大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
1-ElasticSearch 集群
1-ES集群相关概念
es 集群:
•ElasticSearch 天然支持分布式
•ElasticSearch 的设计隐藏了分布式本身的复杂性
ES集群相关概念:
•集群(cluster):一组拥有共同的 cluster name 的 节点。
•节点(node) :集群中的一个 Elasticearch 实例
•索引(index) :es存储数据的地方。相当于关系数据库中的database概念
•分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
•主分片(Primary shard):相对于副本分片的定义。
•副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
2-集群搭建
参见下文集群搭建
3-kibina管理集群
vim kibana-7.4.0-linux-x86_64-cluster/config/kibana.yml
kibana.yml
#支持中文
i18n.locale: "zh-CN"
#5602避免与之前的冲突
server.port: 5602
server.host: "0.0.0.0"
server.name: "kibana-person-cluster"
elasticsearch.hosts: ["http://localhost:9201","http://localhost:9202","http://localhost:9203"]
elasticsearch.requestTimeout: 99999
4-JavaAPI 访问集群
PUT cluster_test
{
"mappings": {
"properties": {
"name":{
"type": "text"
}
}
}
}
GET cluster_test
GET cluster_test/_search
POST /cluster_test/_doc/1
{
"name":"张三"
}
测试类
@Resource(name="clusterClient")
RestHighLevelClient clusterClient;
/** * 测试集群 * @throws IOException */
@Test
public void testCluster() throws IOException {
//设置查询的索引、文档
GetRequest indexRequest=new GetRequest("cluster_test","1");
GetResponse response = clusterClient.get(indexRequest, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
ElasticSearchConfig
private String host1;
private int port1;
private String host2;
private int port2;
private String host3;
private int port3;
//get/set ...
@Bean("clusterClient")
public RestHighLevelClient clusterClient(){
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host1,port1,"http"),
new HttpHost(host2,port2,"http"),
new HttpHost(host3,port3,"http")
));
}
application.yml
elasticsearch:
host: 192.168.140.130
port: 9200
host1: 192.168.140.130
port1: 9201
host2: 192.168.140.130
port2: 9202
host3: 192.168.140.130
port3: 9203
5-分片配置
•在创建索引时,如果不指定分片配置,则默认主分片1,副本分片1。
•在创建索引时,可以通过settings设置分片
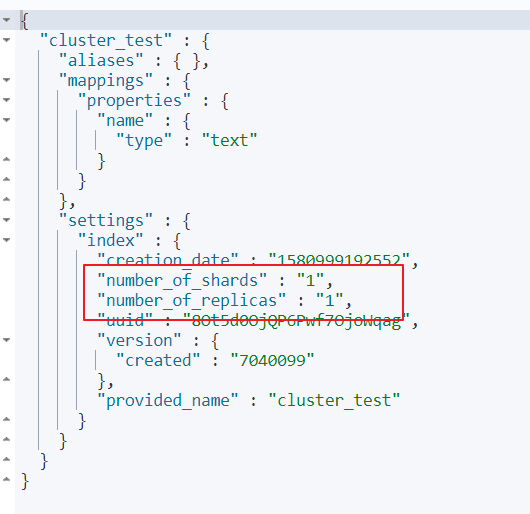

