大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
目录
2、TaskScheduler与SchedulerBackend
1、DAGScheduler与TaskScheduler
DAGScheduler面向我们整个Job划分出了Stage,划分了Stage是从后往前划分的,执行的时候是从前往后,每个Stage内部有一系列任务,Stage里面的任务是并行计算的,这些并行计算的任务的逻辑是完全相同的,只不过是处理的数据不同而已。DAGScheduler会以TaskSet的方式以一个DAG构造的Stage中所有的任务提交给底层调度器TaskScheduler,TaskScheduler是一个接口(做接口的好处就是跟具体的任务调度解耦合,这样Spark就可以运行在不同的资源调度模式上Standalone,yarn,mesos等)这符合面向对象中依赖抽象而不依赖具体的原则,带来了底层资源调度器的可插拔性,导致Spark可以运行在众多的资源调度器模式上。
DAGScheduler是高层调度器,TaskScheduler是底层调度器。高层调度器本身是属于Spark自己内核的实现,通过划分不同的Stage,这个是优化的核心。底层调度器做了一个接口,面向接口了解这个接口可以自己定义底层的具体调度器。
2、TaskScheduler与SchedulerBackend
DAGScheduler完成了面向Stage的划分之后,会按照顺序逐个将我们的Stage通过TaskSchedulerImpl的submitTaskScheduler提交给底层调度器,调度过程如下:
(1)DAG构建完毕,提交stage给taskScheduler,taskScheduler执行submitTasks开始调起具体的Task,他主要的作用是将TaskSet加到我们的TaskSetManager中,这里new了一个TaskSet。


(2)因为TaskScheduler是个接口,进入到他的具体实现,也就是TaskSchedulerImpl。在这里任务集合中的任务可能是ShuffleMapTask也可能是ResultTask。我们把任务集合赋值给变量tasks,然后在同步代码块中创建了一个createTaskSetManager,在其内部路由了TaskSetManager。构建TaskSetManager的参数包括this(TaskSchedulerImpl本身),taskSet,还有最大失败重试次数(是构建TaskSchedulerImpl的时候传进来的,如果没设置的话默认最大为4)
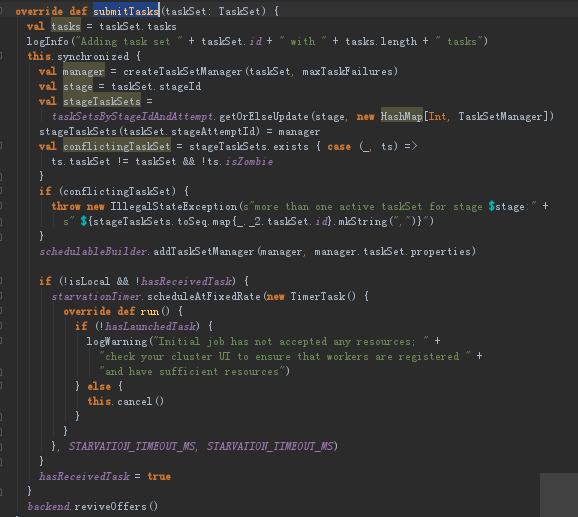

(3)在创建了TaskSetManager后比较关键的一点就是调用了SchedulableBuilder.addTaskSetmanager,SchedulableBuilder会确定TaskSetManager的调度顺序,然后按照TaskSetManager的locality aware来确定每个task具体运行在哪个ExecutorBackend中

