大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
启动和使用H2控制台
H2控制台应用程序允许您使用浏览器访问数据库。这可以是H2数据库,也可以是支持JDBC API的其他数据库。
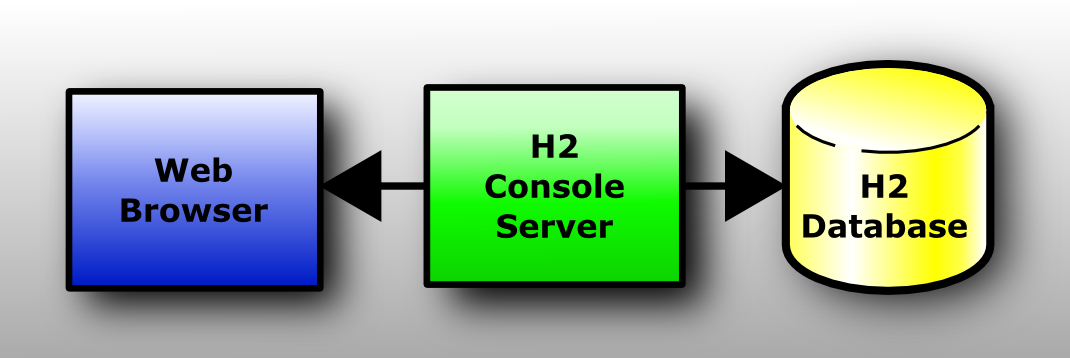

这是一个客户端/服务器应用程序,因此需要服务器和客户端(浏览器)来运行它。
根据您的平台和环境,有多种方法可以启动H2控制台:
| OS | 开始 |
|---|---|
| 视窗 | 单击[开始],[所有程序],[H2]和[H2控制台(命令行)] 系统托盘中将添加一个图标:  如果没有显示窗口和系统托盘图标,则可能是Java未正确安装(在这种情况下,请尝试其他方式启动应用程序)。应打开浏览器窗口并指向登录页面 http://localhost:8082。 |
| 视窗 | 打开文件浏览器,导航到h2/bin,然后双击h2.bat。出现一个控制台窗口。如果出现问题,您将在此窗口中看到错误消息。将打开一个浏览器窗口并指向登录页面(URL :) http://localhost:8082。 |
| 任何 | 双击该h2*.jar文件。这仅在.jar后缀与Java关联时才有效。 |
| 任何 | 打开控制台窗口,导航到该目录h2/bin,然后键入:
|
火墙
如果启动服务器,则可能会从防火墙收到安全警告(如果已安装)。如果您不希望网络中的其他计算机访问计算机上的应用程序,则可以让防火墙阻止这些连接。来自本地计算机的连接仍然有效。仅当您希望其他计算机访问此计算机上的数据库时,才需要在防火墙中允许远程连接。
据报道,当使用带有防火墙的卡巴斯基7.0时,H2控制台在通过IP地址连接时非常慢。解决方法是使用“localhost”进行连接。
服务器中已内置了一个小防火墙:默认情况下,其他计算机可能无法连接到服务器。要更改此设置,请转到“首选项”,然后选择“允许来自其他计算机的连接”。
测试Java
要找出安装了哪个版本的Java,请打开命令提示符并键入:
java -version
如果收到错误消息,则可能需要将Java二进制目录添加到路径环境变量中。
错误消息’端口可能正在使用’
您只能启动H2控制台的一个实例,否则您将收到以下错误消息:“无法启动Web服务器。可能的原因:另一台服务器已在运行……”。可以在同一台计算机上启动多个控制台应用程序(使用不同的端口),但这通常不需要,因为控制台支持多个并发连接。
使用另一个端口
如果H2控制台的默认端口已被其他应用程序使用,则需要配置其他端口。设置存储在属性文件中。有关详细信息,请参阅H2控制台的设置。相关条目是webPort。
如果没有为TCP和PG服务器指定端口,则每个服务将尝试侦听其默认端口。如果默认端口已在使用中,则使用随机端口。
使用浏览器连接到服务器
如果服务器成功启动,您可以使用Web浏览器连接到该服务器。需要启用Javascript。如果在与浏览器相同的计算机上启动服务器,请打开URL http://localhost:8082。如果要从另一台计算机连接到该应用程序,则需要提供服务器的IP地址,例如:http://192.168.0.2:8082。如果您在服务器端启用了TLS,则需要以URL开头https://。
多个并发会话
支持多个并发浏览器会话。由于数据库对象驻留在服务器上,因此并发工作量受服务器应用程序可用内存的限制。
登录
在登录页面,您需要提供连接信息以连接到数据库。设置数据库的JDBC驱动程序类,JDBC URL,用户名和密码。如果完成,请单击[连接]。
您可以保存并重复使用以前保存的设置。设置存储在属性文件中(请参阅H2控制台的设置)。
错误消息
错误消息显示为红色。您可以通过单击消息来显示/隐藏异常的堆栈跟踪。
添加数据驱动程序
要注册其他JDBC驱动程序(MySQL,PostgreSQL,HSQLDB,…),请将jar文件名添加到环境变量H2DRIVERS或CLASSPATH。示例(Windows):要添加HSQLDB JDBC驱动程序C:\Programs\hsqldb\lib\hsqldb.jar,请将环境变量设置H2DRIVERS为C:\Programs\hsqldb\lib\hsqldb.jar。
可以设置多个驱动程序; 条目需要由;(Windows)或:(其他操作系统)分隔。支持路径名中的空格。不得引用设置。
使用H2控制台
H2控制台应用程序有三个主要面板:顶部的工具栏,左侧的树和右侧的查询/结果面板。数据库对象(例如,表)列在左侧。在查询面板中键入SQL命令,然后单击[运行]。结果显示在命令下方。
插入表名称或列名称
要将表和列名称插入脚本,请单击树中的项目。如果在查询为空时单击表,则会SELECT * FROM ...添加。在键入查询时,使用的表在树中展开。例如,如果键入,SELECT * FROM TEST T WHERE T.则会扩展表TEST。
断开连接并停止应用程序
要注销数据库,请单击工具栏面板中的[断开连接]。但是,服务器仍在运行并准备接受新会话。
要停止服务器,请右键单击系统托盘图标,然后选择[退出]。如果您没有系统托盘图标,请导航至[首选项]并单击[关闭],在启动服务器的控制台中按[Ctrl] + [C](Windows),或关闭控制台窗口。