分片配置
#分片配置
#"number_of_shards": 3, 主分片数量
#"number_of_replicas": 1 主分片备份数量,每一个主分片有一个备份
# 3个主分片+3个副分片=6个分片
PUT cluster_test1
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name":{
"type": "text"
}
}
}
}
1.三个节点正常运行(0、1、2分片标号)
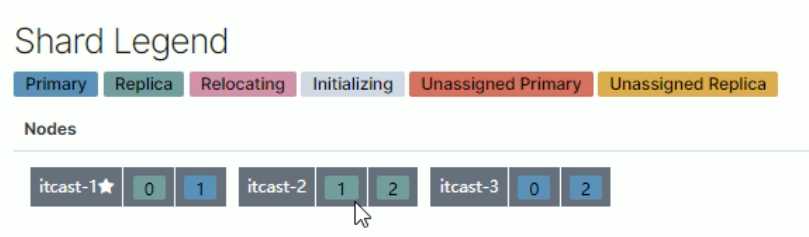
2.person-3 挂掉
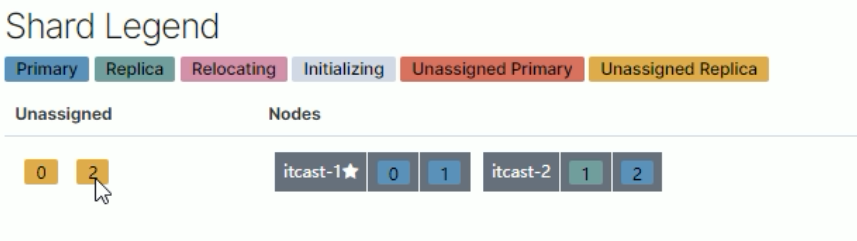
3.将挂掉节点的分片,自平衡到其他节点
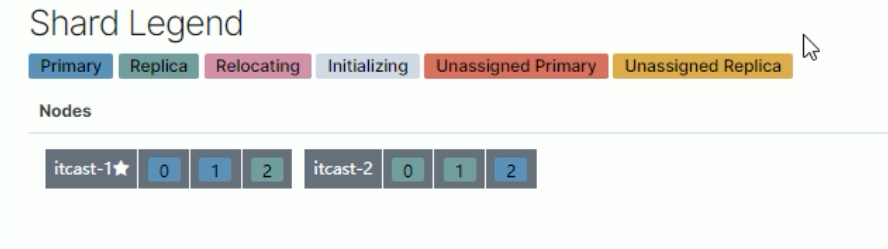
4.person-3 恢复正常后,节点分片将自平衡回去(并不一定是原来的分片)
分片与自平衡
•当节点挂掉后,挂掉的节点分片会自平衡到其他节点中
注意:分片数量一旦确定好,不能修改。
索引分片推荐配置方案:
1.每个分片推荐大小10-30GB
2.分片数量推荐 = 节点数量 * 1~3倍
思考:比如有1000GB数据,应该有多少个分片?多少个节点
1.每个分片20GB 则可以分为40个分片
2.分片数量推荐 = 节点数量 * 1~3倍 –> 40/2=20 即20个节点
6-路由原理
路由原理
•文档存入对应的分片,ES计算分片编号的过程,称为路由。
•Elasticsearch 是怎么知道一个文档应该存放到哪个分片中呢?
•查询时,根据文档id查询文档, Elasticsearch 又该去哪个分片中查询数据呢?
•路由算法 :shard_index = hash(id) % number_of_primary_shards
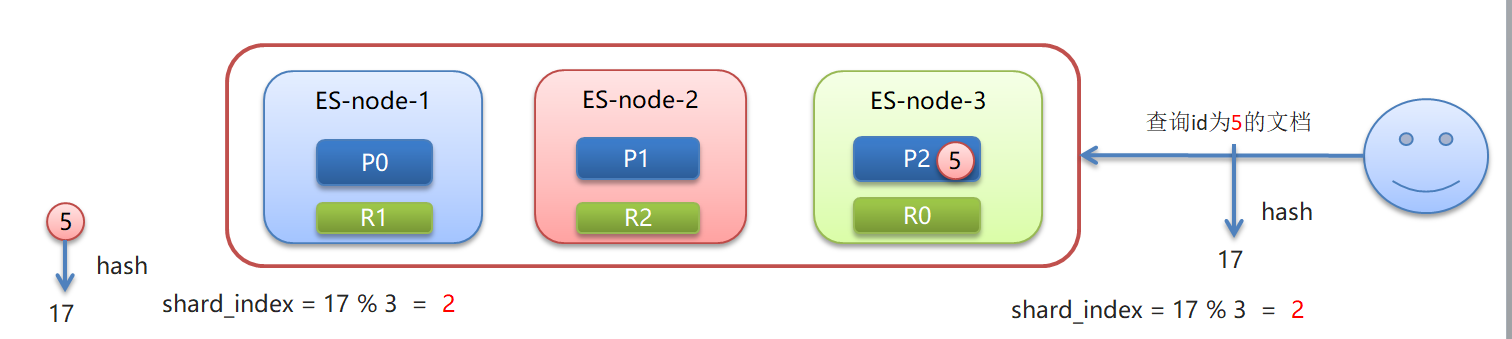
查询id为5的文档:假如hash(5)=17 ,根据算法17%3=2
7-脑裂
ElasticSearch 集群正常状态:
• 一个正常es集群中只有一个主节点(Master),主节点负责管理整个集群。如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
•集群的所有节点都会选择同一个节点作为主节点。
脑裂现象:
•脑裂问题的出现就是因为从节点在选择主节点上出现分歧导致一个集群出现多个主节点从而使集群分裂,使得集群处于异常状态。
脑裂产生的原因:
1.网络原因:网络延迟
•一般es集群会在内网部署,也可能在外网部署,比如阿里云。
•内网一般不会出现此问题,外网的网络出现问题的可能性大些。
2.节点负载
•主节点的角色既为master又为data。数据访问量较大时,可能会导致Master节点停止响应(假死状态)。

