大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
此文章是跟DataWhale开源组织刷leetcode算法题时所写,主要内容借鉴算法通关手册
1.链表排序简介
在数组排序中,常见的排序算法有:冒泡,选择,插入,希尔,归并,快速,堆,计数,桶,基数排序等
而对于链表排序而言,因为链表不支持随机访问,访问链表后面的节点只能依靠next指针从头部顺序遍历,所以相对于数组排序问题来说,链表排序问题会更加复杂一点。
下面来总结一下适合链表排序与不适合链表排序的算法:
- 适合链表的排序算法:冒泡,选择,插入,归并,快速,计数,桶,基数排序
- 不适合链表的排序算法:希尔排序
- 可以用于链表排序但不建议使用的排序算法:堆排序
希尔排序为什么不适合链表排序?
(什么是希尔排序?)
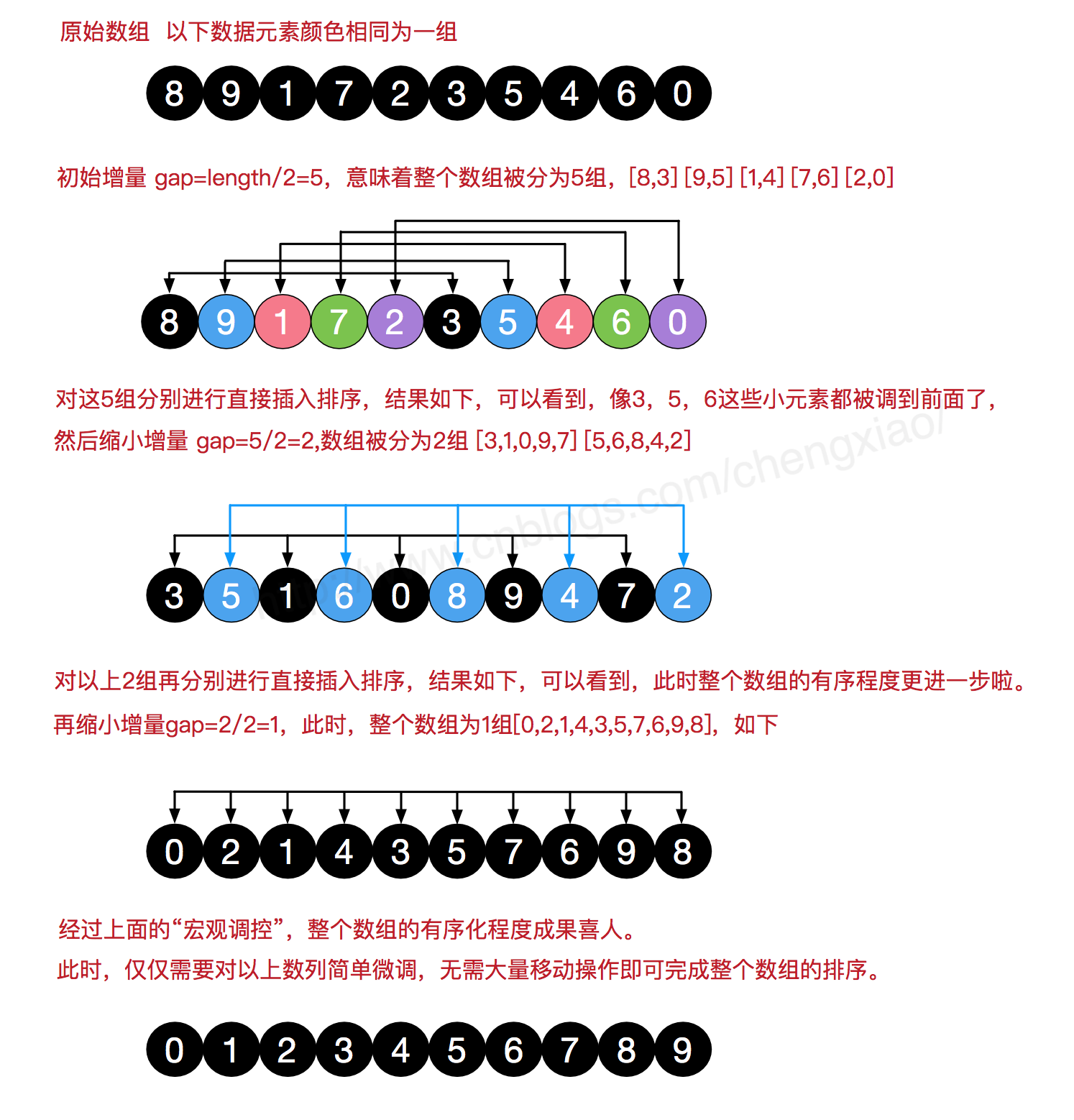

希尔排序:希尔排序中经常涉及到对序列中第i + gap的元素进行操作,其中gap是希尔排序中当前的步长。而链表不支持随机访问的特性,导致这种操作不适合链表,因而希尔排序算法不适合进行链表排序
为什么不建议使用堆排序?