特殊H2控制台语法
H2控制台支持一些内置命令。这些在H2控制台中解释,因此它们适用于任何数据库。内置命令需要位于语句的开头(在任何备注之前),否则它们不会被正确解析。如果有疑问,请;在命令之前添加。
| 指令(S) | 描述 |
|---|---|
| @autocommit_true; @autocommit_false; |
启用或禁用自动提交。 |
| @cancel; | 取消当前运行的语句。 |
| @columns null null TEST; @index_info null null TEST; @tables; @tables null null TEST; |
调用相应的DatabaseMetaData.get方法。模式区分大小写(通常标识符为大写)。有关参数的信息,请参阅Javadoc文档。该行末尾缺少的参数设置为null。元数据命令的完整列表是: @attributes, @best_row_identifier, @catalogs, @columns, @column_privileges, @cross_references, @exported_keys, @imported_keys, @index_info, @primary_keys, @procedures, @procedure_columns, @schemas, @super_tables, @super_types, @tables, @table_privileges, @table_types, @type_info, @udts, @version_columns |
| @edit select * from test; | 使用可更新的结果集。 |
| @generated insert into test() values(); | 显示结果Statement.getGeneratedKeys()。 |
| @history; | 列出命令历史记录。 |
| @info; | 显示的各种的结果Connection和DatabaseMetaData方法。 |
| @list select * from test; | 以列表格式显示结果集(每行都有自己的行,带有行号)。 |
| @loop 1000 select ?, ?/*rnd*/; @loop 1000 @statement select ?; |
多次运行该语句。?使用从0到x-1的循环设置参数()?/*rnd*/。每个都使用随机值。如果使用Statement对象,则使用Statement对象代替PreparedStatement @statement。读取结果集直到ResultSet.next()返回false。打印时间信息。 |
| @maxrows 20; | 设置要显示的最大行数。 |
| @memory; | 显示已用和可用内存。这会打电话System.gc()。 |
| @meta select 1; | 列出ResultSetMetaData运行查询后。 |
| @parameter_meta select ?; | 显示PreparedStatement.getParameterMetaData()通话结果。该声明未执行。 |
| @prof_start; call hash(‘SHA256’, ”, 1000000); @prof_stop; |
启动/停止内置分析工具。列出了开始和停止之间语句的前3个堆栈跟踪(如果有3个)。 |
| @prof_start; @sleep 10; @prof_stop; |
睡几秒钟。用于分析在另一个会话中运行的长时间运行的查询或操作(但在同一进程中)。 |
| @transaction_isolation; @transaction_isolation 2; |
显示(不带参数)或更改(带参数1,2,4,8)事务隔离级别。 |
H2控制台的设置
H2控制台的设置存储在.h2.server.properties用户主目录中调用的配置文件中。对于Windows安装,用户主目录通常是C:\Documents and Settings\[username]或C:\Users\[username]。配置文件包含应用程序的设置,并在首次启动H2控制台时自动创建。支持的设置是:
webAllowOthers:允许其他计算机连接。webPort:H2控制台的端口webSSL:使用加密的TLS(HTTPS)连接。
除了这些设置之外,<number>=<name>|<driver>|<url>|<user>使用转义字符在表单中列出了最近最近使用的连接的属性\。例:1=Generic H2 (Embedded)|org.h2.Driver|jdbc\:h2\:~/test|sa
使用JDBC连接到数据库
要连接到数据库,Java应用程序首先需要加载数据库驱动程序,然后获取连接。一种简单的方法是使用以下代码:
import java.sql.*;
public class Test {
public static void main(String[] a)
throws Exception {
Connection conn = DriverManager.
