETM配置,进一步提升能效。在相同的移动设备电池寿命限制下,Cortex-A72能相较基于Cortex-A15的设备提供3.5倍的性能表现,相比于Cortex-A57也有约1.8倍的性能提升,展现出了优异的整体功耗效率。Cortex-A72是目前基于ARMv8-A架构处理器中使用最广泛的处理器之一,主要其应用市场包括高端智能手机、大屏幕的移动设备、企业网路设备、服务器、无线基台、数字电视。
Cortex-A57

Cortex-A57是ARM针对2013年、2014年和2015年设计起点的CPU产品系列的旗舰级CPU,它也是ARM首次采用64位ARMv8-A架构CPU,而且通过Aarch32执行状态,保持与ARMv7架构的完全后向兼容性。除了ARMv8的架构优势之外,Cortex-A57还提高了单个时钟周期性能,比高性能的Cortex-A15 CPU高出了20%至40%。它还改进了二级高速缓存的的设计以及内存系统的其他组件,极大的提高了能效。Cortex-A57将为移动系统提供超高能的性能,而借助big.LITTLE,SoC能以很低的平均功耗做到这一点。其主要面对的是中高端电脑,平板电脑以及服务器产品。
Cortex-A53

Cortex-A53同样是采取了ARMv8-A架构,能够支持32位的ARMv7代码和64位代码的AArch64执行状态。A53架构特点是功耗降低、能效提高。其目标是28nm HPM制造工艺下、运行SPECint2000测试时,单个核心的功耗不超过0.13W。它提供的性能比Cortex-A7处理器的功率效率更高,并能够作为一个独立的主要的应用处理器,或者搭配Cortex-A57处理器构成big.LITTLE配置。Cortex-A53在相同的频率下,能提供比Cortex-A9更高的效能。其主要面对的是中高端电脑,平板电脑,机顶盒,数字电视等。
Cortex-A35

Cortex-A35是基于ARMv8-A 64位架构设计的一款低功耗CPU,其目的是为了取代此前32位Cortex-A7和Cortex-A5两颗老核心,采用和A53/A7类似的顺序有限双发射设计,同时融入了A72的一些新特性,并在前端重新设计了指令预取单元,提升了分支预测精度。此外,A35还采用了A53的缓存、内存架构,可配置8-64KB一级指令和数据缓存、128KB-1MB二级缓存,加入了NEON/FP单元,改进了存储性能,支持完整流水线的双精度乘法,还为CPU核心、NEON流水线都配备了硬件保留状态(独立电源域)以提升电源管理效率。在同样的工艺、频率下,A35的功耗比A7低大约10%,同时性能提升6-40%。而对比A53,它可以保留80-100%的性能,但是功耗降低32%、面积缩小25%,能效提升25%。A35还可以和A53、A57、A72等大核心搭配,组成big.LITTLE混合架构系统,进一步提升系统能效。其主要定位于低功耗的低端手机、可穿戴、物联网等领域。
Cortex-A32

这是ARM 新一代构架中,唯一一个 32 位(ARMv7-A )架构的处理器,但 A32 就像是 32 位版的 A35,目标很明显,就是在效能比本来就逆天的 A35 的基础上进一步控制功耗。A32 架构主打芯片面积、功耗控制和能耗比,其停留在 32 位(ARMv7-A 指令集),指令预取单元针对效率进行了重新设计,一、二级暂存、浮点和 DSP 操作性能则针对速度进行了改进,并引入了新的电源管理特性。其支持 TrustZone 安全加密、NEON SIMD 指令集、DSP / SIMD 扩展、VFPv4 浮点计算、虚拟硬件等。A32 可以在 32 位下提供和 A35 一样的性能。但更低功耗,让它的效能比(单位电能产出的性能)比 A35 还要高 10%、比 A5 高 30%、比 A7 高 25%。A35 可以透过提升频率达到 A53 80-100% 性能,也就是说,A32 也可以在 32 位下达到同样的性能等级,这时候的芯片面积只有 A53 的 68%,而功耗则只有 A53 的 61%。
在 64 位之下,A35 都有代替 A53 架构的实力,而在 32 位中,A32 就已经是完胜所有人的境界了,而且比起 64 位的 A35 架构,32 位的 A32 更适合用在穿戴设备和物联网产品上。
Cortex-A17
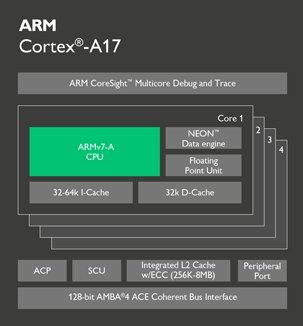
A17仍然基于32位ARMv7-A指令集,初期会采用28nm工艺,后期进化到20nm。本质架构和A12一样都是双宽度、乱序发射,仅仅是改进了外部互联,引入了新的一致性总线AMBA4 ACE,可以更快速地连接内存控制器,从而改善性能和能效。得益于这个新的总线,A17可以支持多核心SoC的完整内存一致性操作,能够参与big.LITTLE双架构混合方案,在特定频率、工艺、内存条件下,A17的性能比A12提升大约40%。在某些特定的环境中,A17的性能已经可以和A15处于一个档次了,但是功耗更低、能效更高。虽然在命名上排在Cortex-A15之上,但其定位中端,而不是高端。
Cortex-A15

