大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
粒子群算法matlab实现:点击这里
粒子群优化算法简介
粒子群优化算法(PSO)最初是由Kennedy和Eberhart博士于1995年受人工生命研究的结果启发,在模拟鸟群觅食过程中的迁徙和群集行为时提出的一种基于群体智能的演化计算技术。
PSO是一种随机全局优化技术,通过粒子间的相互作用发现复杂搜索空间中的最优区域。由于PSO算法独特的优势,在工程领域中收到研究者的广泛关注。
PSO算法归根到底是一种利用随机法求多维函数特定区域的最值的算法。
PSO的优点
(1)相对于其他寻优算法,需要调整的参数较少。
(2)算法实现较为简单,效率较高。
(3)鲁棒性较好。
(4)相对于其他寻优算法,PSO容易收敛。
PSO的缺点
(1)易陷入局部最优解中
(2)难以得到精确的最优解
(3)PSO的机理性研究较少,缺乏严密的数学指导。
因此PSO算法适用于处理高维的,具有多个局部最优解的,对结果精确性要求不高的优化问题。
PSO的原理及基本概念
PSO的原理是模仿鸟群觅食的原理:
单个鸟→单个粒子
鸟群→有许多粒子组成的粒子群
鸟群的觅食行为→粒子群通过一定规律的随机运动,搜寻区域内的最优解
算法描述
在D维区域里存在m个粒子
其中第i个粒子的位置为一个矢量:xi={xi1 , xi2 , xi3…xiD}
其中第i个粒子的速度为一个矢量:vi={vi1 , vi2 , vi3 …viD}
第i个粒子搜索到的最优位置为:pi={pi1 , pi2 , pi3 …piD}
整个粒子群搜索到的最优位置为:pgbest={pgbest1 , pgbest2 , pgbest3 …{pgbestD}
第i个粒子在k次迭代时的速度为:
v i d k + 1 = ω v i d k + c 1 r 1 ( p i d − x i d k ) + c 2 r 2 ( p g b e s t d − x i d k ) v^{k+1}_{id}=ωv^{k}_{id}+c_1r_1(p_{id}-x^k_{id})+c_2r_2(p_{gbestd}-x^k_{id}) vidk+1=ωvidk+c1r1(pid−xidk)+c2r2(pgbestd−xidk)
其中i = 1,2,3…m ; d = 1,2,3…D
ω成为惯性参数;c1,c2称为学习因子,是一个正常数;r1,r2为随机数;等号右边的三项分别是:历史速度的记忆、认知部分、社会部分。
位置更新公式:
x i d k + 1 = x i d k + v i d k + 1 x^{k+1}_{id}=x^{k}_{id}+v^{k+1}_{id} xidk+1=xidk+vidk+1
每次更新的速度控制在一个最大速度vmax以下。
算法流程:
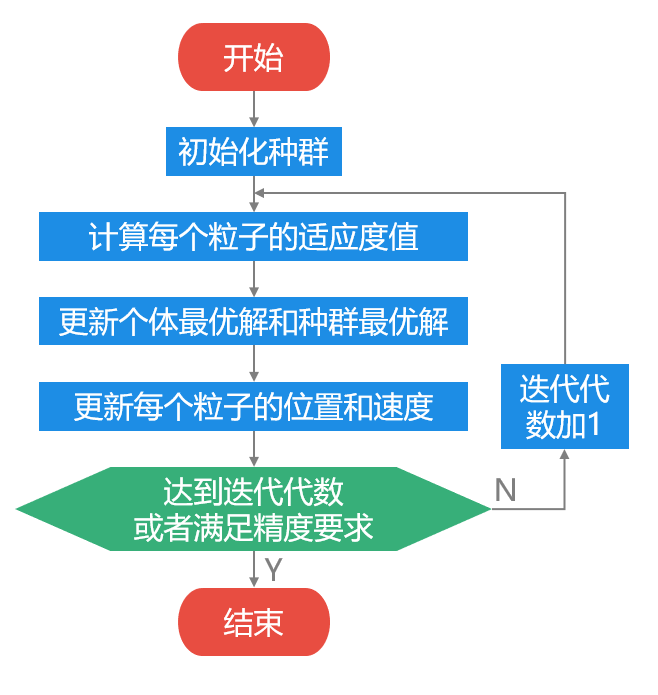
 算法终止条件有两种:
算法终止条件有两种:
(1)达到最大迭代步数
(2)得到可接受的满意解
参数分析
(1)惯性参数ω:
ω代表对原先速度的记忆程度,依据原先的速度进行惯性运动。
较大的ω使粒子更易跳出局部最优解,获得更强的全局寻优能力,但也会使效率降低,不宜收敛;较小的ω容易陷入局部最优解,但更易收敛。
当问题空间较大时,ω不应为一个常数。在前期可以使ω较大以获得更强的全局寻优能力,后期ω变小可以提高收敛速度。这个功能可以由线性递减权值公式实现:
ω = ω m a x − ( ω m a x − ω m i n ) ∗ r u n r u n m a x ω=ω_{max}-(ω_{max}-ω_{min})*\frac{run}{run_{max}} ω=ωmax−(ωmax−ωmin)∗runmaxrun
(2)学习因子c1,c2:
c1,c2分别代表粒子动作来自认知部分和社会部分的权重。
c1=0时,为无私型粒子群算法,丧失群体多样性,容易陷入局部最优解。
c2=0时,为自私型粒子群算法,没有信息的社会共享,收敛速度减慢。
c1>c2>0时,适用于多峰优化问题。
c2>c1>0时,适用于多峰优化问题。
自适应或动态加速度系数是基于迭代次数对两个系数进行动态调节。其中c1随代数增加而减小,c2随代数增加而增大。
c 1 = ( c 1 f − c 1 i ) t T M A X + c 1 i c_1=(c_{1f}-c_{1i})\frac{t}{T_{MAX}}+c_{1i} c1=(c1f−c1i)TMAXt+c1i
c 2 = ( c 2 f − c 2 i ) t T M A X + c 2 i c_2=(c_{2f}-c_{2i})\frac{t}{T_{MAX}}+c_{2i} c2=(c2f−c2i)TMAXt+c2i
实验建议:c1f=0.5,c1i=2.5;c2f=2.5,c2i=0.5
(3)粒子的最大速度vmax
粒子最大速度:维护算法探索能力和开发能力的平衡。速度增大,粒子的探索能力增强,但容易飞过最优解。速度减小,开发能力较大,但容易陷入局部最优。
粒子群的拓扑结构
一种是将群体中所有粒子都作为粒子的邻域,这样的结构叫做全局粒子群算法。这种结构下,粒子的认知部分是自己的历史最优解;社会部分是粒子全体的全局最优值。
另一种是将群体中的部分个体作为粒子的邻域,这样的结构叫做局部粒子群算法。这种结构下,粒子的认知部分是自己的历史最优解;社会部分是粒子邻域内的全局最优值。
全局粒子群算法的收敛能力更强,但容易陷入局部最优解;局部粒子群算法全局寻优能力更强,但收敛速度较慢。
初始化时的前人经验
粒子数一般取20-40,对较难或特定类别的问题可以取100-200。
最大速度通常设定为粒子的范围宽度。
将c1和c2统一为一个控制参数φ=c1+c2。当φ=4.1时具有良好的收敛效果。
ω=0.7298和c1=c2=1.497时算法有较好的收敛性能。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183223.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
