大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
项目后端使用了springboot,maven,前端使用了ckeditor富文本编辑器。目前从html转换的word为doc格式,而图片处理支持的是docx格式,所以需要手动把doc另存为docx,然后才可以进行图片替换。
2021年了,我回来填坑了,又碰到了需要把 html 转换成 word 的场景,目前对于格式不固定的带图片的导出,有以下解决方案:
后端只做部分样式处理,导出工作交给前端完成,代码实现见第四部分。
一.添加maven依赖
主要使用了以下和poi相关的依赖,为了便于获取html的图片元素,还使用了jsoup:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>fr.opensagres.xdocreport</groupId>
<artifactId>xdocreport</artifactId>
<version>1.0.6</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>3.14</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>1.3</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
二.word转换为html
在springboot项目的resources目录下新建static文件夹,将需要转换的word文件temp.docx粘贴进去,由于static是springboot的默认资源文件,所以不需要在配置文件里面另行配置了,如果改成其他名字,需要在application.yml进行相应配置。
doc格式转换为html:
public static String docToHtml() throws Exception {
File path = new File(ResourceUtils.getURL("classpath:").getPath());
String imagePathStr = path.getAbsolutePath() + "\\static\\image\\";
String sourceFileName = path.getAbsolutePath() + "\\static\\test.doc";
String targetFileName = path.getAbsolutePath() + "\\static\\test2.html";
File file = new File(imagePathStr);
if(!file.exists()) {
file.mkdirs();
}
HWPFDocument wordDocument = new HWPFDocument(new FileInputStream(sourceFileName));
org.w3c.dom.Document document = DocumentBuilderFactory.newInstance().newDocumentBuilder().newDocument();
WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter(document);
//保存图片,并返回图片的相对路径
wordToHtmlConverter.setPicturesManager((content, pictureType, name, width, height) -> {
try (FileOutputStream out = new FileOutputStream(imagePathStr + name)) {
out.write(content);
} catch (Exception e) {
e.printStackTrace();
}
return "image/" + name;
});
wordToHtmlConverter.processDocument(wordDocument);
org.w3c.dom.Document htmlDocument = wordToHtmlConverter.getDocument();
DOMSource domSource = new DOMSource(htmlDocument);
StreamResult streamResult = new StreamResult(new File(targetFileName));
TransformerFactory tf = TransformerFactory.newInstance();
Transformer serializer = tf.newTransformer();
serializer.setOutputProperty(OutputKeys.ENCODING, "utf-8");
serializer.setOutputProperty(OutputKeys.INDENT, "yes");
serializer.setOutputProperty(OutputKeys.METHOD, "html");
serializer.transform(domSource, streamResult);
return targetFileName;
}
docx格式转换为html
public static String docxToHtml() throws Exception {
File path = new File(ResourceUtils.getURL("classpath:").getPath());
String imagePath = path.getAbsolutePath() + "\\static\\image";
String sourceFileName = path.getAbsolutePath() + "\\static\\test.docx";
String targetFileName = path.getAbsolutePath() + "\\static\\test.html";
OutputStreamWriter outputStreamWriter = null;
try {
XWPFDocument document = new XWPFDocument(new FileInputStream(sourceFileName));
XHTMLOptions options = XHTMLOptions.create();
// 存放图片的文件夹
options.setExtractor(new FileImageExtractor(new File(imagePath)));
// html中图片的路径
options.URIResolver(new BasicURIResolver("image"));