Cortex-A15最早在2010年发布,基于32位ARMv7-A架构。A15和A9同样具备乱序执行,但是Cortex-A15具备(两倍)的指令发射端口和执行资源,指令解码能力也要高出50%,动态分支预测能力更强(采用了多层级分支表缓存),指令拾取带宽更强(128 bit vs 64 bit),这些都能让A15的流水线执行具备更高的效率。除此以外,A15采用了VFPv4浮点单元设计,能执行FMA指令以及硬件除法指令,相较而言A9的峰值向量浮点性能基本上只有A15的一半。Cortex-A15处理器可以应用在智能手机、平板电脑、移动计算、高端数字家电、服务器和无线基础结构等设备上。
Cortex-A9

ARM Cortex-A9采用ARMv7-A架构,目前我们能见到的四核处理器大多都是属于Cortex-A9系列。 Cortex-A9 处理器的设计旨在打造最先进的、高效率的、长度动态可变的、多指令执行超标量体系结构,提供采用乱序猜测方式执行的 8 阶段管道处理器,凭借范围广泛的消费类、网络、企业和移动应用中的前沿产品所需的功能,它可以兼具高性能和高能效。Cortex-A9 微体系结构既可用于可伸缩的多核处理器(Cortex-A9 MPCore多核处理器),也可用于更传统的处理器(Cortex-A9单核处理器)。可伸缩的多核处理器和单核处理器支持 16、32 或 64KB 4 路关联的 L1 高速缓存配置,对于可选的 L2 高速缓存控制器,最多支持 8MB 的 L2 高速缓存配置,它们具有极高的灵活性,均适用于特定应用领域和市场。
Cortex-A8

ARM Cortex-A8处理器,基于ARMv7-A架构,是目前使用的单核手机中最为常见的产品。Cortex-A8处理器是首款基于ARMv7体系结构的产品,能够将速度从600MHz提高到1GHz以上。Cortex-A8处理器可以满足需要在300mW以下运行的移动设备的功率优化要求;以及需要2000 Dhrystone MIPS的消费类应用领域的性能优化要求。Cortex-A8 高性能处理器目前已经非常成熟,从手机到上网本、DTV、打印机和汽车信息娱乐,Cortex-A8处理器都提供了可靠的高性能解决方案。
Cortex-A7

Cortex-A7采用ARMv7-A架构,它的特点是在保证性能的基础上提供了出色的低功耗表现。Cortex-A7处理器的体系结构和功能集与Cortex-A15 处理器完全相同,不同这处在于,Cortex-A7 处理器的微体系结构侧重于提供最佳能效,因此这两种处理器可在big.LITTLE(大小核大小核心伴侣结构)配置中协同工作,从而提供高性能与超低功耗的终极组合。单个Cortex-A7处理器的能源效率是Cortex-A8处理器的5倍,性能提升50%,而尺寸仅为后者的五分之一。
Cortex-A5

