大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Multinoulli分布(多元伯努利分布):
模型: M u ( p ) Mu(p) Mu(p)
d面?获得每一面的概率: p 1 , p 2 , . . . , p d p_1,p_2,…,p_d p1,p2,...,pd
分布函数:
p ( x ∣ p ) = ∏ k = 1 d p k x k p(x|p)=\prod_{k=1}^d p_k^{x_k} p(x∣p)=k=1∏dpkxk
E ( X ) = p E(X)=p E(X)=p
似然函数:
L = l o g ( ∏ n = 1 N ∏ k = 1 d p k x n k ) = l o g ( ∏ k = 1 d p k m k ) L=log(\prod_{n=1}^N \prod_{k=1}^d p_k^{x_{nk}})=log( \prod_{k=1}^d p_k^{m_k}) L=log(n=1∏Nk=1∏dpkxnk)=log(k=1∏dpkmk) m k = ∑ n x n k m_k=\sum_n x_{nk} mk=n∑xnk
极大似然估计:
L = l n ( ∏ n = 1 → N ∏ k = 1 → d p k x n k ) = l n ( ∏ k = 1 → d p k m k ) = ∑ k = 1 → d m k l n p k + λ ( ∑ k = 1 → d p k − 1 ) L = ln(\prod^{n=1\to N}\prod^{k=1\to d}p_k^{x_{nk}}) = ln(\prod^{k=1\to d}p_k^{m_k}) = \sum^{k=1\to d}m_k lnp_k+\lambda(\sum^{k=1\to d}p_k-1) L=ln(∏n=1→N∏k=1→dpkxnk)=ln(∏k=1→dpkmk)=∑k=1→dmklnpk+λ(∑k=1→dpk−1)
p k = m k λ p_k=\frac{m_k}{\lambda} pk=λmk λ = − N \lambda=-N λ=−N
其中 λ ( ∑ k = 1 d p k − 1 ) \lambda(\sum_{k=1}^{d}p_k-1) λ(∑k=1dpk−1) 的由来
是因为 ∑ k = 1 d p k = 1 \sum_{k=1}^d p_k =1 ∑k=1dpk=1 ,
(概率密度函数和为1),在做极大似然估计时候,必须满足这一条件。对于带有约束的优化问题,常用拉格朗日乘子法, λ > 0 \lambda>0 λ>0 表示拉格朗日乘数,表示约束条件的强度。
多项式分布:
模型: M u l t ( n , p ) Mult(n,p) Mult(n,p)
d面?获得每一面的概率: p 1 , p 2 , . . . , p d p_1,p_2,…,p_d p1,p2,...,pd
掷了n次,每面出现的次数: ( x 1 , x 2 , . . . , x d ) (x_1,x_2,…,x_d) (x1,x2,...,xd)
满足条件: x 1 + x 2 + . . . + x d = n x_1+x_2+…+x_d=n x1+x2+...+xd=n
x i ≥ 0 x_i≥0 xi≥0
分布函数:
C n x 1 C n − x 1 x 2 . . . C n − x 1 − x 2 + . . . x d − 1 x d p 1 x 1 . . . p d x d C_n^{x_1}C_{n-x_1}^{x_2}…C_{n-x_1-x_2+…x_{d-1}}^{x_d}p_1^{x_1}…p_d^{x_d} Cnx1Cn−x1x2...Cn−x1−x2+...xd−1xdp1x1...pdxd