getConnection("jdbc:h2:~/test", "sa", "");
// add application code here
conn.close();
}
}
此代码打开一个连接(使用DriverManager.getConnection())。驱动程序名称是"org.h2.Driver"。数据库URL始终需要jdbc:h2:从此数据库开始识别。getConnection()调用中的第二个参数是用户名(sa在本例中为系统管理员)。第三个参数是密码。在此数据库中,用户名不区分大小写,但密码是。
创建新数据库
默认情况下,如果URL中指定的数据库尚不存在,则会自动创建新的(空)数据库。创建数据库的用户自动成为此数据库的管理员。
可以禁用自动创建新数据库,请参阅仅在已存在的情况下打开数据库。
使用服务器
H2目前支持三个服务器:一个Web服务器(用于H2控制台),一个TCP服务器(用于客户端/服务器连接)和一个PG服务器(用于PostgreSQL客户端)。请注意,只有Web服务器支持浏览器连接。服务器可以以不同的方式启动,一个使用该Server工具。启动服务器不会打开数据库 – 只要客户端连接就会打开数据库。
从命令行启动服务器工具
要Server使用默认设置从命令行启动该工具,请运行:
java -cp h2*.jar org.h2.tools.Server
这将使用默认选项启动该工具。要获取选项列表和默认值,请运行:
java -cp h2*.jar org.h2.tools.Server -?
有可用的选项可以使用其他端口,并启动或不启动部件。
连接到TCP服务器
要使用TCP服务器远程连接到数据库,请使用以下驱动程序和数据库URL:
- JDBC驱动程序类:
org.h2.Driver - 数据库网址:
jdbc:h2:tcp://localhost/~/test
有关数据库URL的详细信息,另请参阅“功能”。请注意,您无法使用此网址连接到网络浏览器。您只能使用H2客户端(通过JDBC)进行连接。
在应用程序中启动TCP服务器
也可以在应用程序中启动和停止服务器。示例代码:
import org.h2.tools.Server;
...
// start the TCP Server
Server server = Server.createTcpServer(args).start();
...
// stop the TCP Server
server.stop();
从另一个进程停止TCP服务器
可以从另一个进程停止TCP服务器。要从命令行停止服务器,请运行:
java org.h2.tools.Server -tcpShutdown tcp://localhost:9092
要从用户应用程序停止服务器,请使用以下代码:
org.h2.tools.Server.shutdownTcpServer("tcp://localhost:9094");
此功能仅停止TCP服务器。如果在同一进程中启动了其他服务器,它们将继续运行。为避免在下次打开数据库时进行恢复,应在调用此方法之前关闭与数据库的所有连接。要停止远程服务器,必须在服务器上启用远程连接。可以使用该选项保护关闭TCP服务器-tcpPassword(必须使用相同的密码来启动和停止TCP服务器)。
使用Hibernate
此数据库支持Hibernate 3.1及更高版本。您可以使用HSQLDB Dialect或本机H2方言。
使用Hibernate时,尽量使用H2Dialect。使用时H2Dialect,兼容模式如MODE=MySQL不受支持。使用这种兼容模式时,请使用Hibernate方言代替相应的数据库H2Dialect; 但请注意H2不支持所有数据库的所有功能。
使用TopLink和Glassfish
要将Glass与Glassfish(或Sun AS)一起使用,请将数据源类名设置为org.h2.jdbcx.JdbcDataSource。您可以在GUI中的Application Server – Resources – JDBC – Connection Pools中设置它,或者通过编辑文件sun-resources.xml:at element jdbc-connection-pool,将属性设置datasource-classname为org.h2.jdbcx.JdbcDataSource。
H2数据库与HSQLDB和PostgreSQL兼容。要利用H2特定功能,请使用H2Platform。该平台的源代码包含在H2中src/tools/oracle/toplink/essentials/platform/database/DatabasePlatform.java.txt。您需要将此文件复制到您的应用程序,并将其重命名为.java。要启用它,请在persistence.xml中更改以下设置:
<property
name="toplink.target-database"
value="oracle.toplink.essentials.platform.database.H2Platform"/>
在旧版本的Glassfish中,属性名称为toplink.platform.class.name。
要在Glassfish中使用H2,请将h2 * .jar复制到该目录glassfish/glassfish/lib。
使用EclipseLink
要在EclipseLink中使用H2,请使用平台类org.eclipse.persistence.platform.database.H2Platform。如果您的EclipseLink版本中没有此平台,则可以在许多情况下使用Oracle平台。另见H2Platform。
使用Apache ActiveMQ
使用H2作为Apache ActiveMQ的后端数据库时,请使用TransactDatabaseLocker而不是默认的锁定机制。否则,数据库文件将无限增长。问题是默认锁定机制使用未提交的UPDATE事务,这使事务日志不会缩小(导致数据库文件增长)。而不是使用的UPDATE说法,TransactDatabaseLocker用途SELECT ... FOR UPDATE这是没有问题的。要使用它,请更改ApacheMQ配置元素<jdbcPersistenceAdapter>element属性databaseLocker="org.apache.activemq.store.jdbc.adapter.TransactDatabaseLocker"。但是,使用MVCC模式将再次导致相同的问题。因此,在这种情况下请不要使用MVCC模式。另一个(更危险的)解决方案是设置useDatabaseLock为false。
在NetBeans中使用H2
使用Netbeans SQL执行窗口时存在一个已知问题:在执行查询之前,SELECT COUNT(*) FROM <query>运行表单中的另一个查询。对于修改状态的查询,这是一个问题,例如SELECT SEQ.NEXTVAL。在这种情况下,分配两个序列值而不是一个。
使用H2和jOOQ
jOOQ在JDBC之上添加了一个薄层,允许类型安全的SQL构造,包括高级SQL,存储过程和高级数据类型。jOOQ将您的数据库模式作为代码生成的基础。如果这是您的示例架构:
CREATE TABLE USER (ID INT, NAME VARCHAR(50));
然后使用以下命令在命令行上运行jOOQ代码生成器:
java -cp jooq.jar;jooq-meta.jar;jooq-codegen.jar;h2-1.3.158.jar;.
