大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE使用 1年只要46元 售后保障 童叟无欺
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。
1. TP、TN、FP、FN解释说明
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
- 行表示预测的label值,列表示真实label值
- TP:True Positive, 被判定为正样本,事实上也是正样本。
- FP:False Positive,被判定为正样本,但事实上是负样本。
- TN:True Negative, 被判定为负样本,事实上也是负样本。
- FN:False Negative,被判定为负样本,但事实上是正样本。
2. precision 和 recall 的计算
- Accuracy:表示预测结果的精确度,预测正确的样本数除以总样本数。
- precision: 准确率,又称为查准率,表示预测结果中,预测为正样本的样本中,正确预测为正样本的概率;
- recall: 召回率,又称为查全率,表示在原始样本的正样本中,最后被正确预测为正样本的概率;

3. 分类模型的评估方法-F分数(F-Score)
精确率(Precision)和召回率(Recall)评估指标,理想情况下做到两个指标都高当然最好,但一般情况下,Precision高,Recall就低,Recall高,Precision就低。
4. P-R曲线、平均精度(Average-Precision,AP)
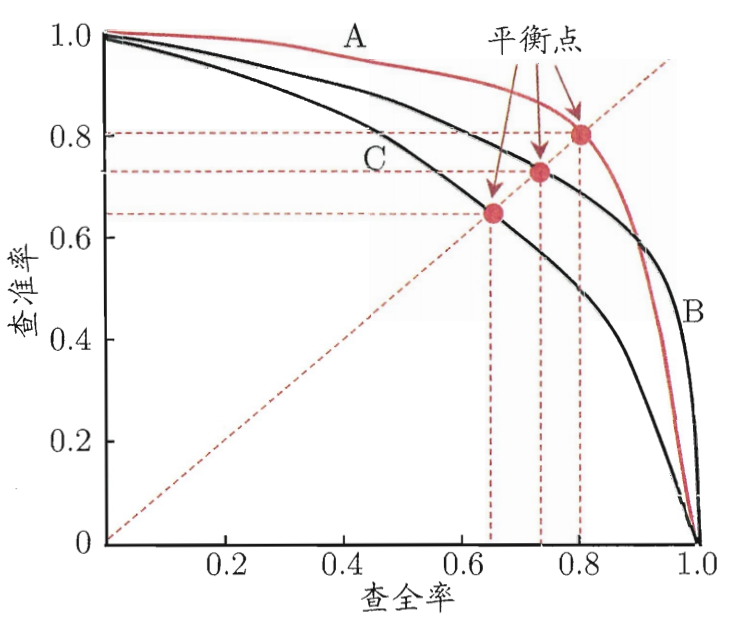
P-R图直观地显示出学习器在样本总体上的查全率、查准率.总体趋势,精度越高,召回越低,进行比较
- 若一个学习器的P-R曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者,如图中学习器A的性能优于学习器C;
- 如果两个学习器的P-R曲线发生了交叉,如图中的A与B,则难以一般性地断言两者孰优孰劣? 只能在具体的查准率或查全率条件下进行比较.
“平衡点”(Break Event Point,简称BEP )就是这样一个度量,它是“查准率=查全率”时的取值, 如图中学习器C的BEP 是0.64, 而基于BEP的比较,可认为学习器A 优于B.
但BEP 还是过于简化了些,更常用的是Fl 度量
5. 分类模型的评估方法-F分数(F-Score)
精确率(Precision)和召回率(Recall)评估指标,理想情况下做到两个指标都高当然最好,但一般情况下,Precision高,Recall就低,Recall高,Precision就低。
所以在实际中常常需要根据具体情况做出取舍,例如一般的搜索情况,在保证召回率的条件下,尽量提升精确率。而像癌症检测、地震检测、金融欺诈等,则在保证精确率的条件下,尽量提升召回率。引出了一个新的指标F-score,综合考虑Precision和Recall的调和值.
- 当
β=1时,称为F1-score或者F1-Measure,这时,精确率和召回率都很重要,权重相同。 - 当有些情况下,我们认为精确率更重要些,那就调整
β的值小于1, - 如果我们认为召回率更重要些,那就调整
β的值大于1。
F1指标(F1-score):F1-score表示的是precision和recall的调和平均评估指标。
举个例子:癌症检查数据样本有10000个,其中10个数据祥本是有癌症,其它是无癌症。假设分类模型在无癌症数据9990中预测正确了9980个,在10个癌症数据中预测正确了9个,此时真阳=9,真阴=9980,假阳=10,假阴=1。
Accuracy = 99.89%
Precision = 47.3%
Recall = 90%
F1-Scoce = 62%
F2-Score = 76.2%
本文部分内容来自一位前辈,非常感谢分享!谢谢!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183885.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
