大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
链表排序与数组排序的区别
数组的排序几乎所有人都很熟悉了,常用的算法插入、冒泡、归并以及快排等都会或多或少依赖于数组可以在O(1)时间随机访问的特点。
链表排序一般指单链表排序,链表是不支持随机访问的,需要访问后面的节点只能从表头顺序遍历,所以链表的排序是一个相对比较复杂的问题。
那么怎样进行链表排序呢?
借助外部空间
既然数组排序简单,那可以借助数组进行排序:
- 把链表中的值一次遍历导入数组(时间复杂度O(n))
- 对数组进行排序(可以选择各种算法,假设选择快排,时间复杂度O(nlogn))
- 把排序后的元素依次放入链表的节点内,也是一次遍历
综上,该方法时间复杂度为O(nlogn),空间复杂度主要为额外的数组空间(如果选择其他排序算法,可能还需要更多的空间)O(n)。
不过这种方法有点投机取巧的意思:
class Solution {
public:
ListNode* sortList(ListNode* head) {
if(!head) return head;
vector<int> a;
auto p = head;
while(p != NULL){
a.push_back(p->val);
p = p->next;
}
delete p;
sort(a.begin(), a.end()); //可以自己写个快排,会提升不少效率
auto q = head;
for(const auto &c : a){
q->val = c;
q = q->next;
}
delete q;
return head;
}
};
冒泡排序
链表可以使用冒泡排序吗?
我们知道,冒泡排序一次冒泡会让至少一个元素移动到它应该处于的位置,n次(可能小于n次)冒泡之后那就所有元素都在自己应该在的位置了。
对于节点pre,cur,如果两者不满足大小关系要求,在数组排序里面,我们会交换两者的值,但是在链表排序里面,有两种选择:
- 交换节点的值,更简单,但是很多题目会要求不能单纯的交换节点的值(⊙﹏⊙)
- 交换节点,复杂,主要体现在两个节点的前驱后继的处理上(因为只能单向遍历)。
第一种情况,可以交换节点的值:
class Solution {
public:
void bubbleSort(ListNode *head, int n){
if(!head || !head->next) return;
for(int i = 0; i < n; ++i){
auto pre = head;
auto cur = head->next;
bool flag = 0;
for(int j = 0; j < n-i-1; ++j){
if(cur != NULL && pre->val > cur->val){
swap(pre->val, cur->val);
flag = 1;
}
pre = pre->next;
cur = cur->next;
}
if(!flag) break;
}
}
ListNode* sortList(ListNode* head) {
auto p = head;
int n = 0; // 记录节点个数
while(p != NULL){
++n;
p = p->next;
}
bubbleSort(head, n);
return head;
}
};
以上代码时间复杂度为O( n 2 n^2 n2), 空间复杂度O(1)。
可以交换节点值的时候代码就会清晰明了,只需要处理好边界问题即可。不过上述代码表现不太好的地方是时间复杂度为O( n 2 n^2 n2),比如在148. 排序链表 里面,就会因为超出时间限制而没法通过最后一个测试用例。
可以看到,如果可以交换节点的值,那使用插入、快排这些顺序遍历可以实现的算法都是可以的(当然,快排就不能使用双指针法了)。
第二种情况,不能交换节点的值:
