大家好,又见面了,我是你们的朋友全栈君。如果您正在找激活码,请点击查看最新教程,关注关注公众号 “全栈程序员社区” 获取激活教程,可能之前旧版本教程已经失效.最新Idea2022.1教程亲测有效,一键激活。
Jetbrains全系列IDE稳定放心使用
ES集群介绍
为什么需要集群
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念
-
集群(cluster):一组拥有共同的 cluster name 的 节点。
-
节点(node) :集群中的一个 Elasticearch 实例
-
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
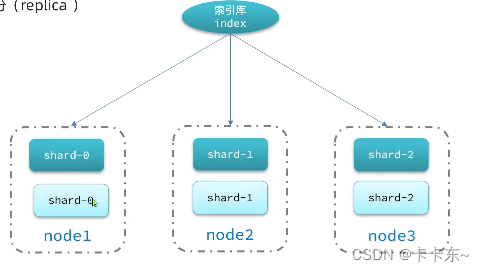

此处,我们把数据分成3片:shard0、shard1、shard2
-
主分片(Primary shard):相对于副本分片的定义。
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
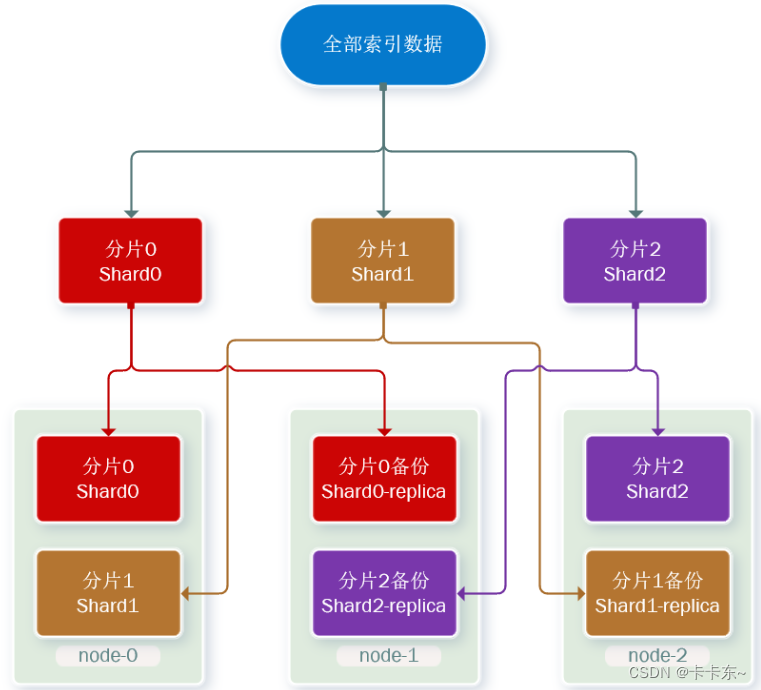
现在,每个分片都有1个备份,存储在3个节点:
- node1:保存了分片0和2
- node1:保存了分片1和0
- node3:保存了分片2和1
搭建ES集群
部署es集群可以直接使用docker-compose来完成,不过要求你的Linux虚拟机至少有4G的内存空间
首先编写一个docker-compose文件,内容如下:
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