org.jooq.util.GenerationTool /codegen.xml
…在codegen.xml类路径中的位置并包含此信息
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<configuration xmlns="http://www.jooq.org/xsd/jooq-codegen-2.3.0.xsd">
<jdbc>
<driver>org.h2.Driver</driver>
<url>jdbc:h2:~/test</url>
<user>sa</user>
<password></password>
</jdbc>
<generator>
<name>org.jooq.util.DefaultGenerator</name>
<database>
<name>org.jooq.util.h2.H2Database</name>
<includes>.*</includes>
<excludes></excludes>
<inputSchema>PUBLIC</inputSchema>
</database>
<generate></generate>
<target>
<packageName>org.jooq.h2.generated</packageName>
<directory>./src</directory>
</target>
</generator>
</configuration>
使用生成的源,您可以按如下方式查询数据库:
Factory create = new H2Factory(connection);
Result<UserRecord> result =
create.selectFrom(USER)
.where(NAME.like("Johnny%"))
.orderBy(ID)
.fetch();
在Web应用程序中使用数据库
有多种方法可以从Web应用程序中访问数据库。以下是使用Tomcat或JBoss的一些示例。
嵌入模式
(当前)最简单的解决方案是在嵌入模式下使用数据库,这意味着在应用程序启动时打开一个连接(一个好的解决方案是使用Servlet侦听器,见下文),或者在会话启动时。只要数据库在同一进程中运行,就可以同时从多个会话和应用程序访问数据库。大多数Servlet容器(例如Tomcat)只使用一个进程,因此这不是问题(除非您在群集模式下运行Tomcat)。Tomcat使用多个线程和多个类加载器。如果多个应用程序同时访问同一个数据库,则需要将数据库jar放在shared/lib或中server/lib目录。最好在Web应用程序启动时打开数据库,并在Web应用程序停止时关闭它。如果使用多个应用程序,则只需要其中一个(任何)应用程序。在应用程序中,一个想法是每个Session使用一个连接,甚至每个请求使用一个连接(action)。如果可能的话,这些连接应在使用后关闭(但如果它们没有关闭则不会那么糟糕)。
服务器模式
服务器模式类似,但它允许您在另一个进程中运行服务器。
使用Servlet侦听器启动和停止数据库
将h2 * .jar文件添加到Web应用程序,并将以下代码段添加到您的web.xml文件中(在context-param该filter部分之间):
<listener>
<listener-class>org.h2.server.web.DbStarter</listener-class>
</listener>
有关如何访问数据库的详细信息,请参阅该文件DbStarter.java。默认情况下,此工具使用数据库URL jdbc:h2:~/test,用户名sa和密码打开嵌入式连接sa。如果要在servlet中使用此连接,可以按如下方式访问:
Connection conn = getServletContext().getAttribute("connection");
DbStarter 也可以启动TCP服务器,但默认情况下禁用此功能。要启用它,请使用db.tcpServer文件中的参数web.xml。这是完整的选项列表。这些选项需要放在description标记和listener/ filter标记之间:
<context-param>
<param-name>db.url</param-name>
<param-value>jdbc:h2:~/test</param-value>
</context-param>
<context-param>
<param-name>db.user</param-name>
<param-value>sa</param-value>
</context-param>
<context-param>
<param-name>db.password</param-name>
<param-value>sa</param-value>
</context-param>
<context-param>
<param-name>db.tcpServer</param-name>
<param-value>-tcpAllowOthers</param-value>
</context-param>
停止Web应用程序时,将自动关闭数据库连接。如果TCP服务器在其中启动DbStarter,它也将自动停止。
使用H2控制台Servlet
H2控制台是一个独立的应用程序,包含自己的Web服务器,但它也可以用作servlet。为此,请h2*.jar在应用程序中包含该文件,并将以下配置添加到web.xml:
<servlet>
<servlet-name>H2Console</servlet-name>
<servlet-class>org.h2.server.web.WebServlet</servlet-class>
<!--
<init-param>
<param-name>webAllowOthers</param-name>
<param-value></param-value>
</init-param>
<init-param>
<param-name>trace</param-name>
<param-value></param-value>
</init-param>
-->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>H2Console</servlet-name>
<url-pattern>/console/*</url-pattern>
</servlet-mapping>
有关详细信息,请参阅src/tools/WEB-INF/web.xml。
要仅使用H2控制台创建Web应用程序,请运行以下命令:
build warConsole
Android的
您可以在Android设备上使用此数据库(使用Dalvik VM),而不是SQLite。到目前为止,只运行了很少的测试和基准测试,但似乎性能类似于SQLite,除了打开和关闭数据库,在H2中尚未优化(H2大约0.2秒,SQLite大约0.02秒) 。读操作似乎比SQLite快一点,写操作似乎更慢。到目前为止,只运行了很少的测试,一切似乎都按预期工作。全文搜索尚未经过测试,但原生全文搜索应该有效。
使用H2而不是SQLite的原因是:
- 完整的Unicode支持,包括UPPER()和LOWER()。
- BLOB和CLOB数据的流式API。
- 全文搜索。
- 多个连接。