堆排序:堆排序所使用的最大堆/最小堆结构本质上是一颗完全二叉树。而完全二叉树适合采用顺序存储结构(数组)。因为数组存储的完全二叉树可以很方便的通过下标序号来确定父亲节点和孩子节点,并且可以极大限度的节省存储空间。
而链表用在存储完全二叉树的时候,因为不支持随机访问的特性,导致其寻找节点和父亲节点会比较耗时,如果增加值向父亲节点的变量,又会浪费大量存储空间。所以堆排序算法不适合进行链表排序。
如果一定要对链表进行堆排序,则可以使用额外的数组空间表示堆结构。然后将链表中各节点的值依次添加入堆结构中,对数组进行堆排序。排序后,再按照堆中元素顺序,依次建立链表节点,构建新的链表并返回新链表头节点。
需要用到额外的辅助空间进行排序的算法
刚才我们说到如果一定要对链表进行堆排序,则需要使用额外的数组空间。除此之外,计数排序,桶排序,基数排序都需要用到额外的数组空间。
接下来,我们将对适合链表排序的8种算法进行一一讲解。当然,这些排序算法不用完全掌握,重点掌握【链表插入排序】,【链表归并排序】这两种排序算法。
2.链表冒泡排序
2.1 链表冒泡排序算法描述
- 使用
node_i、node_j和tail。其中node_i用于控制外循环次数,循环次数为链节点个数(链表长度)。node_j和tail用于控制内循环次数和循环结束位置。 - 排序开始前,将
node_i、node_j置于头节点位置。tail指向链表末尾,即None。 - 比较链表中相邻两个元素
node_j.val与node_j.next.val的值大小,如果node_j.val > node_j.next.val,则值相互交换。否则不发生交换。然后向右移动node_j指针,直到node_j.next == tail时停止。 - 一次循环之后,将
tail移动到node_j所在位置。相对于tail向左移动了一位。此时tail节点右侧为链表中最大的链节点。 - 然后移动
node_i节点,并将node_j置于头节点位置。然后重复第3,4步操作。 - 直到
node_i节点移动到链表末尾停止,排序结束。 - 返回链表的头节点
head。
2.2 链表冒泡排序算法实现代码
def bubbleSort(self, head: ListNode):
node_i = head
tail = None
# 外层循环次数为 链表节点个数
while node_i:
node_j = head
while node_j and node_j.next != tail:
if node_j.val > node_j.next.val:
# 交换两个节点的值
node_j.val, node_j.next.val = node_j.next.val, node_j.val
node_j = node_j.next
# 尾指针向前移动1位,此时尾指针右侧为排好序的链表
tail = node_j
node_i = node_i.next
return head
3.链表选择排序
3.1 链表选择排序算法描述
- 使用两个指针
node_i、node_j。node_i既可以用于控制外循环次数,又可以作为当前未排序链表的第一个链节点位置。 - 使用
min_node记录当前未排序链表中值最小的链节点。 - 每一趟排序开始时,先令
min_node = node_i(即暂时假设链表中node_i节点为值最小的节点,经过比较后再确定最小值节点位置)。 - 然后依次比较未排序链表中
node_j.val与min_node.val的值大小。如果node_j.val < min_node.val,则更新min_node为node_j。 - 这一趟排序结束时,未排序链表中最小值节点为
min_node,如果node_i != min_node,则不用交换。 - 排序结束后,继续向右移动
node_i,重复上述步骤,在剩余未排序链表中寻找最小的链节点,并与node_i进行比较和交换,直到node_i == None或者node_i.next == None时,停止排序。 - 返回链表的头结点
head。
3.2 链表选择排序实现代码
def sectionSort(self, head: ListNode):
node_i = head
# node_i 为当前未排序链表的第一个链表结点
while node_i and node_i.next:
# min_node 为未排序链表中的值最小节点
min_node = node_i
node_j = node_i.next
while node_j:
if node_j.val < min_node.val:
min_node = node_j
node_j = node_j.next
# 交换值最小节点与未排序链表中第一个节点的值
if node_i != min_node:
node_i.val, min_node.val = min_node.val, node_i.val
node_i = node_i.next
return head
4.链表插入排序
4.1 链表插入排序算法描述
- 先使用哑节点
dummy_head构造一个值向head的指针,使得可以从head开始遍历。 - 维护
sorted_list为链表的已排序部分的最后一个节点,初始时,sorted_list = head。 - 维护
prev为插入元素位置的前一个节点,维护cur为待插入元素。初始时,prev = head,cur = head.next。 - 比较
sorted_list和cur的节点值。- 如果
sorted_list.val <= cur.val,说明cur应该插入到sorted_list之后,则将sorted_list后移一位。 - 如果
sorted_list.val > cur.val,说明cur应该插入到head与sorted_list之间。则使用prev从head开始遍历,直到找到插入cur的位置的前一个节点位置,然后将cur插入。
- 如果
- 令
cur = sorted_list.next,此时cur为下一个待插元素。 - 重复4、5步骤,直到
cur遍历结束为空。返回dummy_head的下一个节点。
4.2 链表插入排序实现代码
def insertionSort(self, head: ListNode):
if not head and not head.next:
return head
dummy_head = ListNode(-1)
dummy_head.next = head
sorted_list = head
cur = head.next
while cur:
if sorted_list.val <= cur.val:
# 将 cur 插入到 sorted_list之后
sorted_list = sorted_list.next
else:
prev = dummy_head
while prev.next.val <= cur.val:
prev = prev.next
# 将 cur 到链表中间
sorted_list.next = cur.next
cur.next = prev.next
prev.next = cur
cur = sorted_list.next
return dummy_head.next
5.链表归并排序
5.1 链表归并排序算法描述
-
分割环节:找到链表中心链节点,从中心节点将链表断开,并递归进行分割。
- 使用快慢指针
fast = head.next、slow = head, 让fast每次移动2步,slow移动1步,移动到链表末尾,从而找到链表中心链节点,即slow。 - 从中心位置将链表从中心位置分为左右链表
left_head和right_head,并从中心位置将其断开,即slow.next = None。 - 对左右两个链表分别进行递归分割,直到每个链表中包含一个链节点。
- 使用快慢指针
-
归并环节:将递归后的链表进行两两归并,完成一遍后每个子链表长度加倍。重新进行归并操作,直到得到完整的链表。
- 使用哑节点
dummy_head构造一个头节点,并使用cur值向dummy_head用于遍历。 - 比较两个链表头节点
left和right的值大小。将较小的头节点加入到合并的链表中。并向后移动该链表的头节点指针。 - 然后重复上一步操作,直到两个链表中出现链表为空的情况。
- 将剩余链表插入到合并中的链表中。
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为合并后的头节点返回。
- 使用哑节点
5.2 链表归并排序实现代码
def merge(self, left, right):
# 归并环节
dummy_head = ListNode(-1)
cur = dummy_head
while left and right:
if left.val <= right.val:
cur.next = left
left = left.next
else:
cur.next = right
right = right.next
cur = cur.next
if left:
cur.next = left
elif right:
cur.next = right
return dummy_head.next
def mergeSort(self, head: ListNode):
# 分割环节
if not head or not head.next:
return head
# 快慢指针找到中心链节点
slow, fast = head, head.next
while fast and fast.next:
slow = slow.next
fast = fast.next.next
# 断开左右链节点
left_head, right_head = head, slow.next
slow.next = None
# 归并操作
return self.merge(self.mergeSort(left_head), self.mergeSort(right_head))
6.链表快速排序
6.1 链表快速排序算法描述
- 从链表中找到一个基准值
pivot,这里以头节点为基准值。 - 然后通过快慢指针
node_j、node_j在链表中移动,使得node_i之前的节点值都小于基准值,node_i之后的节点值都大于基准值。从而把数组拆分为左右两个部分。 - 再对左右两个部分分别重复第二步,直到各个部分只有一个节点,则排序结束。
6.2 链表快速排序实现代码
def partition(self, left: ListNode, right: ListNode):
# 左闭右开,区间没有元素或者只有一个元素,直接返回第一个节点
if left == right or left.next == right:
return left
# 选择头节点为基准节点
pivot = left.val
# 使用node_i,node_j双指针,保证node_i之前的节点都小于基准节点值,node_i与node_j之间的节点值都大于等于基准节点值
node_i, node_j = left, left.next
while node_j != right:
# 发现一个小于基准值的元素
if node_j.val < pivot:
# 因为 node_i 之前节点都小于基准值,所以先将node_i向右移动一位(此时node_i节点大于等于基准节点值)
node_i = node_i.next
# 将小于基准值的元素 node_j 与当前node_i换位,换位后可以保证node_i之前的节点都小于基准节点值
node_i.val, node_j.val = node_j.val, node_i.val
node_j = node_j.next
# 将基准节点放到正确位置上
node_i.val, left.val = left.val, node_i.val
return node_i
def quickSort(self, left:ListNode, right: ListNode):
if left == right or left.next == right:
return left
pi = self.partition(left, right)
self.quickSort(left, pi)
self.quickSort(pi.next, right)
return left
7.链表计数排序
7.1 链表计数算法描述
- 使用
cur指针遍历一遍链表。找出链表中最大值list_max和最小值list_min。 - 使用数组
counts存储节点出现次数。 - 再次使用
cur指针遍历一遍链表。将链表中每个值为cur.val的节点出现次数,存入数组对应第cur.val - list_min项中。 - 反向填充目标链表:
- 建立一个哑节点
dummy_head,作为链表的头节点,使用cur指针值向dummy_head。 - 从小到大遍历一遍数组
counts。对于每个counts[i] != 0的元素建立一个链节点,值为i + list_min,将其插入到cur.next上。并向右移动cur。同时counts[i] -= 1。直到counts[i] == 0后继续向后遍历数组counts。 - 将哑节点
