大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
Paper:Spatial Transformer Networks
这是Google旗下 DeepMind 大作,最近学习人脸识别,这篇paper提出的STN网络可以代替align的操作,端到端的训练实现图片的align。
实际使用的过程中不需要landmarks也可以做align了,而且还可以并联多个,这对于多个物体非常适用,而且,输出的feature大小可以变换,这一点也很灵活。
提出背景
CNN可以显示的学习平移不变性,隐式的学习到对旋转,伸缩、尺度等变换的不变性,Google DeepMind 2016年提出的STN网络,可以显式地赋予网络对上述变换的不变性。不依赖于关键点进行矫正和对齐,而且网络可以作为模块加入神经网络的各个层中。
先来看STN效果
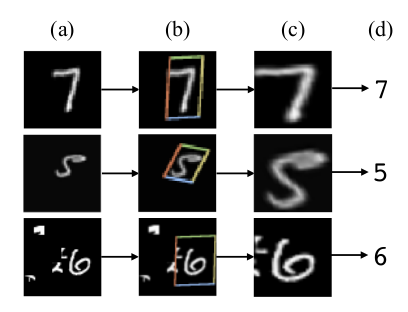

如图,是手写数字识别,图中只有一小块是数字,其他大部分地区都是黑色的,或者是小噪音。假如要识别,用STN层来对图片数据进行旋转缩放,只取其中的一部分,放到之后然后经过CNN就能识别了。说白了就是把图片中物体所在区域送到网络后面的层中,使得后面的分类任务更简单。
本质上来说,CNN是尽力让网络适应物体的形变,而STN是直接通过 Spatial Transformer 将形变的物体给变回到正常的姿态,然后再给网络识别。
STN整体结构
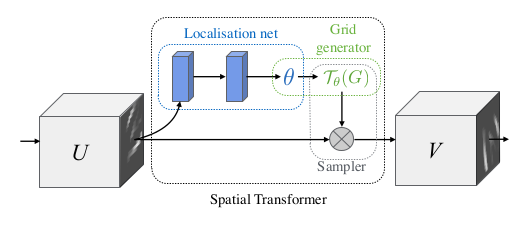
STN的结构如上图所示,由三个模块组成:
(1)Localisation net
Localisation Network的输入是特征图U,输出是变换参数θ,该网络通过回归来学习变换变换参数θ。
θ参数的规模取决于将图像的空间变换视为何种变换,当把图像的空间变换视为纺射变换,θ由6个参数决
定。
(2)Grid generator
Grid generator用于得到输出特征图的坐标点对应的输入特征图的坐标点的位置。
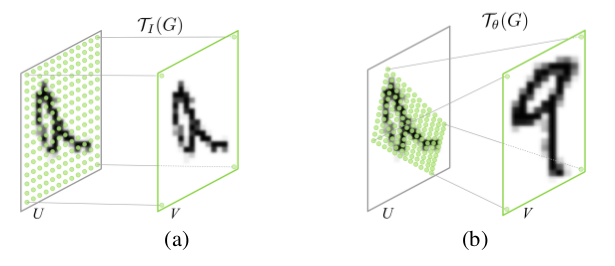
上图中,(a)恒等变换与采样; (b)仿射变换与采样。仿射变换如下所示
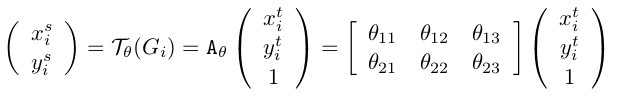
(3)Sampler
通过仿射变换等变化的坐标有可能是浮点数,如果直接取整,则导致无法进行反向传播。因此作者使用
如下公式建立变换前后的坐标映射关系:
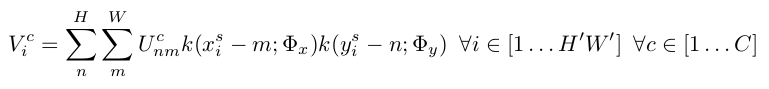
具体实现方式有多种,比如最近邻取整,双线性插值等等。
实验结果
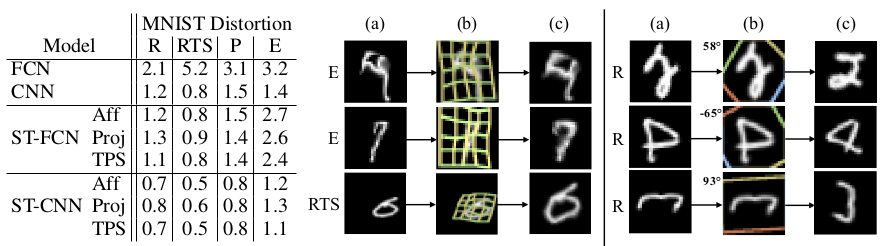
数据集:对mnist图片上的数字做了各种形变操作,比如平移,扭曲,放缩,旋转等。其中,R: rotated, RTS: rotated, translated, and scaled, P: projective distortion, E: elastic distortion。
Spatial Transformer 模块嵌入到 两种主流的分类网络,FCN和CNN中图片输入层与后续分类层之间。
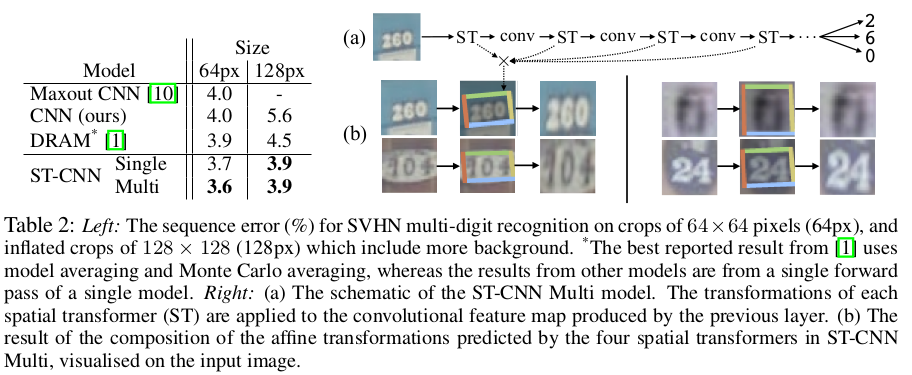

总结思考
Spatial Transformer Networks的出发点是传统CNN中的空间不变性是通过pooling实现的,然而pooling的小尺寸导致不变性只能在网络的深层达到,而且并不能真正处理输入数据的大变换。于是作者提出,对图像或者中间层的feature map作变换。
一个非常大的好处是,STN中三个模块全部可微,因此可以实现端到端的训练。
而且可以处理image,也可以处理feature,应用的位置也非常多,所以说设计的非常灵活了!
STN正常而言是不需要先验的,那么如果有先验的landmarks会不会效果更好呢?
参考文献
[1] https://arxiv.org/abs/1506.02025
[2] https://zhuanlan.zhihu.com/p/37110107
[3] https://arleyzhang.github.io/articles/7c7952f0/
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183894.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
