大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
上回讲完了伯努利分布、二项分布和Beta分布,以及从最大似然估计的非参数化思想和引入共轭先验,使得参数变成一个变量,建模求解的参数化方法两方面介绍了求解模型参数 的方法。没有读过的朋友可以参考:《PRML》学习笔记2.1——伯努利分布、二项分布和Beta分布,从贝叶斯观点出发
的方法。没有读过的朋友可以参考:《PRML》学习笔记2.1——伯努利分布、二项分布和Beta分布,从贝叶斯观点出发
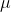
今天将为大家介绍两个更难理解的分布——多项式分布和狄利克雷分布。
1.多项式变量和多项式分布
伯努利分布的一个经典例子就是掷硬币,当你掷出去的时候,得到的结果只有正面朝上或者反面朝上两种可能,因此可以用进行建模。概率密度的表达式中,的取值只有两种情况——0或1,那么,这个建模方法就不适用于掷骰子了,毕竟骰子有6个面,对应着6种投掷结果。所以这时候就要将服从伯努利分布的变量进行扩展了。
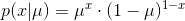
首先,使用一种方式来表达投掷骰子的结果,这里推荐的是”1-of-K”表示法,使用一个K维向量来表示状态,向量中一个元素等于1,其余元素为0,用来表示发生的是第k中情况:
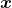
(1)
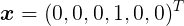
如果用参数表示的概率,那么的分布为:
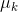
(2)
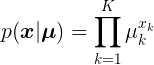
因为代表的是一种情况的概率,所以满足而且。可以看出,这是伯努利分布的一个多维上的推广,伯努利分布也可以换成相同的形式表达:,是一个2维向量,同样是用”1-of-K”表示法,这里的也满足且。
继续K维向量的讨论,由刚才的分布推导出其数学期望为:
(3)
![\large \mathbb{E}[\boldsymbol{x}|\boldsymbol{\mu}]=\sum_{\boldsymbol{x}}p(\boldsymbol{x}|\boldsymbol{\mu})\boldsymbol{x}=(\mu_1,...,\mu_K)^T=\boldsymbol{\mu}](https://img-blog.csdnimg.cn/20181229172456376)
那么,可以联系之前从伯努利分布到二项分布的引出过程,我们也制造一个集合,它由个独立同分布(如上面的分布)的向量,那么对应的似然函数是:
(4)
设 ,那么这个部分代表了似然函数对于个数据点的依赖关系,而也可以理解为,在次观测中,观测到的次数。接下来求解最大似然解,转化成对数似然函数:
(5)
同时存在的限制条件为,这个限制通过拉格朗日乘数实现,总的函数变为:
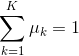
(6)
求导:
(7)
将代入中,解得,对应的就是在次观测中,观测到的次数的比例。然后,类似于二项分布,考虑的联合分布(二项分布只考虑的分布),可以得到:
(8)
此时满足。
2.狄利克雷分布
由多项式分布的形式可知,参数的共轭先验分布满足,其中且,由于这两个条件的限制,参数被限制在了k-1维的单纯性中(作为特例,Beta分布的参数分布在一条直线上)。归一化后,得到了狄利克雷分布:
(9)
它是Beta分布的多维推广。同样,用贝叶斯公式可得,参数的后验概率正比于似然函数和先验概率的乘积。因此形式一致,得到归一化后的后验概率分布也是狄利克雷分布,为:
(10)
因此参数可以理解为的有效观测数。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182917.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