schedulableBuilder他是SchedulableBuilder类型的,是整个应用程序级别调度器,我们是在TaskSchedulerImpl创建的时候就对他实例化。他本身是我们应用程序级别的调度器,他自己支持2种调度模式有FIFO(先进先出)和FAIR(公平调度)。我们的调度策略可以通过spark-env.sh中的spark.scheduler.mode进行具体的配置,默认是FIFO。

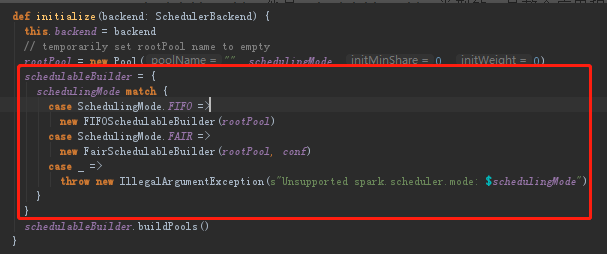
(4)在SchedulableBuilder.addTaskSetmanager之后有一个关键的步骤backend.reviveOffers()他的作用就是给DriverEndPoint发ReviveOffers消息。

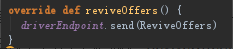
运行时调用的是CoarseGrainedSchedulerbackend的reviveOffers方法。ReviveOffers是个case Object,啥也没有,因为不需要封装数据,相当于一个触发器。因为资源调度肯定是统一进行调度算法的,这里只不过相当于一个信号灯。所以只要资源变化的时候ReviveOffers就会被触发,因为不是通过ReviveOffers本身去调资源的。只不过是触发调资源的过程,为什么要触发资源,原因很简单提交新的任务过来了
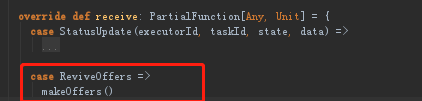
(5)DriverEndPoint这个驱动程序的调度器收到ReviveOffers消息后调用makeOffers,makeOffers的目的是找出可以利用的executors。
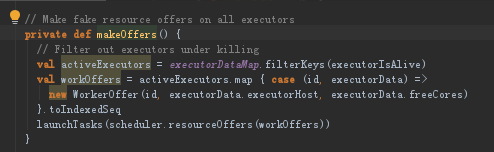
创建WorkerOffer,WorkerOffer是个很简单的数据结构,是个case class,在这边会告诉我们具体的Executor可用的资源,可用资源是是cpu的core(为什么不考虑内存只考虑core?因为已经分配好了,基本都符合要求(内存),现在要计算,计算的核心考虑对象是cpu)

launchTasks参数中的Scheduler.resourceOffers是根据已经可用的计算资源,为每个task具体分配计算资源。这里的Scheduler就是TaskSchedulerImpl。输入是ExecutorBackend及其上可用的Cores,输出是TaskDescription的二维数组,在其中确定了每个Task具体运行在哪个ExecutorBackend。
(6)resourceOffers是如何确定task具体运行在哪个ExecutorBackend上的呢?作为参数传进来的WorkerOffer是个一维数据,里面装了所有可计算的资源,返回的是个二维数据每个任务他的数据本地性。