前面说过,交换节点的难点在于前驱后继的处理,如果当前要交换的pre和cur如下所示:
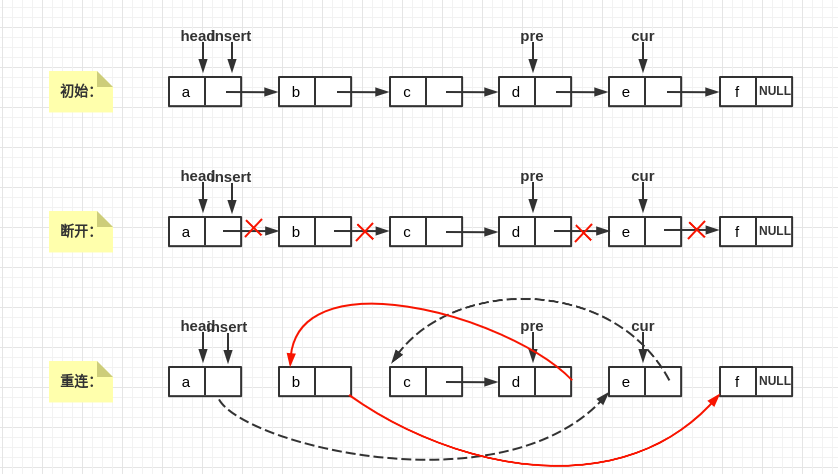

可以看到要交换节点,我们需要:
- 随时记录
pre,cur的前驱 - 两个临时变量保存
pre,cur的后继 - 更改指针
看上去就头很大。但事实上链表排序完全没必要使用冒泡,因为对于链表来说,插入排序比冒泡排序更容易理解也更简单,具体可以看下一部分插入排序的讲解。这儿就不贴冒泡的代码了(其实是因为没写(⊙﹏⊙))。
插入排序
数组的插入排序,简单来说就是每次在未排序区间取元素,然后将该元素插入到已排序空间的合适位置,直到未排序空间为空。
链表的插入排序处理逻辑与数组的是一致的。
插入,顾名思义就是在两个节点之间插入另一个节点,并且保持序列是有序的。上一节为什么说插入比冒泡更简单呢(无论是链表还是数组,一般都优先使用插入排序),看下面的图,如果当前要将节点cur插入到节点pre之后:
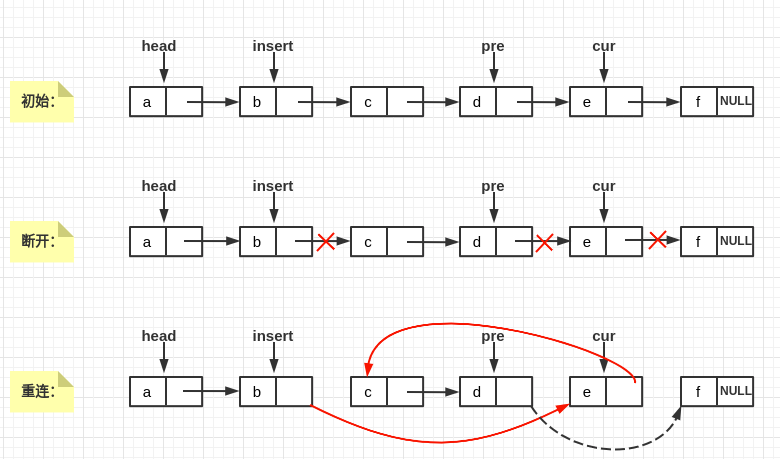
可以看到整体操作逻辑简单了许多:我们只需要知道cur的前驱和插入位置(其实就是要插在哪个节点之后)就可以啦。
链表的插入排序对应:
147. 对链表进行插入排序 – 力扣(LeetCode)
LeetCode第 147 题:对链表进行插入排序(C++)
贴一个代码:
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if(!head || !head->next) return head;
auto dummy = new ListNode(-1);
dummy->next = head;
auto pre = head; // 当前节点的前驱
auto cur = head->next;
while(cur != NULL){
auto tmp = dummy;
if(pre->val >= cur->val){ //需要进行插入
while(tmp->next->val < cur->val) //从第一个节点开始寻找插入位置
tmp = tmp->next; // cur应该插入在tmp后面
pre->next = cur->next; //断开节点cur
cur->next = tmp->next; //插入
tmp->next = cur;
cur = pre->next; //继续处理下一个节点
}
else{ //无需插入
pre = pre->next;
cur = cur->next;
}
}
return dummy->next;
}
};
时间复杂度为O( n 2 n^2 n2),空间复杂度为O(1)。
可以进行优化:因为上述代码我们每次的插入点都是从头开始查找的,但是其实可以先和上一个插入点tmp进行比较,如果当前节点值更大的话,查找插入点的起始点就可以是tmp节点,否则再从头开始查找插入点。
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if(!head || !head->next) return head;
auto dummy = new ListNode(-1);
dummy->next = head;
auto pre = head; // 当前节点的前驱
auto cur = head->next;
auto tmp = dummy; //tmp用于记录上一次的插入位置
while(cur != NULL){
if(cur->val < tmp->val) tmp = dummy; //如果当前值比上一次插入点的值要小,就只能从头查找插入点,否则,插入点的查找可以从上一个插入点之后开始查找
if(pre->val >= cur->val){ //需要进行插入
//tmp开始寻找插入位置
while(tmp->next->val < cur->val) tmp = tmp->next; // cur应该插入在tmp后面