-
JVM内存回收
•当Master节点设置的JVM内存较小时,引发JVM的大规模内存回收,造成ES进程失去响应。
避免脑裂:
1.网络原因:discovery.zen.ping.timeout 超时时间配置大一点。默认是3S
2.节点负载:角色分离策略
•候选主节点配置为
•node.master: true
•node.data: false
•数据节点配置为
•node.master: false
•node.data: true
3.JVM内存回收:修改 config/jvm.options 文件的 -Xms 和 -Xmx 为服务器的内存一半。
8-ElasticSearch 集群-集群扩容
按照集群搭建步骤再复制Es节点进行配置,参见 集群搭建
ElasticSearch 集群搭建
2.1 搭建集群
Elasticsearch如果做集群的话Master节点至少三台服务器或者三个Master实例加入相同集群,三个Master节点最多只能故障一台Master节点,如果故障两个Master节点,Elasticsearch将无法组成集群.会报错,Kibana也无法启动,因为Kibana无法获取集群中的节点信息。
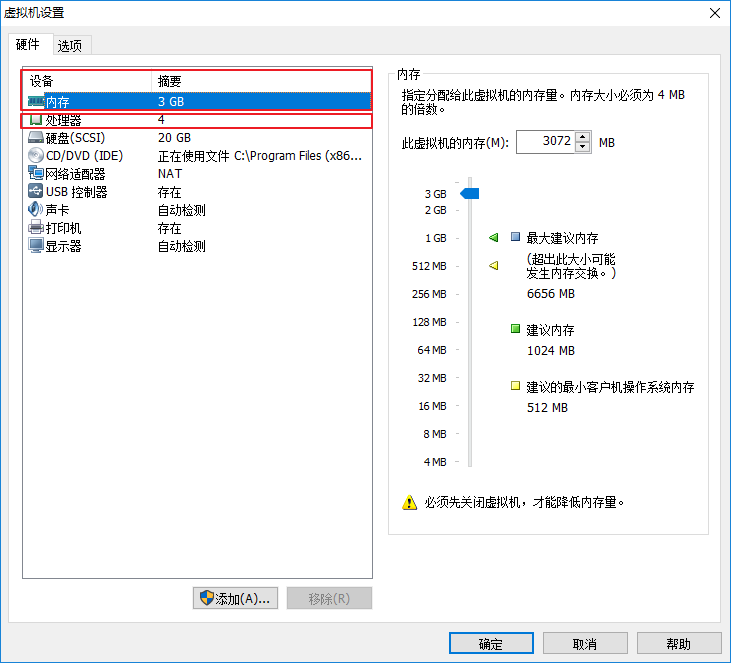
由于,我们使用只有一台虚拟机,所以我们在虚拟机中安装三个ES实例,搭建伪集群,而ES启动比较耗内存,所以先设置虚拟机的内存3G和CPU个数4个
2.1.1 整体步骤
步骤如下:
-
拷贝opt目录下的elasticsearch-7.4.0安装包3个,分别命名:
elasticsearch-7.4.0-itcast1
elasticsearch-7.4.0-itcast2
elasticsearch-7.4.0-itcast3
-
然后修改elasticsearch.yml文件件。
-
然后启动启动itcast1、itcast2、itcast3三个节点。
-
打开浏览器输⼊:http://192.168.149.135:9200/_cat/health?v ,如果返回的node.total是3,代表集 群搭建成功
在此,需要我们特别注意的是,像本文这样单服务器多节点( 3 个节点)的情况,仅供测试使用,集群环境如下:
| cluster name | node name | IP Addr | http端口 / 通信端口 |
| itcast-es | itcast1 | 192.168.149.135 | 9201 / 9700 |
| itcast-es | itcast2 | 192.168.149.135 | 9202 / 9800 |
| itcast-es | itcast3 | 192.168.149.135 | 9203 / 9900 |
2.1.2 拷贝副本
拷贝opt目录下的elasticsearch-7.4.0安装包3个,打开虚拟机到opt目录
执行 拷贝三份
cd /opt
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast1
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast2
cp -r elasticsearch-7.4.0 elasticsearch-7.4.0-itcast3
2.1. 3 修改elasticsearch.yml配置文件
1)、创建日志目录
cd /opt
mkdir logs
mkdir data
# 授权给itheima用户
chown -R itheima:itheima ./logs
chown -R itheima:itheima ./data
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast1
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast2
chown -R itheima:itheima ./elasticsearch-7.4.0-itcast3
打开elasticsearch.yml配置,分别配置下面三个节点的配置文件
vim /opt/elasticsearch-7.4.0-itcast1/config/elasticsearch.yml
vim /opt/elasticsearch-7.4.0-itcast2/config/elasticsearch.yml
vim /opt/elasticsearch-7.4.0-itcast3/config/elasticsearch.yml
2)、下面是elasticsearch-7.4.0-itcast1配置文件
cluster.name: itcast-es
node.name: itcast-1
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9700