Cortex-A5处理器同样基于ARMv7-A架构,它是能效最高、成本最低的处理器,能够向最广泛的设备提供最基础的 Internet 访问。Cortex-A5 处理器在指令以及功能方面与更高性能的 Cortex-A8、Cortex-A9 和 Cortex-A15 处理器完全兼容 – 一直到操作系统级别。Cortex-A5 处理器还保持与经典 ARM 处理器(包括 ARM926EJ-S、ARM1176JZ-S 和 ARM7TDMI?)的向后应用程序兼容性。其定位于从入门级智能手机、低成本手机和智能移动设备以及基础工业设备。
为了给大家介绍一个更直观的感受,请看下面这张图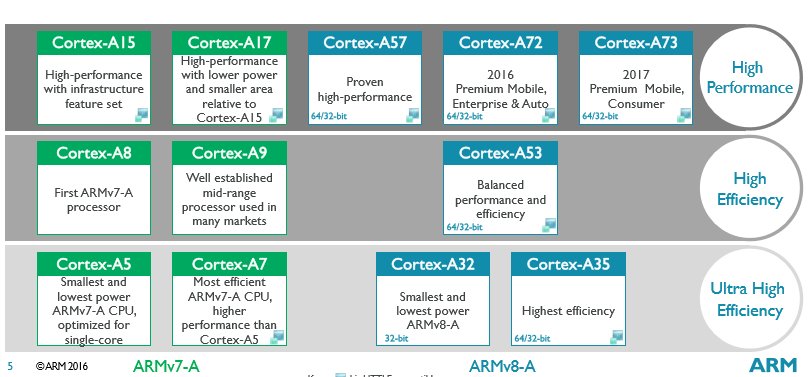
如图所示,绿色的部分都是v7-A的架构,蓝色的是v8-A架构,基本上绿色都是可以支持到32和64位的,除了A32,只支持到32位。在右边的每个部分,比如说需要高效能的最上面的A15-A73这个部分是最高效的,接下来就是比较注重整个效率的部分了,中间那个部分是比较高效率的,最下面那栏的是效率最好的,在电池的效能方面达到了最好的标准。
如果非要给他们一个排序的话,从高到低大体上可排序为:Cortex-A73处理器、Cortex-A72处理器、Cortex-A57处理器、Cortex-A53处理器、Cortex-A35处理器、Cortex-A32处理器、Cortex-A17处理器、Cortex-A15处理器、Cortex-A7处理器、Cortex-A9处理器、Cortex-A8处理器、Cortex-A5处理器。
| 架构 | 处理器家族 |
|---|---|
| ARMv1 | ARM1 |
| ARMv2 | ARM2、ARM3 |
| ARMv3 | ARM6, ARM7 |
| ARMv4 | StrongARM、ARM7TDMI、ARM9TDMI |
| ARMv5 | ARM7EJ、ARM9E、ARM10E、XScale |
| ARMv6 | ARM11、ARM Cortex-M |
| ARMv7 | ARM Cortex-A、ARM Cortex-M、ARM Cortex-R |
| ARMv8 | Cortex-A50[9] |
以上就是ARM Cortex-A系列处理器的基本资料,参照百度百科等多家网站整理总结,如有不妥之处欢迎指正。希望对您有所帮助。
全文转自:https://news.znds.com/article/13324.html
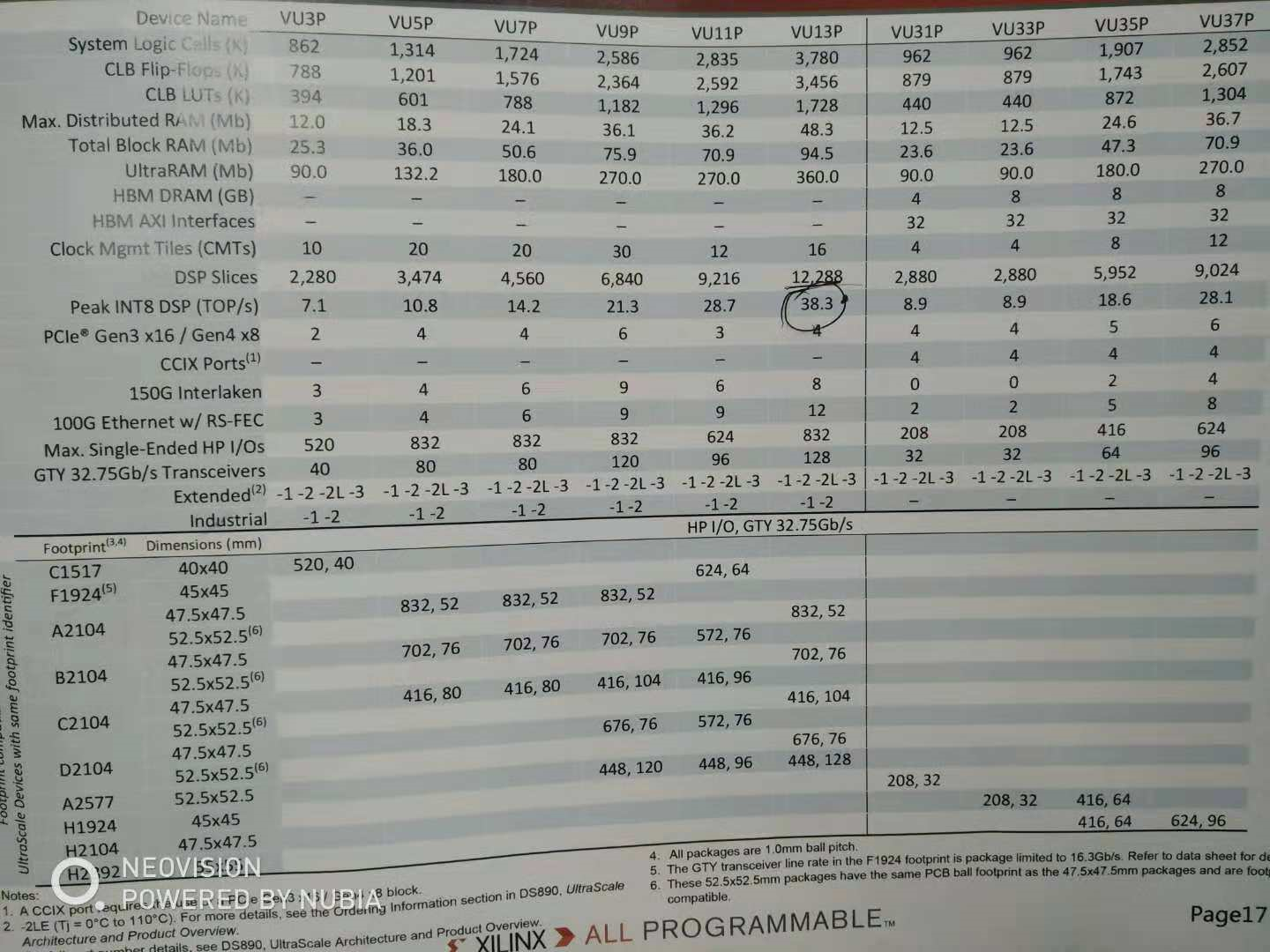
FPGA浮点运算性能计算
https://www.xzbu.com/8/view-6826917.htm