- 用户定义的函数和触发器。
- 数据库文件加密。
- 读取和写入CSV文件(此功能也可以在数据库外部使用)。
- 参照完整性和检查约束。
- 更好的数据类型和SQL支持。
- 内存数据库,只读数据库,链接表。
- 与其他数据库更好地兼容,简化了移植应用程序。
- 可能性能更好(到目前为止读取操作)。
- 服务器模式(通过TCP / IP访问不同计算机上的数据库)。
目前只支持JDBC API(计划在将来的版本中支持Android数据库API)。可以使用常规H2 jar文件和较小的文件h2small-*.jar。要创建较小的jar文件,请运行命令./build.sh jarSmall(Linux / Mac OS)或build.bat jarSmall(Windows)。
数据库文件需要存储在应用程序可访问的位置。例:
String url = "jdbc:h2:/data/data/" +
"com.example.hello" +
"/data/hello" +
";FILE_LOCK=FS" +
";PAGE_SIZE=1024" +
";CACHE_SIZE=8192";
conn = DriverManager.getConnection(url);
...
限制:目前不支持使用连接池,因为javax.sql.Android上不提供所需的类。
CSV(逗号分隔值)支持
CSV文件支持可以在数据库内使用功能一起使用CSVREAD并且CSVWRITE,也可以在数据库之外被用作一个独立的工具。
从数据库中读取CSV文件
可以使用该功能读取CSV文件CSVREAD。例:
SELECT * FROM CSVREAD('test.csv');
请注意出于性能原因,CSVREAD不应在连接内使用。而是首先导入数据(可能导入临时表),必要时创建所需的索引,然后查询此表。
从CSV文件导入数据
从CSV文件加载或导入数据(有时称为“批量加载”)的快速方法是将表创建与导入相结合。(可选)在创建表时可以设置列名和数据类型。另一种选择是使用INSERT INTO ... SELECT。
CREATE TABLE TEST AS SELECT * FROM CSVREAD('test.csv');
CREATE TABLE TEST(ID INT PRIMARY KEY, NAME VARCHAR(255))
AS SELECT * FROM CSVREAD('test.csv');
从数据库中编写CSV文件
内置函数CSVWRITE可用于从查询创建CSV文件。例:
CREATE TABLE TEST(ID INT, NAME VARCHAR);
INSERT INTO TEST VALUES(1, 'Hello'), (2, 'World');
CALL CSVWRITE('test.csv', 'SELECT * FROM TEST');
从Java应用程序编写CSV文件
Csv即使不使用数据库,该工具也可以在Java应用程序中使用。例:
import java.sql.*;
import org.h2.tools.Csv;
import org.h2.tools.SimpleResultSet;
public class TestCsv {
public static void main(String[] args) throws Exception {
SimpleResultSet rs = new SimpleResultSet();
rs.addColumn("NAME", Types.VARCHAR, 255, 0);
rs.addColumn("EMAIL", Types.VARCHAR, 255, 0);
rs.addRow("Bob Meier", "bob.meier@abcde.abc");
rs.addRow("John Jones", "john.jones@abcde.abc");
new Csv().write("data/test.csv", rs, null);
}
}
从Java应用程序读取CSV文件
无需打开数据库即可读取CSV文件。例:
import java.sql.*;
import org.h2.tools.Csv;
public class TestCsv {
public static void main(String[] args) throws Exception {
ResultSet rs = new Csv().read("data/test.csv", null, null);
ResultSetMetaData meta = rs.getMetaData();
while (rs.next()) {
for (int i = 0; i < meta.getColumnCount(); i++) {
System.out.println(
meta.getColumnLabel(i + 1) + ": " +
rs.getString(i + 1));
}
System.out.println();
}
rs.close();
}
}
升级,备份和还原
数据库升级
从一个版本的数据库引擎升级到下一个版本的推荐方法是使用旧引擎创建数据库备份(以SQL脚本的形式),然后使用新引擎执行SQL脚本。
使用脚本工具备份
备份数据库的推荐方法是创建压缩的SQL脚本文件。这将导致一个小的,人类可读的,与数据库版本无关的备份。创建脚本还将验证数据库文件的校验和。该Script工具运行如下:
java org.h2.tools.Script -url jdbc:h2:~/test -user sa -script test.zip -options compression zip
也可以使用SQL命令SCRIPT创建数据库的备份。有关这些选项的更多信息,请参阅SQL命令SCRIPT。备份可以远程完成,但是文件将在服务器端创建。内置的FTP服务器可用于从服务器检索文件。
从脚本还原
要从SQL脚本文件还原数据库,可以使用该RunScript工具:
java org.h2.tools.RunScript -url jdbc:h2:~/test -user sa -script test.zip -options compression zip
有关这些选项的更多信息,请参阅SQL命令RUNSCRIPT。还原可以远程完成,但文件需要位于服务器端。内置的FTP服务器可用于将文件复制到服务器。也可以使用SQL命令RUNSCRIPT执行SQL脚本。SQL脚本文件可以以RUNSCRIPT命令的形式包含对其他脚本文件的引用。但是,使用服务器模式时,需要在服务器端提供引用脚本文件。
在线备份
该BACKUPSQL语句和Backup工具都创建的数据库文件的zip文件。但是,此文件的内容不是人类可读的。
生成的备份在事务上是一致的,这意味着一致性和原子性规则适用。
BACKUP TO 'backup.zip'
该Backup工具(org.h2.tools.Backup)不能用于创建一个在线备份; 运行此程序时,不得使用该数据库。
不支持在数据库运行时通过复制数据库文件来创建备份,除非文件系统支持创建快照。对于其他文件系统,无法保证以正确的顺序复制数据。
命令行工具
该数据库附带了许多命令行工具。要获得有关工具的更多信息,请使用参数’ – ?’启动它,例如:
java -cp h2*.jar org.h2.tools.Backup -?