outputStreamWriter = new OutputStreamWriter(new FileOutputStream(targetFileName), "utf-8");
XHTMLConverter xhtmlConverter = (XHTMLConverter) XHTMLConverter.getInstance();
xhtmlConverter.convert(document, outputStreamWriter, options);
} finally {
if (outputStreamWriter != null) {
outputStreamWriter.close();
}
}
return targetFileName;
}
转换成功后会生成对应的html文件,如果想在前端展示,直接读取文件转换为String返回给前端即可。
public static String readfile(String filePath) {
File file = new File(filePath);
InputStream input = null;
try {
input = new FileInputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
StringBuffer buffer = new StringBuffer();
byte[] bytes = new byte[1024];
try {
for (int n; (n = input.read(bytes)) != -1;) {
buffer.append(new String(bytes, 0, n, "utf8"));
}
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
在富文本编辑器ckeditor中的显示效果:

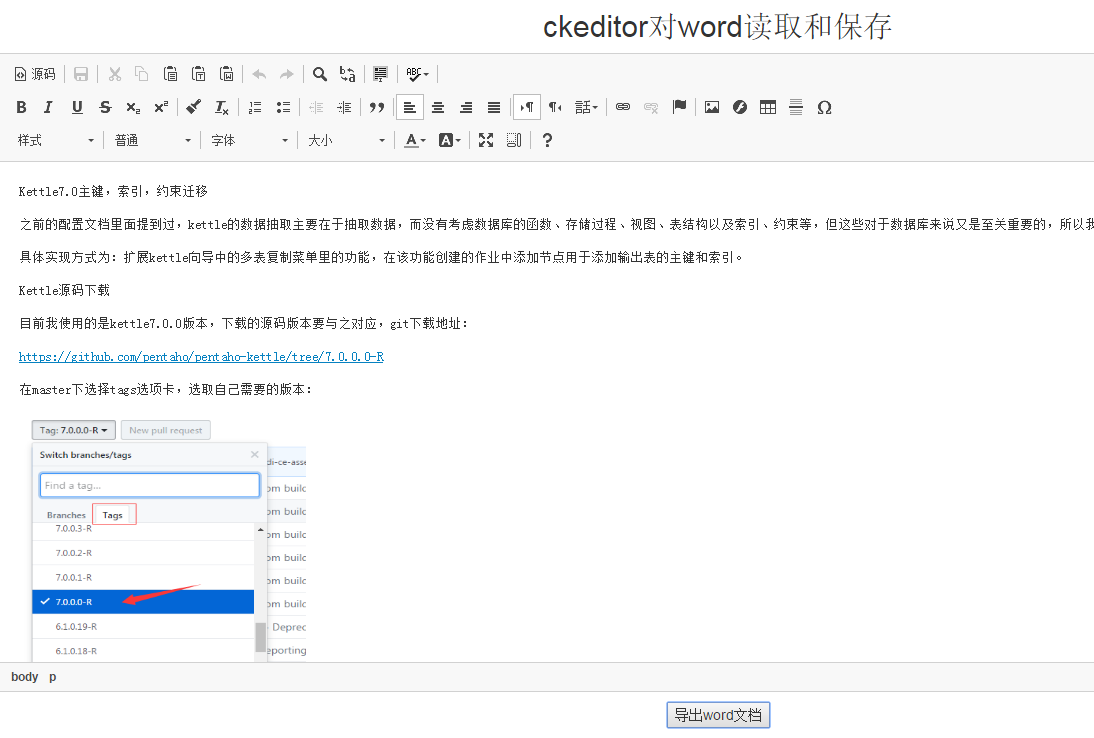
三.html转换为word
实现思路就是先把html中的所有图片元素提取出来,统一替换为变量字符”${imgReplace}“,如果多张图片,可以依序排列下去,之后生成对应的doc文件(之前试过直接生成docx文件发现打不开,这个问题尚未找到好的解决方法),我们将其另存为docx文件,之后就可以替换变量为图片了:
public static String writeWordFile(String content) {
String path = "D:/wordFile";
Map<String, Object> param = new HashMap<String, Object>();
if (!"".equals(path)) {
File fileDir = new File(path);
if (!fileDir.exists()) {
fileDir.mkdirs();
}
content = HtmlUtils.htmlUnescape(content);
List<HashMap<String, String>> imgs = getImgStr(content);
int count = 0;
for (HashMap<String, String> img : imgs) {
count++;
//处理替换以“/>”结尾的img标签
content = content.replace(img.get("img"), "${imgReplace" + count + "}");
//处理替换以“>”结尾的img标签
content = content.replace(img.get("img1"), "${imgReplace" + count + "}");
Map<String, Object> header = new HashMap<String, Object>();
try {
File filePath = new File(ResourceUtils.getURL("classpath:").getPath());
String imagePath = filePath.getAbsolutePath() + "\\static\\";
imagePath += img.get("src").replaceAll("/", "\\\\");
//如果没有宽高属性,默认设置为400*300
if(img.get("width") == null || img.get("height") == null) {
header.put("width", 400);
header.put("height", 300);
}else {
header.put("width", (int) (Double.parseDouble(img.get("width"))));
header.put("height", (int) (Double.parseDouble(img.get("height"))));
}
header.put("type", "jpg");
header.put("content", OfficeUtil.inputStream2ByteArray(new FileInputStream(imagePath), true));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
param.put("${imgReplace" + count + "}", header);
}
try {
// 生成doc格式的word文档,需要手动改为docx
byte by[] = content.getBytes("UTF-8");
ByteArrayInputStream bais = new ByteArrayInputStream(by);
POIFSFileSystem poifs = new POIFSFileSystem();
DirectoryEntry directory = poifs.getRoot();
DocumentEntry documentEntry = directory.createDocument("WordDocument", bais);
FileOutputStream ostream = new FileOutputStream("D:\\wordFile\\temp.doc");
poifs.writeFilesystem(ostream);
bais.close();
ostream.close();
// 临时文件(手动改好的docx文件)
CustomXWPFDocument doc = OfficeUtil.generateWord(param, "D:\\wordFile\\temp.docx");
//最终生成的带图片的word文件
FileOutputStream fopts = new FileOutputStream("D:\\wordFile\\final.docx");
doc.write(fopts);
