大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
看了许多GBDT构建特征的资料整理而成,具体资料见Reference。
文章目录
1. 背景
1.1 Gradient Boosting
Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。损失函数是评价模型性能(一般为拟合程度+正则项),认为损失函数越小,性能越好。而让损失函数持续下降,就能使得模型不断改性提升性能,其最好的方法就是使损失函数沿着梯度方向下降(讲道理梯度方向上下降最快)。
Gradient Boost是一个框架,里面可以套入很多不同的算法。
1.2 Gradient Boosting Decision Tree
每一次建立树模型是在之前建立模型损失函数的梯度下降方向。即利用了损失函数的负梯度在当前模型的值作为回归问题提升树算法的残差近似值,去拟合一个回归树。
具体算法算理:GBDT原理-Gradient Boosting Decision Tree
1.3 GBDT应用-回归和分类
GBDT分类:每一颗树拟合当前整个模型的损失函数的负梯度,构建新的树加到当前模型中形成新模型,下一棵树拟合新模型的损失函数的负梯度。下面是其在Python的sklearn包下简单调用方法。
from sklearn import ensemble
clf = ensemble.GradientBoostingClassifier()
gbdt_model = clf.fit(X_train, y_train) # Training model
predicty_x = gbdt_model.predict_proba(test1217_x)[:, 1] # predict: probablity of 1
# 包含的参数
# loss = loss, learning_rate = learning_rate, n_estimators = n_estimators,
# min_samples_split = min_samples_split,
# min_samples_leaf = min_samples_leaf,
# min_weight_fraction_leaf = min_weight_fraction_leaf,
# max_depth = max_depth, init = init, subsample = subsample,
# max_features = max_features,
# random_state = random_state, verbose = verbose,
# max_leaf_nodes = max_leaf_nodes, warm_start = warm_start,
# presort = presort
GBDT回归:每一颗树拟合当前整个模型的残差,构建新的树加到当前模型中形成新模型,下一棵树拟合新模型的损失函数的负梯度。
from sklearn import ensemble
clf = ensemble.GradientBoostingRegressor()
gbdt_model = clf.fit(X_train, y_train) # Training model
y_upper = gbdt_model.predict(x_test) # predict
# 包含的参数和上面一致。
GBDT调参问题:sklearn中GBDT调参
GBDT运用的正则化技巧,防止模型过于复杂,参考这篇文章GBDT运用的正则化技巧
2. GBDT构建新的特征思想
特征决定模型性能上界,例如深度学习方法也是将数据如何更好的表达为特征。如果能够将数据表达成为线性可分的数据,那么使用简单的线性模型就可以取得很好的效果。GBDT构建新的特征也是使特征更好地表达数据。