f ( x ) = n ! x ( 1 ) ! . . . x ( d ) ! ( p 1 ) x ( 1 ) . . . ( p d ) x ( d ) f(x)=\frac{n!}{x^{(1)}!…x^{(d)}!}(p_1)^{x^{(1)}}…(p_d)^{x^{(d)}} f(x)=x(1)!...x(d)!n!(p1)x(1)...(pd)x(d)
多项式展开定理:
( p 1 + . . . + p d ) n = ∑ x ∈ Δ d , n n ! x ( 1 ) ! . . . x ( d ) ! ( p 1 ) x ( 1 ) . . . ( p d ) x ( d ) (p_1+…+p_d)^n=\sum_{x∈ \Delta d,n}\frac{n!}{x^{(1)}!…x^{(d)}!}(p_1)^{x^{(1)}}…(p_d)^{x^{(d)}} (p1+...+pd)n=x∈Δd,n∑x(1)!...x(d)!n!(p1)x(1)...(pd)x(d)
矩生成函数:
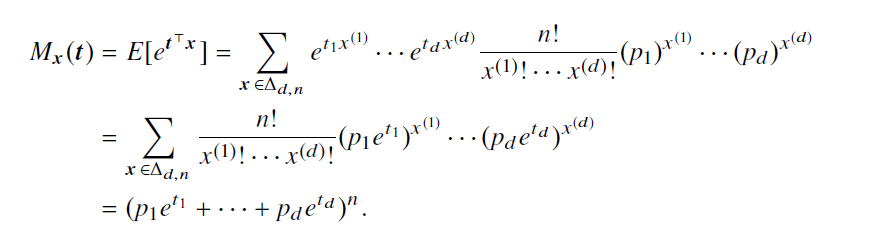

E ( x j ) = n p j E(x^j)=np_j E(xj)=npj
C o v [ x ( j ) , x ( j ′ ) ] = { n p j ( 1 − p j ) ( j = j ′ ) − n p j p j ′ ( j ≠ j ′ ) Cov[x^{(j)},x^{(j’)}]= \begin{cases} np_j(1-p_j) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (j=j’) \\ -np_jp_{j’} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (j≠j’) \end{cases} Cov[x(j),x(j′)]={
npj(1−pj) (j=j′)−npjpj′ (j=j′)
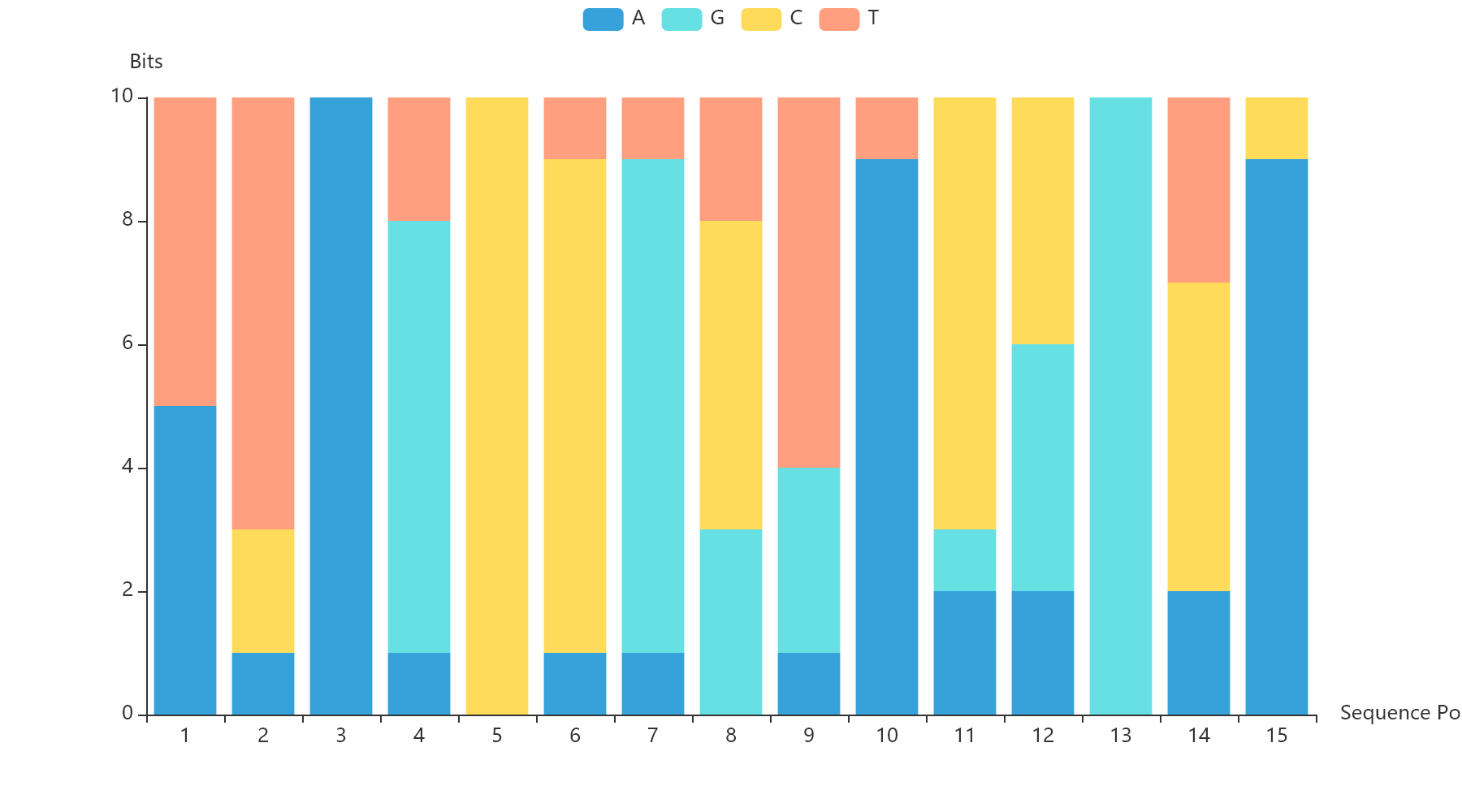
一个服从多项式分布的例子:
将 这 个 基 因 碱 基 序 列 可 视 化 将这个基因碱基序列可视化 将这个基因碱基序列可视化
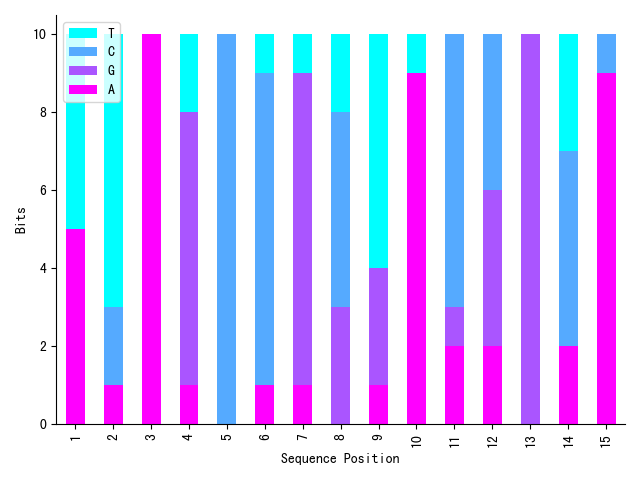
Matplotlib:
import xlrd as xl
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
import pandas as pd
data = xl.open_workbook("等位基因.xlsx")
table = data.sheets()[0]
if data.sheet_loaded(sheet_name_or_index=0):
cols = table.ncols # 列数
lists = [table.col_values(_) for _ in range(cols)]
list_x = [_ for _ in range(1, len(lists) + 1)]
list_A = []
list_G = []
list_C = []
list_T = []
for item in lists:
dicts = dict(Counter(item))
list_A.append(dicts.get('A', 0))
list_G.append(dicts.get('G', 0))
list_C.append(dicts.get('C', 0))
list_T.append(dicts.get('T', 0))
columns = ('A', 'G', 'C', 'T')
data = []
data.append(list_A)
data.append(list_G)
data.append(list_C)
data.append(list_T)
data = np.array(data)
data = data.T