pre->next = cur->next; //断开节点cur
cur->next = tmp->next; //插入
tmp->next = cur;
cur = pre->next; //继续处理下一个节点
}
else{ //无需插入
pre = pre->next;
cur = cur->next;
}
}
return dummy->next;
}
};
归并排序
后面的归并排序和快速排序时间复杂度都是O(nlogn),空间复杂度则略有不同,两者的思想都是分治加递归(递归不是必要的),只不过一个自顶向下,一个自下而上。
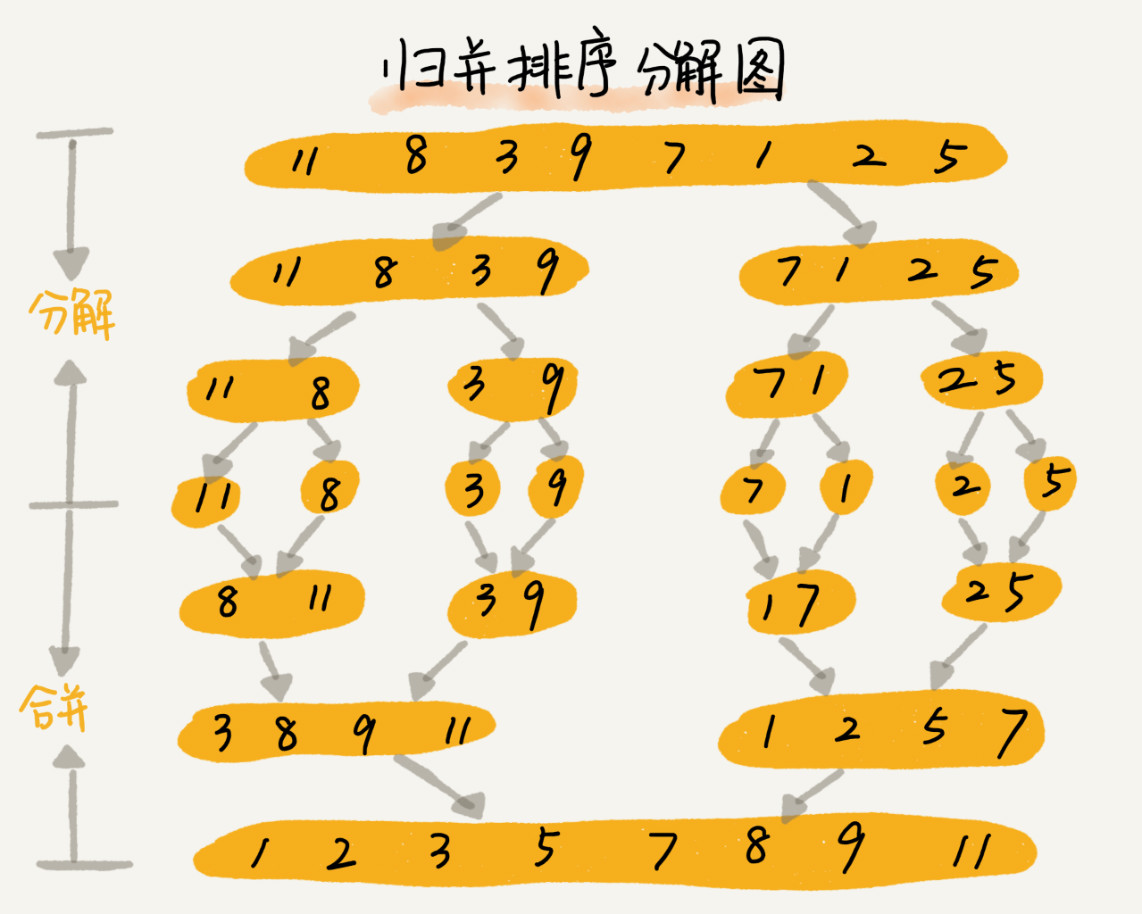
先来看归并:
归并排序其实是链表排序的主流方法。 归并主要分为分割和合并两大部分,入栈的时候分割,出栈的时候合并,这也是归并常常采用递归实现的原因。
首先,如何分割?数组里面我们是这样操作的:
void merge_sort_c(vector<int> &a, int beg, int end){
if (beg >= end) return;
auto mid = beg +(end-beg) / 2;
merge_sort_c(a, beg, mid);
merge_sort_c(a, mid+1, end);
merge(a, beg, mid, end);
}
主要就是获取中间位置,然后分治,但是对于链表来说,怎样寻找中间节点呢?
- 直接法:第一次遍历获取节点个数,第二次遍历就可以定位到中间节点了
- 快慢指针法:慢指针一次走一步,快指针一次走两步,当快指针达到末尾的时候,慢指针正好会指向中间节点,只用一次遍历。
此处就是用快慢指针法来定位中间节点,从而达到分割的目的:
ListNode *slow = head, *fast = head->next;
// fast一次要走两步
while(fast != NULL && fast->next != NULL){
slow = slow->next;
fast = fast->next->next;
}
auto tmp = slow->next;//右边链表的开头
slow->next = NULL; //切断形成左半边链表
其实就是将链表切成两部分,也就是分治嘛。。。
那么又如何处理合并呢?
数组的merge函数我们已经很熟悉了:
需要一个辅助数组,大小与A[p…r]相同,双指针i,j分别指向两个待合并数组开头,假设为A[p…q],A[q+1,r]:
- 比较A[i]与A[j],将较小者放入辅助数组并移动指针指向下一个元素…直到有一个数组处理完成
- 然后再将未处理完成的数组剩余元素一次性放入辅助数组(此时辅助数组里就是排序好的数组了)
- 最后将辅助数组里的元素搬运回原数组
可以看到处理的空间复杂度为O(n),主要是辅助数组的开销。那这儿为什么要用辅助数组呢?主要是因为如果不使用辅助数组的话,就只能进行元素插入,而数组存储空间是连续的,意味着插入操作将会带来大量的元素移动(O(n)时间复杂度),这是接受不了的。
void merge(vector<int> &a, int beg, int mid, int end){
vector<int> tmp(end-beg+1, 0);
int i = beg, j = mid + 1;
int k = 0;
while (i <= mid && j <= end){
if (a[i] <= a[j])
tmp[k++] = a[i++];
else
tmp[k++] = a[j++];
}
// 处理剩余部分
int start = (i == mid + 1) ? j : i;
int tail = (i == mid + 1) ? end : mid;
while (start <= tail)
tmp[k++] = a[start++];