主要参考Facebook[1],原文提升效果:
在预测Facebook广告点击中,使用一种将决策树与逻辑回归结合在一起的模型,其优于其他方法,超过3%。
主要思想:GBDT每棵树的路径直接作为LR输入特征使用。
用已有特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,最后把这些新特征加入原有特征一起训练模型。构造的新特征向量是取值0/1的,向量的每个元素对应于GBDT模型中树的叶子结点。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于GBDT模型里所有树包含的叶子结点数之和。
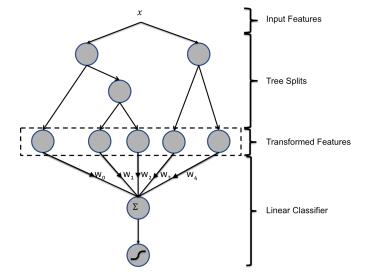

上图为混合模型结构。输入特征通过增强的决策树进行转换。 每个单独树的输出被视为稀疏线性分类器的分类输入特征。 增强的决策树被证明是非常强大的特征转换。
例子1:上图有两棵树,左树有三个叶子节点,右树有两个叶子节点,最终的特征即为五维的向量。对于输入x,假设他落在左树第一个节点,编码[1,0,0],落在右树第二个节点则编码[0,1],所以整体的编码为[1,0,0,0,1],这类编码作为特征,输入到线性分类模型(LR or FM)中进行分类。
论文中GBDT的参数,树的数量最多500颗(500以上就没有提升了),每棵树的节点不多于12。
3. GBDT与LR融合方案
在CTR预估中,如何利用AD ID是一个问题。
直接将AD ID作为特征建树不可行,而onehot编码过于稀疏,为每个AD ID建GBDT树,相当于发掘出区分每个广告的特征。而对于曝光不充分的样本即长尾部分,无法单独建树。
综合方案为:使用GBDT对非ID和ID分别建一类树。
-
非ID类树:
不以细粒度的ID建树,此类树作为base,即这些ID一起构建GBDT。即便曝光少的广告、广告主,仍可以通过此类树得到有区分性的特征、特征组合。
-
ID类树:
以细粒度 的ID建一类树(每个ID构建GBDT),用于发现曝光充分的ID对应有区分性的特征、特征组合。如何根据GBDT建的两类树,对原始特征进行映射?以如下图3为例,当一条样本x进来之后,遍历两类树到叶子节点,得到的特征作为LR的输入。当AD曝光不充分不足以训练树时,其它树恰好作为补充。
方案如图:
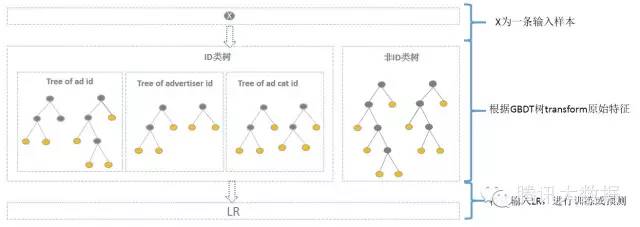
其中kaggle竞赛一般树的数目最多为30,通过GBDT转换得到特征空间相比于原始ID低了很多。
4. 源码内容
具体kaggle-2014-criteo实现的GitHub源码:https://github.com/guestwalk/kaggle-2014-criteo
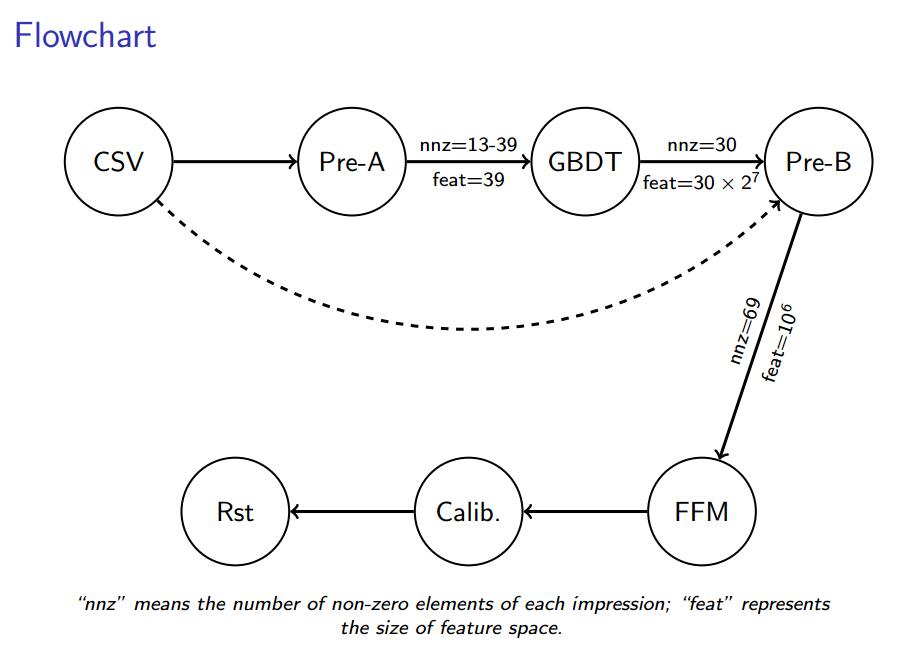
generate GBDT features:
- 使用GBDT生成特征。
- 使用了30颗深度为7的树。
- 一共生成30个特征。
- 基于下面的算法:http://statweb.stanford.edu/~jhf/ftp/trebst.pdf
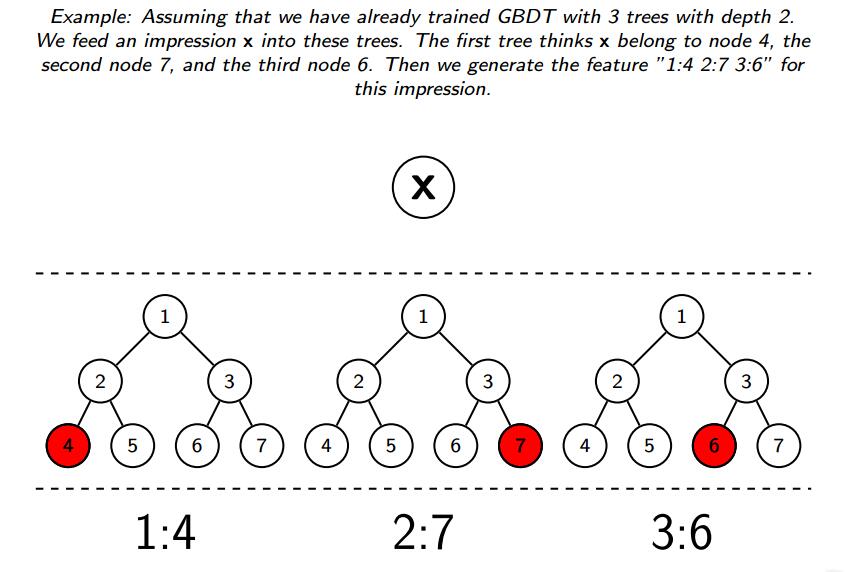
例子2:下图假设训练了3颗深度2的树模型,对于输入X,在第1个树属于节点4,在第2个树属于节点7,第3颗树属于节点6,所以生成的特征为”1:4 2:7 3:6”
generate features for FFM
-
数值型特征:进行变换: v ← ⌊ l o g ( v ) 2 ⌋ v \leftarrow \lfloor log(v)^2 \rfloor v←⌊log(v)2⌋
-
类别特征:出现小于10的类转换到一个特殊的value,即合为一种。
-
GBDT特征直接使用。
-