文件内容介绍:
version: complse版本
es01: 节点
image: 镜像
container_name:容器名称
environment:环境变量node.name: 节点名称
cluster.name: 集群名称,es自动建立集群
discovery.seed_hosts:另外两个的地址,可以用容器名称互联
cluster.initial_master_nodes:初始化的主节点,可以参与选举
“ES_JAVA_OPTS=-Xms512m -Xmx512m”:最小和最大JVM内存volumes: 数据卷地址
ports: 端口映射
编写完成后,将此文件上传到有docker-compose的linux文件夹中:
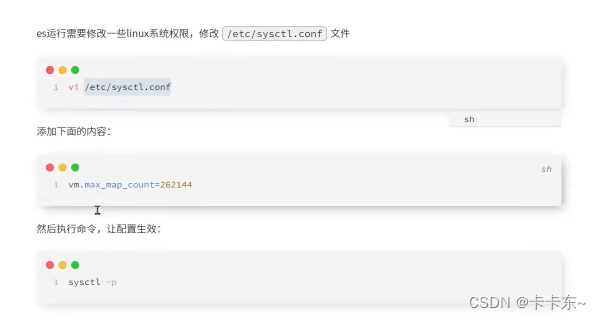
还需要修改一下运行的内存,去/etc/susctl.conf下。不然集群占用太大起不来:
完成以后,回到docker-compose文件目录下,执行:
docker-compose up -d
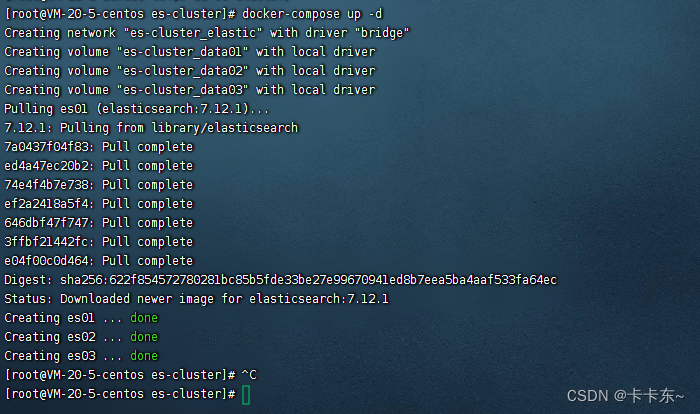
可以看到,三个es都启动了
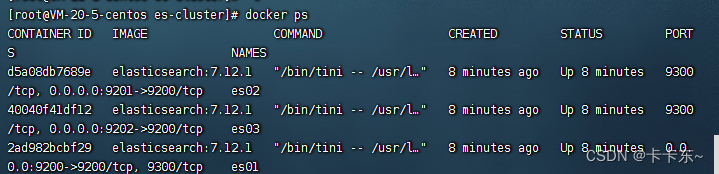
好家伙,内存堆满了:
使用cerebro监控一下集群:
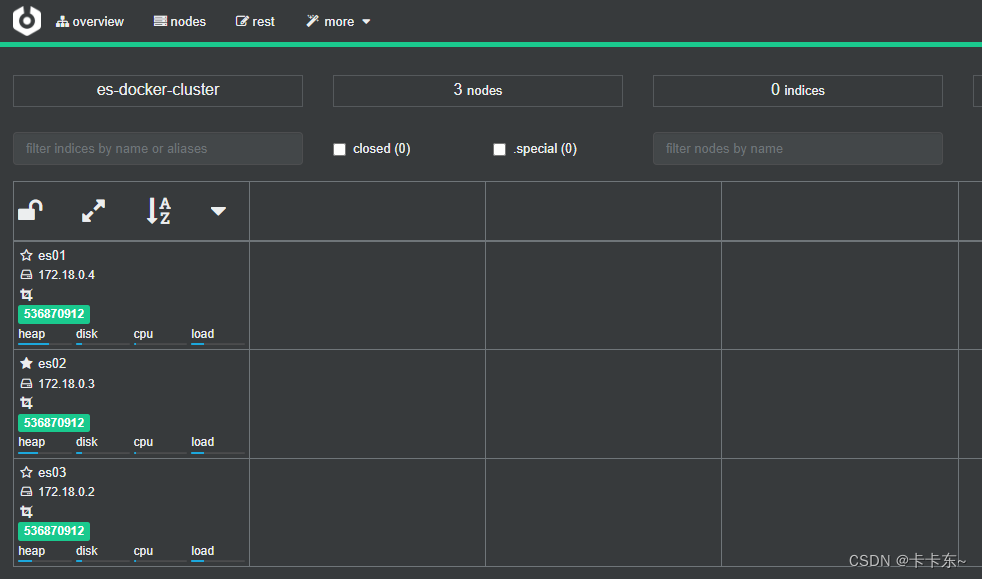
创建集群的索引库:可以在settings中指定分片数量和副本数量。创建完成后可以看到分片和副本,也说明了es天生支持分布式集群。

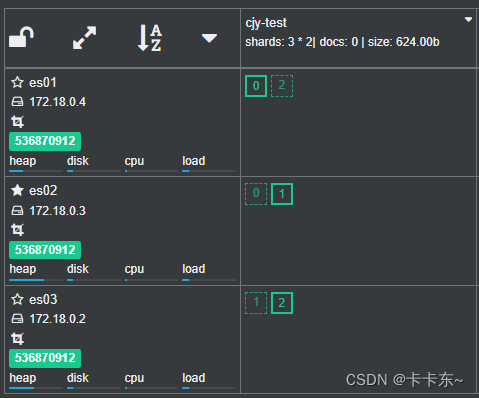
