大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
一、基尼系数是什么?
1)定义
下面是摘自李航《统计学习方法》中基尼系数的定义,非常清晰。


2)基尼系数有什么意义?
我们可以先来看一组数据
| X的取值 | 方案一 | 方案二 | 方案三 | 方案四 | P的平方 | 方案一 | 方案二 | 方案三 | 方案四 |
| 类别一 | 0.9 | 0.5 | 0.4 | 0.2 | p1^2 | 0.81 | 0.25 | 0.16 | 0.04 |
| 类别二 | 0.1 | 0.5 | 0.3 | 0.2 | p2^2 | 0.01 | 0.25 | 0.09 | 0.04 |
| 类别三 | 0 | 0 | 0.3 | 0.2 | p3^2 | 0 | 0 | 0.09 | 0.04 |
| 类别四 | 0 | 0 | 0 | 0.2 | p4^2 | 0 | 0 | 0 | 0.04 |
| 类别五 | 0 | 0 | 0 | 0.2 | p5^2 | 0 | 0 | 0 | 0.04 |
| 基尼系数 | 0.18 | 0.5 | 0.66 | 0.8 | 总和 | 0.82 | 0.5 | 0.34 | 0.2 |
| 总和 | 1 | 1 | 1 | 1 | 基尼系数 | 0.18 | 0.5 | 0.66 | 0.8 |
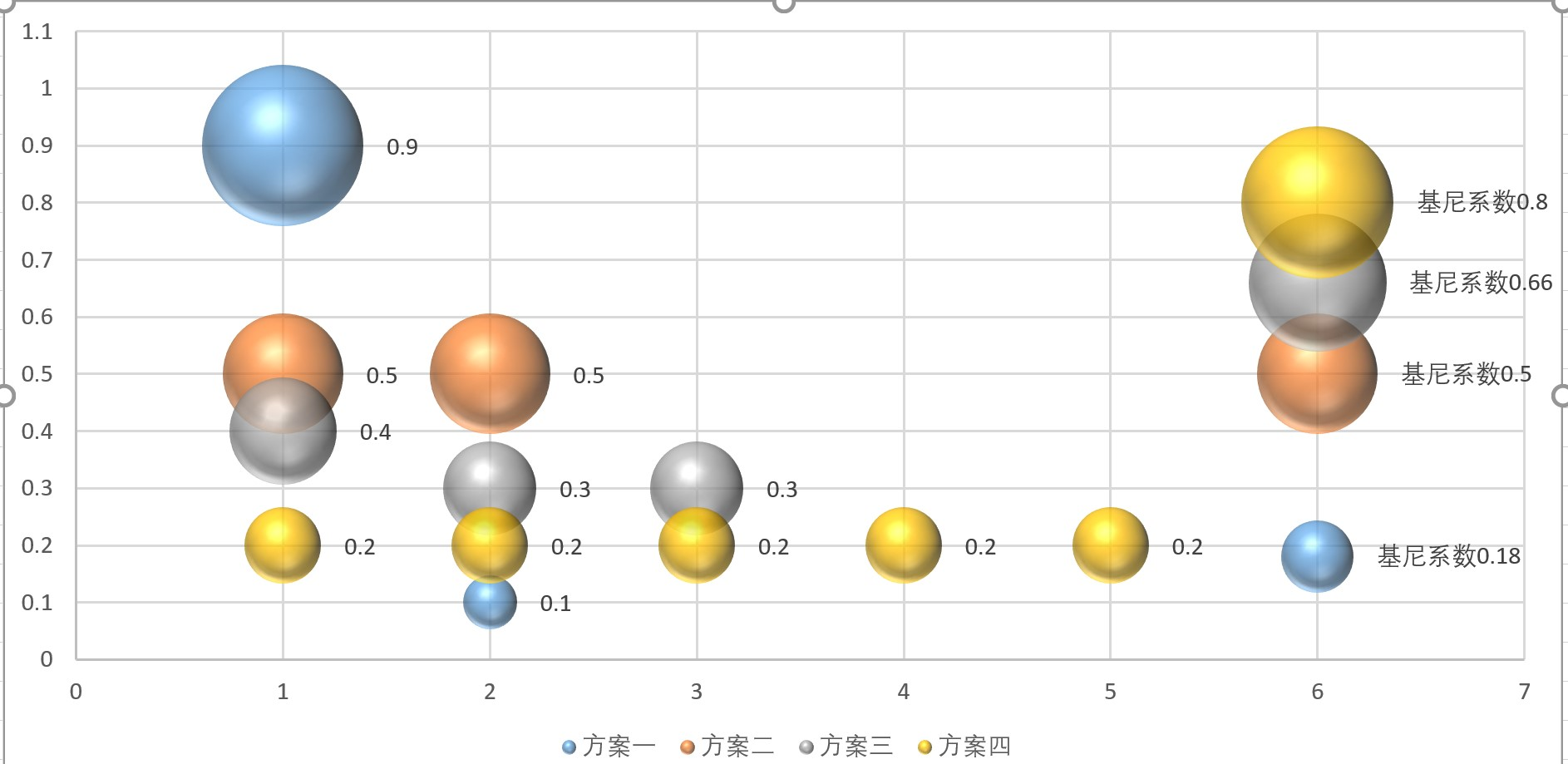
由上图我们可以观察到,类别的个数是 方案一(2个) < 方案三(3个) < 方案四(4个) ,基尼系数为 方案一 < 方案三 < 方案四;而方案一和方案二类别个数相同,但方案一的类别集中度比方案二要高,而基尼系数为 方案一 < 方案二
基尼系数的特质是:
1) 类别个数越少,基尼系数越低;
2)类别个数相同时,类别集中度越高,基尼系数越低。
当类别越少,类别集中度越高的时候,基尼系数越低;当类别越多,类别集中度越低的时候,基尼系数越高。
【类别集中度是指类别的概率差距,0.9+0.1的概率组合,比起0.5+0.5的概率组合集中度更高】
二、熵
1)熵是什么?