fopts.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return "D:/wordFile/final.docx";
}
//获取html中的图片元素信息
public static List<HashMap<String, String>> getImgStr(String htmlStr) {
List<HashMap<String, String>> pics = new ArrayList<HashMap<String, String>>();
Document doc = Jsoup.parse(htmlStr);
Elements imgs = doc.select("img");
for (Element img : imgs) {
HashMap<String, String> map = new HashMap<String, String>();
if(!"".equals(img.attr("width"))) {
map.put("width", img.attr("width").substring(0, img.attr("width").length() - 2));
}
if(!"".equals(img.attr("height"))) {
map.put("height", img.attr("height").substring(0, img.attr("height").length() - 2));
}
map.put("img", img.toString().substring(0, img.toString().length() - 1) + "/>");
map.put("img1", img.toString());
map.put("src", img.attr("src"));
pics.add(map);
}
return pics;
}
OfficeUtil工具类,之前发现网上的写法只支持一张图片的修改,多张图片就会报错,是因为添加了图片,processParagraphs方法中的runs的大小改变了,会报ArrayList的异常,就和我们循环list中删除元素会报异常道理一样,解决方法就是复制一个新的Arraylist进行循环:
package com.example.demo.util;
import java.io.ByteArrayInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.poi.POIXMLDocument;
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow;
/** * 适用于word 2007 */
public class OfficeUtil {
/** * 根据指定的参数值、模板,生成 word 文档 * @param param 需要替换的变量 * @param template 模板 */
public static CustomXWPFDocument generateWord(Map<String, Object> param, String template) {
CustomXWPFDocument doc = null;
try {
OPCPackage pack = POIXMLDocument.openPackage(template);
doc = new CustomXWPFDocument(pack);
if (param != null && param.size() > 0) {
//处理段落
List<XWPFParagraph> paragraphList = doc.getParagraphs();
processParagraphs(paragraphList, param, doc);
//处理表格
Iterator<XWPFTable> it = doc.getTablesIterator();
while (it.hasNext()) {
XWPFTable table = it.next();
List<XWPFTableRow> rows = table.getRows();
for (XWPFTableRow row : rows) {
List<XWPFTableCell> cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
List<XWPFParagraph> paragraphListTable = cell.getParagraphs();
processParagraphs(paragraphListTable, param, doc);
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return doc;
}
/** * 处理段落 * @param paragraphList */
public static void processParagraphs(List<XWPFParagraph> paragraphList,Map<String, Object> param,CustomXWPFDocument doc){
if(paragraphList != null && paragraphList.size() > 0){
for(XWPFParagraph paragraph:paragraphList){
//poi转换过来的行间距过大,需要手动调整
if(paragraph.getSpacingBefore() >= 1000 || paragraph.getSpacingAfter() > 1000) {
paragraph.setSpacingBefore(0);
paragraph.setSpacingAfter(0);
}
//设置word中左右间距
paragraph.setIndentationLeft(0);
paragraph.setIndentationRight(0);
List<XWPFRun> runs = paragraph.getRuns();
//加了图片,修改了paragraph的runs的size,所以循环不能使用runs
List<XWPFRun> allRuns = new ArrayList<XWPFRun>(runs);
for (XWPFRun run : allRuns) {
String text = run.getText(0);
if(text != null){
boolean isSetText = false;
for (Entry<String, Object> entry : param.entrySet()) {
String key = entry.getKey();
if(text.indexOf(key) != -1){
isSetText = true;
Object value = entry.getValue();