命令行工具是:
Backup创建数据库的备份。ChangeFileEncryption允许更改文件加密密码或数据库的算法。Console启动基于浏览器的H2控制台。ConvertTraceFile将.trace.db文件转换为Java应用程序和SQL脚本。CreateCluster从独立数据库创建集群。DeleteDbFiles删除属于数据库的所有文件。Recover帮助恢复损坏的数据库。Restore恢复数据库的备份。RunScript针对数据库运行SQL脚本。Script允许将数据库转换为SQL脚本以进行备份或迁移。Server用于服务器模式以启动H2服务器。Shell是一个命令行数据库工具。
也可以通过调用main或其他公共方法从应用程序调用这些工具。有关详细信息,请参阅Javadoc文档。
壳牌工具
Shell工具是一个简单的交互式命令行工具。要启动它,请键入:
java -cp h2*.jar org.h2.tools.Shell
系统将要求您提供数据库URL,JDBC驱动程序,用户名和密码。连接设置也可以设置为命令行参数。连接后,您将获得选项列表。内置命令不需要以分号结尾,但只有当行以分号结尾时才执行SQL语句;。这允许输入多行语句:
sql> select * from test
...> where id = 0;
默认情况下,结果将打印为表格。对于包含许多列的结果,请考虑使用列表模式:
sql> list
Result list mode is now on
sql> select * from test;
ID : 1
NAME: Hello
ID : 2
NAME: World
(2 rows, 0 ms)
使用OpenOffice Base
OpenOffice.org Base支持通过JDBC API进行数据库访问。要使用OpenOffice Base连接到H2数据库,首先需要将JDBC驱动程序添加到OpenOffice。连接H2数据库的步骤如下:
- 启动OpenOffice Writer,转到[工具],[选项]
- 确保在OpenOffice.org / Java中选择了Java运行时环境
- 单击[类路径…],[添加存档…]
- 选择你的h2 jar文件(位置取决于你,可以在你选择的任何地方)
- 单击[确定](根据需要),停止OpenOffice(包括Quickstarter)
- 启动OpenOffice Base
- 连接到现有数据库; 选择[JDBC]; [下一个]
- 示例数据源URL:
jdbc:h2:~/test - JDBC驱动程序类:
org.h2.Driver
现在您可以访问存储在当前用户主目录中的数据库。
在NeoOffice中使用H2(不带X11的OpenOffice):
- 在NeoOffice中,转到[NeoOffice],[首选项]
- 在[NeoOffice],[Java]下查找页面
- 单击[类路径],[添加存档…]
- 选择你的h2 jar文件(位置取决于你,可以在你选择的任何地方)
- 单击[确定](根据需要),重新启动NeoOffice。
现在,使用“数据库向导”创建新数据库时:
- 单击[文件],[新建],[数据库]。
- 选择[连接到现有数据库],然后选择[JDBC]。点击下一步。
- 示例数据源URL:
jdbc:h2:~/test - JDBC驱动程序类:
org.h2.Driver
在NeoOffice中使用H2的另一个解决方案是:
- 将h2 jar打包在扩展包中
- 在NeoOffice中将其安装为Java扩展
这可以通过使用NetBeans OpenOffice插件创建它来完成。另请参阅扩展开发。
Java Web Start / JNLP
使用Java Web Start / JNLP(Java网络启动协议)时,必须在.jnlp文件中设置权限标记,并且必须对应用程序.jar文件进行签名。否则,在尝试写入文件系统时,将发生以下异常java.security.AccessControlException:: access denied(java.io.FilePermission ... read)。示例权限标记:
<security>
<all-permissions/>
</security>
使用连接池
对于H2,如果数据库已经打开,则打开连接很快。尽管如此,如果您经常打开和关闭连接,使用连接池可以提高性能。H2中包含一个简单的连接池。它基于Christian d’Heureuse 的Mini Connection Pool Manager。还有其他更复杂的开源连接池,例如Apache Commons DBCP。对于H2,从内置连接池获取连接的速度比获取连接池快两倍DriverManager.getConnection()。内置连接池使用如下:
import java.sql.*;
import org.h2.jdbcx.JdbcConnectionPool;
public class Test {
public static void main(String[] args) throws Exception {
JdbcConnectionPool cp = JdbcConnectionPool.create(
"jdbc:h2:~/test", "sa", "sa");
for (int i = 0; i < args.length; i++) {
Connection conn = cp.getConnection();
conn.createStatement().execute(args[i]);
conn.close();
}
cp.dispose();
}
}
全文检索