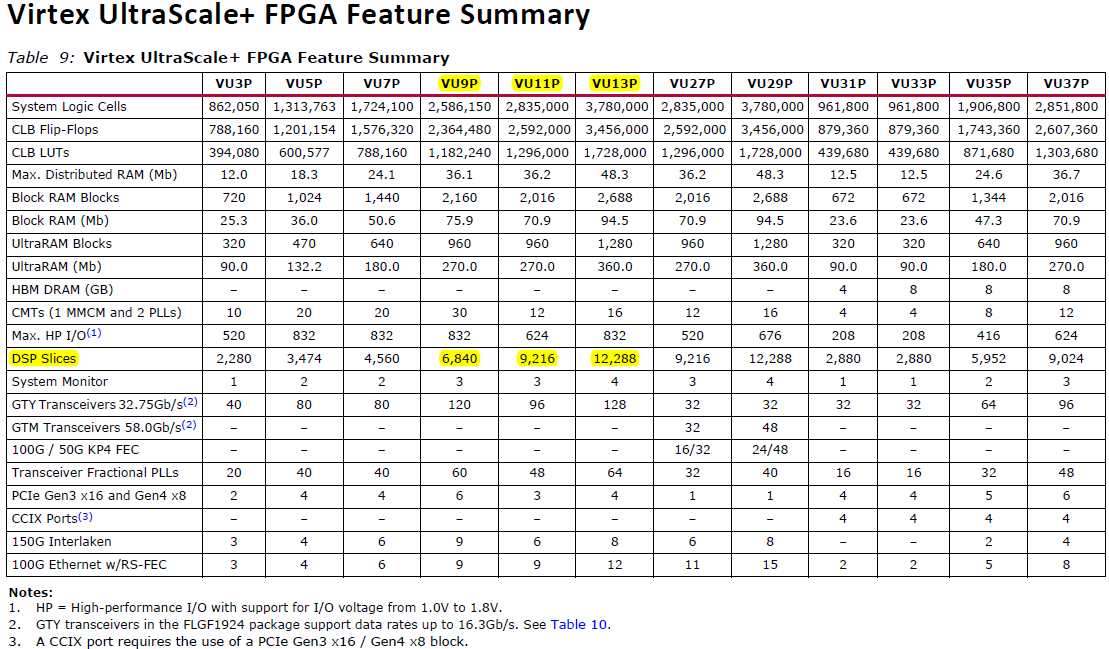
FPGA算力计算:DSP Slices(DSP核数) X2(分为2X INT8)X2(乘加两种)X f(频率)=
如VU9P算力=
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183922.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