①首先开始循环遍历可用资源(o <- offers),然后判断如果不包含这个executor,要把executor加进去,刚才是最新请求了一下机器有哪些可用资源,executorIdToHost这是个内存数据结构
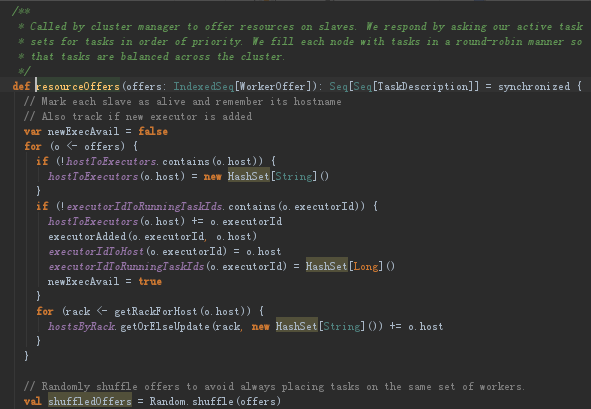

这个是数据本地性,默认情况下在一个rack,实际生产环境肯定是若干个rack。
②shuffledOffers把我们所有可用计算资源打散,以寻求计算的负载均衡。tasks中对每个worker new了一个ArrayBuffer里面是TaskDescription,每个executor可用放几个TaskDescription就可以运行多少个任务,他有多少个core就可以立即分配多少个任务。所以new一个一维数组他的长度是当前机器的cores的个数决定的。(现在创建的一维数组是说当前这个ExecutorBackend可以分配多少个task也就是可以并行运行多少个task)。
sortedTaskSets根据调度顺序,返回的是TaskSet集体的计算集合。然后遍历所有排序后的TaskSet集合,如果有可用的新的executor,我们会把executorAdded交给taskSet。
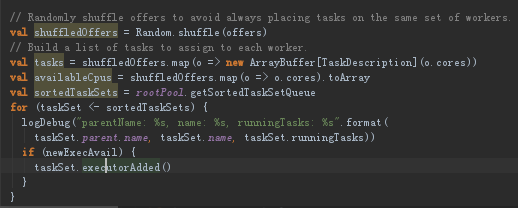
 如果有新的ExecutorBackend分配给我们的job,此时会调用executorAdded来获得最新的完整的可用计算资源
如果有新的ExecutorBackend分配给我们的job,此时会调用executorAdded来获得最新的完整的可用计算资源
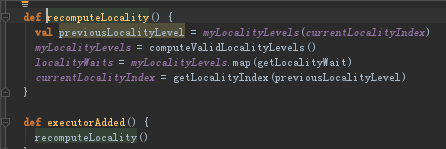
③回到resourceOffers方法中(这个是TaskSchedulerImpl的),接下来这里是两层循环,追求最高最优先级本地性(首先是PROCESS_LOCAL,不行就NODE_LOCAL,不行的话就…按优先级下去)。
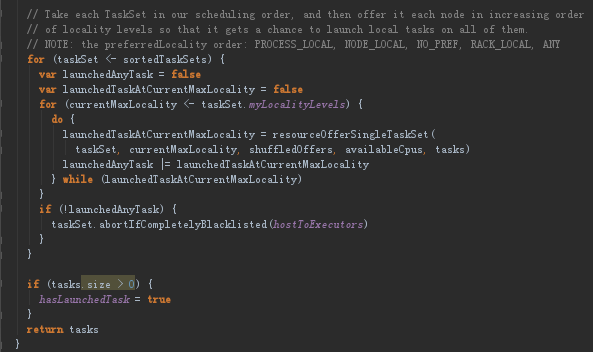
在resourceOfferSingleTaskSet中,获得executorId,根据他的id获得host,然后判断一下每台机器可用的计算资源,PUC_PER_TASK默认为1(就是每个任务默认用一条线程)。然后就就开始进行总路规则的计算
如果符合要求的话就执行,所以最后算的还是要靠taskSetManager的resourceOffer,他获得就是每个任务具体运行在哪里,返回的就是TaskDescription
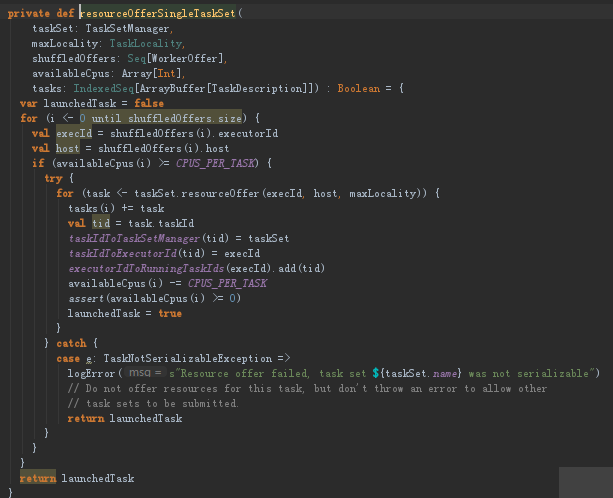
④到taskSetManager的resourceOffer方法中
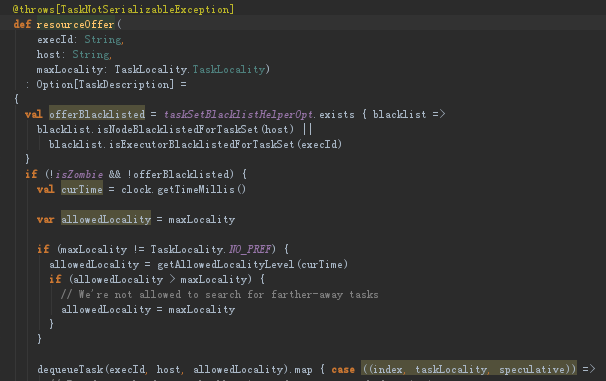
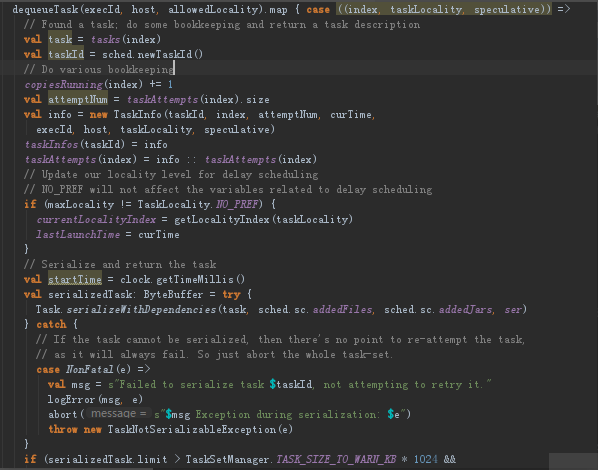
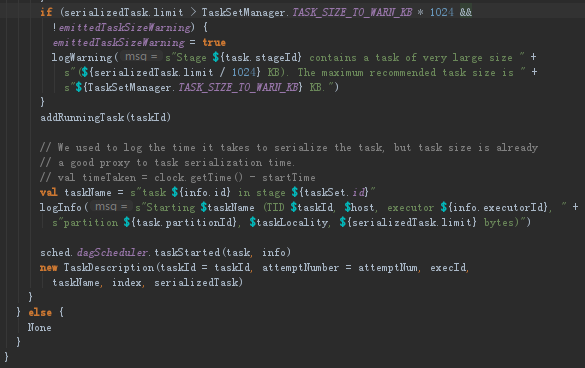