for (const auto &c : tmp) a[beg++] = c;
}
但是,如果处理链表就不存在这个问题,因为链表不是连续存储的,插入删除的时间复杂度都是O(1)。 所以链表的合并并不需要O(n)的空间复杂度,因为我们不需要类似辅助数组这样的东西,我们仅仅是调整一下相应的指针就能达到合并的目的。
void merge(ListNode *left, ListNode *right, ListNode *h){
while(left != NULL && right != NULL){
if(left->val < right->val){
h->next = left;
left = left->next;
}else{
h->next = right;
right = right->next;
}
h = h->next; //随时更新h,好在h后面加入新节点
}
h->next = left ? left : right; //处理剩余部分
}
那上述merge的空间复杂度是O(1)还是O(logn)呢?其实我也不太确定,因为递归的函数栈确实是logn,这个算不算空间复杂度也是众说纷纭。
递归实现的链表归并排序代码:
class Solution {
public:
ListNode* merge(ListNode *left, ListNode *right){
auto head = new ListNode;
auto h = head;
while(left && right){
if(left->val < right->val){
h->next = left;
left = left->next;
}else{
h->next = right;
right = right->next;
}
h = h->next;
}
h->next = left == NULL ? right : left;
return head->next;
}
ListNode* merge_sort(ListNode *head){
if(!head->next) return head;
ListNode *slow = head, *fast = head->next;
while(fast && fast->next){
slow = slow->next;
fast = fast->next->next;
}
auto r_head = slow->next;//slow->next右边部分的头结点
slow->next = NULL;//左边切断开
auto left = merge_sort(head);
auto right = merge_sort(r_head);
return merge(left, right);
}
ListNode* sortList(ListNode* head) {
if (!head || !head->next) return head;
return merge_sort(head);
}
};
可以看一下这个题:
题目要求常数级的空间复杂度,如果递归栈算在空间复杂度里面的话,那上述递归的归并排序代码就不符合要求了。那不符合要求并不代表归并排序不行,因为递归只是算法的特定实现方式而已,我们也可以使用迭代来实现链表的归并排序。
看下面的示意图:
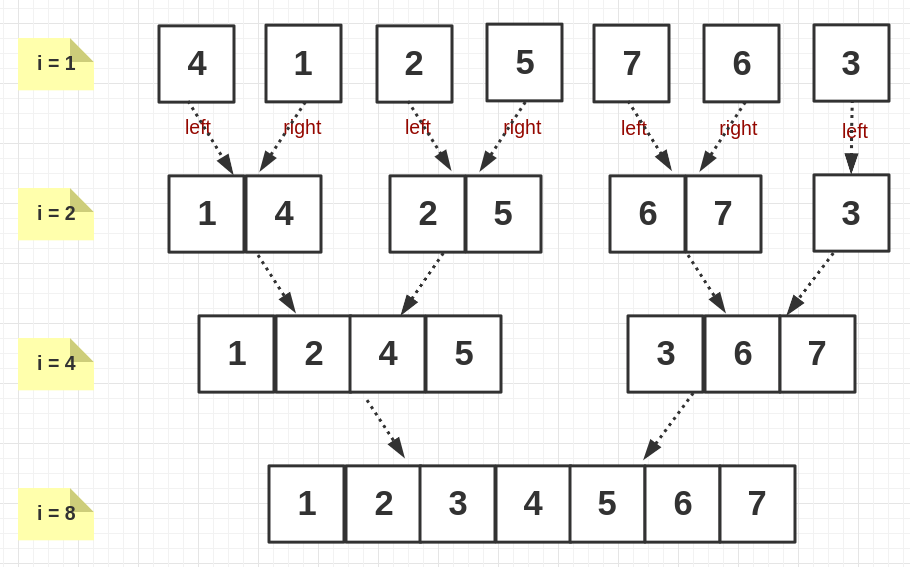
第一轮迭代 1 + 1-> 2,第二轮迭代 2 + 2-> 4,以此类推,总的迭代次数应该为logn,即迭代变量i每次都会变为之前的两倍,i即为每次迭代需要合并的块含有的元素数量。
- 首先,最外层迭代次数为
logn - 内层迭代变量
j递增方式为:j += 2*i,每次合并两块,合并完两块之后下一次循环合并再后面的两块…
迭代实现的代码会长了很多(很长。),但其实逻辑更简单,具体看注释吧:
class Solution {
public:
ListNode* sortList(ListNode* head) {