H2包括两个全文搜索实现。一个是使用Apache Lucene,另一个(本机实现)将索引数据存储在数据库的特殊表中。
使用本机全文搜索
要初始化,请致电:
CREATE ALIAS IF NOT EXISTS FT_INIT FOR "org.h2.fulltext.FullText.init";
CALL FT_INIT();
您需要在要使用它的每个数据库中初始化它。之后,您可以使用以下方法为表创建全文索引:
CREATE TABLE TEST(ID INT PRIMARY KEY, NAME VARCHAR);
INSERT INTO TEST VALUES(1, 'Hello World');
CALL FT_CREATE_INDEX('PUBLIC', 'TEST', NULL);
PUBLIC是模式名称,TEST是表名。列名列表(逗号分隔)是可选的,在这种情况下,所有列都被索引。索引实时更新。要搜索索引,请使用以下查询:
SELECT * FROM FT_SEARCH('Hello', 0, 0);
这将生成一个结果集,其中包含检索数据所需的查询:
QUERY: "PUBLIC"."TEST" WHERE "ID"=1
要删除表上的索引:
CALL FT_DROP_INDEX('PUBLIC', 'TEST');
要获取原始数据,请使用FT_SEARCH_DATA('Hello', 0, 0);。结果包含列SCHEMA(模式名称),TABLE(表名称),COLUMNS(列名称数组)和KEYS(对象数组)。要加入表,请使用连接,如下所示:SELECT T.* FROM FT_SEARCH_DATA('Hello', 0, 0) FT, TEST T WHERE FT.TABLE='TEST' AND T.ID=FT.KEYS[0];
您还可以在Java应用程序中调用索引:
org.h2.fulltext.FullText.search(conn, text, limit, offset);
org.h2.fulltext.FullText.searchData(conn, text, limit, offset);
使用Apache Lucene全文搜索
要使用Apache Lucene全文搜索,您需要在类路径中使用Lucene库。目前,Apache Lucene 3.6.2用于测试。较新版本可能有效,但未经过测试。怎么做取决于应用程序; 如果使用H2控制台,则可以将Lucene jar文件添加到环境变量H2DRIVERS或CLASSPATH。要在数据库中初始化Lucene全文搜索,请调用:
CREATE ALIAS IF NOT EXISTS FTL_INIT FOR "org.h2.fulltext.FullTextLucene.init";
CALL FTL_INIT();
您需要在要使用它的每个数据库中初始化它。之后,您可以使用以下方法为表创建全文索引:
CREATE TABLE TEST(ID INT PRIMARY KEY, NAME VARCHAR);
INSERT INTO TEST VALUES(1, 'Hello World');
CALL FTL_CREATE_INDEX('PUBLIC', 'TEST', NULL);
PUBLIC是模式名称,TEST是表名。列名列表(逗号分隔)是可选的,在这种情况下,所有列都被索引。索引实时更新。要搜索索引,请使用以下查询:
SELECT * FROM FTL_SEARCH('Hello', 0, 0);
这将生成一个结果集,其中包含检索数据所需的查询:
QUERY: "PUBLIC"."TEST" WHERE "ID"=1
删除表上的索引(警告这将重新索引整个数据库的所有全文索引):
CALL FTL_DROP_INDEX('PUBLIC', 'TEST');
要获取原始数据,请使用FTL_SEARCH_DATA('Hello', 0, 0);。结果包含列SCHEMA(模式名称),TABLE(表名称),COLUMNS(列名称数组)和KEYS(对象数组)。要加入表,请使用连接,如下所示:SELECT T.* FROM FTL_SEARCH_DATA('Hello', 0, 0) FT, TEST T WHERE FT.TABLE='TEST' AND T.ID=FT.KEYS[0];
您还可以在Java应用程序中调用索引:
org.h2.fulltext.FullTextLucene.search(conn, text, limit, offset);
org.h2.fulltext.FullTextLucene.searchData(conn, text, limit, offset);
Lucene全文搜索仅支持在特定列中搜索。列名必须为大写(除非原始列是双引号)。对于以下划线(_)开头的列名,需要添加另一个下划线。例:
CREATE ALIAS IF NOT EXISTS FTL_INIT FOR "org.h2.fulltext.FullTextLucene.init";
CALL FTL_INIT();
DROP TABLE IF EXISTS TEST;
CREATE TABLE TEST(ID INT PRIMARY KEY, FIRST_NAME VARCHAR, LAST_NAME VARCHAR);
CALL FTL_CREATE_INDEX('PUBLIC', 'TEST', NULL);
INSERT INTO TEST VALUES(1, 'John', 'Wayne');
INSERT INTO TEST VALUES(2, 'Elton', 'John');
SELECT * FROM FTL_SEARCH_DATA('John', 0, 0);