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
cluster.initial_master_nodes: ["itcast-1", "itcast-2","itcast-3"]
path.data: /opt/data
path.logs: /opt/logs
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9201
#内部节点之间沟通端口
transport.tcp.port: 9700
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["itcast-1", "itcast-2","itcast-3"]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
3)、下面是elasticsearch-7.4.0-itcast2配置文件
cluster.name: itcast-es
node.name: itcast-2
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9202
transport.tcp.port: 9800
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
cluster.initial_master_nodes: ["itcast-1", "itcast-2","itcast-3"]
path.data: /opt/data
path.logs: /opt/logs
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-2
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9202
#内部节点之间沟通端口
transport.tcp.port: 9800
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["itcast-1", "itcast-2","itcast-3"]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
4)、下面是elasticsearch-7.4.0-itcast3 配置文件
cluster.name: itcast-es
node.name: itcast-3
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9203
transport.tcp.port: 9900
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
cluster.initial_master_nodes: ["itcast-1", "itcast-2","itcast-3"]
path.data: /opt/data
path.logs: /opt/logs
#集群名称
cluster.name: itcast-es
#节点名称
node.name: itcast-3
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
#端口
http.port: 9203
#内部节点之间沟通端口
transport.tcp.port: 9900
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["itcast-1", "itcast-2","itcast-3"]
#数据和存储路径
path.data: /opt/data
path.logs: /opt/logs
2.1.4 执行授权
在root用户下执行
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast1
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast2
chown -R itheima:itheima /opt/elasticsearch-7.4.0-itcast3
如果有的日志文件授权失败,可使用(也是在root下执行)
cd /opt/elasticsearch-7.4.0-itcast1/logs
chown -R itheima:itheima ./*
cd /opt/elasticsearch-7.4.0-itcast2/logs
chown -R itheima:itheima ./*
cd /opt/elasticsearch-7.4.0-itcast3/logs
chown -R itheima:itheima ./*
2.1.5 启动三个节点
启动之前,设置ES的JVM占用内存参数,防止内存不足错误