if (value instanceof String) {
//文本替换
text = text.replace(key, value.toString());
} else if (value instanceof Map) {
//图片替换
text = text.replace(key, "");
Map pic = (Map)value;
int width = Integer.parseInt(pic.get("width").toString());
int height = Integer.parseInt(pic.get("height").toString());
int picType = getPictureType(pic.get("type").toString());
byte[] byteArray = (byte[]) pic.get("content");
ByteArrayInputStream byteInputStream = new ByteArrayInputStream(byteArray);
try {
String blipId = doc.addPictureData(byteInputStream,picType);
doc.createPicture(blipId,doc.getNextPicNameNumber(picType), width, height,paragraph);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
if(isSetText){
run.setText(text,0);
}
}
}
}
}
}
/** * 根据图片类型,取得对应的图片类型代码 * @param picType * @return int */
private static int getPictureType(String picType){
int res = CustomXWPFDocument.PICTURE_TYPE_PICT;
if(picType != null){
if(picType.equalsIgnoreCase("png")){
res = CustomXWPFDocument.PICTURE_TYPE_PNG;
}else if(picType.equalsIgnoreCase("dib")){
res = CustomXWPFDocument.PICTURE_TYPE_DIB;
}else if(picType.equalsIgnoreCase("emf")){
res = CustomXWPFDocument.PICTURE_TYPE_EMF;
}else if(picType.equalsIgnoreCase("jpg") || picType.equalsIgnoreCase("jpeg")){
res = CustomXWPFDocument.PICTURE_TYPE_JPEG;
}else if(picType.equalsIgnoreCase("wmf")){
res = CustomXWPFDocument.PICTURE_TYPE_WMF;
}
}
return res;
}
/** * 将输入流中的数据写入字节数组 * @param in * @return */
public static byte[] inputStream2ByteArray(InputStream in,boolean isClose){
byte[] byteArray = null;
try {
int total = in.available();
byteArray = new byte[total];
in.read(byteArray);
} catch (IOException e) {
e.printStackTrace();
}finally{
if(isClose){
try {
in.close();
} catch (Exception e2) {
System.out.println("关闭流失败");
}
}
}
return byteArray;
}
}
我认为之所以word2003不支持图片替换,主要是因为处理2003版本的HWPFDocument对象被声明为了final,我们就无法重写他的方法了。
而处理2007版本的类为XWPFDocument,是可以继承的,通过继承XWPFDocument,重写createPicture方法即可实现图片替换,以下为对应的CustomXWPFDocument类:
package com.example.demo.util;
import java.io.IOException;
import java.io.InputStream;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.xmlbeans.XmlException;
import org.apache.xmlbeans.XmlToken;
import org.openxmlformats.schemas.drawingml.x2006.main.CTNonVisualDrawingProps;
import org.openxmlformats.schemas.drawingml.x2006.main.CTPositiveSize2D;
import org.openxmlformats.schemas.drawingml.x2006.wordprocessingDrawing.CTInline;
/** * 自定义 XWPFDocument,并重写 createPicture()方法 */
public class CustomXWPFDocument extends XWPFDocument {
public CustomXWPFDocument(InputStream in) throws IOException {
super(in);
}
public CustomXWPFDocument() {
super();
}
public CustomXWPFDocument(OPCPackage pkg) throws IOException {
super(pkg);
}
/** * @param ind * @param width 宽 * @param height 高 * @param paragraph 段落 */
public void createPicture(String blipId, int ind, int width, int height,XWPFParagraph paragraph) {
final int EMU = 9525;
width *= EMU;
height *= EMU;
CTInline inline = paragraph.createRun().getCTR().addNewDrawing().addNewInline();
String picXml = ""