使用hashing trick将三类特征映射到1M-dimensionl。
5. Python实现
上面的源码用到了多线程实现,Python的sklearn库中提供了该方法,下面简单的实践:
首先要明确使用libFFM还是逻辑回归,两者不同之处在于:
libFFM适用于例子2的情况,即只用使用每棵树的index。
逻辑回归适用于例子1的情况,须将节点使用one-hot编码,核心代码如下:其中关键方法为树模型(GBDT)的apply()方法。
# 弱分类器的数目
n_estimator = 10
# 随机生成分类数据。
X, y = make_classification(n_samples=80000)
# 切分为测试集和训练集,比例0.5
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
# 将训练集切分为两部分,一部分用于训练GBDT模型,另一部分输入到训练好的GBDT模型生成GBDT特征,然后作为LR的特征。这样分成两部分是为了防止过拟合。
X_train, X_train_lr, y_train, y_train_lr = train_test_split(X_train, y_train, test_size=0.5)
# 调用GBDT分类模型。
grd = GradientBoostingClassifier(n_estimators=n_estimator)
# 调用one-hot编码。
grd_enc = OneHotEncoder()
# 调用LR分类模型。
grd_lm = LogisticRegression()
'''使用X_train训练GBDT模型,后面用此模型构造特征'''
grd.fit(X_train, y_train)
# fit one-hot编码器
grd_enc.fit(grd.apply(X_train)[:, :, 0])
''' 使用训练好的GBDT模型构建特征,然后将特征经过one-hot编码作为新的特征输入到LR模型训练。 '''
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)
# 用训练好的LR模型多X_test做预测
y_pred_grd_lm = grd_lm.predict_proba(grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]
# 根据预测结果输出
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)
这只是一个简单的demo,具体参数还需要根据具体业务情景调整。
官方例子介绍:http://scikit-learn.org/stable/auto_examples/ensemble/plot_feature_transformation.html#example-ensemble-plot-feature-transformation-py
总结
对于样本量大的数据,线性模型具有训练速度快的特点,但线性模型学习能力限于线性可分数据,所以就需要特征工程将数据尽可能地从输入空间转换到线性可分的特征空间。GBDT与LR的融合模型,其实使用GBDT来发掘有区分度的特征以及组合特征,来替代人工组合特征。工业种GBDT+LR、GBDT+FM都是应用比较广泛。
csdn原文:http://blog.csdn.net/shine19930820/article/details/71713680
关注公众号接收最新文章:百川NLP

References
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182767.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