vim /opt/elasticsearch-7.4.0-itcast1/bin/elasticsearch

可以发现,ES启动时加载/config/jvm.options文件
vim /opt/elasticsearch-7.4.0-itcast1/config/jvm.options

默认情况下,ES启动JVM最小内存1G,最大内存1G
-xms:最小内存
-xmx:最大内存
修改为256m

启动成功访问节点一:

可以从日志中看到:master not discovered yet。还没有发现主节点
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 不成功

启动成功访问节点二:
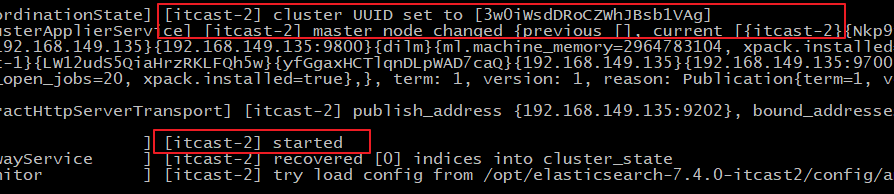
可以从日志中看到:master not discovered yet。还没有发现主节点master node changed.已经选举出主节点itcast-2
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 成功

健康状况结果解释:
cluster 集群名称
status 集群状态
green代表健康;
yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;
red 代表部分主分片不可用,可能已经丢失数据。
node.total代表在线的节点总数量
node.data代表在线的数据节点的数量
shards 存活的分片数量
pri 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
relo迁移中的分片数量,正常情况为 0
init 初始化中的分片数量 正常情况为 0
unassign未分配的分片 正常情况为 0
pending_tasks准备中的任务,任务指迁移分片等 正常情况为 0
max_task_wait_time任务最长等待时间
active_shards_percent正常分片百分比 正常情况为 100%
启动成功访问节点三
访问集群状态信息 http://192.168.149.135:9201/_cat/health?v 成功

可以看到节点已经变为3个,至此,ES集群已经搭建成功~
2.2 使用Kibana配置和管理集群
2.2.1 集群配置
因为之前我们在单机演示的时候也使用到了Kibana,我们先复制出来一个Kibana,然后修改它的集群配置
cd /opt/
cp -r kibana-7.4.0-linux-x86_64 kibana-7.4.0-linux-x86_64-cluster
# 由于 kibana 中文件众多,此处会等待大约1分钟的时间
修改Kibana的集群配置
vim kibana-7.4.0-linux-x86_64-cluster/config/kibana.yml
加入下面的配置
elasticsearch.hosts: ["http://localhost:9201","http://localhost:9202","http://localhost:9203"]
启动Kibana
sh kibana --allow-root