因为实质来讲DAGScheduler已经告诉我们具体任务运行在哪台机器上。DAGScheduler是从数据层面考虑preferedLocation的(从RDD的层面确定),而TaskScheduler是从具体计算Task的角度考虑计算的本地性。他们并没有冲突而且是配合在一块的,所以说TaskScheduler是更底层的调度DAGScheduler是高层的调度。DAGScheduler确定数据的本地性就是确定数据在哪台机器上,根据这个数据本地性确认计算要发生在哪台机器上,TaskScheduler有5个数据本地性原则,肯定追求PROCESS_LOCAL(考虑数据是否直接在内存中)。一个是高层,一个是底层,高层就是preferedLocation确定数据具体在哪台机器上,机器上有executor,底层就是知道数据本地性的情况下任务的本地性,所以底层是更具体的。TaskScheduler确定executor上具体的task运行的数据具体在内存中还是节点上,还是在这台机器上,这完全是2码事
(7)回到makeOffers方法中,本地两个层面,一个数据本地性,一个是计算的本地性,确定好后就launchTasks,把任务发送给executorBackend去执行。首先将二维数组进行序列化。
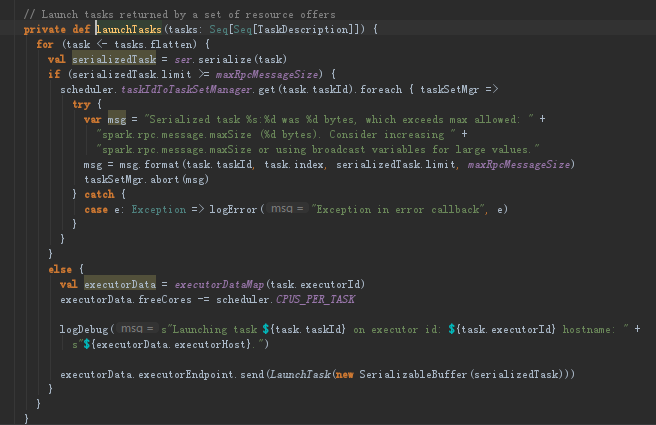
任务要大于128M就把任务abort丢弃

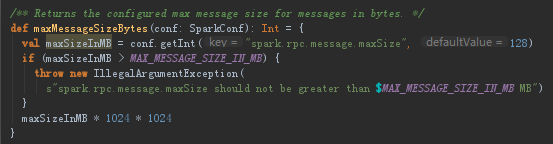
如果任务小于128M。那么启动任务,启动具体任务的是CoarseGrainedSchedulerBackend去launchTask到具体的ExecutorBackend上。TaskSetManager是跟踪任务的,不是发送任务的
(8)CoarseGrainedExecutorBackend接收到消息之后,就反序列化交给executor
3、任务调度过程总结
(1)DAG构建完毕,提交stage给taskScheduler,taskScheduler的实例TaskSchedulerImpl执行submitTasks方法,将TaskSet加入到TaskSetManager中进行管理;
(2)SchedulerBuilder.addTaskSetManager方法SchedulerBuilder确定在哪个ExecutorBackend中(按照TaskSetManager的locality aware来确定每个task具体运行在哪个ExecutorBackend中),SchedulableBuilder是整个应用程序级别调度器有FIFO和FAIR两种调度模式;
(3)CoarseGrainedSchedulerBackend.reviveOffers给DriverEndPoint发送ReviveOffers,ReviveOffers本身是一个空的case Object对象,只是起到触发底层资源调度的作用,在有Task提交或者计算资源变动的时候会发生ReviveOffers这个消息作为触发器;