if (!head || !head->next) return head;
int n = 0;
for(auto i = head; i != NULL; i = i->next) ++n; //n为链表长度
auto dummy = new ListNode(-1);
dummy->next = head;
// 总体循环次数为logn
for(int i = 1; i < n; i += i){
auto beg = dummy;
// 最开始1个和1个合并为两个,然后2,2->4, 4,4->8
for(int j = 0; j + i < n; j += 2*i){ //j += 2*i为下一块的起点
auto left = beg->next;
auto right = left;
for(int k = 0; k < i; ++k) right = right->next;//right指向第二块的起点,每块有i个节点,越过i个节点即可
// merge第一块和第二块,起点分别为left, right
// 第一块的节点数为i, 第二块的节点数可能小于i(为i-1),因为节点个数有奇偶之分,所以需要检查right != NULL
int p = 0, q = 0;//计数
while(p < i && q < i && right != NULL){
if(left->val <= right->val){
beg->next = left;
left = left->next;
++p;
}else{
beg->next = right;
right = right->next;
++q;
}
beg = beg->next;
}
while(p < i){// 可能还有剩余未处理的
beg->next = left;
beg = beg->next;
left = left->next;
++p;
}
while(q < i && right != NULL){
beg->next = right;
beg = beg->next;
right = right->next; //right会指向下一块的起点
++q;
}
// 处理完之后beg指向的是两块中(已经排序好)元素最大的那个节点
beg->next = right; //调整beg位置,将beg和下一块连接起来
}
}
return dummy->next;
}
};
迭代实现就满足了上面的题目时间复杂度O(nlogn),以及常数级的空间复杂度的要求。
快速排序
终于到快速排序了╮(﹀_﹀)╭
数组快排简单说就是找分区点pivot(第一个或者最后一个),然后将小于pivot的元素全部放到它的左边,大于它的元素则放到右边,自上而下,分治+递归。
递归过程简单明了:
void quickSort(vector<int> &a, int beg, int end){
if (beg >= end) return;
auto q = partition(a, beg, end); //获取分区结点
quickSort(a, beg, q-1);
quickSort(a, q+1, end);
}
重点在于partition函数的实现,快速排序的多种实现方式_,贴两个常用的:
双指针法:
// 双指针(pivot为末尾)
int partition1_1(vector<int> &a, int low, int high){
auto pivot = a[high];
int i = low, j = high;
while (i < j){
// 先看左边(顺序不能错)
while (i < j && a[i] <= pivot) ++i;
// 再看右边
while (i < j && a[j] >= pivot) --j;
swap(a[i], a[j]);
}
swap(a[high], a[i]);
return i;
}
以及这个不知道名字的方法:
// 单边法(末尾为pivot)
int partition2_1(vector<int> &a, int low, int high){
auto pivot = a[high];
int i = low, j = low;//i指向以处理区间右边界,j用来遍历元素
while (j < high){
if (a[j] < pivot)
swap(a[i++], a[j]); //已处理区间多了一个元素,右边界增加1
++j;
}
swap(a[high], a[i]);
return i;
}
如果以开头作为pivot:
// 单边法(开头为pivot)
int partition2_2(vector<int> &a, int low, int high){
auto pivot = a[low];
int i = low+1, j = low+1;//i指向以处理区间右边界,j用来遍历元素
while (j <= high){
if (a[j] < pivot)
swap(a[i++], a[j]);//已处理区间多了一个元素,右边界增加1
++j;
}
swap(a[low], a[i-1]);
return i-1;
}
为什么要强调第二种我叫不上名字的方法以及它的以开头为pivot的版本呢,因为接下来我们要用在链表的快速排序上面。
首先想想我们为什么不用双指针法,因为双指针需要从后往前遍历啊,而单链表是没法从后往前遍历的。
所以我们需要第二种方法,因为它一直在从前往后遍历,而且最好是以链表开头作为pivot,因为也没法以链表结尾作为pivot(需要遍历到末尾)。那么现在我们就可以对链表进行partition了。
注意,这儿的partition是以排序可以交换节点的值为前提的。
partition函数逻辑和上一个处理数组的逻辑是一样的,细节上略有差别,主要因为:
- 处理数组的,可以访问到a[i-1],也就是边界的前一个元素
- 而链表则无法访问到上一个节点
class Solution {
public:
ListNode* partition(ListNode *head, ListNode *tail){
auto pivot = head->val;
auto left = head;
auto cur = head->next;
while(cur != tail){
if(cur->val < pivot){
left = left->next;
swap(left->val, cur->val);
}
cur = cur->next;
}
swap(head->val, left->val);
return left;
}
void quickSort(ListNode *head, ListNode *tail){//不包含tail
if(head == tail || head->next == tail) return; //head->next == tail表示区间内只有一个节点
auto q = partition(head, tail);
quickSort(head, q);
quickSort(q->next, tail);
}
ListNode* sortList(ListNode* head) {
if (!head || !head->next) return head;
quickSort(head, NULL);
return head;
}
};
既然上面的快排代码是建立在可以交换节点值的前提上的,那么如果不可以交换节点的值,只能交换节点,应该怎么写呢?
我们要做的依然是partition操作, 还是使用头结点作为pivot,把链表分为3部分:pivot左边,pivot,pivot右边。
具体的还是看注释吧,重点还是在划分部分:
class Solution {
public:
ListNode* quicksort(ListNode *head){