+ "<a:graphic xmlns:a=\"http://schemas.openxmlformats.org/drawingml/2006/main\">"
+ " <a:graphicData uri=\"http://schemas.openxmlformats.org/drawingml/2006/picture\">"
+ " <pic:pic xmlns:pic=\"http://schemas.openxmlformats.org/drawingml/2006/picture\">"
+ " <pic:nvPicPr>" + " <pic:cNvPr id=\""
+ ind
+ "\" name=\"Generated\"/>"
+ " <pic:cNvPicPr/>"
+ " </pic:nvPicPr>"
+ " <pic:blipFill>"
+ " <a:blip r:embed=\""
+ blipId
+ "\" xmlns:r=\"http://schemas.openxmlformats.org/officeDocument/2006/relationships\"/>"
+ " <a:stretch>"
+ " <a:fillRect/>"
+ " </a:stretch>"
+ " </pic:blipFill>"
+ " <pic:spPr>"
+ " <a:xfrm>"
+ " <a:off x=\"0\" y=\"0\"/>"
+ " <a:ext cx=\""
+ width
+ "\" cy=\""
+ height
+ "\"/>"
+ " </a:xfrm>"
+ " <a:prstGeom prst=\"rect\">"
+ " <a:avLst/>"
+ " </a:prstGeom>"
+ " </pic:spPr>"
+ " </pic:pic>"
+ " </a:graphicData>" + "</a:graphic>";
inline.addNewGraphic().addNewGraphicData();
XmlToken xmlToken = null;
try {
xmlToken = XmlToken.Factory.parse(picXml);
} catch (XmlException xe) {
xe.printStackTrace();
}
inline.set(xmlToken);
inline.setDistT(0);
inline.setDistB(0);
inline.setDistL(0);
inline.setDistR(0);
CTPositiveSize2D extent = inline.addNewExtent();
extent.setCx(width);
extent.setCy(height);
CTNonVisualDrawingProps docPr = inline.addNewDocPr();
docPr.setId(ind);
docPr.setName("图片" + ind);
docPr.setDescr("测试");
}
}
以上就是通过POI实现html和word的相互转换,对于html无法转换为可读的docx这个问题,不是很好解决。
html和word的相互转换也可以通过 freemarker 模板的方式实现,这个是同事给的思路,我没有尝试,大家有兴趣的可以试试,缺点就是模板是固定的,不够灵活,不适用于经常变动的网页。
历经两年多又发现了一个新的解决方案,亲测可用,见第四部分。
四.html转换为word之前端实现
前端实现的方法比较灵活,也支持表格,echarts 的导出,使用 file-saver 插件实现。
在 vue 和 angular 下测试了都可以用,而后端只需要对图片和样式进行处理,转换和导出工作交给前端来做(后端同学露出了如释重负的笑容)。
java 代码实现
controller 实现:
@PostMapping("/article/htmlFormat")
public Ret html(String html) throws Exception {
return articleService.formatHtmlStyle(html);
}
service 实现:
// 实现图片和样式处理的方法
public Ret formatHtmlStyle(String html) {
JSONArray picsArr = new JSONArray();
// 缩小图片
Document doc = Jsoup.parse(html);
Elements elementsP = doc.getElementsByTag("p");
for (int i = 0; i < elementsP.size(); i++) {
Element element = elementsP.get(i);
boolean hasImg = false;
Elements elementsChildren = element.children();
for (int j = 0; j < elementsChildren.size(); j++) {
Element elementChild = elementsChildren.get(j);
if (elementChild.nodeName().equals("img")) {
hasImg = true;
break;
}
}
if (hasImg) {
element.attr("style", "text-align: center ;");
} else {
element.attr("style",
"font-family: FangSong_GB2312 ;font-size:18px;text-indent: 2em ;line-height:34px;text-align:justify;");
}
}
Elements elements = doc.getElementsByTag("img");
for (int i = 0; i < elements.size(); i++) {
Element element = elements.get(i);
String src = element.attr("src");
JSONObject picjo = new JSONObject();
picjo.put("index", i);
// 将网络图片转为 base64 格式
picjo.put("src", CommonUtil.urlToBase64(src));
picsArr.add(picjo);
element.attr("src", "" + i);
}
Ret ret = Ret.create().setCodeAndMsg(200).set("html", doc.body().html()).set("pics", picsArr);
return ret;
}
注意事项:
1.这里的Ret就是一个结果封装类,不是重点,只要把 html 和 pics 返回即可。