SELECT * FROM FTL_SEARCH_DATA('LAST_NAME:John', 0, 0);
CALL FTL_DROP_ALL();
用户定义的变量
该数据库支持用户定义的变量。变量以@允许表达式或参数的任何地方开始并且可以使用。变量不会持久化并且会话作用域,这意味着只能从定义它们的会话中看到变量。通常使用SET命令分配值:
SET @USER = 'Joe';
也可以使用SET()方法更改该值。这在查询中很有用:
SET @TOTAL = NULL;
SELECT X, SET(@TOTAL, IFNULL(@TOTAL, 1.) * X) F FROM SYSTEM_RANGE(1, 50);
未设置的变量评估为NULL。用户定义变量的数据类型是分配给它的值的数据类型,这意味着在使用变量名之前不必(或可能)声明变量名。对指定值没有限制; 也支持大对象(LOB)。回滚事务不会影响用户定义变量的值。
日期和时间
日期,时间和时间戳值支持ISO 8601格式,包括时区:
CALL TIMESTAMP '2008-01-01 12:00:00+01:00';
如果未设置时区,则使用系统的当前时区设置解析该值。日期和时间信息存储在H2数据库文件中,根据使用的数据类型,有或没有时区信息。
- 使用TIMESTAMP数据类型如果使用其他系统时区打开数据库,则日期和时间将相同。这意味着如果您在一个时区存储值’2000-01-01 12:00:00’,然后关闭数据库并在另一个时区再次打开数据库,您也将获得’2000-01-01 12 :00:00′ 。请注意,不支持在加载H2驱动程序后更改时区。
- 使用TIMESTAMP WITH TIME ZONE数据类型时区偏移量存储,如果存储值’2008-01-01 12:00:00 + 01:00’,即使关闭并以不同的时间重新打开数据库,它也保持不变区。如果您使用指定的时区名称存储值,例如’2008-01-01 12:00:00 Europe / Berlin’,则此名称将转换为时区偏移量。不存储时区的名称。
使用Spring
使用TCP服务器
使用以下配置使用Spring Framework启动和停止H2 TCP服务器:
<bean id = "org.h2.tools.Server"
class="org.h2.tools.Server"
factory-method="createTcpServer"
init-method="start"
destroy-method="stop">
<constructor-arg value="-tcp,-tcpAllowOthers,-tcpPort,8043" />
</bean>
这destroy-method将有助于防止热重新部署或重新启动服务器时出现异常。
OSGi的
标准H2罐可以作为一个捆绑在OSGi容器中。H2实现OSGi Service Platform Release 4 V4.2企业规范中定义的JDBC服务。H2数据源工厂服务已注册以下属性:OSGI_JDBC_DRIVER_CLASS=org.h2.Driver和OSGI_JDBC_DRIVER_NAME=H2 JDBC Driver。该OSGI_JDBC_DRIVER_VERSION属性反映了驱动程序的版本。
支持以下标准配置属性:JDBC_USER, JDBC_PASSWORD, JDBC_DESCRIPTION, JDBC_DATASOURCE_NAME, JDBC_NETWORK_PROTOCOL, JDBC_URL, JDBC_SERVER_NAME, JDBC_PORT_NUMBER。任何其他标准财产将被拒绝。非标准属性将在连接URL中传递给H2。
Java管理扩展(JMX)
支持JMX管理,但默认情况下不启用。要启用JMX,请;JMX=TRUE在打开数据库时附加到数据库URL。各种工具都支持JMX,其中一个就是这样的工具jconsole。打开时jconsole,连接到打开数据库的进程(使用服务器模式时,需要连接到服务器进程)。然后转到该MBeans部分。在org.h2你会发现每个数据库都有一个条目。条目的对象名称是数据库短名称,加上路径(每个冒号都用下划线字符替换)。
支持以下属性和操作:
CacheSize:当前使用的缓存大小(KB)。CacheSizeMax(读/写):以KB为单位的最大高速缓存大小。Exclusive:此数据库是否以独占模式打开。FileReadCount:自数据库打开以来的文件读取操作数。FileSize:文件大小(KB)。FileWriteCount:自数据库打开以来的文件写入操作数。FileWriteCountTotal:自创建数据库以来的文件写入操作数。LogMode(读/写):当前的事务日志模式。详情SET LOG请见。Mode:兼容模式(REGULAR如果不使用兼容模式)。MultiThreaded:如果启用了多线程,则为true。Mvcc:如果MVCC已启用,则为true 。ReadOnly:如果数据库是只读的,则为true。TraceLevel(读/写):文件跟踪级别。Version:正在使用的数据库版本。listSettings:列出数据库设置。listSessions:列出打开的会话,包括当前正在执行的语句(如果有)和锁定的表(如果有)。
要启用JMX,你可能需要设置系统属性com.sun.management.jmxremote和com.sun.management.jmxremote.port所要求的JVM。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182854.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