if(!head || !head->next) return head;
auto pivot = head->val;
auto left = new ListNode(-1); //左边部分的开头
auto right = new ListNode(-1); //右边部分的开头
ListNode *l = left,*r= right;
for(auto cur = head; cur != NULL; cur = cur->next){
if(cur->val < pivot){
l->next = cur;
l = l->next;
}else{
r->next = cur; //那么此处第一个就是head
r = r->next;
}
}
l->next = NULL;
r->next = NULL;
// 现在left->next即为左边部分的头结点
//right->next即为pivot
//riight->next->next即为右边部分的头结点
auto p = quicksort(left->next);
auto q = quicksort(right->next->next);
//上面分治的时候切断了, 最后需要再进行连接
//p可能为NULL
if(!p) left->next = right->next;
else{
left->next = p;
while(p->next != NULL) p = p->next; //p指向末尾
p->next = right->next;
}
right->next->next = q;
return left->next;
}
ListNode* sortList(ListNode* head) {
if (!head || !head->next) return head;
return quicksort(head);
}
};
换个写法:
class Solution {
public:
ListNode* quicksort(ListNode *head){
if(!head || !head->next) return head;
auto left = new ListNode(0);
auto right = new ListNode(0);
ListNode *l = left, *r = right;
auto pivot = head->val;
//cur从head->next开始,到最后再单独把head链接进来
for(auto cur = head->next; cur != NULL; cur = cur->next){
if(cur->val < pivot){
l->next = cur;
l = l->next;
}else{
r->next = cur;
r = r->next;
}
}
l->next = NULL;//断开形成左边链表
r->next = NULL;//断开形成右边链表
auto p = quicksort(left->next);
auto q = quicksort(right->next);
//最后再进行连接
//p可能为NULL
if(!p) left->next = head;
else{
left->next = p;
while(p->next != NULL) p = p->next;
p->next = head;
}
head->next = q;
return left->next;
}
ListNode* sortList(ListNode* head) {
if(!head || !head->next) return head;
return quicksort(head);
}
};
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/183038.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