2.html 中的图片路径是网络图片,需要转换为 base64 才能在 word 中显示。
CommonUtil 中的转换代码如下:
public static String urlToBase64(String imgUrl) {
InputStream inputStream = null;
ByteArrayOutputStream outputStream = null;
byte[] buffer = null;
try {
// 创建URL
URL url = new URL(imgUrl);
// 创建链接
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5000);
inputStream = conn.getInputStream();
outputStream = new ByteArrayOutputStream();
// 将内容读取内存中
buffer = new byte[1024];
int len = -1;
while ((len = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, len);
}
buffer = outputStream.toByteArray();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
// 关闭inputStream流
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (outputStream != null) {
try {
// 关闭outputStream流
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 对字节数组Base64编码
String base64 = "data:image/png;base64," + new BASE64Encoder().encode(buffer);
return base64;
}
vue 代码实现
1.安装 file-saver
npm install file-saver --save
bower install file-saver
如果提示 “bower不是内部或外部命令”,需要安装bower
npm install -g bower
安装 TypeScript 定义
npm install @types/file-saver --save-dev
2.使用
导入 saveAs
import {
saveAs } from 'file-saver';
实现下载处理逻辑
downloadArticle: function() {
var FileSaver = require('file-saver');
var html = "这里是你的html内容";
//var html = "<html>" + this.$refs.article.innerHTML + "</html>";
var param = new URLSearchParams();
param.append('html', html);
// 调用上面的 java 接口获取处理后的html内容
this.$axios({
method: 'post',
url: '/article/htmlFormat',
data: param
}).then((response) = > {
const _static = {
mhtml: {
top: "Mime-Version: 1.0\nContent-Base: " + location.href + "\nContent-Type: Multipart/related; boundary=\"NEXT.ITEM-BOUNDARY\";type=\"text/html\"\n\n--NEXT.ITEM-BOUNDARY\nContent-Type: text/html; charset=\"utf-8\"\nContent-Location: " + location.href + "\n\n<!DOCTYPE html>\n<html>\n_html_</html>",
head: "<head>\n<meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\">\n<style>\n_styles_\n</style>\n</head>\n",
body: "<body>_body_</body>"
}
};
const dealhtml = response.data.html;
const img = response.data.pics;
let mhtmlBottom = "\n";
for (let i = 0; i < img.length; i++) {
const uri = img[i].src;
const index = img[i].index;
mhtmlBottom += "--NEXT.ITEM-BOUNDARY\n";
mhtmlBottom += "Content-Location: " + index + "\n";
mhtmlBottom += "Content-Type: " + uri.substring(uri.indexOf(":") + 1, uri.indexOf(";")) + "\n";
mhtmlBottom += "Content-Transfer-Encoding: " + uri.substring(uri.indexOf(";") + 1, uri.indexOf(",")) + "\n\n";
mhtmlBottom += uri.substring(uri.indexOf(",") + 1) + "\n\n";
}
mhtmlBottom += "--NEXT.ITEM-BOUNDARY--";
// 整合html代码片段
const fileContent = _static.mhtml.top.replace("_html_", _static.mhtml.body.replace("_body_", dealhtml)) + mhtmlBottom;
// 导出
const blob = new Blob([fileContent], {
type: "application/msword;charset=utf-8"
});
saveAs(blob, `testImage.doc`);
});
}
注意事项:
不要图省事在后端把 base64 写在 image 标签的 src 里面,这样会导致导出的word文档只有在切换为编辑视图后才能显示图片。
最终效果:

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182726.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