dummy_dead的下一个链节点dummy_head.next作为新链表的头节点返回。
- 建立一个哑节点
7.2 链表计数排序代码实现
def countingSort(self, head: ListNode):
if not head:
return head
# 找出链表中最大值list_max和最小值list_min
list_min, list_max = float('inf'), float('-inf')
cur = head
while cur:
if cur.val < list_min:
list_min = cur.val
if cur.val > list_max:
list_max = cur.val
cur = cur.next
size = list_max - list_min + 1
counts = [0 for _ in range(size)]
cur = head
while cur:
counts[cur.val - list_min] += 1
cur = cur.next
dummy_head = ListNode(-1)
cur = dummy_head
for i in range(size):
while counts[i]:
cur.next = ListNode(i + list_min)
counts[i] -= 1
cur = cur.next
return dummy_head.next
8.链表桶排序
8.1 链表桶排序算法描述
- 使用
cur指针遍历一遍链表。找出链表中最大值list_max和最小值list_min。 - 通过
(最大值 - 最小值) / 每个桶的大小计算出桶的个数,即bucket_count = (list_max - list_min) // bucket_size + 1个桶。 - 定义二维数组
buckets为桶,外层数组大小为bucket_count个。 - 使用
cur指针再次遍历一遍链表,将每个元素装入对应的桶中。 - 对每个桶内元素单独排序(使用插入、归并、快排等算法)。
- 最后按照顺序将桶内的元素拼成新的链表,并返回。
8.2 链表桶排序代码实现
def insertionSort(self, arr):
for i in range(1, len(arr)):
temp = arr[i]
j = i
while j > 0 and arr[j - 1] > temp:
arr[j] = arr[j - 1]
j -= 1
arr[j] = temp
return arr
def bucketSort(self, head: ListNode, bucket_size = 5):
if not head:
return head
# 找出链表中最大值list_max 和最小值 list_min
list_min, list_max = float('inf'), float('-inf')
cur = head
while cur:
if cur.val < list_min:
list_min = cur.val
if cur.val > list_max:
list_max = cur.val
cur = cur.next
# 计算桶的个数,并定义桶
bucket_count = (list_max - list_min) // bucket_size + 1
buckets = [[] for _ in range(bucket_count)]
# 将链表节点依次添加到对应桶中
cur = head
while cur:
buckets[(cur.val - list_min) // bucket_size].append(cur.val)
cur = cur.next
dummy_head = ListNode(-1)
cur = dummy_head
for bucket in buckets:
# 对桶中元素单独排序
self.sortLinkedList(bucket)
for num in bucket:
cur.next = ListNode(num)
cur = cur.next
return dummy_head.next
9. 链表基数排序
9.1 链表基数排序算法描述
- 使用
cur指针遍历,获取节点位数最长的位数size。 - 从个位到高位遍历位数。因为
0–9共有10位数字,使用建立10个桶。 - 以每个节点对应数上的数字为索引,将节点值放入到对应桶中。
- 建立一个哑节点
dummy_head,作为链表的头节点。使用cur指针指向dummy_head。 - 将桶中元素依次取出,并根据元素值建立链表节点,并插入到新的链表后面。从而生成新的链表。
- 之后依次以十位,百位,…,直到最大值元素的最高位处值为索引,放入到对应桶中,并生成新的链表,最终完成排序。
- 将哑节点
dummy_dead的下一个链节点dummy_head.next作为新链表的头节点返回。
9.2 链表基数排序代码实现
def radixSort(self, head: ListNode):
# 计算位数最长的位数
size = 0
cur = head
while cur:
val_len = len(str(cur.val))
if val_len > size:
size = val_len
cur = cur.next
# 从个位到高位遍历位数
for i in range(size):
buckets = [[] for _ in range(10)]
cur = head
while cur:
# 以每个节点对应位数上的数字为索引,将节点值放入到对应桶中
buckets[cur.val // (10 ** i) % 10].append(cur.val)
cur = cur.next
# 生成新的链表
dummy_head = ListNode(-1)
cur = dummy_head
for bucket in buckets:
for num in bucket:
cur.next = ListNode(num)
cur = cur.next
head = dummy_head.next
return head
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183104.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