下面是摘自李航《统计学习方法》中熵的定义。

2)怎样理解熵的意义?
我们可以先来看一组数据
| X的取值 | 方案一 | 方案二 | 方案三 | 方案四 | P的平方 | 方案一 | 方案二 | 方案三 | 方案四 |
| 类别一 | 0.9 | 0.5 | 0.4 | 0.2 | p1*(-lnp1) | 0.09 | 0.35 | 0.37 | 0.32 |
| 类别二 | 0.1 | 0.5 | 0.3 | 0.2 | p2*(-lnp2) | 0.23 | 0.35 | 0.36 | 0.32 |
| 类别三 | 0 | 0 | 0.3 | 0.2 | p3*(-lnp3) | 0.00 | 0.00 | 0.36 | 0.32 |
| 类别四 | 0 | 0 | 0 | 0.2 | p4*(-lnp4) | 0.00 | 0.00 | 0.00 | 0.32 |
| 类别五 | 0 | 0 | 0 | 0.2 | p5*(-lnp5) | 0.00 | 0.00 | 0.00 | 0.32 |
| 熵 | 0.82 | 0.50 | 0.34 | 0.20 | 熵 | 0.82 | 0.50 | 0.34 | 0.20 |
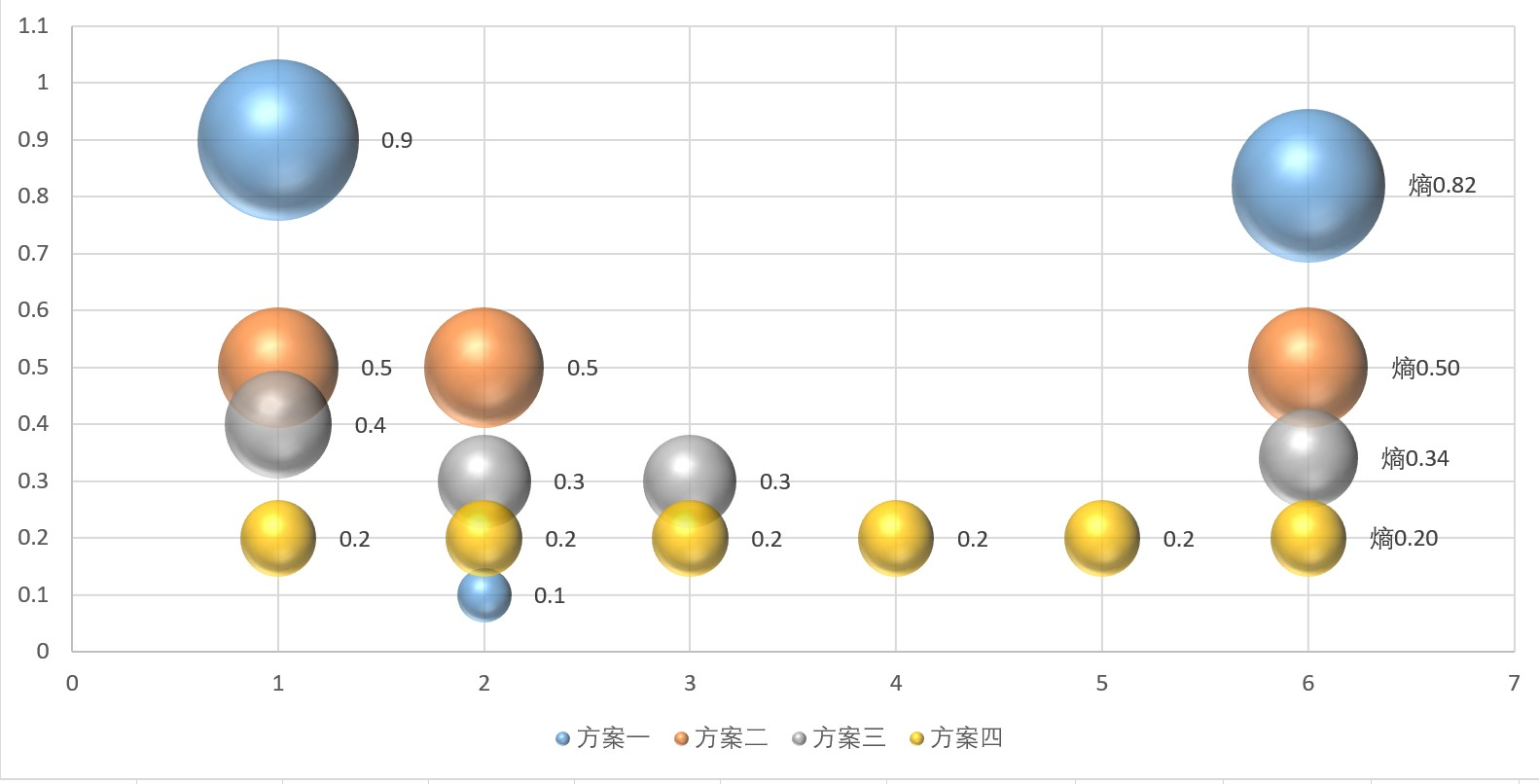
可以看到,这幅图跟基尼系数的图是差不多的。也就是熵和基尼系数都有着类似的特质,它们都可以用来衡量信息的不确定性。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183334.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