df = pd.DataFrame(data, columns=columns, index=[_ for _ in range(1, cols + 1)])
df.plot(kind='bar', stacked=True,colormap="cool_r",legend="reverse")
print(df)
ax=plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.xlabel("Sequence Position")
plt.ylabel("Bits")
plt.show()
else:
print("打开文件失败")
Pyecharts:
import xlrd as xl
import numpy as np
from pyecharts.charts import *
from collections import Counter
from pyecharts import options as opts
from pyecharts.render import make_snapshot
from snapshot_selenium import snapshot
from pyecharts.globals import ThemeType
data = xl.open_workbook("等位基因.xlsx")
# table=data.sheet_by_name('Sheet1')
# table=data.sheet_by_index(0)
table = data.sheets()[0]
if data.sheet_loaded(sheet_name_or_index=0):
rows = table.nrows # 行数
cols = table.ncols # 列数
lists = [table.col_values(_) for _ in range(cols)]
list_x = [_ for _ in range(1, len(lists) + 1)]
list_A = []
list_G = []
list_C = []
list_T = []
for item in lists:
dicts = dict(Counter(item))
list_A.append(dicts.get('A', 0))
list_G.append(dicts.get('G', 0))
list_C.append(dicts.get('C', 0))
list_T.append(dicts.get('T', 0))
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add_xaxis(list_x)
.add_yaxis("A", list_A, stack='stack1')
.add_yaxis("G", list_G, stack='stack1')
.add_yaxis("C", list_C, stack='stack1')
.add_yaxis("T", list_T, stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(pos_left="10%"),
yaxis_opts=opts.AxisOpts(name="Bits"),
xaxis_opts=opts.AxisOpts(name="Sequence Position")))
make_snapshot(snapshot, bar.render(), "111.png")
else:
print("打开文件失败")
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183914.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