(4)DriverEndPoint收到ReviveOffers消息,然后路由到makeOffers具体的方法中,在makeOffers方法中首先准备好所有可以用于计算的workOffers(代表了所有可用ExecutorBackend中可以使用的Cores等信息);
(5)调用TaskSchedulerImpl的resourceOffers,作为参数执行launchTasks发送出去。TaskSchedulerImpl为每一个Task具体分配计算资源,输入是ExecutorBackend及其上可用的Cores,输出TaskDescription二维数组,在其中为每个Task具体运行在哪个ExecutorBackend。
resourceOffers是如何确定Task运行在哪个ExecutorBackend上的算法实现如下:
(1)通过Random.shuffle方法重新洗牌所有的计算资源,用于负载均衡;
(2)根据每个ExecutorBackend的Cores个数,申明声明类型为TaskDescription的ArrayBuffer数组;
(3)如果新的ExecutorBackend分配给我们的Job,此时会回调用executorAdded来获得最新的完整的可用计算资源
(4)求的最高级别的优先级本地性;
(5)通过TaskSetManager的resourceOffers最终确定每个Task具体运行在哪个ExecutorBackend的具体的本地性;
(6)通过launchTasks把任务发送给ExecutorBackend执行。
注意:
(1)默认Task的最大重试次数是4;
(2)spark目前支持FIFO的FAIR两种调度器;
(3)TaskScheduler中要负责为Task分配计算资源,此时程序已经具备集群中你的计算资源了,根据计算本地性原则确定Task具体运行在哪个ExecutorBackend中,每个Task默认是采用一条线程计算的;
(4)TaskDescription中已经确定好Task运行在哪个ExecutorBackend;
(5)数据本地优先级由高到底为:PROCESS_LOCAL,NODE_LOCAL,NO_PREF,RACK_LOCAL,ANY;
(6)DAGScheduler是从数据层面考虑数据本地性,而TaskScheduler是从具体计算Task角度考虑计算本地性的。也就是DAGScheduler通过preferedLocation确定数据的本地性就是确定数据在哪台机器上,根据这个数据本地性确认计算要发生在哪台机器上,TaskScheduler就是知道数据本地性的情况下任务的本地性,所以底层是更具体的;
(7)Task进行广播的时候,如果任务大于128M的话,则Task会被直接丢弃,如果小于128M的话会通过CoarseGrainedSchedulerBackend去launchTask到具体的ExecutorBackend上。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183207.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