这样我们的一个es集群就搭建好了。但是真正生产环境上,还需要注意一些问题。下面这些引入概念:
集群职责划分
elasticsearch中集群节点有不同的职责划分:
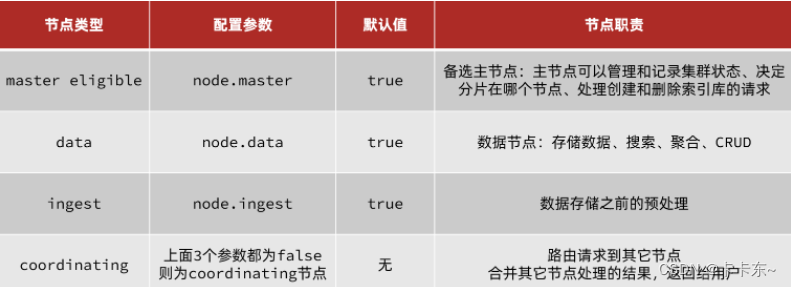
默认情况下,集群中的任何一个节点都同时具备上述四种角色。
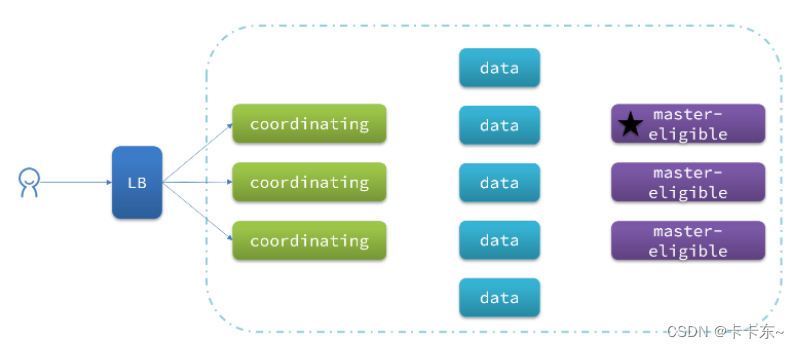
但是真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求第
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:
集群脑裂问题
脑裂是因为集群中的节点失联导致的。
例如一个集群中,主节点与其它节点失联:
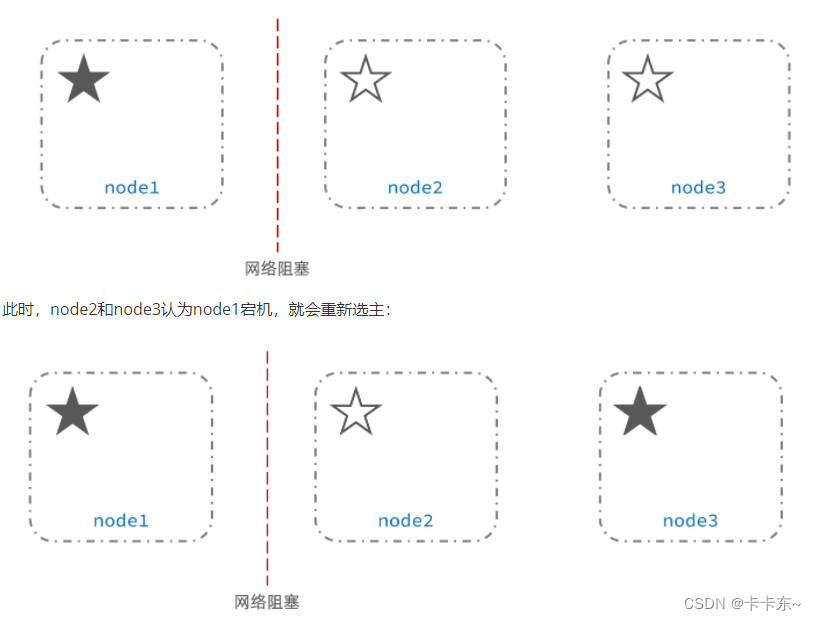
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异。
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:
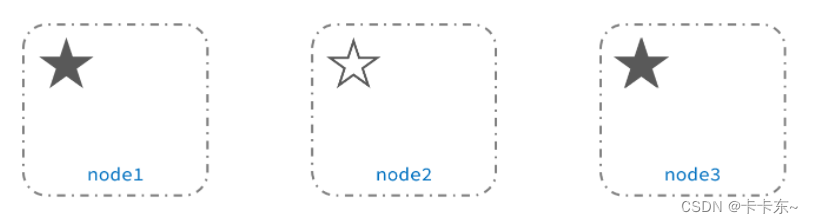
解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选。集群中依然只有1个主节点,没有出现脑裂。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/182624.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