2.2.2 管理集群
1、打开Kibana,点开 Stack Monitoring 集群监控
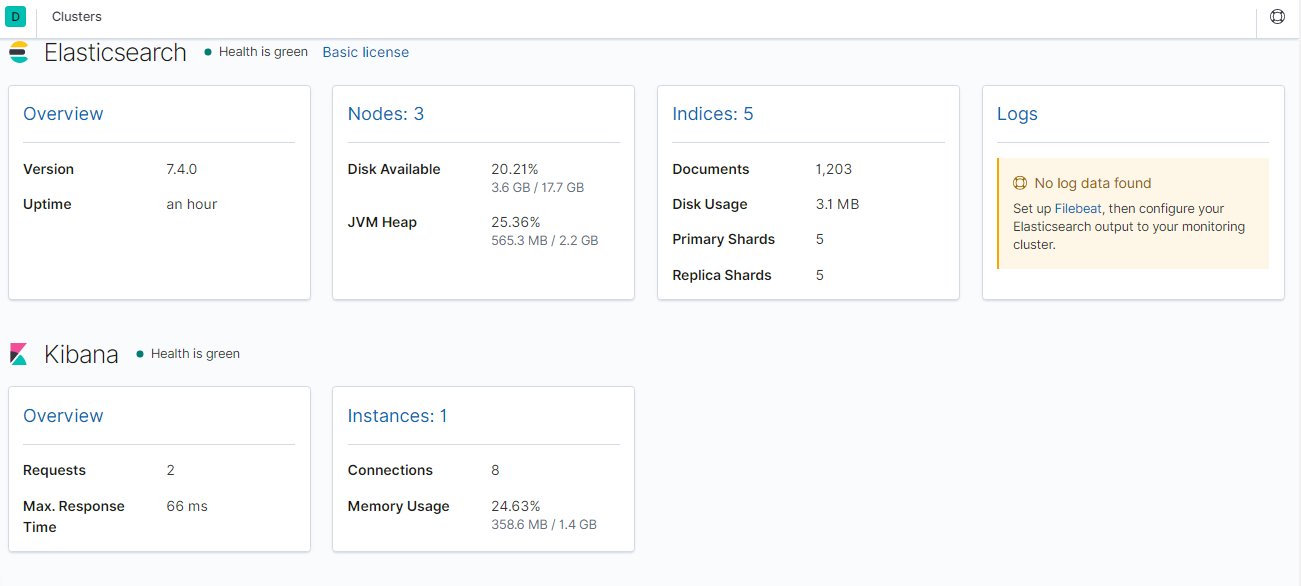
2、点击【Nodes】查看节点详细信息
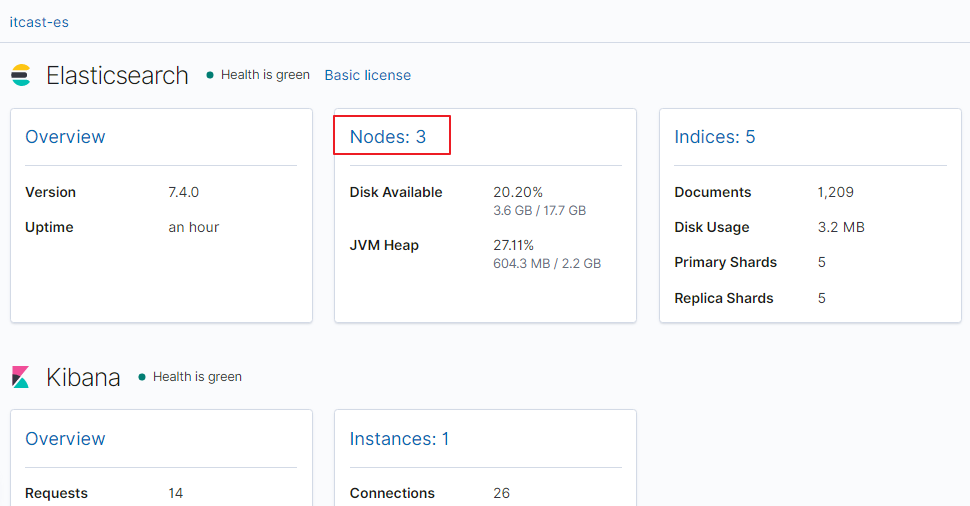
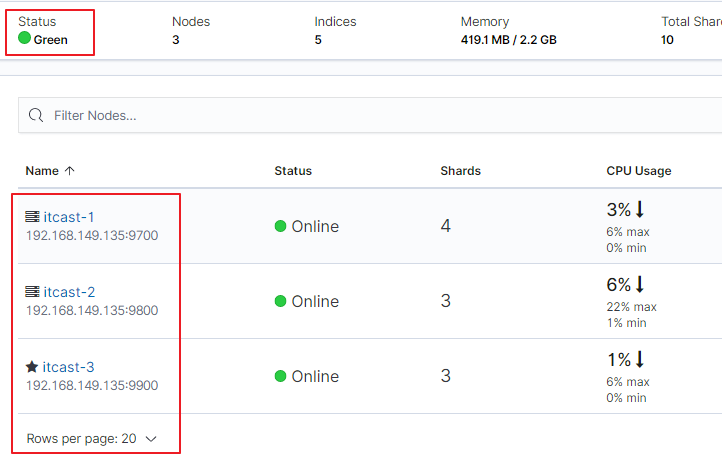
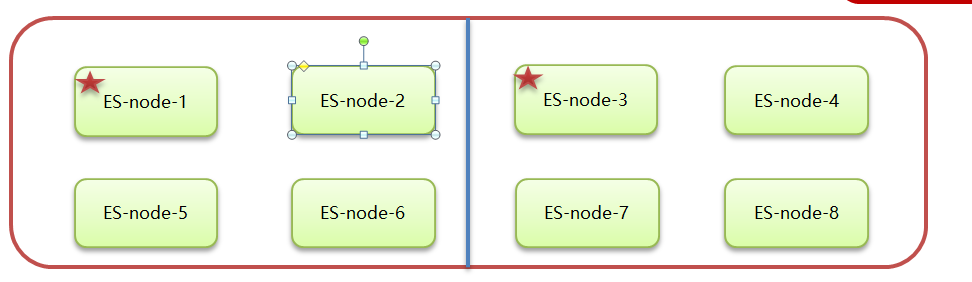
在上图可以看到,第一个红框处显示【Green】,绿色,表示集群处理健康状态
第二个红框是我们集群的三个节点,注意,itcast-3旁边是星星,表示是主节点
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183416.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
